

Spring Data JPA fournit une implémentation de la couche d’accès aux données pour une application Spring. C’est une brique très pratique car elle permet de ne pas réinventer la roue de l’accès aux données à chaque nouvelle application et donc de se concentrer sur la partie métier. Il y a quelques bonnes pratiques à respecter lors de l’utilisation de Spring Data JPA : par exemple, limiter le chargement des objets inutiles pour optimiser les performances.
Dans ce but, cet article donnera quelques conseils afin de réduire les aller-retours vers la base de données, de ne pas récupérer l’ensemble des éléments de la base de données et de ce fait ne pas impacter les performances globales de l’application. Pour cela, nous verrons dans un premier temps les différents outils que Spring Data JPA nous offre pour améliorer le contrôle de l’accès aux données, ainsi que quelques bonnes pratiques afin de réduire l’impact qu’aura la récupération des données sur notre application. Ensuite, je vous ferai part d’un retour d’expérience qui sera un exemple concret de l’amélioration des performances d’une application Spring en jouant sur ces différents aspects et en réduisant ainsi les problèmes sous-jacents.
Le chargement des relations d’entités
Un peu de théorie : les types de chargement EAGER et LAZY
Lors de la création d’une application utilisant Spring Data JPA (et plus globalement Hibernate), les dépendances d’un objet (par exemple l’auteur d’un livre) peuvent être chargées de façon automatique (chargement EAGER) ou manuelle (chargement LAZY).
Dans le cas d’une dépendance de type EAGER, à chaque fois que l’on va charger un objet, les objets en relation seront également chargés : lorsque l’on demande les informations d’un livre, les informations de l’auteur seront également récupérées. Dans le cas d’une dépendance de type LAZY, seules les informations de l’objet demandé seront chargées : on ne récupérera pas les données de l’auteur.
Dans Spring Data JPA, une relation entre deux objets du domaine possède l’une ou l’autre de ces méthodes de chargement des données. Par défaut, la méthode sera déterminée par le type de relation. Voici un rappel des différents types de relation avec la méthode de chargement par défaut :
@OneToOne
Pour chaque instance de l’entité A, une et une seule instance de l’entité B est associée. B n’est également lié qu’à une seule instance de l’entité A. Un exemple typique est la relation entre un patient et son dossier patient :
@Entity
public class Patient implements Serializable {
@OneToOne
private DossierPatient dossier;
}
Pour ce type de relation, la méthode de chargement de la relation par défaut est EAGER : à chaque fois que l’on demande les données du patient, on aura donc également les données de son dossier.
@ManyToOne
Pour chaque instance de l’entité A, une et une seule instance de l’entité B est associée. En revanche, B peut être lié à plusieurs instances de l’entité A. Un exemple typique est la relation entre un produit et sa catégorie associée :
@Entity
public class Produit implements Serializable {
@ManyToOne
private CategorieProduit categorie;
}
Pour ce type de relation, la méthode de chargement de la relation par défaut est EAGER : à chaque fois que l’on demande les données d’un produit, on aura donc également les données de sa catégorie.
@OneToMany
Pour chaque instance de l’entité A, zéro, une, ou plusieurs instances de l’entité B sont associées. En revanche, B n’est lié qu’à une seule instance de l’entité A. Il s’agit de l’inverse de la relation @ManyToOne, nous pouvons donc prendre l’exemple d’une catégorie de produit avec sa liste de produits associés :
@Entity
public class CategorieProduit implements Serializable {
@OneToMany
private Set<Produit> produits = new HashSet<>();
}
Pour ce type de relation, la méthode de chargement de la relation par défaut est LAZY : à chaque fois que l’on demande les données d’une catégorie, la liste de ses produits ne sera pas chargée.
@ManyToMany
Pour chaque instance de l’entité A, zéro, une, ou plusieurs instances de l’entité B sont associées. L’inverse est également vrai, B peut être lié à zéro, une, ou plusieurs instances de l’entité A. Un exemple typique est la relation entre un article et sa liste de thèmes abordés :
@Entity
public class Article implements Serializable {
@ManyToMany
private Set<Theme> themes = new HashSet<>();
}
Pour ce type de relation, la méthode de chargement de la relation par défaut est également LAZY : à chaque fois que l’on demande les données d’un article, la liste de ses thèmes ne sera pas chargée.
Minimiser l’utilisation des relations EAGER
Le but est de ne récupérer en base de données que les données nécessaires à ce que l’on a demandé. Par exemple, si l’on souhaite afficher la liste des noms des auteurs présents dans notre application, on ne souhaite pas récupérer l’ensemble de leurs relations : les livres qu’ils ont écrits, leur adresse, etc.
Une bonne pratique est donc de minimiser les relations chargées de façon automatique. En effet, plus on a des relations EAGER, plus on charge des objets qui ne nous sont pas forcément utiles. Cela va se traduire par une augmentation du nombre d’allers retours nécessaires vers la base de données et une augmentation du temps de traitement dédié au mapping des tables de la base de données vers les entités de notre application. De ce fait, il peut être intéressant d’utiliser au maximum les relations LAZY et de charger les données des relations manquantes seulement lorsqu’elles sont souhaitées.
Concrètement, il est conseillé de ne conserver un chargement EAGER que pour les relations dont nous sommes sûrs que les données liées seront toujours utiles (et je pense que ce cas n’est pas si courant). Cela implique de laisser les méthodes de récupération par défaut des relations @OneToMany et @ManyToMany et de forcer le chargement LAZY pour les relations @OneToOne et @ManyToOne. Ceci se matérialise par l’attribut “fetch” de la relation :
@Entity
public class Produit implements Serializable {
@ManyToOne(fetch = FetchType.LAZY)
private CategorieProduit categorie;
}
Cela demande un travail supplémentaire d’ajustement pour chaque entité et chaque relation car il va être primordial de créer de nouvelles méthodes qui nous permettront de charger l’ensemble des données nécessaires à une action en un minimum de requêtes. En effet, si on veut afficher l’ensemble des données d’un auteur (ses informations, la liste de ses livres, son adresse, etc.), il sera intéressant de récupérer l’objet et ses relations en une seule requête, en utilisant donc des jointures en base de données.
Comment contrôler quelles sont les requêtes effectuées
Spring Data JPA effectue l’accès aux données à notre place. Cependant, il faut avoir conscience de comment va être effectué ce traitement. Afin de vérifier quelles requêtes sont exécutées pour récupérer les données en base, il faut activer les logs Hibernate. Pour ce faire, plusieurs solutions sont à notre disposition. Tout d’abord, une option peut être activée dans spring :
>spring:
jpa:
show-sql: true
Ou alors, il est possible de le configurer au niveau du fichier de conf du logger :
<logger name="org.hibernate.SQL" level="DEBUG"/>
NB : Dans ces logs, les arguments passés aux requêtes ne sont pas affichés (ils sont remplacés par “?”), mais cela n’empêche pas de voir quelles sont les requêtes exécutées.
Comment optimiser la récupération des objets LAZY
Spring Data JPA fournit la possibilité de spécifier quels seront les relations chargées lors d’une requête de sélection dans la base de données. Nous allons voir avec différentes méthodes le même exemple : comment récupérer un article avec ses thèmes abordés en une seule requête.
Méthode n°1 : récupération et chargement des objets avec @Query
L’annotation @Query permet d’écrire une requête de sélection grâce au langage JPQL. On peut ainsi utiliser le mot-clé JPQL “fetch” positionné sur la jointure des relations de la requête dans le but de charger ces relations. Dans le repository de l’entité Article, il est ainsi possible de créer une méthode “findOneWithThemesById” en indiquant que la liste des thèmes devra être chargée dans l’instance de l’article récupéré :
@Repository
public interface ArticleRepository extends JpaRepository<Article,Long> {
@Query("select article from Article article left join fetch article.themes where article.id =:id")
Article findOneWithThemesById(@Param("id") Long id);
}
Méthode n°2 : Récupération et chargement des objets avec @EntityGraph
Depuis Spring Data JPA 1.10, nous avons la possibilité d’utiliser l’annotation @EntityGraph afin de créer des graphes de relations à charger en même temps que l’entité lorsque demandé. Cette annotation s’utilise également dans les repositories JPA. La définition quant à elle peut se faire soit directement sur la requête du repository, soit sur l’entité.
Définition du graphe sur la requête
On définit sur la requête les relations qui seront chargées avec l’entité grâce au mot-clé “attributePaths” qui représente la liste de relations (ici une liste d’un seul élément) :
@Repository
public interface ArticleRepository extends JpaRepository<Article,Long> {
@EntityGraph(attributePaths = "themes")
Article findOneWithThemesById(Long id);
}
Définition du graphe sur l’entité
On peut également définir ces graphes sur l’entité grâce à la notion de NamedEntityGraph arrivé avec JPA 2.1. Le principal avantage est qu’il est possible de se servir de la définition de ce graphe dans plusieurs requêtes. Dans ce cas, on spécifie la liste des relations chargées grâce au mot-clé “attributeNodes” qui sont une liste de @NamedAttributeNode. Voici comment l’implémenter sur l’entité Article :
@Entity
@NamedEntityGraph(name = "Article.themes", attributeNodes = @NamedAttributeNode("themes"))
public class Article implements Serializable {
...
}
Puis il est possible de s’en servir de la façon suivante :
@Repository
public interface ArticleRepository extends JpaRepository<Article,Long> {
@EntityGraph(value = "Article.themes")
Article findOneWithThemesById(Long id);
}
De plus, il est possible de spécifier le type de chargement des relations non spécifiées avec l’attribut “type” : chargement LAZY de toutes les relations non spécifiées ou chargement par défaut (EAGER ou LAZY suivant le type indiqué sur la relation). Il est également possible de créer des sous-graphes et ainsi travailler de manière hiérarchique afin d’être le plus fin possible.
Limitation liée à l’utilisation de @EntityGraph
Pour ces 2 méthodes liées aux graphes d’entités, on ne peut, à ma connaissance, pas récupérer une liste contenant l’ensemble des entités avec des relations. En effet, pour cela, on aimerait créer une méthode qui se définirait par exemple comme “findAllWithThemes()” avec comme nœuds du graphe “themes”. Or ce n’est pas possible, il faut forcément utiliser une restriction de recherche (synonyme d’un “where” dans une requête “select” en base de données).
Pour pallier cette limitation, une solution est de créer une méthode “findAllWithThemesByIdNotNull()” : l’identifiant n’étant jamais “null”, toutes les données seront retournées. L’autre solution est de faire cette requête avec jointure à l’aide de la première méthode, car l’annotation @Query n’a pas cette limitation.
Ajout de l’information non optionnelle si besoin
Lorsqu’une relation @OneToOne et @ManyToOne a un caractère obligatoire, c’est-à-dire que l’entité possède forcément sa relation associée, il est important de spécifier à Spring Data JPA que cette relation n’est pas optionnelle. Nous pouvons prendre l’exemple suivant : une personne possède obligatoirement une adresse, qui peut elle-même être partagée par plusieurs personnes. Ainsi, la définition de la relation est la suivante :
@Entity
public class Personne implements Serializable {
@ManyToOne(optional = false)
@NotNull
private Adresse adresse;
}
L’ajout de l’information “optional = false” va permettre à Spring Data JPA d’être plus efficace dans la création de ses requêtes de sélection car il saura qu’il a forcément une adresse associée à une personne. Par conséquent, une bonne pratique est de toujours spécifier cet attribut lors de la définition d’une relation obligatoire.
Points d’attention
Attention aux conséquences
Suite au refactoring du code d’une application pour apporter ces fonctionnalités, c’est-à-dire la modification du chargement des relations de EAGER vers LAZY, certaines régressions et bugs peuvent apparaître. Voici deux exemples très courants.
Potentielle perte d’information
Le premier effet de bord peut être la perte d’information, par exemple lors de l’envoi d’entités via Web Service.
En effet, lorsque l’on modifie par exemple la relation entre Personne et Adresse de EAGER vers LAZY, il faut revoir les requêtes de sélection des entités Personne afin d’ajouter le chargement explicite de leur adresse (avec l’une des méthodes vues ci-dessus). Sans quoi, il se peut que le Web Service de récupération d’une personne fournisse uniquement les données propres à la personne et que les données de l’adresse aient disparues. Cela est problématique car le web service peut ne plus respecter son contrat d’interface, cela peut par exemple impacter l’affichage sur une page web : on s’attend à ce que l’adresse soit renvoyée car on en a besoin pour l’afficher dans notre vue HTML.
Afin d’éviter ce problème, il est intéressant d’utiliser des DTO (Data Transfer Object) plutôt que directement renvoyer les entités aux clients. En effet, le mapper transformant l’entité en DTO va charger l’ensemble des relations dont il a besoin en allant récupérer en base de données les relations qui n’ont pas encore été chargées lors de la requête initiale : il s’agit du Lazy Loading. Ainsi, même si l’on ne refactore pas la récupération des entités, le web service continuera de renvoyer les mêmes données.
Potentiel problème de transaction
Le deuxième effet de bord peut être l’apparition de l’exception “LazyInitializationException”.
Cette exception apparaît lorsque l’on essaye de charger une relation en dehors d’une transaction, le Lazy Loading ne peut alors pas se faire car l’objet est détaché : il ne fait pas partie d’une session Hibernate. Cela peut apparaître après les modifications du type de chargement des relations car avant ces modifications, les relations étaient chargées automatiquement à la récupération des données en base de données.
L’exception peut dans ce cas être levée pour 2 principales raisons. La première cause peut être que vous n’êtes pas dans une transaction Hibernate. Dans ce cas, il faut soit rendre le traitement transactionnel (grâce à l’annotation Spring @Transactional à positionner sur la méthode ou sur sa classe), soit appeler un service transactionnel qui pourra s’occuper de charger les dépendances. La deuxième cause peut être que vous êtes sortis de la transaction dans laquelle votre entité avait été attachée, et que l’entité n’est pas attachée à votre nouvelle transaction. Dans ce cas, il faut soit charger les relations dans la première transaction, soit réattacher l’objet dans la seconde.
Spécificités des requêtes paginées
Lorsque l’on souhaite créer une requête paginée devant contenir des informations d’une ou plusieurs relation(s), le chargement des données appartenant aux relations dès la requête de sélection est une (très) mauvaise idée. Par exemple, lorsque l’on récupère la première page des articles de l’application avec leurs thèmes, il est préférable de ne pas charger directement l’ensemble des données articles+thèmes, mais d’abord les données concernant les articles puis les données thèmes de ces articles dans un second temps. En effet, sans cela, l’application sera obligée de récupérer l’ensemble de données de la jointure entre les 2 tables, de les stocker en mémoire, pour ensuite sélectionner seulement les données de la page demandée. Ceci est directement lié au fonctionnement des bases de données, elles doivent sélectionner l’ensemble des données de la jointure même si on ne souhaite qu’un fragment des données : que ce soit une page, un min/max ou le top x des résultats.
Dans le cas d’un chargement d’une page avec ses relations, un message explicite apparaît dans les logs pour vous en avertir :
HHH000104: firstResult/maxResults specified with collection fetch; applying in memory!
Plus la volumétrie des 2 tables est importante, plus l’impact sera élevé : avec des tables contenant des millions d’entrées, cela peut se traduire par un traitement extrêmement coûteux pour l’application.
Pour pallier ce problème, il est donc indispensable de charger dans un premier temps les entités sans leurs relations puis de charger celles-ci dans un second temps. Pour charger les données de l’entité de la page demandée, on peut utiliser la méthode findAll(Pageable pageable) du repository JPA (hérité de la classe PagingAndSortingRepository). Ensuite, pour charger les données des relations, vous pouvez utiliser le Lazy Loading en appelant directement le getter des relations à récupérer pour chacune des entités.
Cette opération va être coûteuse car elle va engendrer beaucoup de requêtes. En effet, on aura pour chaque entité autant de requêtes de sélection qu’il y a de relations à charger : ce problème est connu sous le nom du “problème du N+1 avec Hibernate”. Si on prend l’exemple d’un chargement d’une page de 20 articles avec une relation à charger, cela se traduira par 21 requêtes : 1 pour la page et 20 pour les thèmes de chacun des articles.
Afin de réduire ce coût, il est possible d’utiliser l’annotation @BatchSize(size = n) sur la relation @OneToMany ou @ManyToMany entre les deux entités. Cela permet d’indiquer à Hibernate d’attendre d’avoir un nombre suffisant (n) de relations à récupérer avant de faire la requête de sélection dans la base de données. Ce nombre n est à associer à la taille des pages (cela signifie néanmoins d’avoir une taille des pages par défaut car n est défini sur l’entité et donc constant). Ainsi, dans l’exemple précédent, on peut spécifier le nombre minimal à 20 :
@Entity
public class Article implements Serializable {
@ManyToMany
@BatchSize(size = 20)
private Set<Theme> themes = new HashSet<>();
}
Dans ce cas, le nombre de requêtes pour charger la page passera de 21 à 2 : 1 pour la page et 1 pour l’ensemble des thèmes.
NB : si la page contient moins de 20 éléments (donc inférieur à n), les thèmes seront quand même bien chargés.
Aller plus loin
Voici d’autres points intéressants à creuser pour ne pas voir les performances de son application chuter.
Utilisation d’un cache
Pour booster les performances de votre application, il peut être intéressant d’utiliser un système de cache. Il existe tout d’abord le cache de second niveau d’Hibernate. Cela permet de garder en mémoire les entités du domaine ainsi que leur relation et donc de réduire le nombre d’accès à la base de données. Il existe également le cache de requête. En complément du cache de second niveau, il est souvent plus utile. Il permet de conserver en mémoire les requêtes effectuées et leur résultat. Il faut cependant porter attention à quelques points lors de l’utilisation de celui-ci :
- le cache de second niveau est utile uniquement lors des accès aux entités par l’id (et par les bonnes méthodes JPA) ;
- dans une application distribuée, il est obligatoire d’utiliser également un cache distribué, ou de ne l’utiliser que sur des objets en lecture seule qui changent rarement ;
- la mise en place est plus compliquée lorsque la base de données peut-être altérée par d’autres éléments (c’est-à-dire lorsque l’application n’est pas le point central d’accès aux données).
Création d’index
La création d’index est un passage obligé pour améliorer les performances d’accès à la base de données. Ceci permet des recherches de sélection plus rapides et moins coûteuses. Une application dépourvue d’index sera donc beaucoup moins performante. Quelques précisions sur la création d’index :
- plus la volumétrie de la table est importante, plus l’index portera ses fruits ;
- un index est généralement utile que si les données sont suffisamment réparties (un index sur le sexe avec 50% M et 50% F n’est pas très efficace) ;
- un index qui accélère la lecture va également ralentir l’écriture ;
- les SGBD n’ont pas tous les mêmes politiques d’indexation qui devront donc être étudiées, un index peut par exemple être créé automatiquement ou non à l’ajout d’une clé étrangère suivant le SGBD.
Gestion des transactions
La gestion des transactions est aussi un levier important d’optimisation : il est nécessaire de bien les utiliser si l’on ne veut pas voir apparaître des problèmes de performance. Par exemple, leur mise en place étant coûteuse pour l’application, il est préférable de ne pas en utiliser dans les cas où elles ne sont pas nécessaires. Par défaut, Hibernate va attendre la fin de la transaction Spring avant de mettre à jour l’ensemble des données dans la base (sauf dans les cas où un flush de persistance intermédiaire lui est nécessaire). Pendant ce temps, il va stocker les mises à jour en mémoire. Si une transaction concerne une volumétrie de données très importante, on peut rencontrer des problèmes de performances. Dans ce cas, il est préférable de découper le traitement en plusieurs transactions. De plus, lorsque la transaction ne fait que de la lecture, il faut indiquer à Spring qu’elle est en lecture seule afin d’améliorer les performances :
@Transactional(readOnly = true)
Retour d’expérience
On m’a récemment demandé de travailler sur les performances d’une application web. Malgré un premier travail sur certaines parties pour améliorer les performances globales, l’application continuait de provoquer une saturation des serveurs sur lesquels elle était installée (surtout en charge CPU), les délais d’attente pour chaque requête étaient très élevés et on semblait avoir atteint la volumétrie maximale que l’application pouvait supporter. En remarquant le nombre de requêtes effectuées constamment vers la base de données (à l’activation des logs Hibernate) et en regardant dans le code comment étaient produites ces requêtes, j’ai décidé d’appliquer les quelques conseils de cet article afin de donner un peu d’air à l’application.
Procédé utilisé
L’application web sur laquelle je suis intervenu a la particularité de fonctionner beaucoup plus sous la forme de batch (actions faites toutes les 1 à 60 secondes selon les jobs) que d’actions utilisateur. Afin de réduire ces problèmes de performance, j’ai essayé de procéder de manière itérative, en me préoccupant d’un traitement à la fois dans l’ordre décroissant de la fréquence des jobs : d’abord ceux qui sont effectués chaque seconde jusqu’à ceux effectués chaque minute.
Pour chaque job, je comptais le nombre de requête Hibernate de sélection effectuées pour réaliser le traitement et j’essayais de voir si chacune était nécessaire ou s’il s’agissait de données récupérées à tort. Dès que je trouvais une incohérence dans ce qui était chargé depuis la base de données, je modifiais le type de relation (EAGER à LAZY), je créais des requêtes adaptées dans les repositories et je favorisais les critères de sélection sur la requête (contrairement à un filtre appliqué à posteriori sur la liste des données récupérées).
Le but était de réduire le nombre de requête effectuées à un nombre minimum (une seule si possible) et de ne charger que les objets nécessaires à chaque traitement.
Afin de vérifier si la charge sur la base de données (et le chargement des données) diminuait, j’ai décidé de me baser sur 2 métriques : le nombre de requêtes de sélection et le nombre d’objets chargés par minute. Pour cela, j’ai utilisé une méthode assez simpliste : je redirigeais les logs de l’application sur 1 minutes, et de ce fichier, je comptais :
- le nombre de requêtes de sélection : nombre d’occurrences de “SELECT …” ;
- le nombre d’objets chargés : nombre d’occurrences de “SELECT …” additionné au nombre d’occurrences de “… join fetch …”.
Résultats
Après quelques jours de travail sur ce sujet et en appliquant seulement ces quelques procédures, j’ai réussi à diviser environ par 5 le nombre de requêtes effectuées en base de données et par environ 7 le nombre total d’objets chargés.
Avec la nouvelle version de l’application en production, la charge du serveur s’est vraiment amoindrie. Pour preuve, voici l’état du serveur avant la nouvelle version :
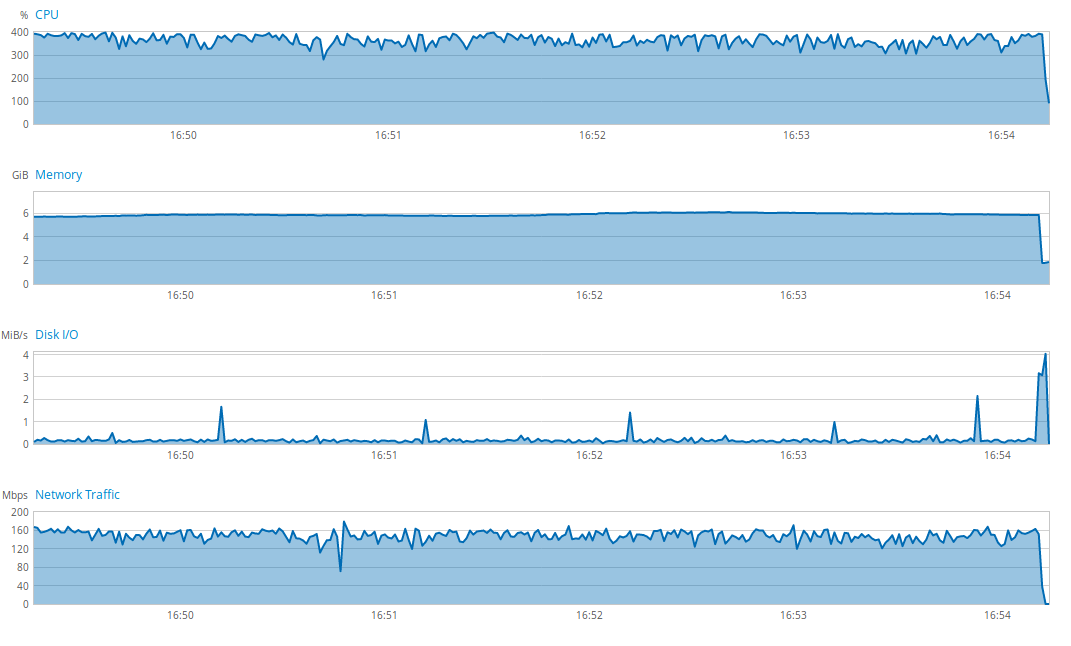
On voit une utilisation importante et presque inquiétante de l’ensemble des ressources du serveur. Après le passage à la nouvelle version, voici l’état du serveur :
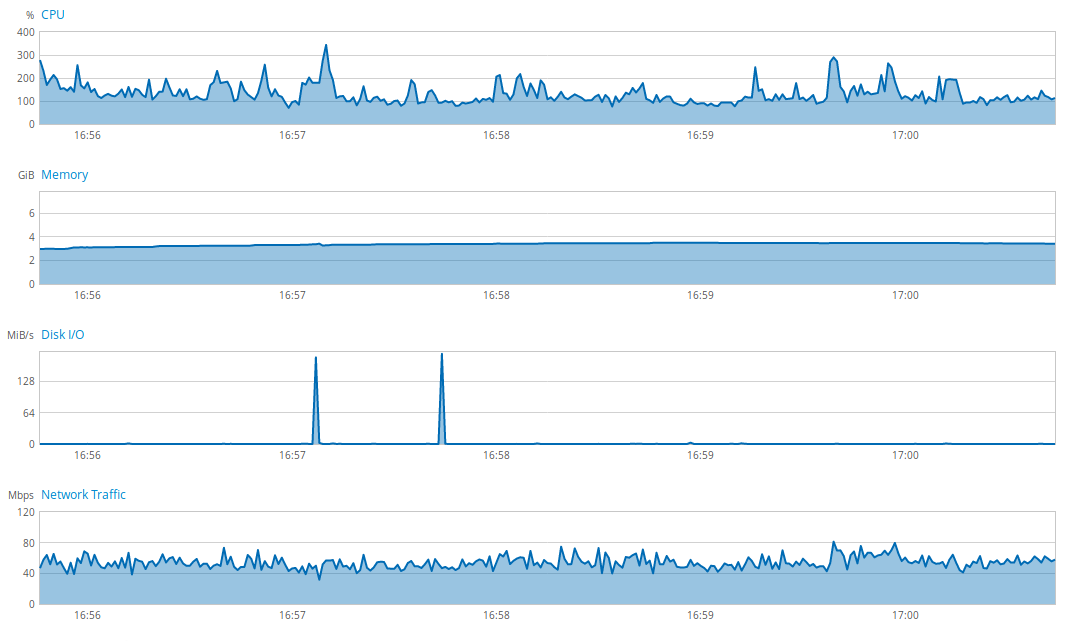
L’usage global du serveur a été considérablement diminué grâce à quelques petits ajustements, simples à mettre en place. Il est donc nécessaire pour moi de garder à l’esprit ces problématiques lors du développement d’une application.
Conclusion
Après avoir énoncé les différents types de relations entre entités et leur méthode de chargement par défaut, nous avons compris pourquoi il était important de favoriser au maximum un chargement LAZY des relations entre entités. Nous avons appris comment récupérer un maximum de données en un minimum de requêtes, notion d’autant plus importante lors de l’utilisation des chargements LAZY, ceci grâce à quelques outils fournis par Spring Data JPA. Avec un exemple sous la forme d’un retour d’expérience, nous avons vu à quel point il est important de respecter ces quelques conseils si on ne veut pas voir apparaître des chutes de performances importantes dans nos applications.
Ce qui est important de retenir est que chaque demande d’informations à la base de données doit être justifiée, qu’il ne faut pas récupérer de données qui ne nous sont pas utiles, et qu’il est préférable de minimiser le nombre de requête de sélection pour chaque demande d’informations (une seule si possible par demande).
Ce travail est continu, il doit être effectué au fil de l’eau lors de la réalisation de l’application. Sinon, il nous faudra nous pencher sur ces problématiques lorsque les problèmes de performances apparaîtront, au risque de connaître des régressions lors des tentatives de résolution. Il ne faut pas non plus tomber dans l’excès, certaines actions ne nécessitent pas forcément un investissement de temps conséquent. Ce travail est surtout primordial lorsqu’une action est réalisée très souvent, et lorsque l’on récupère des grappes de données imposantes.
Ressources :
- https://www.jtips.info/index.php?title=Hibernate/Cache
- https://dzone.com/articles/spring-data-jpa-and-database
- https://jhipster.github.io/
- https://jhipster.github.io/using-cache/
- http://spring.io/
- http://projects.spring.io/spring-data-jpa/
- https://docs.spring.io/spring-data/jpa/docs/current/reference/html/
- http://docs.spring.io/spring-data/data-jpa/docs/current/api/org/springframework/data/jpa/repository/EntityGraph.EntityGraphType.html
Blog JPA :
