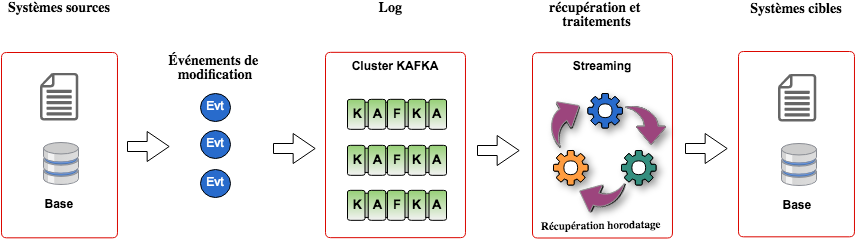
Kafka est très répandu dans les architectures Big Data orientées événements. Un cas d'utilisation typique est son utilisation pour la synchronisation entre des systèmes existants (et souvent centralisés) vers des systèmes distribués. Les modifications du système source sont émises sous forme de messages dans Kafka et récupérées et traitées pour alimenter un Data Lake...
Quelle est la latence minimale que les frameworks de streaming peuvent garantir lors de la consommation de messages Kafka ?
C'est une question qui obsède les clients pour qui la mise en place d'une architecture orientée événements et donc un découplage entre gestion des messages et traitement est obligatoirement synonyme de latence importante.
Voici les frameworks testés :
- Kafka Stream
- Flink
- Spark (Streaming, Structured Streaming et Continuous Processing)
Et leur versions :
- Spark : 2.3.0
- Flink : 1.4.2
- Kafka : 0.11.0.2
Spark Continous Processing est une nouveauté de la version 2.3. Il promet une latence beaucoup plus faible que Structured Streaming, un code très proche (en réalité une seule ligne change) et un temps de failover amélioré. Cependant, dans la version 2.3, Spark Continous Processing est en bêta (les filtres ne sont pas encore supportés, les listeners provoquent des dysfonctionnements...).
Description du benchmark
Le code source du benchmark est disponible à l'url suivante : https://gitlab.ippon.fr/cparageaud/Kafka-Latency
Alimentation
Un traitement qui injecte des messages au format JSON dans Kafka. Deux versions d'un producteur de message en utilisant l'API Kafka et un seul thread.
- Une version synchrone (4000 messages/seconde en moyenne).
- Une version asynchrone (80000 messages/seconde en moyenne).
On peut configurer le nombre de partitions et le nombre de réplicas.
Traitement
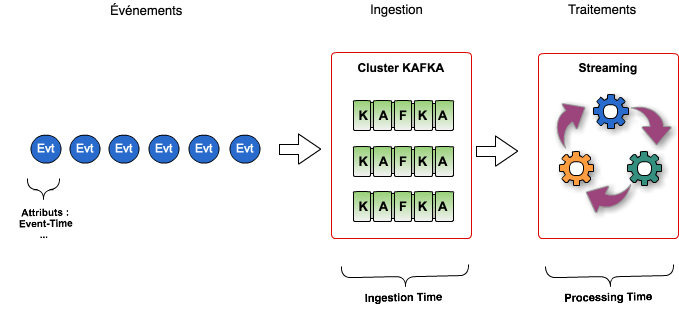
Pour chacun des frameworks testés, le traitement lit les messages, les convertit en objet Java et mesure le temps entre l'insertion dans Kafka et sa prise en compte dans le framework. Pour cela je profite de l'horodatage automatique des messages (Kafka 0.10) pour mesurer le délai entre l'insertion d'un message et sa lecture par le framework de streaming.
Le programme ne mesure donc que le temps pris par le framework pour récupérer le message, il faudrait y ajouter le temps de traitement du message pour être plus réaliste.
!!!Remarque importante!!!
Il y a assez peu d'optimisation du code des frameworks de streaming. Le but étant de mesurer la capacité brute des frameworks et leur simplicité de mise en œuvre.
Résultats
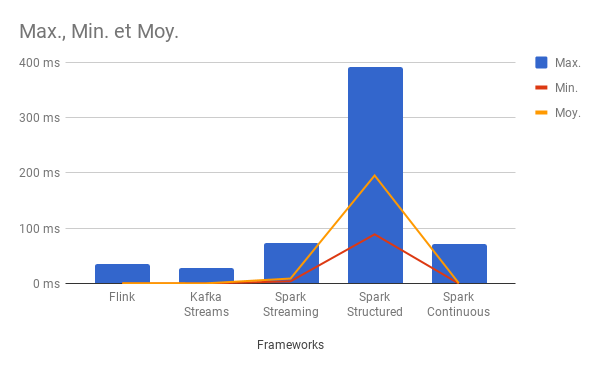
Voici les statistiques relevées une fois sur trois essais et en prenant le meilleur résultat. À ce sujet, il faut noter que la latence est plus importante lors des premières mesures.
Les statistiques affichent le nombre de messages lus, le temps total pour traiter 10 000 messages, les temps min/moyen/max en millisecondes pour lire un message.
Test n°1 (4000 msg/sec)
Tests réalisés en local (pour éviter les latences réseau) et avec trois partitions.
Débit de 5000 messages par seconde.
Flink
count=10000, sum=5202, min=0, average=0.520200, max=25
count=10000, sum=4185, min=0, average=0.418500, max=16
count=10000, sum=3577, min=0, average=0.357700, max=19
count=10000, sum=3561, min=0, average=0.356100, max=12
count=10000, sum=4492, min=0, average=0.449200, max=36
count=10000, sum=4543, min=0, average=0.454300, max=20
count=10000, sum=4725, min=0, average=0.472500, max=19
count=10000, sum=4960, min=0, average=0.496000, max=14
count=10000, sum=3960, min=0, average=0.396000, max=13
count=10000, sum=3295, min=0, average=0.329500, max=7
Total=100000, sum=42500, min=0, average=0.425000, max=36
Kafka Stream
count=10000, sum=5562, min=0, average=0.556200, max=28
count=10000, sum=4452, min=0, average=0.445200, max=17
count=10000, sum=3363, min=0, average=0.336300, max=19
count=10000, sum=4182, min=0, average=0.418200, max=14
count=10000, sum=3076, min=0, average=0.307600, max=21
count=10000, sum=2765, min=0, average=0.276500, max=9
count=10000, sum=2677, min=0, average=0.267700, max=18
count=10000, sum=2653, min=0, average=0.265300, max=10
count=10000, sum=2640, min=0, average=0.264000, max=14
count=10000, sum=2703, min=0, average=0.270300, max=2
Total=100000, sum=34073, min=0, average=0.340730, max=28
Spark Continuous Processing
count=10000, sum=6061, min=0, average=0.606100, max=39
count=10000, sum=4958, min=0, average=0.495800, max=40
count=10000, sum=3884, min=0, average=0.388400, max=13
count=10000, sum=6422, min=0, average=0.642200, max=52
count=10000, sum=5517, min=0, average=0.551700, max=62
count=10000, sum=8755, min=0, average=0.875500, max=62
count=10000, sum=6386, min=0, average=0.638600, max=50
count=10000, sum=3183, min=0, average=0.318300, max=4
count=10000, sum=9583, min=0, average=0.958300, max=72
count=10000, sum=7614, min=0, average=0.761400, max=59
Total=100000, sum=62363, min=0, average=0.623630, max=72
Spark Streaming
count=10000, sum=300850, min=4, average=30.085000, max=73
count=10000, sum=297202, min=5, average=29.720200, max=72
count=10000, sum=288975, min=4, average=28.897500, max=61
count=10000, sum=283003, min=4, average=28.300300, max=61
count=10000, sum=287947, min=4, average=28.794700, max=58
count=10000, sum=289833, min=4, average=28.983300, max=58
count=10000, sum=300129, min=4, average=30.012900, max=63
count=10000, sum=293778, min=5, average=29.377800, max=58
count=10000, sum=289893, min=4, average=28.989300, max=65
count=10000, sum=285300, min=4, average=28.530000, max=59
Total=100000, sum=2916910, min=4, average=29.169100, max=73
Spark Structured Streaming
count=10000, sum=2262725, min=107, average=226.272500, max=372
count=10000, sum=2067066, min=99, average=206.706600, max=343
count=10000, sum=1897437, min=93, average=189.743700, max=347
count=10000, sum=1855384, min=89, average=185.538400, max=354
count=10000, sum=1805868, min=91, average=180.586800, max=323
count=10000, sum=1840182, min=90, average=184.018200, max=312
count=10000, sum=1818365, min=90, average=181.836500, max=338
count=10000, sum=1909444, min=89, average=190.944400, max=341
count=10000, sum=1866281, min=91, average=186.628100, max=314
count=10000, sum=2231013, min=100, average=223.101300, max=391
Total=100000, sum=19553765, min=89, average=195.537650, max=391
Analyse des résultats
Kafka Stream et Flink se démarquent assez nettement en termes de garantie de latence faible (moyenne) et méritent leur qualification de Streaming temps réel.
Spark suit avec des temps très variables entre les différentes API :
- Continuous Streaming (très prometteur),
- Streaming classique (correct),
- Structured Streaming (décevant).
On peut justifier ces latences entre Spark et les autres frameworks par la façon dont sont récupérés les messages.
Kafka Stream et Flink récupèrent les messages presque unitairement (3 maximum selon mes observations) contrairement à Spark qui les récupère soit par lots (max.poll.records : 1000 par défaut) soit selon la fenêtre de micro-batching indiquée.
Les évolutions récentes de Spark vers du temps réel n'ont pas modifié réellement la nature micro-batch du framework mais les améliorations sont tout de même notables avec l'API Continuous Processing.
Dans cette version de Spark on ne dispose plus que de l'approche 'Direct API' qui simplifie l'écriture des programme en gérant automatiquement la scalabilité des traitements (autant de workers que de partitions) et facilite le commit des offsets dans Kafka.
L'ancienne API qui utilisait des receivers est plus configurable et sans doute plus rapide mais dépréciée.
Avec l'approche 'Direct API' les possibilités de tuning sont très limitées.
On peut bien sûr améliorer la latence en définissant un nombre maximum de messages à récupérer plus faible que la valeur par défaut mais très rapidement Spark n'arrive plus à suivre le débit imposé par le batch d'insertion.
Le nombre de partitions Kafka est en réalité le seul levier possible, et il faut donc un nombre de consommateurs supérieur au nombre de producteurs afin de garantir une latence faible.
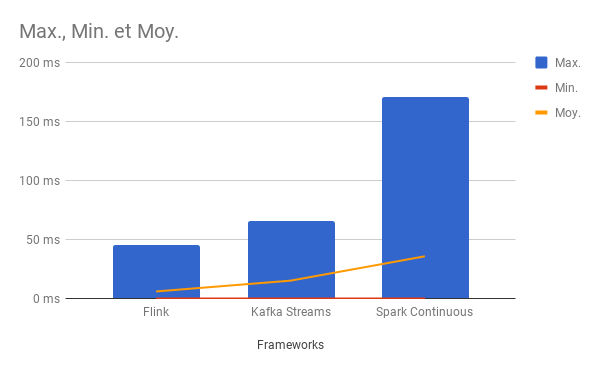
Test n°2 : impact du débit et du nombre de partitions
Tests toujours réalisés en local (pour éviter les latences réseau) et avec un producteur asynchrone : 80 000 messages par seconde. Seul le nombre de partitions varie entre les deux tests (3 puis 6).
Test avec trois partitions
Flink
count=10000, sum=31117, min=0, average=3.111700, max=20
count=10000, sum=22143, min=0, average=2.214300, max=32
count=10000, sum=28706, min=0, average=2.870600, max=25
count=10000, sum=38498, min=0, average=3.849800, max=14
count=10000, sum=19681, min=0, average=1.968100, max=13
count=10000, sum=99540, min=0, average=9.954000, max=25
count=10000, sum=80365, min=0, average=8.036500, max=22
count=10000, sum=24124, min=0, average=2.412400, max=14
count=10000, sum=131536, min=0, average=13.153600, max=45
count=10000, sum=122838, min=0, average=12.283800, max=45
count=100000, sum=598548, min=0, average=5.985480, max=45
Kafka Stream
count=10000, sum=32500, min=0, average=3.250000, max=19
count=10000, sum=47099, min=0, average=4.709900, max=34
count=10000, sum=51013, min=0, average=5.101300, max=20
count=10000, sum=37862, min=0, average=3.786200, max=14
count=10000, sum=118486, min=0, average=11.848600, max=43
count=10000, sum=118137, min=0, average=11.813700, max=46
count=10000, sum=226332, min=0, average=22.633200, max=60
count=10000, sum=361573, min=4, average=36.157300, max=55
count=10000, sum=400666, min=4, average=40.066600, max=62
count=10000, sum=119749, min=0, average=11.974900, max=66
count=100000, sum=1513417, min=0, average=15.134170, max=66
Spark Continuous Processing
count=10000, sum=58016, min=1, average=5.801600, max=28
count=10000, sum=70277, min=1, average=7.027700, max=56
count=10000, sum=174781, min=0, average=17.478100, max=44
count=10000, sum=27171, min=0, average=2.717100, max=10
count=10000, sum=192750, min=0, average=19.275000, max=95
count=10000, sum=226921, min=2, average=22.692100, max=72
count=10000, sum=360543, min=0, average=36.054300, max=142
count=10000, sum=722477, min=26, average=72.247700, max=139
count=10000, sum=829614, min=36, average=82.961400, max=164
count=10000, sum=914190, min=34, average=91.419000, max=171
count=100000, sum=3576740, min=0, average=35.767400, max=171
Test avec six partitions
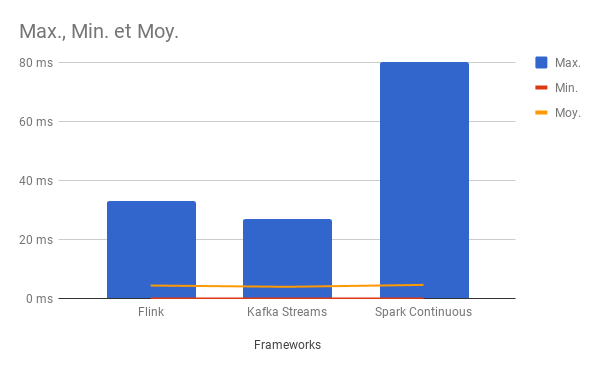
Spark Continuous Processing
count=10000, sum=49561, min=1, average=4.956100, max=80
count=10000, sum=37316, min=1, average=3.731600, max=32
count=10000, sum=39679, min=1, average=3.967900, max=17
count=10000, sum=29107, min=1, average=2.910700, max=19
count=10000, sum=30914, min=0, average=3.091400, max=6
count=10000, sum=31493, min=0, average=3.149300, max=8
count=10000, sum=114246, min=0, average=11.424600, max=66
count=10000, sum=54818, min=0, average=5.481800, max=41
count=10000, sum=37484, min=0, average=3.748400, max=16
count=10000, sum=36536, min=0, average=3.653600, max=18
count=100000, sum=461154, min=0, average=4.611540, max=80
Flink
count=10000, sum=59183, min=1, average=5.918300, max=33
count=10000, sum=37661, min=1, average=3.766100, max=29
count=10000, sum=44510, min=1, average=4.451000, max=10
count=10000, sum=37180, min=0, average=3.718000, max=6
count=10000, sum=59425, min=1, average=5.942500, max=32
count=10000, sum=36416, min=1, average=3.641600, max=8
count=10000, sum=43589, min=1, average=4.358900, max=7
count=10000, sum=38930, min=1, average=3.893000, max=8
count=10000, sum=48019, min=0, average=4.801900, max=22
count=10000, sum=35069, min=1, average=3.506900, max=6
count=100000, sum=439982, min=0, average=4.399820, max=33
Kafka Stream
count=10000, sum=39328, min=1, average=3.932800, max=27
count=10000, sum=46471, min=1, average=4.647100, max=27
count=10000, sum=29261, min=0, average=2.926100, max=10
count=10000, sum=33628, min=1, average=3.362800, max=8
count=10000, sum=30319, min=0, average=3.031900, max=14
count=10000, sum=35544, min=0, average=3.554400, max=7
count=10000, sum=38136, min=1, average=3.813600, max=6
count=10000, sum=53384, min=0, average=5.338400, max=23
count=10000, sum=54927, min=0, average=5.492700, max=21
count=10000, sum=35464, min=0, average=3.546400, max=6
count=100000, sum=396462, min=0, average=3.964620, max=27
Conclusion
Il est possible de garantir une latence très faible dans une architecture orientée événements et ce avec Kafka couplé aux principaux frameworks de Streaming (et avec la co-localisation des données et des traitements).
Il y a toutefois des différences importantes entre les différents frameworks de Streaming lorsqu'il s'agit de récupérer des messages dans Kafka. On peut soit privilégier la latence soit le débit total.
La latence peut être réduite en multipliant le nombre de partitions dans Kafka, ce qui prouve la scalabilité de l'ensemble.
Mais il ne faut pas oublier que ce ne sont que les temps de récupération des messages, il a aussi des différences de performances de traitement des données pour les différents frameworks évoqués.
Il y a aussi des cas où les temps de traitement sont importants (proche de la seconde) ce qui devrait lisser les différences entre les frameworks.
Et surtout il ne faut pas se focaliser uniquement sur les performances, les critères de choix doivent intégrer de nombreux paramètres (failover, scalabilité, écosystème...).
Il est donc conseillé de réaliser un benchmark représentatif du cas d'usage pour véritablement statuer.


