Continuons dans notre série d’articles sur la modélisation Cassandra (lire Factures et commandes et Recherche multicritère). Avant de pouvoir passer une commande et plus encore de produire une facture, votre client va devoir lister les articles qu’il souhaite acheter. Pour cela, l’application propose généralement d’utiliser un panier, liste remplie au fur et à mesure par l’utilisateur. C’est de cet objet particulier et important que nous allons parler aujourd’hui.
Panier
Les paniers ne se limitent pas aux sites marchands. On les retrouve dans la plupart des applications où les utilisateurs sont conduits à faire une sélection de plusieurs éléments, sur lesquels ils effectuent une opération en masse par la suite. Ce peut être une liste d’articles qui seront achetés en fin de navigation. Dans un logiciel de facturation, ce pourrait être une sélection de factures sur lesquelles on veut envoyer une relance. On peut aussi penser aux listes de préférences ou aux listes de souhaits.
Dans sa forme classique, un panier est donc une liste qui est remplie progressivement par ajout et retrait d’éléments. Souvent, le contenu sera exploité par une action qui provoquera son vidage.
Les éléments d’un panier ne sont pas classés. Il est fréquent que l’affichage classe les éléments, éventuellement triés par catégorie. Le classement et le tri sont des règles d’affichage qui sont réalisées par le tiers de présentation.
Par ailleurs, un panier doit pouvoir être manipulé de façon concurrente. On imagine souvent une personne seule devant son ordinateur en train de sélectionner deux livres, l’un après l’autre, puis de les commander. Mais ce n’est pas le seul cas d’usage. Vous rencontrerez aussi le cas d’un couple qui effectue ses courses en ligne chacun avec son ordinateur connecté sur le même compte. Madame réduit le nombre de packs de bières à un, parce que cinq c’est trop. Pendant ce temps, Monsieur en rajoute, parce qu’il en faut au moins trois pour la soirée foot de vendredi soir avec les copains. Les deux appuyant simultanément l’un sur le bouton [+], l’autre sur le bouton [-]. À partir du moment où l’on travaille sur le web, il faut partir du principe que les requêtes vont s’exécuter en parallèle.
Modèle fonctionnel
Le modèle fonctionnel du panier est donc simple : c’est un sac, c’est-à-dire un ensemble qui peut contenir plusieurs fois le même élément. Le nombre de répétitions de l’élément étant conservé. Pour traiter le cas général, nos paniers seront nommés pour être distingués entre eux.
Le modèle conceptuel est donc le suivant :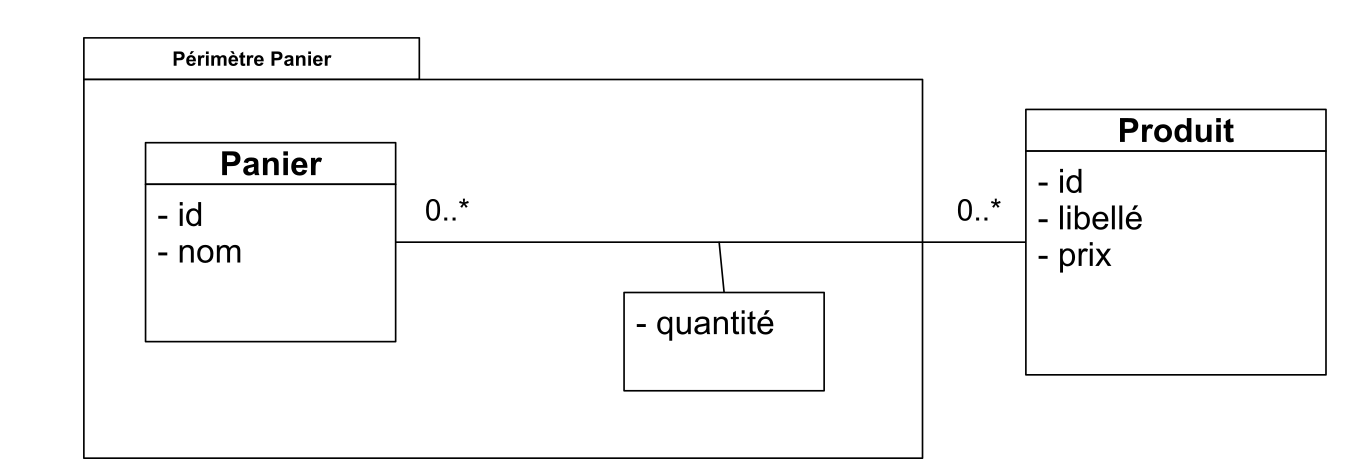
Modèle logique
Avec une base relationnelle, le modèle de base se décline très simplement par l’utilisation de deux tables : l’une représente l’entité panier et l’autre la jointure N-N entre les entités Panier et Produit. La modélisation de l’entité Produit ne sera pas traitée ici. On simplifiera le propos en considérant qu’il est représenté par une table unique.
On obtient le schéma suivant :
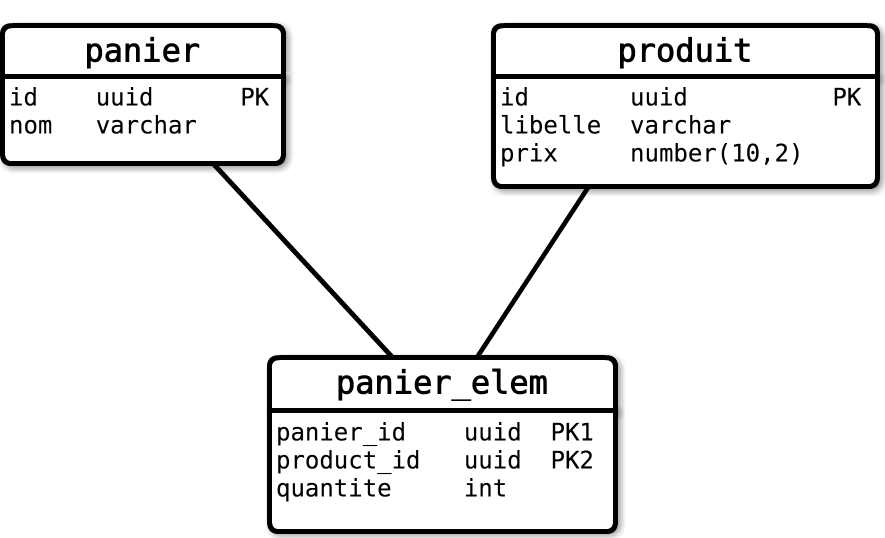
Modèle naïf
Prenons le cas de Dave Lopernahif. Il connait bien les bases de données relationnelles avec lesquelles il travaille régulièrement. Il utilise Cassandra depuis peu de temps, mais pense en avoir compris le fonctionnement. D’ailleurs, le modèle n’est-il pas proche ? Cassandra stocke les données dans des tables et CQL ressemble à s’y méprendre à SQL. Bien sûr, il faut s’adapter aux spécificités de la base et à l’absence de jointure. C’est pourquoi Dave sait qu’il doit stocker toutes les informations concernant le panier et sa jointure avec les produits dans une seule table. Heureusement, il a déjà lu un excellent article sur la modélisation Java où une relation de composition 1-N était modélisée grâce au mécanisme de partition. Ici, la relation n’est pas une relation de composition, les lignes ne représenteront pas l’entité Produit, mais le lien vers l’entité.
En suivant ce principe, Dave modélise sa table ainsi :
- La clé de partition est l’identifiant du panier.
- Le nom du panier est contenu dans une colonne statique (attribut de la partition).
- L’identifiant du produit est utilisé comme l’unique colonne de clustering.
- La quantité est une colonne normale.
- Le libellé du produit et son prix peuvent être dénormalisés sous la forme de colonnes normales.
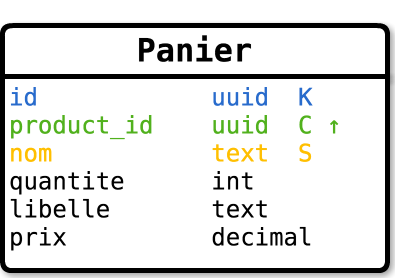
Modélisation naïve
Pour lire le contenu du panier, une requête suffit :
select * from panier where id = ?
Et notre développeur est content. Sauf que …
Gestion de la concurrence
Sauf que maintenant, il faut pouvoir gérer les modifications concurrentes. Et nous tombons dans le cas classique d’une modification par lecture puis écriture de la valeur modifiée.
Lors de l’utilisation d’une base de données relationnelle, la solution consiste à poser un verrou à la lecture puis à faire la modification. Le cas particulier de la première insertion devant être prise en compte. Or Cassandra ne permet pas de poser de verrou. “Mais, se dit Dave, il y a les transactions légères qui fonctionnent comme un compare-n-swap au niveau de la ligne”. Il suffit donc pour lui de suivre l’algorithme suivant :
select quantite from panier where id = :panier_id and product_id = :product_id
Si on a un résultat alors on définit : nv_quantite ← anc_quantite + quantite_ajoute et on exécute la commande suivante :
update panier set quantite = :nv_quantite where id = :panier_id and product_id = :product_id if quantite = :anc_quantite
Sinon on exécute :
insert (id, product_id, quantite, libelle, prix) values (:id, :product_id, :quantite_ajoute, :libelle, :prix) if not exists
Dans les deux cas, la deuxième commande peut échouer en cas de modification parallèle. Dans ce cas, on recommence à la première étape.
Avec ce fonctionnement, Dave Lopernahif obtient rapidement une application qui fonctionne.
Une modélisation efficace
Cependant, la modélisation de notre ami a deux problèmes importants :
- L’utilisation des transactions légères est lente. Elle est même très lente, car elle requiert quatre échanges entre le nœud coordinateur de la requête et les répliques.
- De plus, le niveau de cohérence est de type SERIAL, qui est une cohérence immédiate forte et ne permet pas de bénéficier de la cohérence à terme offerte par Cassandra. Il en résulte une réduction de la haute disponibilité.
Cette modélisation n’est donc pas satisfaisante et il nous faut revoir complètement la modélisation.
On pourrait vouloir utiliser les compteurs. Seulement, une table contenant des colonnes de type compteur ne peut pas contenir de colonne d’un autre type, ce qui complique le modèle. Mais aussi, les requêtes d’augmentation et de réduction du compteur ne sont pas idempotentes, ce qui les rend peu fiables et limite leur utilisation à des comptages statistiques où un certain taux d’erreur est autorisé.
Pour obtenir une représentation efficace, il faut se souvenir que Cassandra est très fort pour ajouter des données et moins pour les modifier. Ainsi, plutôt que de stocker le contenu de la liste, il est préférable de stocker les évènements qui la modifient. Chaque évènement est identifié par un identifiant unique UUID de type 1, c’est-à-dire horodaté.
Notre table sera donc structurée ainsi:
- La clé de partition est l’identifiant du panier.
- Le nom du panier est contenu dans une colonne statique (attribut de la partition).
- L’identifiant de l’évènement constitue l’unique colonne de clustering classé par ordre croissant.
- Les données de l’évènement (product_id, quantité et valeurs dénormalisées) sont stockées comme des colonnes ordinaires.

Modèle efficace
Cette modélisation a l’avantage de ne nécessiter que des ajouts de données, de gérer naturellement la concurrence et de ne nécessiter aucune lecture avant l’écriture. On est dans le cas optimal qui nous permettra de tirer le maximum de performances de Cassandra.
Gestion de la cohérence
De plus, cette représentation du panier nous permet de relâcher la cohérence.
En effet, Cassandra, sur le modèle de Dynamo créée par Amazon pour gérer les paniers du site marchand, est conçue initialement comme une base cohérente à terme. L’idée est de privilégier la disponibilité et la résistance aux partitions réseau plutôt que la cohérence des données sur tous les serveurs. Amazon préfère ajouter un élément au panier, même s’il n’arrive pas à mettre à jour toutes ses répliques plutôt que de lever une erreur et voir son client potentiel partir finir son achat ailleurs. Les écarts entre les données étant réconciliées par le système par la suite.
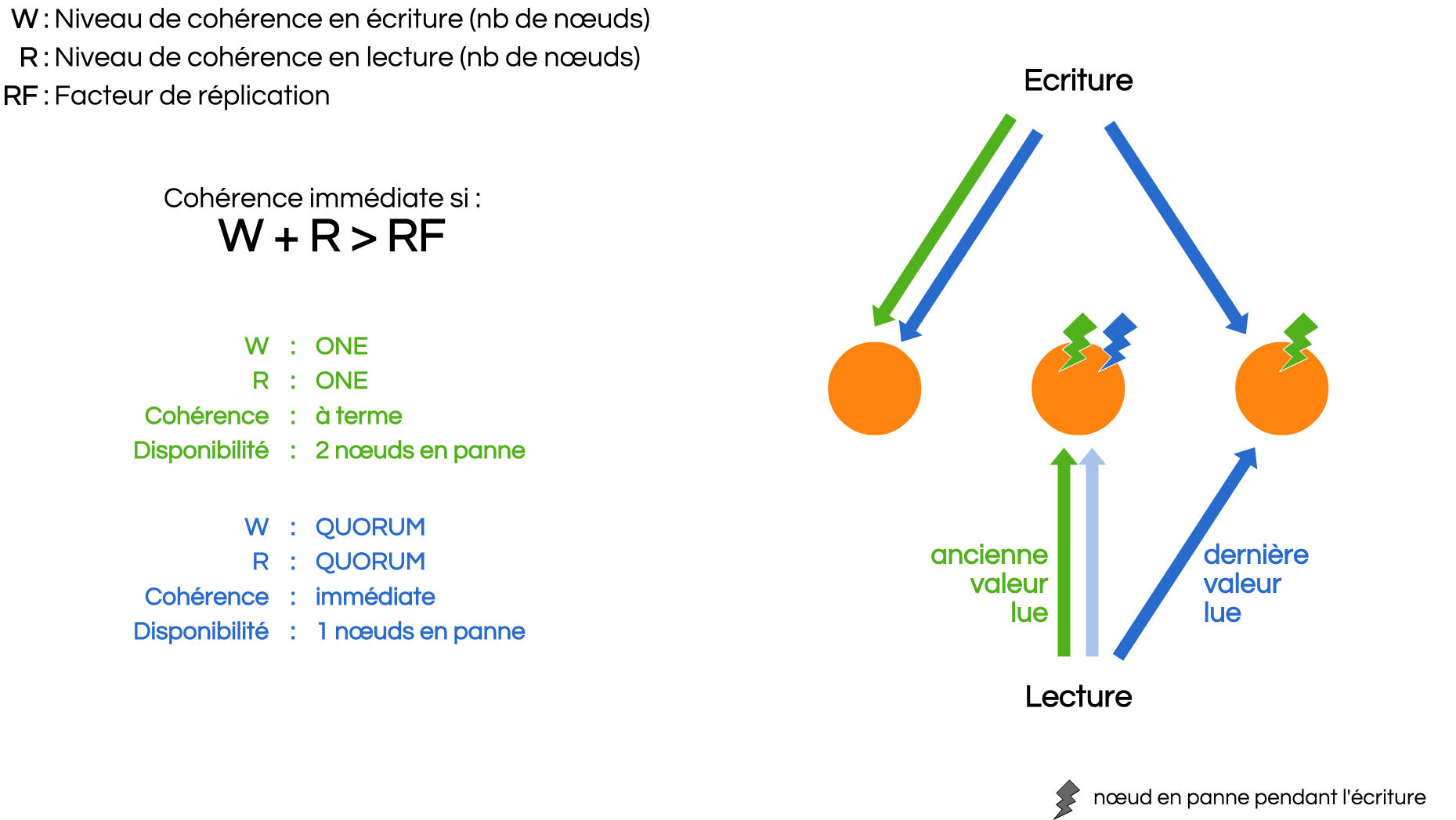
En fait, Cassandra donne la liberté au développeur de choisir s’il veut plus de cohérence ou une plus grande disponibilité. Selon votre cas métier, vous devrez choisir la très haute disponibilité (et la latence d’écriture la plus faible) ou la cohérence immédiate.
Le réglage s’effectue en choisissant le niveau de cohérence de chaque requête. Au moment de l’écriture, le niveau de cohérence est le nombre de nœuds qui ont acquitté l’écriture. Au moment de la lecture, c’est le nombre de nœuds qui ont répondu. Lorsque deux nœuds fournissent une valeur différente, la plus récente est conservée et un mécanisme de réparation se met en place. Les principaux niveaux de cohérence offerts par Cassandra sont ONE, QUORUM et ALL. Souvent utilisés en ONE-ONE pour une cohérence à terme ou QUORUM-QUORUM pour une cohérence immédiate. D’autres combinaisons sont possibles, mais elles sont rares et ne doivent être utilisées que si l’on en maitrise les conséquences.