

Du 25 au 27 Octobre 2016 a eu lieu à Bruxelles, la conférence officielle européenne autour du framework Apache Spark : le Spark Summit Europe.
Vous pourrez retrouver, dans cet article, un retour de cet évènement pour celles et ceux qui n’ont pas pu y prendre part.
Les éléments à retenir du Summit
Apache Spark cette année

“It’s a great year for Apache Spark“. Tels sont les mots du créateur de Spark, Matei Zaharia, pour résumer l’année 2016. En effet, la communauté autour de Spark ne cesse de grossir, aussi bien en nombre de commiteurs sur le code source qu’en nombre de personnes assistant à des confs sur ce sujet. De plus, une version majeure est sortie cette année apportant tout un lot de fonctionnalités et d’optimisations non négligeables ; version regroupant pas moins de 2000 patches codés pour un total de 280 commiteurs.
L’API de Spark
Les conférences ont vraiment mis l’accent sur Spark SQL. On oublie les RDDs et son API plutôt bas niveau. On ne se concentre que sur les DataSets / DataFrames, tirant ainsi parti du couple Tungsten / Catalyst pour l’optimisation de nos traitements Spark.
Fait important de la 2.0, les jobs en 1.X sont valables sur la 2.0 (back-compatibility). De plus, avec Spark 2.0, plus besoin de jongler avec les différents SqlContext : tout est regroupé dans un SparkSession, ce qui simplifie l’API.
Point très prometteur pour le futur et que vous avez peut être pu voir dans Spark 2.0, c’est l’API en alpha des Structured Streams avec pour nom de code actuel, les DataStreams. Cette API change radicalement la façon de concevoir nos jobs de processing en streaming avec Spark. C’est une API de plus haut niveau que celle des DStreams (dérivée des RDDs), puisqu’elle est basée sur les DataSets. Il faudra attendre que sortent les prochaines minor releases, pour pouvoir utiliser cette nouvelle API.
La fermeture de l’AMPLab de Berkeley
L’UC Berkeley AMPLab, ayant pour but d’innover dans le domaine du BigData et qui a permis à des technologies comme Apache Spark, Apache Mesos et Alluxio (anciennement Tachyon) de se lancer, va fermer ses portes pour laisser la place au RISELab qui lui aura pour but de se concentrer sur le traitement sécurisé de flux de données.
La Data Science avec Apache Spark
La Data Science fut une part non négligeable des talks du Summit, avec beaucoup de REX montrant comment utiliser Spark pour amener des algorithmes de Machine Learning en production.
En début de seconde journée, nous avons eu une présentation d’Ali Ghodsi, cofondateur et CEO de Databricks sur la démocratisation de l’AI avec Apache Spark. Point intéressant de sa conférence, l’AI existe depuis 40 ans et n’a pris son envol dans le monde seulement parce que nous avons les outils, comme Spark, pour entraîner et valider des modèles complexes. L’intérêt de Spark pour faire de l’AI vient de sa facilité à se connecter à d’autres framework, de sa flexibilité et de la rapidité à mettre en place un prototype avec.
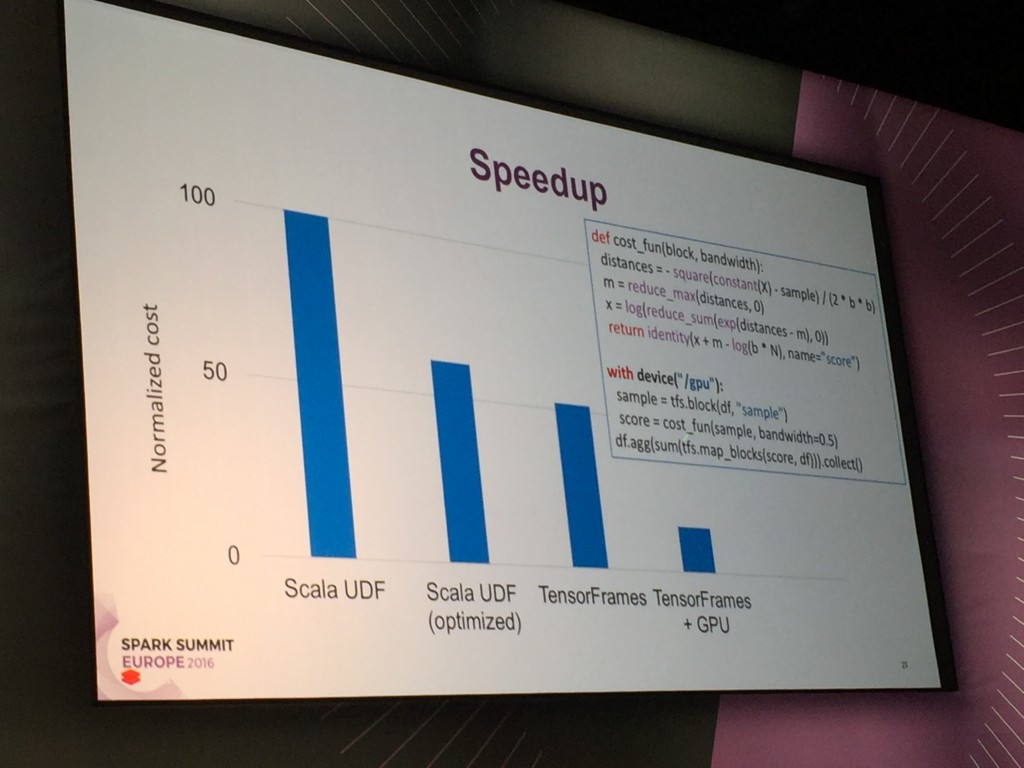
Ali Ghodsi a fini sa présentation par une démonstration de l’utilisation d’un modèle de Deep Learning avec Apache Spark et TensorFlow sur le notebook Databricks (l’addition des trois donne TensorFrames). Afin de soutenir le training de modèles de plus en plus complexes (comme du Deep Learning par exemple), on a pu voir que des développements avaient été réalisés pour utiliser la puissance des GPU pour le calcul donnant des résultats très prometteurs pour la suite.
Le notebook Databricks mis en avant
Nous avons pu assister à plusieurs démonstration de la facilité à mettre en place un algo de Machine Learning sur un cluster, monté à la volée, dans Amazon AWS via le notebook de Databricks. Il semble qu’il y ait une certaine volonté de s’abstraire des contraintes liées à la gestion d’un cluster et donc de se concentrer seulement sur le métier pour pouvoir expérimenter de gros traitements rapidement et ainsi valider ou non ce qui a été fait.
Le monitoring des jobs et la configuration de l’allocation des ressources
Un des problèmes abordé dans toute une série de talks concernait le comportement des jobs en production et l’utilisation des ressources du cluster. La volonté finale étant d’optimiser les jobs pour qu’ils n’utilisent que les ressources dont ils ont besoin et ainsi éviter les temps de d’inactivité qui peuvent survenir.
Une option a souvent été mise à l’honneur : l’allocation dynamique de ressources. Cette option donne la possibilité d’être plus tolérant et plus efficace sur l’utilisation des ressources du cluster. Elle permet d’allouer ou de désallouer des executors suivant les besoins du jobs. Du fait de cette option, on perd un peu en temps d’exécution, mais on évite de se retrouver avec un nombre trop important de ressources inactives mais allouées.
Conclusion
Ce fut le premier Spark Summit auquel j’assistais, évènement que j’ai trouvé très intéressant de part la qualité et la diversité des sujets abordés. Spark est un framework au coeur de l’éco-système Big Data. Beaucoup de chemin a été parcouru par ce framework depuis la première major release en mai 2014. Il reste néanmoins beaucoup de choses à faire sur ce sujet, ce qui le rend très attractif.
N’hésitez pas à jeter un oeil au programme des confs du Summit, vous pourrez y retrouver toutes les slides et vidéos des présentations. Les vidéos des présentations ont été regroupées dans des playlists Youtube suivant le thème abordé.
