
Cet article présente un retour d’expérience sur une industrialisation de jobs Spark dans le cadre d’un datalake. Nous allons découvrir le but de l’industrialisation et les problèmes que nous avons résolus avec notre approche.
Qu’est-ce qu’un datalake ?
Un datalake est une solution de stockage permettant de sauvegarder une très large quantité de données brutes en format natif pour une durée indéterminée. L'intérêt d’un datalake est de pouvoir recevoir des données de sources et de formats très différents au même endroit et ainsi casser les silos entre les métiers.
Contexte
Afin de répondre à ses besoins, notre client a mis en place un datalake pour stocker et traiter des données provenant de sources très diverses. Ce datalake est construit sur Hadoop et HDFS (Sans distribution) ainsi que sur Azure (HDInsight) dans un second temps. Le client utilise Spark pour effectuer les traitements sur les données et possède un Apache Drill permettant de requêter sur l’ensemble des données présentes.
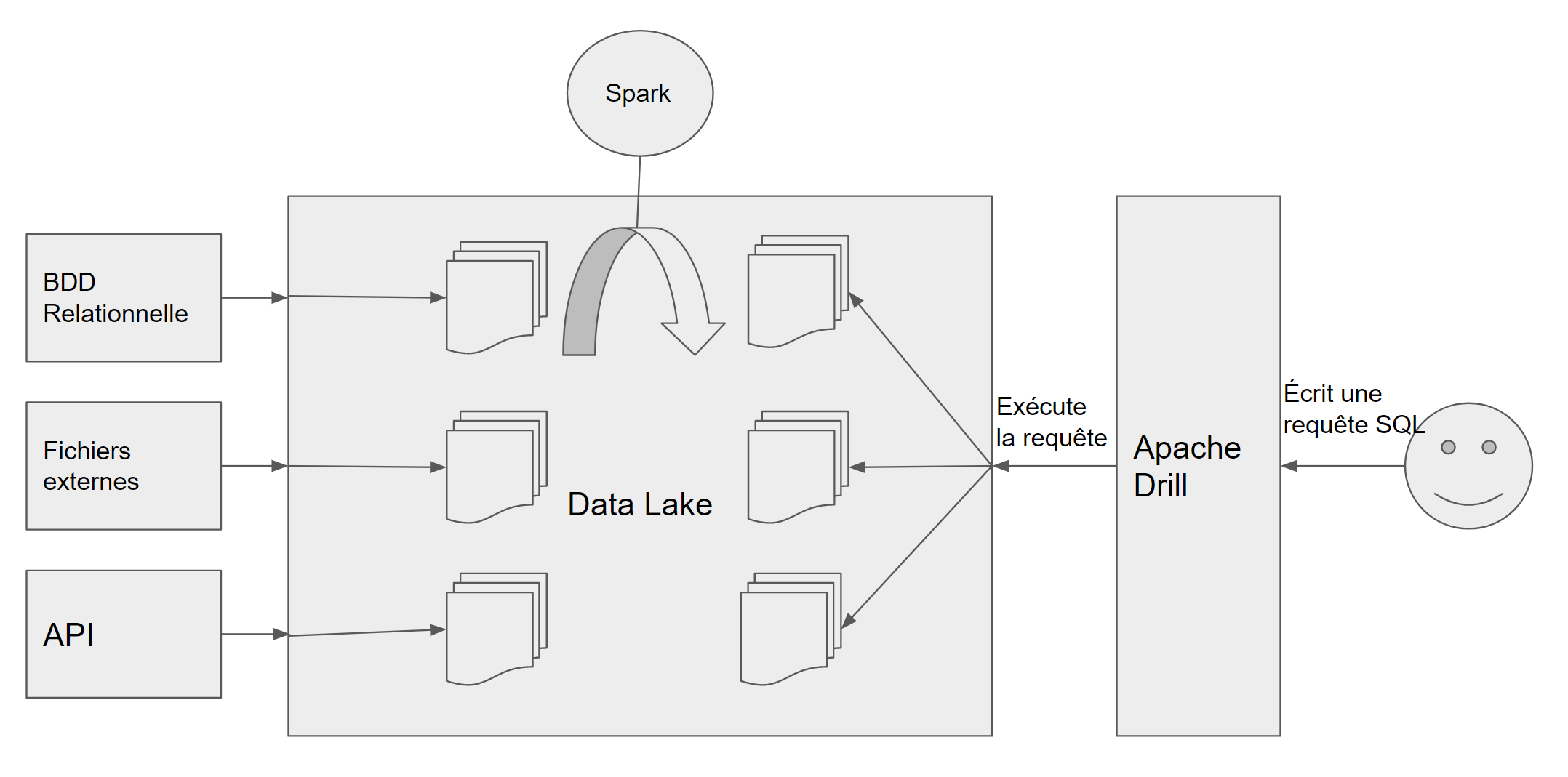
Architecture du datalake
Dans le but de maîtriser les développements, nous avons mis en place une industrialisation des jobs Spark de transformation de données et des jobs écrits par les data scientists. Le client développant des applications en Java, l’ensemble des jobs Spark et de l’industrialisation sont réalisés dans ce langage.
Industrialisation
Les objectifs de l'industrialisation sont multiples :
-
Maîtriser l'environnement de développement des data engineers et data scientists, afin de ne pas se retrouver avec des développements disparates au sein des équipes.
-
Mettre en place un cadre de développement à la fois simple pour le développeur mais aussi répondant à un maximum de problématiques de data engineering. Par exemple, afin de pouvoir étudier les différentes étapes de transformation dans un job Spark, nous avons mis en place une méthode de débuggage qui, si le paramètre est défini lors du lancement du job, écrit sur le disque les datasets intermédiaires.
-
Gérer automatiquement les problématiques communes à tous les jobs telles que la gestion du catalogue de données et du data lineage pour coller aux exigences du RGPD et de gouvernance des données.
-
Gérer automatiquement la configuration d'exécution des jobs sur des environnements différents (local, on premise, cloud Azure… ) et la configuration par défaut des jobs. De plus, le packaging des jobs (création de jar prêts à l’emploi pour spark-submit, c’est à dire contenant l’ensemble des dépendances sans Spark) est géré pour le développeur.
-
Éviter les problèmes qui pourraient survenir ; en effet, sans industrialisation, on risque de se retrouver avec des jobs disparates au niveau du code (par exemple sur la hiérarchie des classes différentes, sur la structure de job devenant alambiqué ou même sur la qualité du code pouvant être inégale), mais aussi de l’approche des problématiques et ainsi s’exposer à des erreurs lors de l'exécution du job.
-
Fournir une aide au niveau des tests unitaires : l’intégration d’un framework de test permettant de comparer le contenu de deux dataframes, avec un formatage intégré directement avec l’IDE.
Ainsi, avec un job industrialisé, on s’assure la reproductibilité et la qualité du job, ainsi que la simplification de son écriture en cachant la complexité des configurations et des appels redondants au SI du client.
Architecture
Core
Pour mettre en place cette industrialisation, nous avons créé un projet nommé "spark-parent" qui sera le projet parent de tout job, c’est à dire que notre job héritera de toutes nos classes utilitaires. Il contient des modules permettant de gérer la configuration, mais aussi les appels au catalogue de données (qui était chez nous un outil fait maison, propre au client, mais on peut intégrer des solutions tels Apache Atlas ou Spline par exemple) ou encore la gestion de la session selon l’environnement d'exécution.
Nous avons créé un module core, qui sera le coeur de l’application, contenant une classe SparkApplication gérant le lancement de notre job, ainsi que la classe principale SparkRunner, de laquelle tous nos jobs héritent. Cette architecture est fortement inspirée du framework SpringBoot dans son fonctionnement.
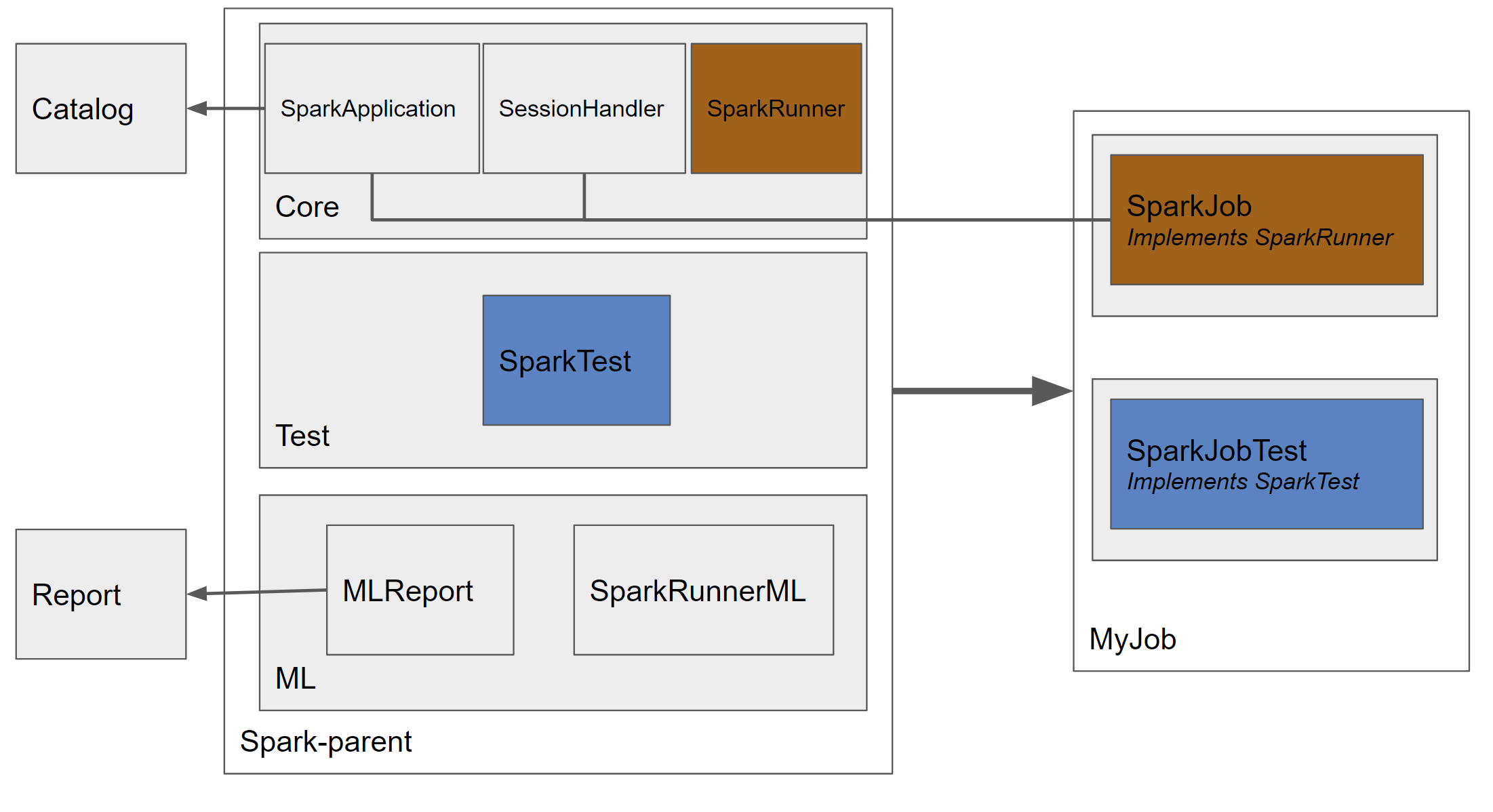
Architecture du projet spark-parent
La classe SparkApplication nous permet de cacher les complexités du lancement du job Spark (Gestion de l’environnement, des paramètres du job et de l’application, gestion de l’envoi des données dans le catalogue…). Elle gère la configuration et le lancement des jobs : elle va s'instancier différemment selon le mode de lancement (inféré à partir de l’environnement), entre local, standalone, yarn ou cloud. Cela permet ainsi au data engineer de s’affranchir de développements spécifiques selon l’environnement cible. Ainsi, devant développer sous Windows, nous avons embarqué et automatiquement configuré l'exécutable winutils et la variable HADOOP_HOME, évitant les soucis liés à cette plateforme.
Cette classe, à l’instar de la classe SpringApplication dans le framework Spring boot (cf), gère le lancement du job (à détailler)
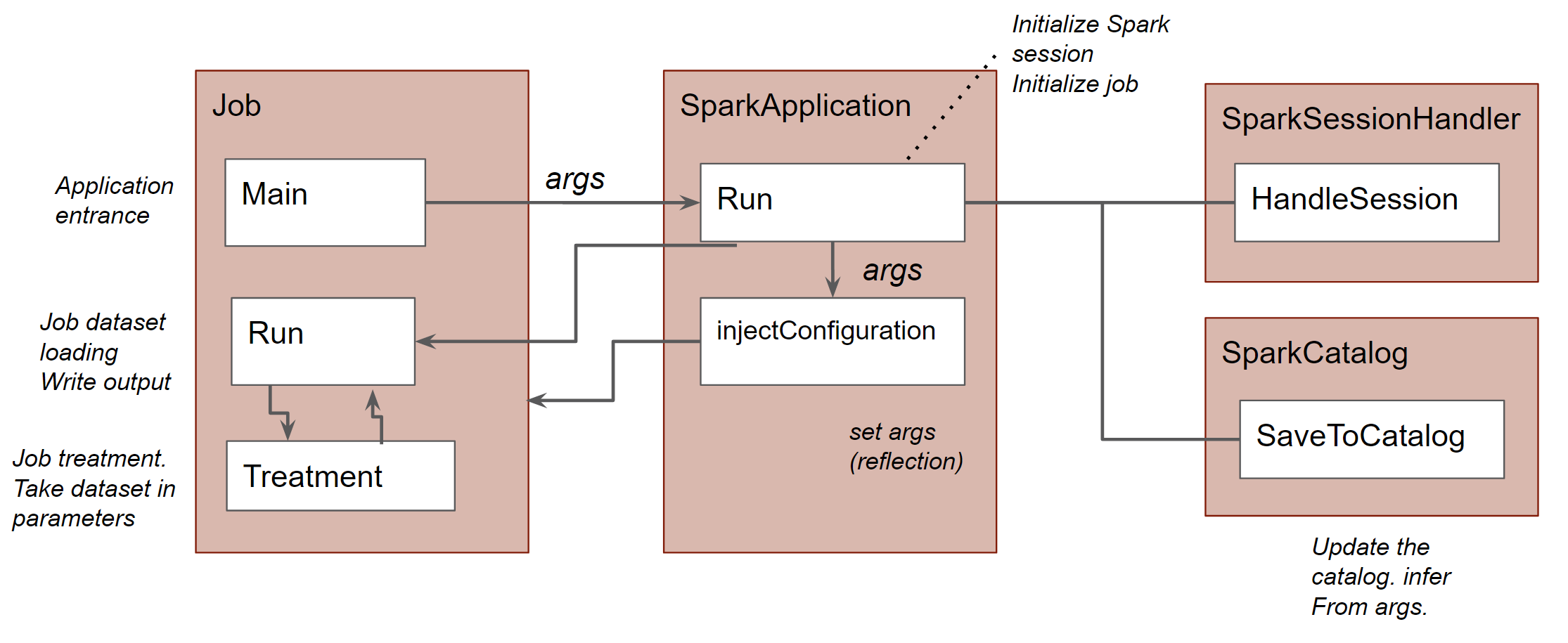
Utilisation du projet
Afin de créer un job, il suffit de créer une classe qui hérite de "SparkRunner". La classe de notre job contient une méthode main, permettant de lancer le job de manière unitaire et qui initialise l’ensemble à l’aide de la fonction run de SparkApplication. La seconde méthode de l’interface est run, qui est la méthode appelée par SparkApplication une fois l’application initialisée : elle contient l’initialisation des datasets et la lecture des fichiers d’entrée, l’appel à la méthode treatment et l’enregistrement du dataset de sortie. La méthode treatment contient simplement le code métier du job : elle prend en entrée les datasets nécessaires et retourne le dataset de retour. Cela permet de tester facilement ce code métier ainsi que de pouvoir simplement enchaîner les jobs, prenant les datasets de sortie des jobs précédents en entrée du job suivant par exemple.
Machine learning
Lors de la mise en place de l’industrialisation, le client avait deux buts : rationaliser et intégrer les développements de l’équipe de datascientists à ceux des data engineers. Automatiser certaines de leurs tâches a permis une mise en place de cycles plus agiles, dans un esprit d’intégration continue.
Cela a été possible en construisant un outil permettant d'exécuter un job de machine learning, créer le modèle de machine learning, exécuter une validation du modèle, mais aussi obtenir des métriques sur le modèle ainsi créé (Courbe de lift, table des quantiles, importance des variables par exemple dans le cadre d’un algorithme de random forest).
Au final, les algorithmes écrits en Spark R par les data scientists étaient recopiés en Java par un data engineer afin de finir industrialisés. Cette recopie consistait à recréer le pipeline de machine learning créé en Spark R.
Outils
Afin de suivre au mieux la qualité des jobs Spark, nous avons créé des outils de gestion de la qualité :
-
Outil de reporting de qualité sur une table, permettant de voir le taux de remplissage des différents champs de la table (si le champ est null, vide ou rempli) ou les différentes valeurs possibles d’un champ en particulier. Pour ce dernier point, un diagramme de répartition est disponible pour les champs ayant moins de 10 valeurs possibles.
-
Framework de test générant un rapport automatique, pouvant être écrit par une personne de la cellule de qualité, permettant de tester si les fichiers générés n’ont pas de soucis fonctionnels par exemple. En écrivant dans un fichier json une requête SQL telle que celles écrites dans Apache Drill, les fichiers en entrée et la valeur de sortie souhaitée, l’application sort un rapport à la manière des tests unitaires : tests ok ou ko avec un récapitulatif de ces tests.
Ces Outils ont été écrits en quelques jours et ont permis à la fois au métier de voir quels problèmes existent sur leurs données et de pouvoir facilement tester les critères d’acceptation.
Les étapes suivantes
Certaines parties de l’industrialisation ne nous satisfaisant pas, nous avons des points que nous voulons améliorer :
-
Gestion des sous-jobs, c’est-à-dire de pouvoir enchaîner plusieurs jobs Spark pouvant se lancer indépendamment. Actuellement, l'enchaînement de jobs est géré, mais pas de manière convenable, c’est-à-dire que l’on a besoin de trois lignes de code pour exécuter un sous job : exécution du job, récupération du résultat et écriture sur disque. Nous voudrions mettre en place un enchaînement à la manière des transformations spark qui s'enchaînent et ainsi améliorer la lecture du job.
-
Utiliser de manière plus fine le logical plan de Spark (le plan d’exécution optimisé) afin de l’utiliser dans la gouvernance de données (data lineage, gestion de l’anonymisation…), avec l’utilisation de Spline par exemple.
Conclusion
La mise en place de cette industrialisation a permis de se détacher des différentes complications liées à la configuration et de se focaliser sur les développements métiers des jobs. De plus, l’ajout des tests unitaires et du reporting ont amélioré la qualité des réalisations. Ainsi, nous avons noté une augmentation de la productivité des data engineers et des data scientists, réduisant le temps passé et homogénéisant l’écriture des jobs.
Si j’avais à refaire cela chez un autre client, j’irais chercher plus du côté des solutions open source pour la résolution des problématiques notamment de data lineage avec Apache Atlas ou Spline. Nous avons commencé à travailler sur une version open source du projet : Sparkle.
