

Introduction
L’objectif de cet article est de constituer une sorte de cahier des charges d’un outil de gouvernance qui nous permettra ensuite, dans un second article, de comparer des outils de gouvernance de données.
Commençons par définir ce que nous appelons la gouvernance des données.
La gouvernance, c’est le pilotage de la décision. En ce qui concerne les données, il s’agit donc de piloter toutes les décisions qui concernent les données. J’aime bien la définition donnée sur le site definitions-marketing.com :
La notion de gouvernance des données désigne l’organisation et les procédures mises en place pour encadrer les pratiques de collecte et d’utilisation des données au sein d’une organisation. La gouvernance des données vise à optimiser l’efficacité de l’usage des données dans le respect d’un cadre juridique et déontologique.
Détaillons plusieurs termes de cette définition :
- Organisation : il s’agit d’identifier des rôles, et pas forcément les personnes, responsables de la gouvernance.
- Procédure : c’est pour supporter ces procédures que nous allons avoir besoin d’outils de gouvernance de données.
- Collecte : les sources de données et la façon dont on les collecte (avec ou sans l’accord des individus par exemple) est un élément clé de la gouvernance.
- Utilisation : il faut donc savoir pour quelles finalités et dans quels traitements les données sont utilisées.
- Optimiser l’efficacité : la gouvernance de données n’apporte pas que des contraintes, elle représente aussi une opportunité d’améliorer son utilisation des données.
- Respect d’un cadre juridique et déontologique : il existe des réglementations (nous parlerons du RGPD) autour de la gestion des données, auxquelles s’ajoutent des règles déontologiques qu’il faut s’imposer quand on manipule des données personnelles.
Quel rapport avec le RGPD ?
Je n’ai pas l’ambition de vous présenter en détail le Règlement Général sur la Protection des Données personnelles.
Vous trouverez beaucoup de ressources sur le Web pour le découvrir, parmi lesquelles je vous recommande l’excellente vidéo de Samson GDPR / RGPD expliqué en emojis.
L’article de la CNIL RGPD : se préparer en 6 étapes donne également une bonne vision des enjeux de cette nouvelle règlementation.
Ce qu’il faut en retenir, c’est qu’à partir du 25 mai 2018, toutes les entreprises dans le monde qui manipulent des données personnelles de résidents Européens seront soumises à une réglementation spécifique.
Cela signifie qu’il faut mettre en place dès à présent une gouvernance de données avec, par définition, une organisation et des procédures qui permettront de garantir le respect de cette réglementation.
Dans l’article de la CNIL, on voit apparaître la notion de cartographie des traitements. Cette cartographie doit aussi s’appliquer aux données et fera l’objet d’un chapitre dans la suite de cet article.
Mais parlons d’abord de l’organisation de la gouvernance des données.
Qui sont les acteurs de la gouvernance des données ?
Qui dit organisation, dit identification de rôles chargés de définir, d’appliquer et de suivre les procédures qui seront mises en place.
La RGPD impose le rôle de Data Protection Officer qui sera juridiquement responsable de la protection des données. Ce rôle sera sans doute supporté par une personne, du service juridique de préférence, avec une affinité forte pour les sujets centrés sur les données (stockage, traitement, sécurité, …).
Profitons de la mise en place de la gouvernance pour identifier un Chief Quality Officer qui s'intéressera particulièrement à la définition et au respect des procédures de mise en qualité des données. C’est un prérequis majeur pour rendre possible la création de valeur à partir des données. Ce rôle peut être porté par le Chief Data Officer ou par une équipe entière dans le cas des grosses organisations.
La responsabilité de la bonne cartographie des données pourra être portée par les Data Owners qui sont souvent les utilisateurs métiers responsables des domaines fonctionnels producteurs des données. Ils pourront s’appuyer sur les Data Stewards pour réaliser la cartographie des données.
Enfin, en ce qui concerne la cartographie des traitements, le rôle pourra être partagé entre les Enterprise Architect et les Data Architect qui définiront les informations à cartographier et s’assureront auprès des Data Engineers que cette cartographie est réalisée et maintenue à jour.
Tous ces rôles n’impliquent pas nécessairement l’ouverture de nouveaux postes dans l’entreprise, mais peuvent reposer sur les équipes existantes.
Maintenant que nous avons vu qui se chargera de la cartographie, voyons les informations qu’il s’agit de collecter autour des données et des traitements.
Quelles informations doit-on cartographier ?
Sur les données
Sur les données, l’objectif est de réaliser une cartographie sémantique des données.
C’est-à-dire qu’on veut identifier les éléments suivants :
- identification métier de la donnée : à quoi elle sert au sens métier,
- rattachement à un domaine fonctionnel,
- identification technique de la donnée : quel est son nom technique dans la source de données (par exemple, nom du champ dans SAP),
- source de la donnée : chemin complet pour accéder à la donnée (s’il s’agit d’une donnée issue d’une base relationnelle, on voudra connaître le nom du schéma, de la table et du champ),
- confidentialité de la donnée : est-ce qu’elle peut contenir des informations personnelles.
Il s’agit bien là de métadonnées, c’est-à-dire de données qui décrivent les données. Il n’est pas question de stocker les données elles-mêmes dans le catalogue. C’est pour cela qu’on parle de cartographie sémantique.
À partir de ces informations, on doit pouvoir construire deux visions du catalogue de données :
- une vision métier qui sera alimentée et consommée par les équipes métiers (data owner, data steward, etc.),
- une vision technique qui sera plus à destination des data engineers.
C’est la combinaison de ces deux visions qui permet d’avoir une vue consolidée des données stockées dans un SI. Cette vue doit pouvoir vivre au cours du temps et être enrichie lors de l’intégration de nouvelles sources de données.
Sur les traitements
Concernant les traitements, nous avons besoin d’inventorier les informations suivantes :
- le flux de données : source et cible du traitement,
- les transformations : toutes les transformations appliquées à la donnée au cours du traitement.
Par exemple, on pourra retrouver les traitements suivants : mise en qualité, anonymisation, dé-duplication, etc.
Un outil puissant : Le Data Lineage
On appelle Data Lineage la traçabilité du cycle de vie d’une donnée de son état initial (sa source), jusqu’à son état final (sa destination) en passant par toutes les transformations qui ont eu lieu entre les deux.
L’objectif final est d’avoir une vision précise des données que l’on stocke et de la manière dont on les utilise à l’échelle du SI.
Si on observe la cartographie du point de vue d’un traitement, on doit voir quelles données sont concernées par ce traitement et pouvoir faire ainsi une étude d’impact très rapidement.
Par exemple, si une anomalie du traitement a provoqué une corruption des données, on peut savoir quelles données sont potentiellement concernées.
Si on observe la cartographie du point de vue d’une donnée, on doit pouvoir suivre de quel jeu de données unique, ou multiples s’il s’agit d’une jointure, cette donnée est issue. Ainsi, on peut analyser rapidement les impacts d’une modification de jeu de données source en retrouvant rapidement les données qui en sont issues.
L’idéal est de pouvoir naviguer dans le data lineage comme dans un graphe de données, de type arbre généalogique. Je vous montrerai des exemples de cette représentation dans le second article.
Pourquoi cette cartographie est si importante ?
Dans le monde des bases de données relationnelles, où la modélisation des bases de données était maîtrisée et compréhensible, la cartographie les données était éventuellement gérée au niveau du S.I., par les architectes d’entreprise.
À l’exception de quelques sociétés qui avaient compris l’enjeu de la gouvernance des données, on se contentait d’un modèle conceptuel et / ou physique des données, qui était rarement maintenu à jour.
Les outils d’architecture d’entreprise étaient assez lourds et rarement mis à disposition de toute l’équipe.
Avec les ETL et les bus de services, on a ressenti la nécessité de cartographier les flux de données, mais aucune méthode ne s’est vraiment imposée et chacun faisait de son mieux.
On sentait bien qu’il y avait un réel intérêt à faire ce travail qui restait malheureusement généralement à l’état d’ambition.
Avec l’utilisation de plus en plus fréquente de lacs de données, où les données sont plus ou moins structurées, nous avons besoin de nous outiller pour cartographier les données.
La multiplication des interactions avec ces données nécessite également un outil qui permette d’inventorier ces traitements.
L’aspect positif de la contrainte apportée par le RGPD est d’insister sur la responsabilité juridique relative au stockage des données personnelles et aux traitements qui les exploitent. Il faut donc voir le RGPD comme une opportunité pour faire rentrer la gouvernance des données dans les organisations.
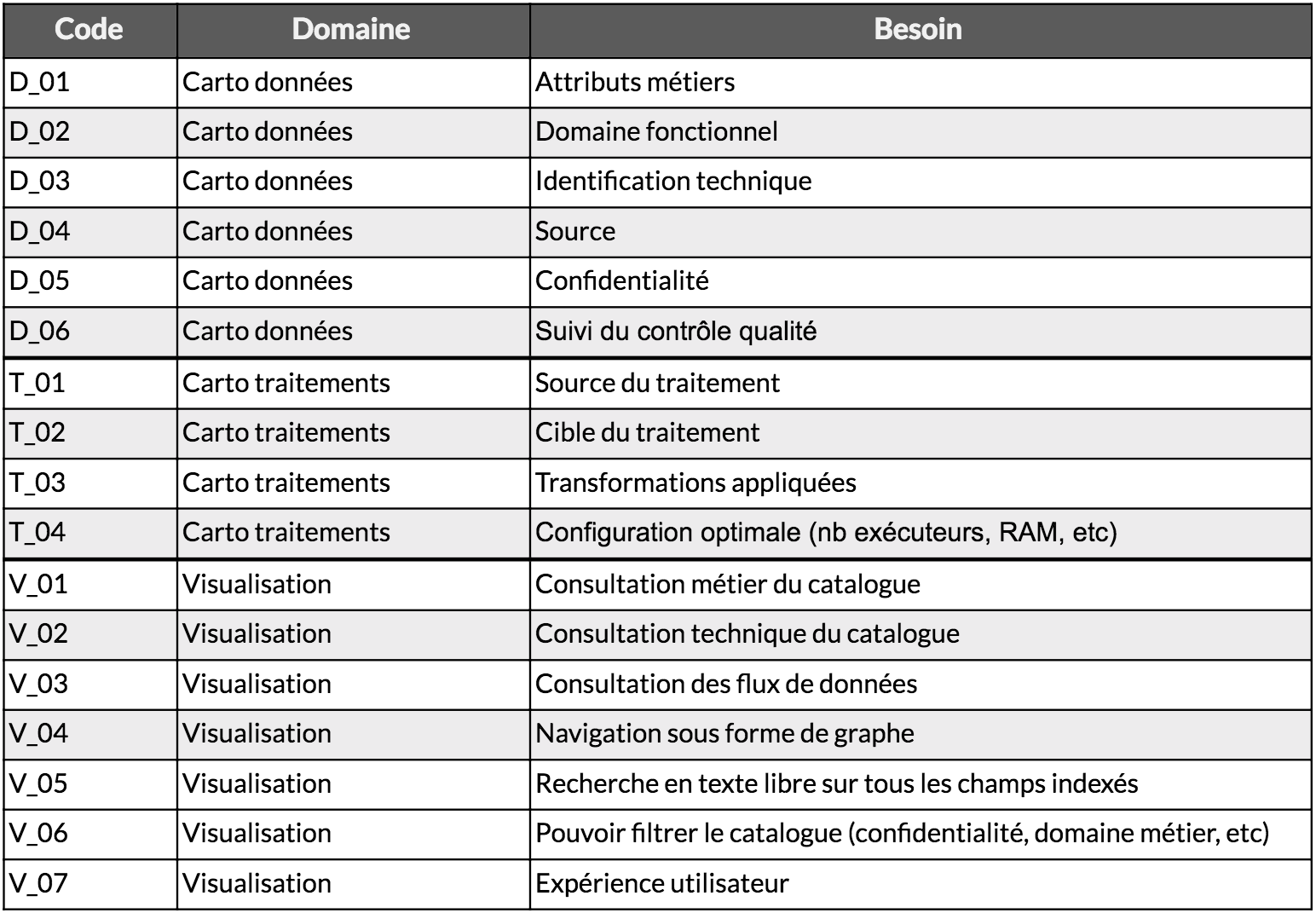
Matrice d’exigences
Voici une matrice qui va nous permettre d’organiser les exigences disséminées dans cet article en faisant des regroupements selon le domaine concerné :
- la cartographie des données,
- la cartographie des traitements,
- la visualisation de ces informations.
Un code est attribué à chaque exigence. Il nous sera utile dans le second article où nous comparerons les outils disponibles en leur attribuant une note pour chaque exigence.
Conclusion
Cet article avait pour seule ambition d’introduire les notions de cartographie des données et des traitements qu’on peut attendre d’un outil de gouvernance de données.
Dans un second article, nous allons étudier l’offre logicielle actuelle au regard des exigences que nous avons listées dans la matrice précédente.
