

Après un premier article consacré au data lineage pour les Jobs Spark, nous continuons cette série que l’on pourrait appeler “Spark dans la vraie vie”, pour nous intéresser à un autre aspect très important lorsque l’on utilise des traitements Spark sur un datalake d’entreprise : le logging et les métriques.
TL;DR Babar By Critéo offre une solution clef en main pour visualiser les ressources consommés sur le cluster lors d'un Job Spark.
Commençons par définir la notion de logging telle qu’on l’entend dans les systèmes distribués. On parle de logging dans des systèmes basés autour de la notion de fichiers de logs (que l’on pourrait traduire par journal d’évènements en français). Un log va contenir toutes les métriques et messages remontés à la fois par notre traitement (log applicatif) et par notre infrastructure (log technique). Ces logs peuvent être soit générés automatiquement ou bien définis par le développeur à l’intérieur de son code.
Avec cette première définition, on comprend qu’il y a deux types de logs :
- Les logs applicatifs propres à chaque Application (Job Spark dans notre cas).
- Les logs d’infrastructure propres à la topologie du cluster et au gestionnaire de ressources ([YARN dans notre cas, le vrai, pas celui qui permet de gérer les dépendances JavaScript).
Et ces logs peuvent être générés de deux façons :
- Automatiquement que ce soit pour l’applicatif ou l’infrastructure.
- Par l’action d’un utilisateur (plutôt au niveau applicatif par exemple avec la fonction
log.info()oulog.warn()).
Dans le cas des Jobs Spark, les logs générés automatiquement (appli & infra) sont particulièrement volumineux et fouillis. Il peut être très complexe et peu pratique de retrouver les logs créés par l’utilisateur au milieu de toutes ces informations générées automatiquement.

Il nous faut donc des outils pour permettre de gérer plus efficacement ces fichiers de logs pour permettre au développeur de pouvoir débugger efficacement son code et de superviser ses Jobs. Au niveau infra, les logs sont générés au niveau de la consommation des ressources (CPU, RAM, etc.) à un instant t. Mais ce qui nous intéresse est de pouvoir générer du reporting sur la consommation de ressources tout au long de la durée du traitement sous forme de graphique. Ce que nous allons voir en fin d’article avec Babar, outil open source développé par Criteo présenté dans cet article.
Gestion des logs applicatifs
Générations des logs avec Log4J
Pour générer des informations dans des logs, on utilise en règle générale un logger comme Log4J. Log4J fonctionne selon un système d’appender qui va écrire chaque nouvelle ligne du fichier de log dans un ou plusieurs emplacements cibles (fichier, console, etc.).
On peut définir plusieurs appenders pour une même configuration Log4J :
#- Root logger use
log4j.rootLogger=INFO, CONSOLE, KAFKA
#- Logs format in the console
log4j.appender.CONSOLE=org.apache.log4j.ConsoleAppender
log4j.appender.CONSOLE.layout=org.apache.log4j.PatternLayout
log4j.appender.CONSOLE.layout.ConversionPattern=%d{HH:mm:ss} %c{1}:%L %m%n
On inclut ce fichier dans la commande spark-submit qui déclenche notre traitement :
--driver-java-options '-Dlog4j.configuration=file:/path/to/LOG4J_FILE'
Enfin, dans notre classe principale on instancie le logger avec l’instruction :
val logger = Logger.getLogger(getClass.getName)
On pourra ensuite logger n’importe quelle information avec les méthodes info, error, warn, etc. :
logger.info("Lancement du Job Spark")
Exploitation des fichiers de logs
Redirection vers un fichier
Avec Log4J, il existe deux solutions pour envoyer les logs applicatifs vers un fichier :
- Utiliser un appender qui écrit directement dans un fichier sur un des edge nodes du cluster.
- Rediriger la sortie standard de la console (stdout) vers un fichier sur un des edge nodes du cluster.
Une fois que tous nos logs applicatifs sont stockés dans un fichier, on peut commencer à les analyser avec la commande grep par exemple pour extraire les informations qui nous intéressent.
Détail des logs dans Spark History Server
La solution précédente s’avérant particulièrement fastidieuse pour comprendre ce qui s’est passé au cours de notre traitement, Spark fournit nativement une Web UI pour visualiser les différentes étapes et logs générés au cours du traitement : Spark History Server.
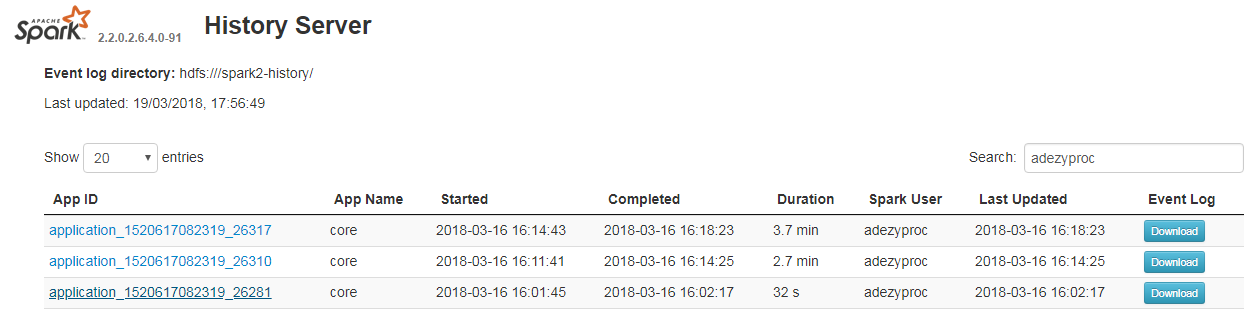
Cette interface permet de mieux comprendre ce qui se déroule au cours du traitement même si cela peut être perturbant pour ceux non habitués à Spark car la quasi-totalité des temps de traitements sont concentrés dans ce qu’on appelle les actions (écriture en BDD, count, groupBy). Cela est dû au mécanisme de lazyness de Spark qui effectue toutes les transformations (cela mériterait un autre article de blog, mais si cela vous intéresse plus d’informations sont disponibles dans cet article du blog de Data Flair).
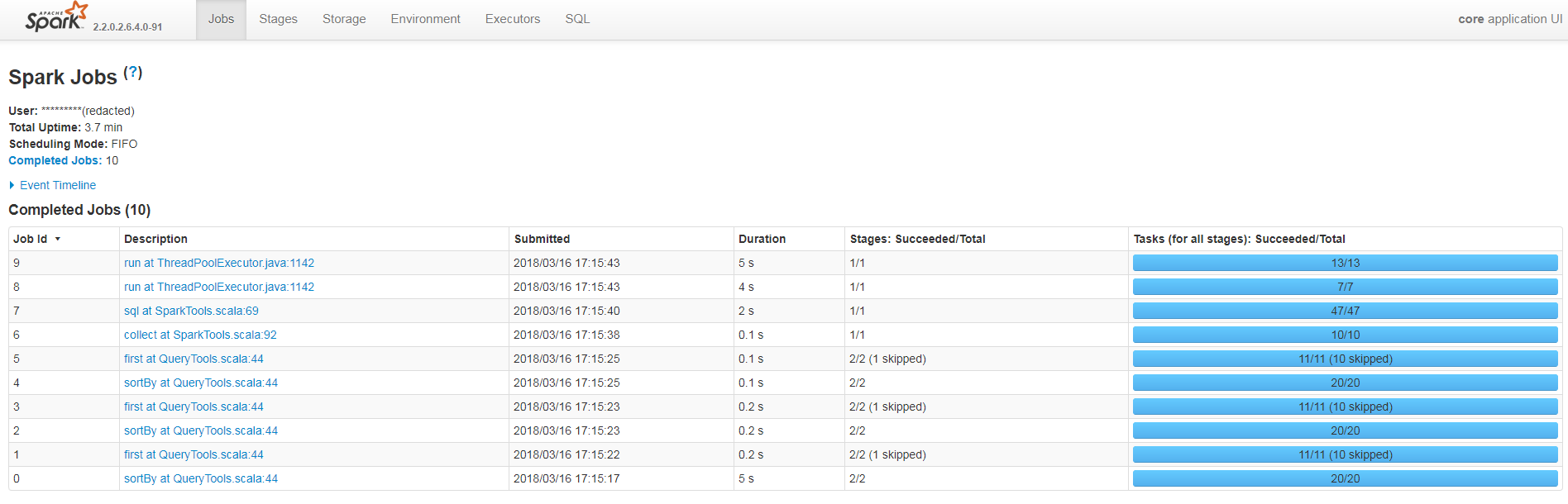
Agréger les logs vers un moteur d’indexation (ELK)
Une autre solution couramment utilisée dans les architectures Big Data est d’envoyer les logs applicatifs vers un moteur d’indexation comme ElasticSearch pour pouvoir ensuite les visualiser et faire des recherches.
Pour ce faire on utilise un shipper de la suite Elastic, tel que LogStash (plus de fonctionnalités) ou Filebeats (plus léger). Ces outils vont permettre d’aller enregistrer les fichiers de logs sur un indexe Elasticsearch.
Une fois les logs ingérés, ils sont ensuite manipulables via une Web UI telle que Kibana profitant de toutes la force d'Elasticsearch dans la recherche full text. On peut également utiliser les indexes Elasticsearch comme back-end pour une Web UI spécifique (avec JHipster par exemple).
Archi Custom sur HortonWorks + UI
Chez notre client actuel, nous avons mis en place une architecture particulière pour répondre à ce besoin. Nous avons en effet comme contraintes d’utiliser seulement des briques technologiques de la stack HortonWorks.
Cette stack contient uniquement des produits open source, recommandé par HortonWorks, dont Elasticsearch ne fait pas partie au contraire de son concurrent open Solr. Bien que sorti avant Elasticsearch et basé également sur Lucene, Solr est bien moins populaire et bénéficie de moins de connecteurs qu’Elasticsearch. Il n’existe par conséquent pas de connecteur Log4J qui permette d’envoyer directement les informations dans Solr à travers Kerberos (qui assure la sécurité au sein du cluster ; plus d’informations sont disponibles dans l'article Wikipédia sur Kerberos).
On passe donc par un topic Kafka, sur lequel un appender Log4J spécifique va écrire les Logs sur les brokers de Kakfa. Les consumers vont ensuite envoyer les données vers un index Solr. Pour visualiser les données, plutôt que d’utiliser Banana (l’équivalent de Kibana pour Solr), nous avons développé notre propre UI pour coller au mieux à notre besoin, les fonctionnalités de Banana étant limitées.
Cette application Web est développée en Spring Boot avec React pour l’interface Web.
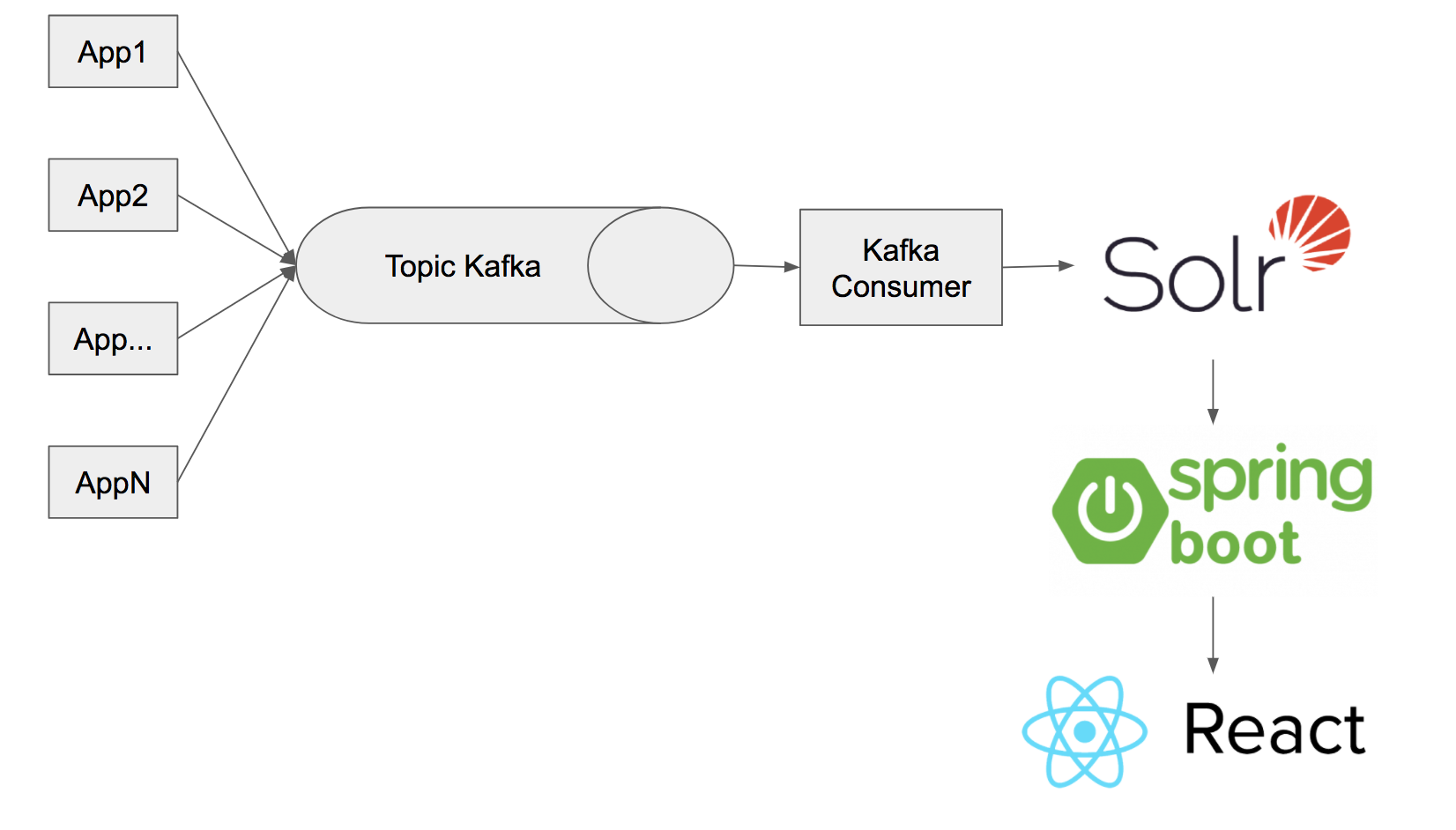
Cette architecture nous permet, à nous développeurs, de facilement manipuler nos fichiers de logs, mais aussi grâce à Kafka de conserver les données dans des topics pendant un mois. Ce qui est peut être très utile si l’ingestion des logs sort en erreur à un moment donné. Cette interface est ensuite mise à disposition pour les autres utilisateurs du Data Lake (data scientists & data analysts) chez notre client.
Gestion des logs infrastructure
Pour les logs d'infrastructure, l'objectif est complètement différent des logs applicatifs. Il ne s'agit plus de comprendre ce qu’il s’est passé pendant notre Job au niveau applicatif, mais quelles ont été les ressources physiques nécessaires (la mémoire utilisée, le % de CPU utilisé, le ratio d’utilisation du garbage collector...).
Au sein d’un environnement basé sur Hadoop, c’est YARN qui s’occupe de faire le lien entre les besoins en ressources nécessaires par l’applicatif et les ressources hardware à disposition. YARN est utilisé par la plupart des technologies de l’écosystème Hadoop (Hive, Spark, MapReduce, etc.). Il ne dépend donc pas de l'applicatif. YARN génère automatiquement des métriques sur l’utilisation des ressources et ce sont elles qui vont nous intéresser pour par exemple comprendre à quel moment et pourquoi notre job Spark part en erreur, car il épuise toutes les ressources disponibles.
YARN Cli & YARN Ui
Nativement, YARN expose une interface utilisateur et une ligne de commande qui permettent de récupérer les logs pour une application ID donnée (ID généré automatiquement pour chaque traitement utilisant des ressources YARN). Cependant, ces logs bruts sont difficiles à interpréter en l’état. Cette solution n’est donc pas satisfaisante.
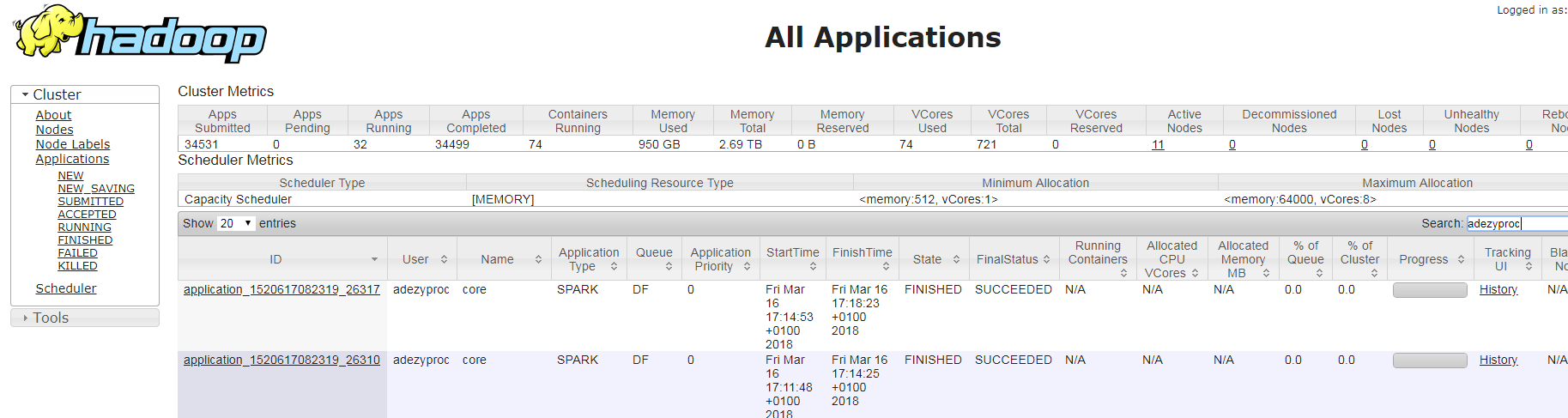
Utiliser une BDD time series
Généralement, pour ces problématiques de métriques, on va chercher à utiliser une base de données dite time series.
En effet, ces métriques sont toujours données en fonction du temps (car à la fin, ce qu’on recherche c’est l’évolution temporelle de notre consommation en CPU par exemple) et bonne nouvelle il existe une catégorie de BDD NoSQL pour cela !
Parmi les principales :
Ces bases de données time series sont souvent associés avec une interface pour visualiser les données. L’outil numéro 1 dans ce domaine étant Grafana, solution Open source de visualisation de séries temporelles pouvant se connecter aux 3 bases de données précédemment citées.
Si vous voulez voir un cas d’application concret d'influxDB et de Grafana je vous conseille l’excellent article d’Alexis Seigneurin sur Kafka streams qui met en en place cette stack pour monitorer son cluster Kafka.
Néanmoins, pour utiliser ces outils, il faut définir soit même les métriques et intégrer un connecteur existant entre le système qui produit les logs et la base de données qui va les stocker.
Babar by Criteo
C’est pour simplifier la solution précédente et automatiser la génération de ces rapports que je vais vous présenter la solution que nous avons mise en place au sein du datalake d’un de nos clients.
Cette solution est très simple et rapide à mettre en place. Elle ne nécessite pas de configuration particulière au niveau du cluster car elle utilise les logs YARN qui sont nativement présents sur le cluster --- il suffit seulement de récupérer deux JARs sur un des edge nodes du cluster et de changer la configuration de Spark Submit)
Cette solution s’appelle Babar et est fraîchement développée par les équipes de Criteo Engineering et est composée de deux parties principales :
- Un Java agent qui est placé au niveau des JVM de chaque exécuteur et qui va permettre d’écrire des métriques spéciales au niveau des logs YARN.
- Un programme Java qui, à partir du fichier de log YARN, va générer deux pages HTML : une avec les graphiques de consommation de ressources et une autre avec les couches de dépendances utilisées par le programme.
Babar se basant intégralement sur YARN, il est capable de générer ces rapports pour toute application qui utilise YARN dans notre gestionnaire de ressources (Hive, Map Reduce...), même si dans notre exemple nous allons nous concentrer sur Spark uniquement.
Commencez par cloner le projet depuis le GitHub de Criteo.
On va tout d’abord s’intéresser au dossier “babar-agent”. Pour packager un JAR, utilisez l'instruction mvn clean package. Une fois le JAR assemblé, uploadez-le sur votre edge node d’où vous lancez habituellement votre job Spark.
Il va falloir ensuite modifier la commande spark submit utilisée habituellement en rajoutant deux options :
--filesqui va permettre de propager le JAR de babar-agent sur chacun des exécuteurs.--confpour définir des extraJavaOptions sur les exécuteurs (le Java agent dans notre cas)
--files $PATH_BABAR/babar-agent.jar \
--conf spark.executor.extraJavaOptions="-javaagent:./babar-agent.jar=StackTraceProfiler[profilingMs=100,reportingMs=60000],MemoryProfiler[profilingMs=5000,reservedMB=7175],CPUTimeProfiler[profilingMs=5000]" \
Après avoir exécuté spark submit, de nouvelles métriques ont été écrites sur les logs YARN.
C’est là qu’intervient la deuxième partie du programme “babar-processor”. Il faut, comme pour le premier JAR, le packager avec Maven et l’uploader sur le edge node. Il faut récupérer l’application ID du job qui vient d’être exécuté (présent dans les logs applicatifs, sur les UI de spark history server ou celles de YARN)
Récupérer le fichier de log sur le edge node depuis YARN.
yarn logs --applicationId <Application_id> > myJob.log
Puis exécuter le babar processor pour créer les rapports HTML.
java -jar /path/to/babar-processor.jar -l myJob.log
La création de ces rapports est facilement automatisable soit dans un script Shell qui encapsule le lancement du Spark Submit ou bien avec un ordonnanceur type Oozie ou Airflow
Un fichier output sera généré contenant deux pages Webs : une première page sur l’utilisation de la RAM et du CPU via divers graphiques.
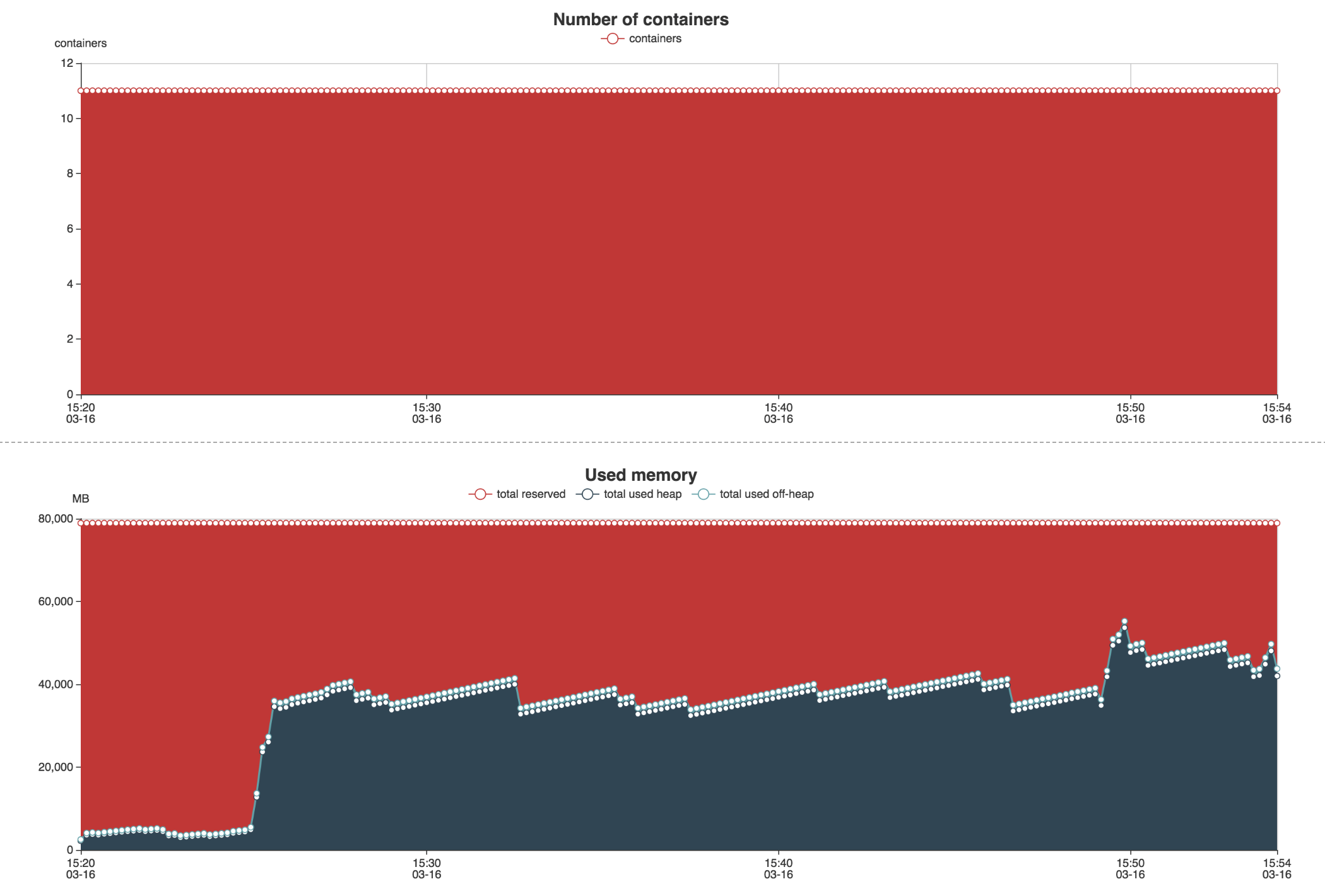
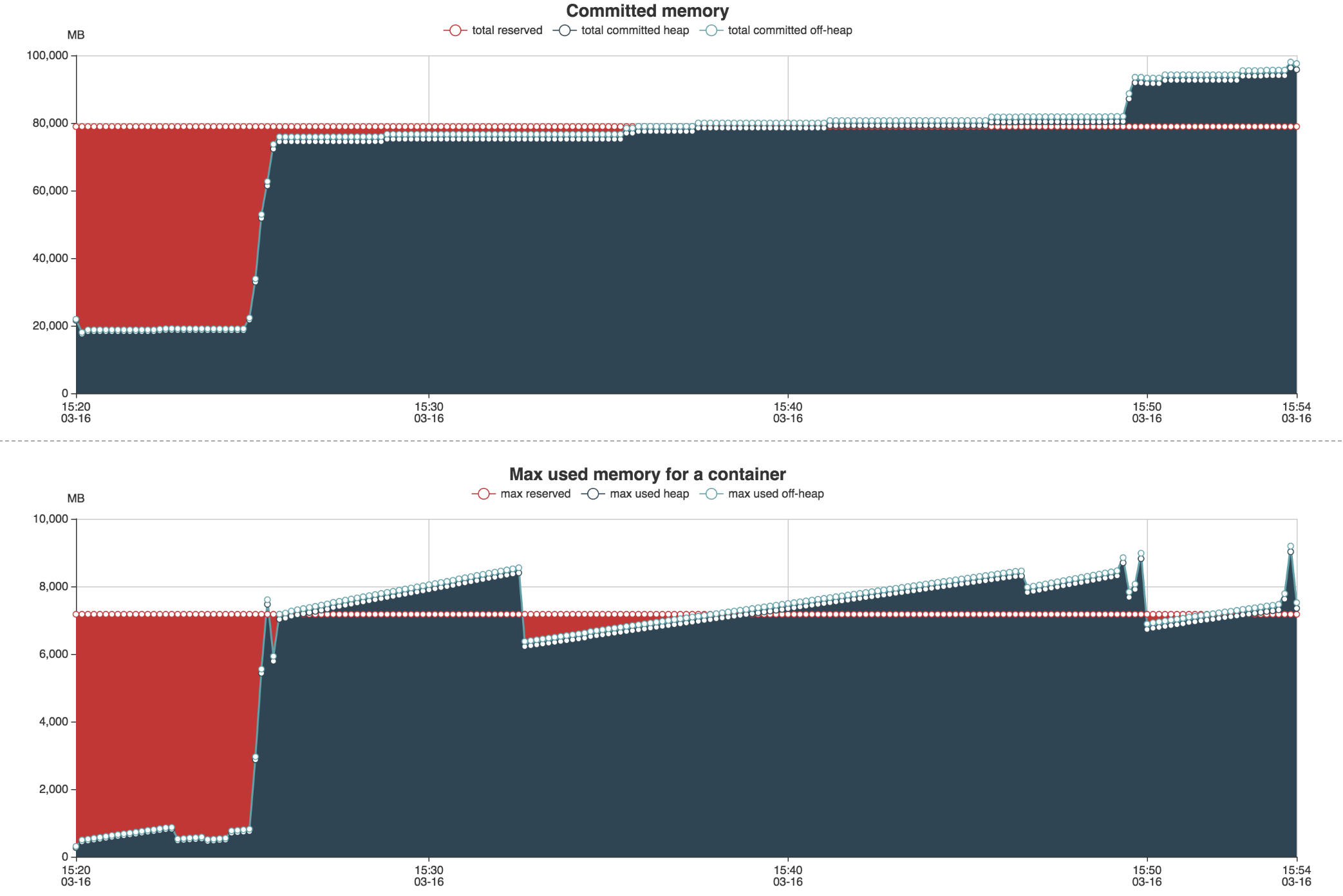
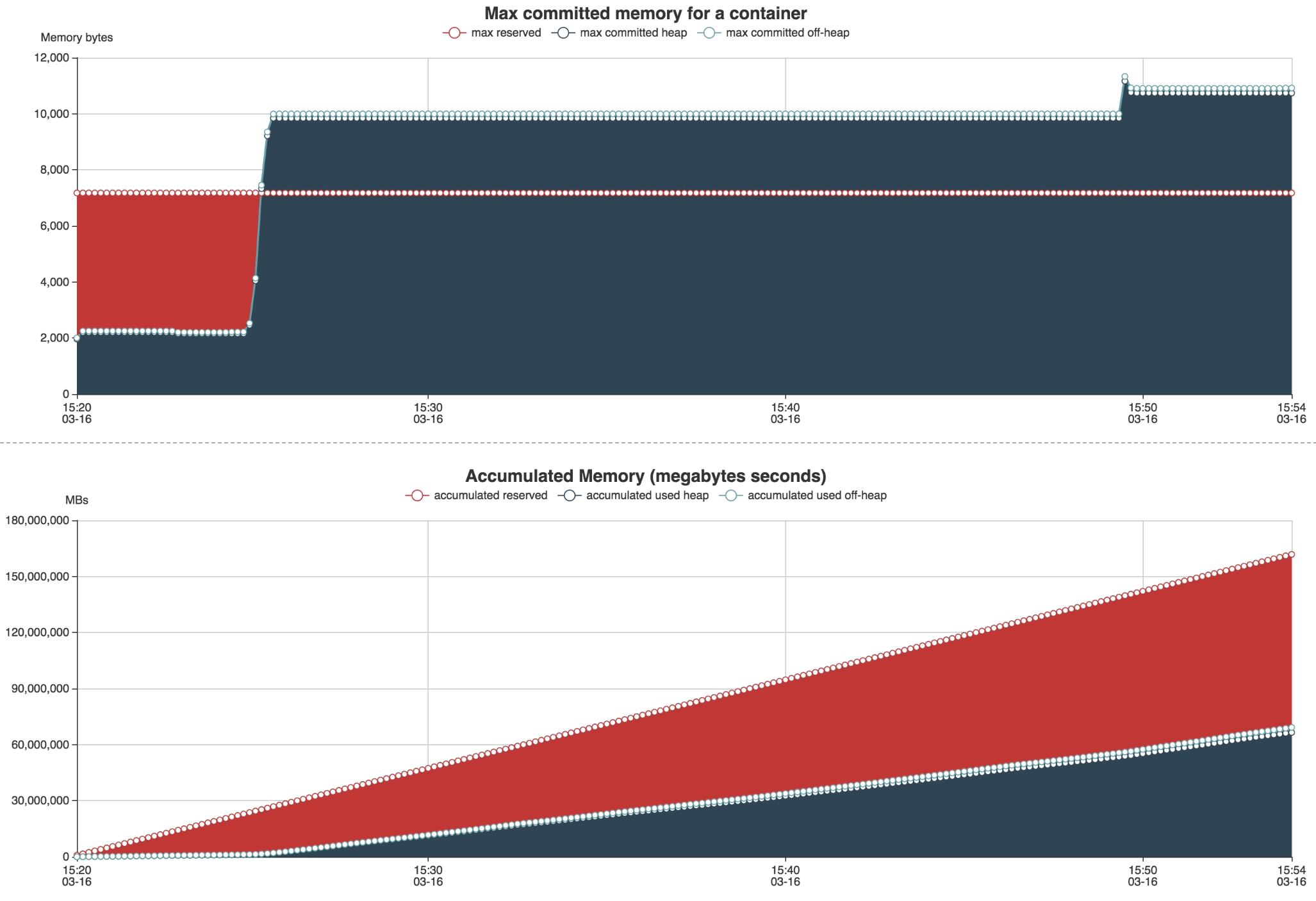
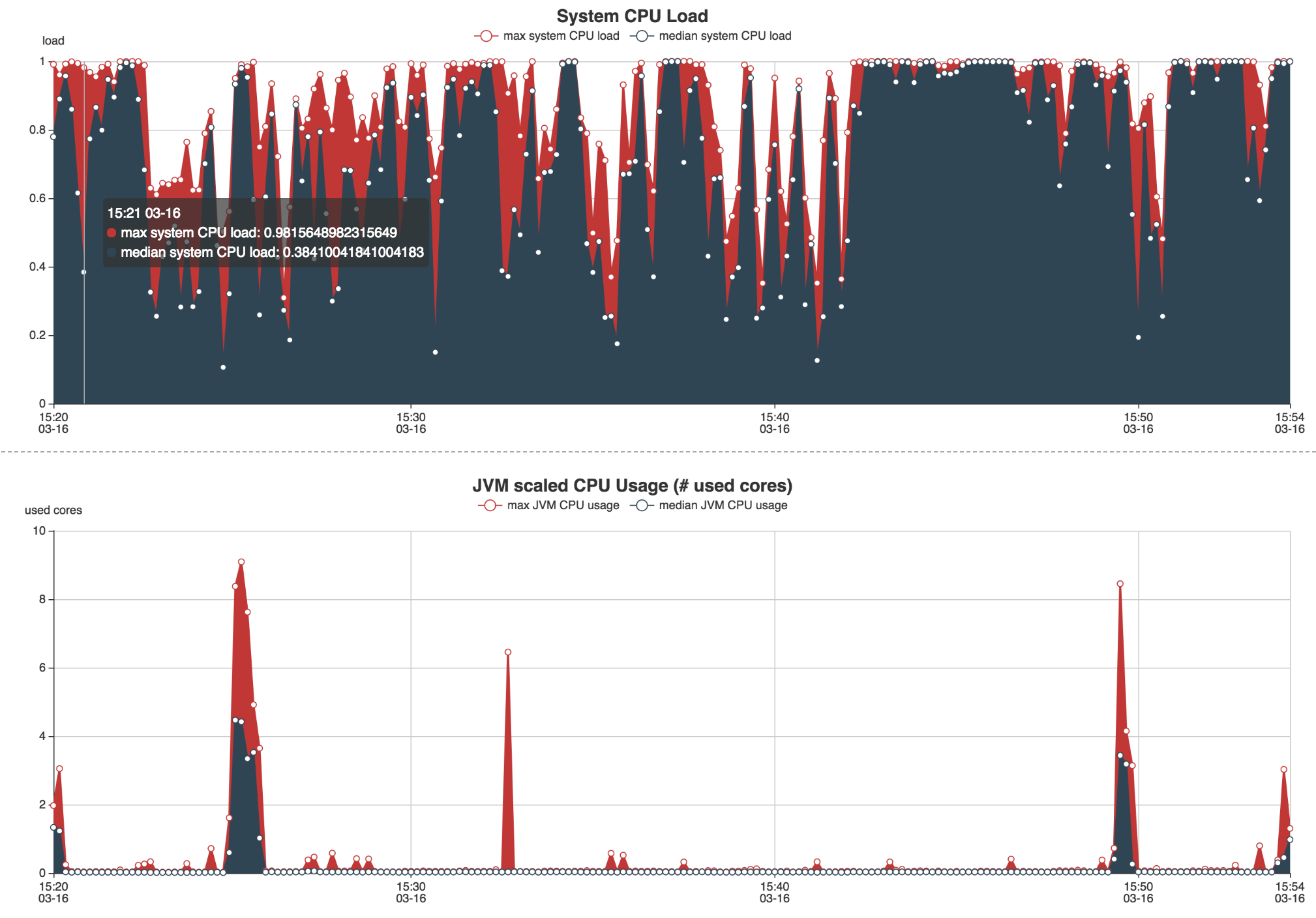
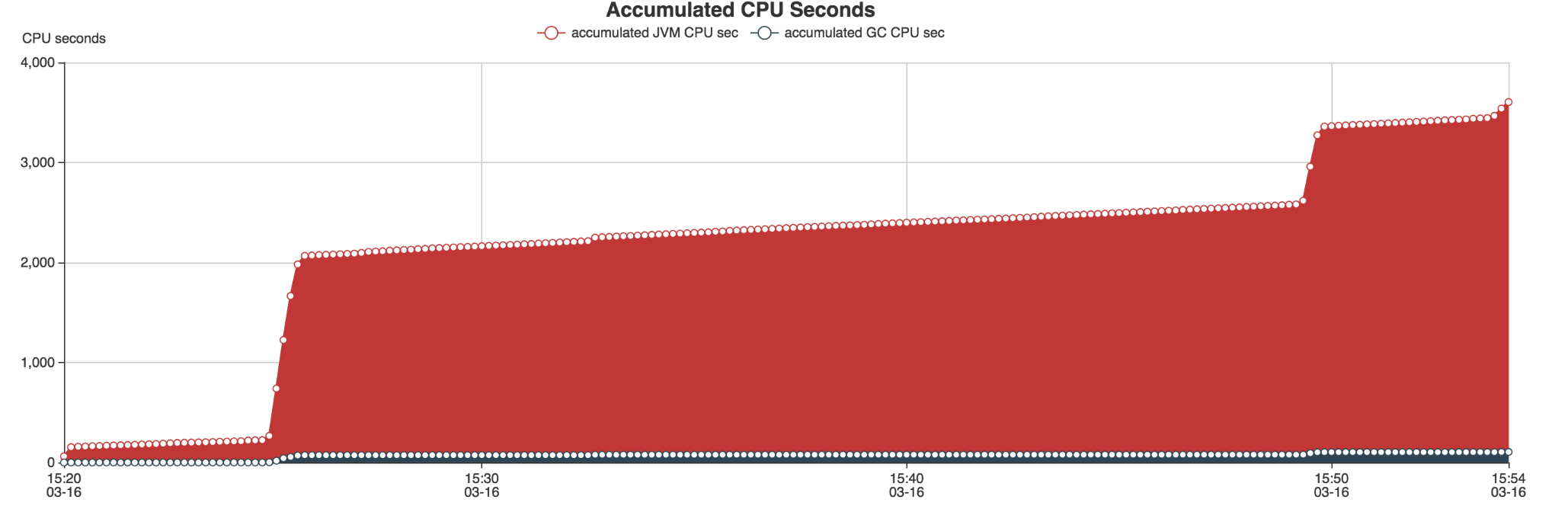
Babar nous permet de générer des rapports automatiquement à chaque lancement de nos jobs, au même titre que le fichier de log applicatif. Il nous permet de surveiller l’exécution de nos Jobs Spark en vérifiant qu’une nouvelle feature ne fait pas exploser la consommation de ressources. Nous utilisons cet outil pour affiner les options de lancement de notre spark submit (nombre d'exécuteurs, RAM par exécuteurs, nombre de partitions, etc.).
Babar étant un outil qui vient d’être récemment open sourcé par Criteo il reste relativement stable. On peut imaginer que de nouvelles features viennent au fur et à mesure :)
Un bémol cependant : cet outil est très orienté batch et marche uniquement sur un cluster Hadoop. Dans le cas où l’on souhaiterait faire le même monitoring pour Kafka Streams par exemple, on ne pourrait pas employer cet outil car Kafka n’est pas basé sur YARN et utilise de simples JVM comme ressources de calcul avec Zookepeer pour la gestion de clusters.
D’autres outils existent pour adresser cette problématique. Le plus connu d’entre eux étant Dr Eléphant, développé par Linkedin et qui expose une interface Web pour monitorer ses Jobs Sparks.
Conclusion
La gestion des logs de traitements distribués sur un Data Lake Hadoop est un sujet central pour pérenniser les développements et aider les ingénieurs à développer, au même titre que le data lineage évoqué dans un précédent article.
En effet, ces outils vont permettre de suivre l’évolution de nos développements au cours du temps et d’être en mesure de pouvoir analyser à la fois l’applicatif et l’infrastructure, le jour où nos traitements partent subitement en erreur à la suite d’une nouvelle fonctionnalité ou d’une montée de version sur le cluster, par exemple :)
C’est aussi un bon moyen de peaufiner les configurations des options du job Spark de manière itérative pour pouvoir choisir le meilleur ratio temps d’exécution / consommations de ressources.
Twitter : @lulufrego
