
Le 22 Mars 2023 a eu lieu, à Paris, le premier AWS Analytics - User Group Meetup. Ce rendez-vous rassemblant les passionnés de Cloud et de data engineering était dédié à Amazon Redshift avec la présence exceptionnelle du VP Redshift monde. Nous avons d’ailleurs eu l’occasion de nous entretenir avec lui pour mettre en place une architecture datawarehouse liée au scaling chez un de nos clients Ippon.
Lors de cette journée, où se sont enchaînés keynotes et sessions de travails (et pauses cafés évidemment), un terme est revenu à plusieurs reprises : le Data Sharing. Le quoi ???
Revenons d’abord au début …
Dans l'univers en constante évolution du big data et du partage de l’information, les entreprises font face à un enjeu majeur : stocker et analyser d’importants flux de données à hautes volumétries, de façon performante et cost-effective, tout en évitant la duplication au sein d’une organisation. Pour y répondre, les solutions de data engineering dévoilent de nouveaux paradigmes d’architectures pour pouvoir différencier le calcul du stockage, comme celle du “lakehouse” par exemple.
C'est dans ce contexte que la fonctionnalité "data sharing" d'Amazon Redshift s'inscrit comme une solution innovante et puissante. Elle répond à cette problématique en permettant à plusieurs clusters d'accéder à des données communes. Cette approche facilite non seulement la collaboration entre différentes parties prenantes, mais ouvre également la porte à des cas d'usage innovants tels que le data-analytics as a service, l'analyse en temps réel à l'échelle de l'entreprise et la consolidation de données de plusieurs sources dans un environnement unifié.
Dans cet article, nous définirons ce qu’est le data sharing, discuterons de ses avantages et développerons des cas d'usage concrets où il permet de surmonter les obstacles traditionnels liés au partage de données.
Définitions
Amazon Redshift
Amazon Redshift est le service de datawarehouse managé dans le Cloud par AWS. Il permet aux utilisateurs de collecter, stocker et analyser de grandes quantités de données à l'aide de requêtes SQL standard. Redshift est conçu pour gérer de vastes ensembles de données, allant de quelques centaines de gigaoctets à un pétaoctet ou plus et en fournissant des performances rapides grâce à des techniques telles que le stockage en colonnes, la compression des données, et des optimisations de requêtes.
Un cluster Redshift est composé des éléments suivants :
- Un nœud leader (gère le traitement des requêtes, la coordination et distribution).
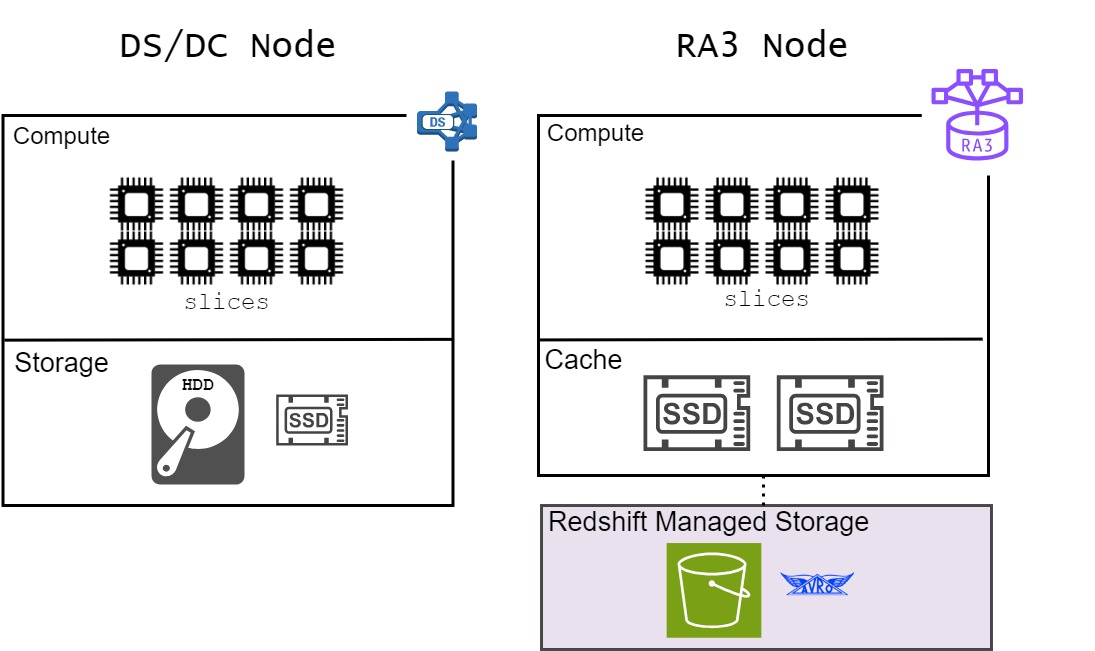
- Plusieurs nœuds de calculs “DS / DC” (“dense storage” ou “dense compute” à choisir en fonction de ses besoins). Chaque nœud de calcul comporte des unités CPU appelés “slices” visant à répartir les données et à paralléliser les calculs, ainsi que des disques de stockage SSD / HDD.
Pour pallier ce problème, AWS annonce fin 2019 la release d’un nouveau type de nœud : les nœuds RA3. Ces derniers permettent justement de séparer le calcul du stockage : finis les disques HDD et place non seulement aux nouveaux disques SSD à haute capacité pour le cache, mais surtout au RMS (Redshift Managed Storage) : une nouvelle couche de stockage des données totalement gérée par AWS sur S3 et basée sur le framework de sérialisation Apache Avro.
Data Sharing
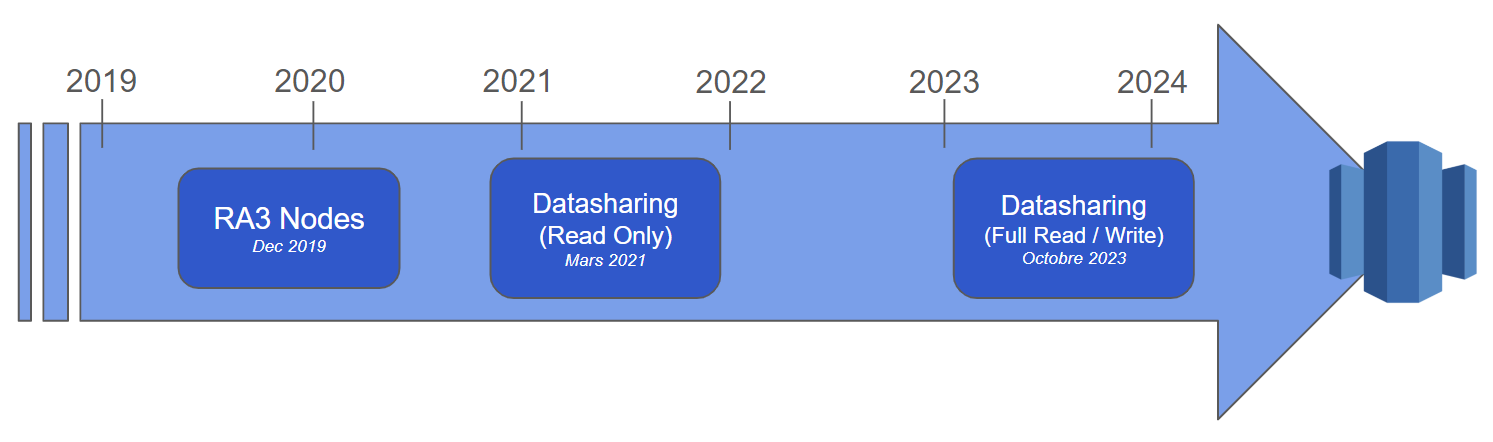
L’arrivée des nouveaux types de nœud RA3 a permis à une séparation calcul/stockage de voir le jour. C’est grâce à ce nouveau paradigme qu’AWS annonce en Mai 2021 la sortie du data sharing : une nouvelle fonctionnalité permettant le partage de données live en lecture entre clusters Redshift (provisionné RA3 ou workgroup Redshift serverless) sans besoin de copier ou déplacer les données. En Octobre 2023, lors de l’AWS re:Invent, est dévoilée la fonctionnalité du multi-data warehouse data sharing en écriture.
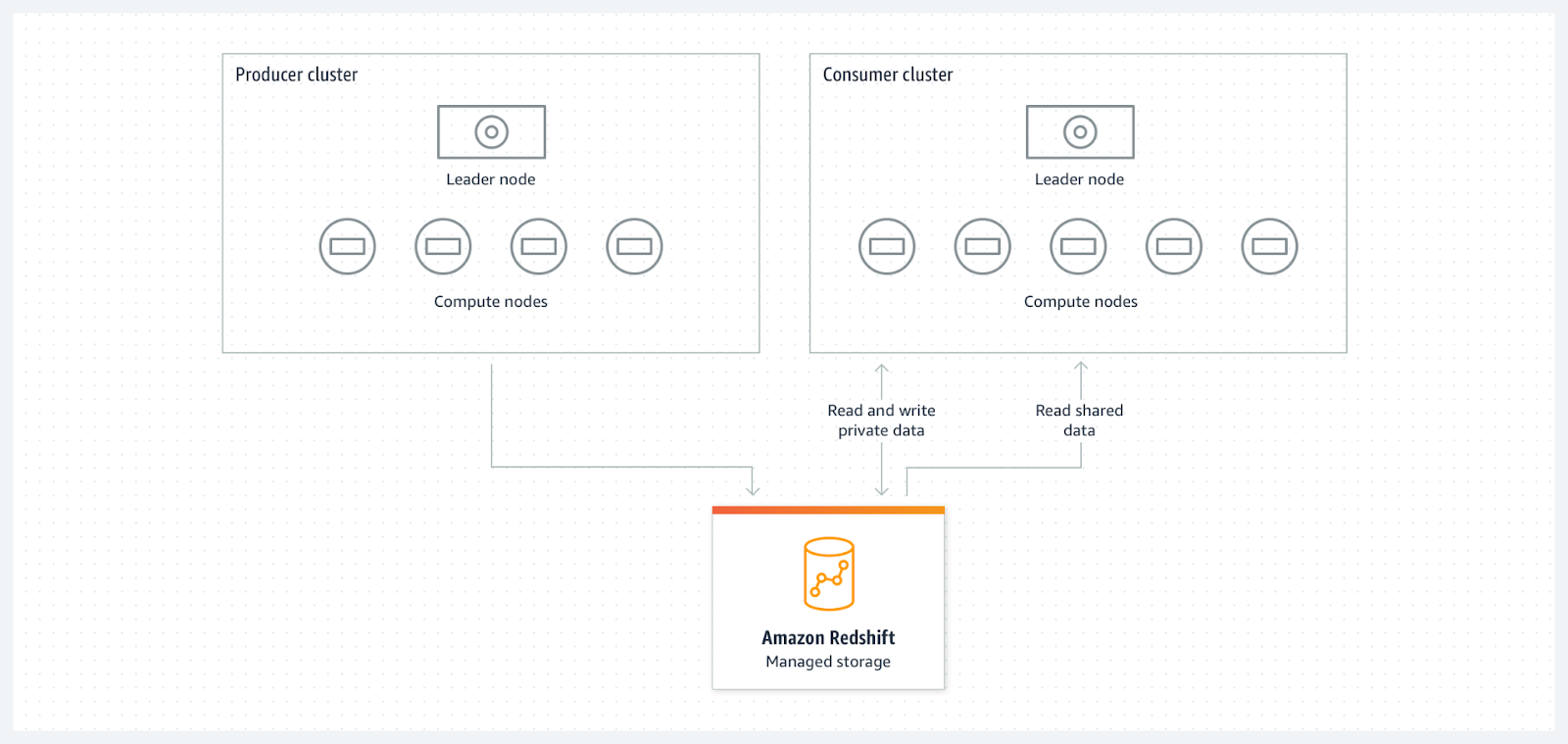
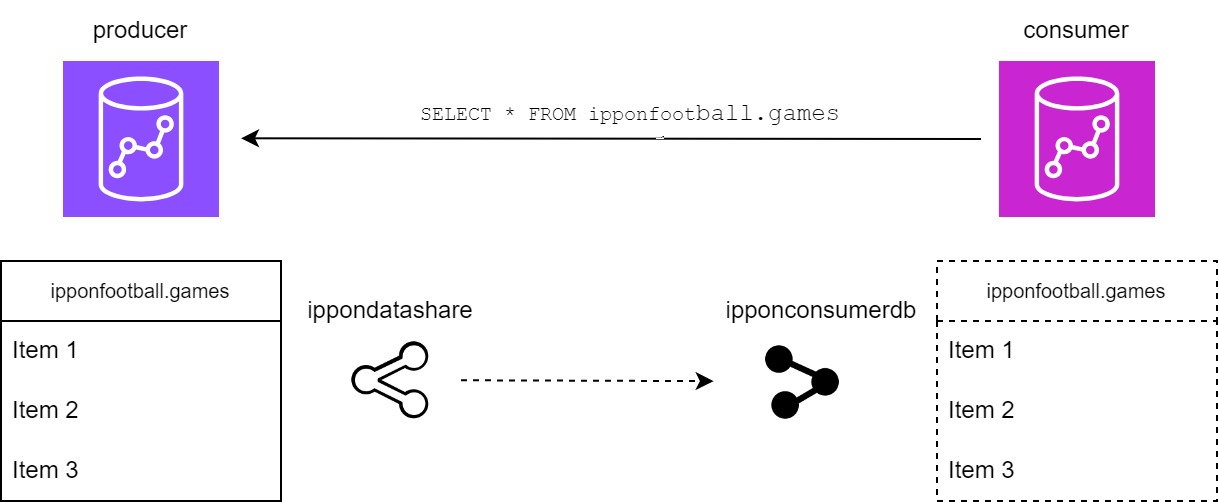
Le partage de données dans Amazon Redshift repose sur la notion de Data Share. Un Data Share est un objet dans Redshift qui contient des informations sur les ensembles de données (tables, vues, etc.) que l'on souhaite partager avec d'autres clusters Redshift. Un Data Share possède un producteur (source de la donnée) et un consommateur (utilisateur de la donnée) et assure la cohérence up-to-date des données entre les deux.
Mise en application
Créons un Data share. Le processus se déroule en plusieurs étapes : la première depuis le cluster producteur, qui est la source du partage de la donnée, et la seconde depuis le cluster consommateur, qui est l'utilisateur de ces données partagées.
D’abord, depuis le cluster producteur :
- Création d'un Data Share : un administrateur de cluster crée un Data Share et y ajoute les objets de données (tables, vues) qu'il souhaite partager.
- Partage avec des consommateurs : l'administrateur partage ensuite le Data Share avec un ou plusieurs clusters consommateurs en spécifiant leurs identifiants. Le namespace ID se situe dans les informations générales du namespace.
- Accès aux données partagées : les clusters consommateurs peuvent alors accéder aux données partagées à travers le Data Share. Les données restent stockées physiquement dans le cluster producteur, mais elles sont accessibles en lecture aux clusters consommateurs comme si elles étaient localement présentes.
Pour voir le Data Share créé avec les informations, utiliser la commande :

Ensuite, passons à la la création du Data Share depuis le cluster consommateur :
- Création de la base de données liée au data share :
- Ajout des permissions d’accès à la base de données :
- Création d’un schéma externe pour utiliser le schéma comme un objet de la base de données principale.
Le consommateur peut maintenant utiliser la table stockée par le producteur comme table ordinaire :
Voici à quoi ressemble le data share que nous venons de créer :
Use cases
1. Isolation des workloads et monitoring
(Workload = charge de travail)
L'isolation de workload fait référence à la capacité d'exécuter différentes tâches sur des clusters distincts afin de s'assurer que chacune d’entre elles n'a pas d'impact sur la performance des autres. Cela permet d’adapter chaque ressource de calcul à ses besoins précis mais aussi de monitorer l'utilisation et les coûts associés à chacune de ces ressources. Redshift fournit des métriques détaillées sur la consommation des ressources informatiques, permettant des modèles précis de FinOps.
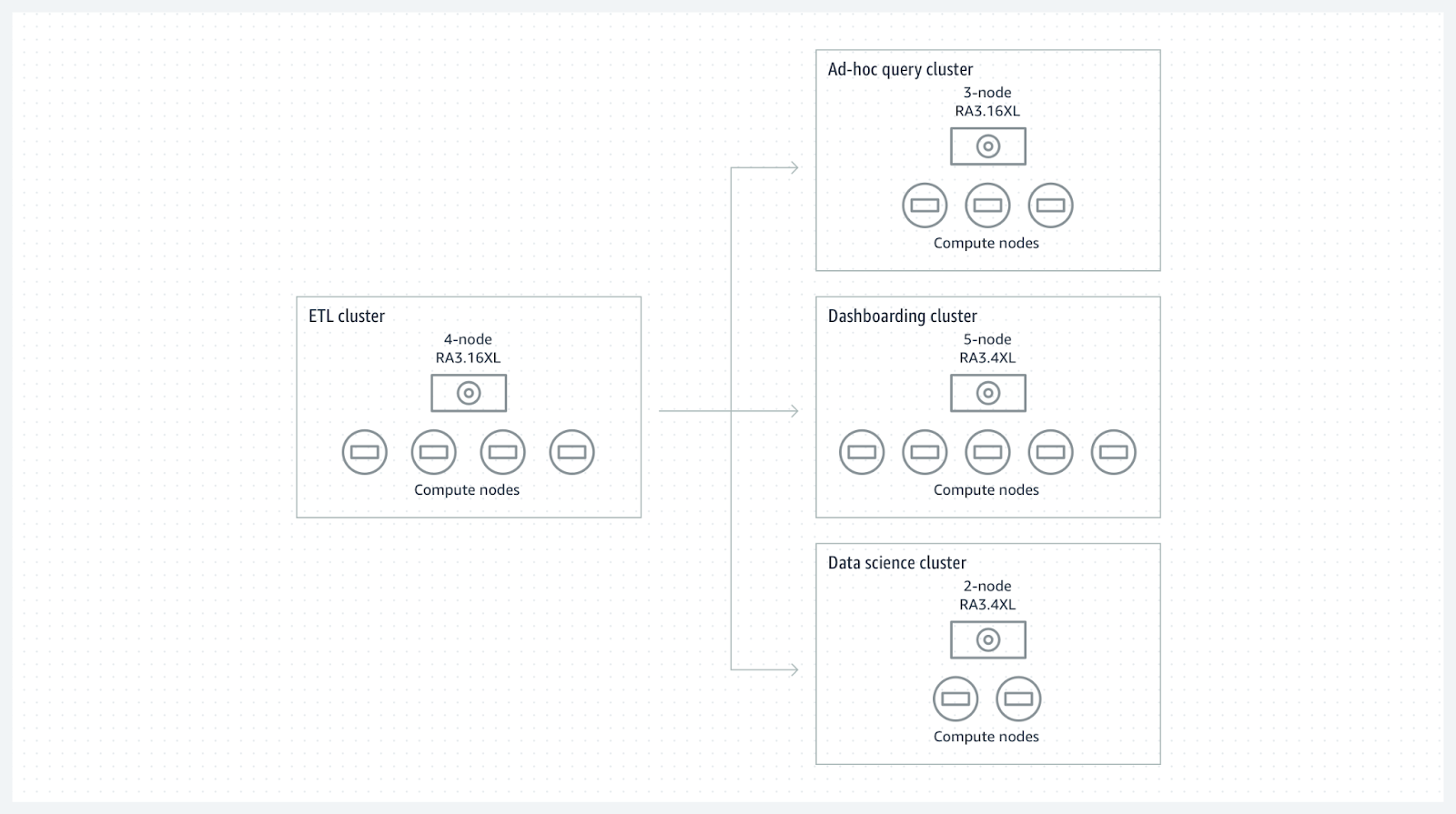
Exemple : la société Ippon a mis en place un pipeline ELT/ETL classique où elle charge des données brutes dans un datawarehouse. Après quelques transformations et agrégations, elle met à disposition ces données propres aux équipes BI qui construisent des dashboards, ainsi qu’aux data scientists qui alimentent des modèles à partir de ces données. Quatre workloads sont isolés :
- Un cluster producteur pour l’ELT/ETL : la puissance de calcul est utilisée pour charger les nouvelles données entrantes et les transformer avec du SQL. Ce cluster exposera donc ces tables aux autres clusters consommateurs.
- Un cluster consommateur pour la BI : pour exposer ses données dans un outil de data visualisation.
- Un cluster consommateur pour la data science : pour implémenter des modèles de machine learning.
- Un cluster consommateur pour l’exploration ad-hoc : pour l’exploration occasionnelle des données via requête SQL.
2. Collaboration cross-group et data mesh
(data mesh = conception d’architecture data décentralisé)
Le concept de data mesh met l'accent sur une architecture décentralisée, où les données sont traitées comme un produit (“data product”) avec une propriété spécifique au domaine (“data domain”). Cette approche favorise la collaboration inter-groupes en permettant aux différentes unités commerciales de partager et d'accéder directement aux produits de données, améliorant ainsi l'agilité et la prise de décision.
Avec le data sharing, chaque équipe ou département peut gérer ses propres données comme un produit, y compris la gouvernance, la qualité et le cycle de vie, tout en permettant l'accès à d'autres départements. Les équipes peuvent partager des ensembles de données à travers différents clusters Redshift sans réplication, rendant ainsi l'accès par d'autres groupes facile et utilisable. Cette configuration favorise un écosystème collaboratif où les données sont facilement et en toute sécurité partagées entre les équipes, améliorant les projets et les initiatives d'analytiques interfonctionnels.
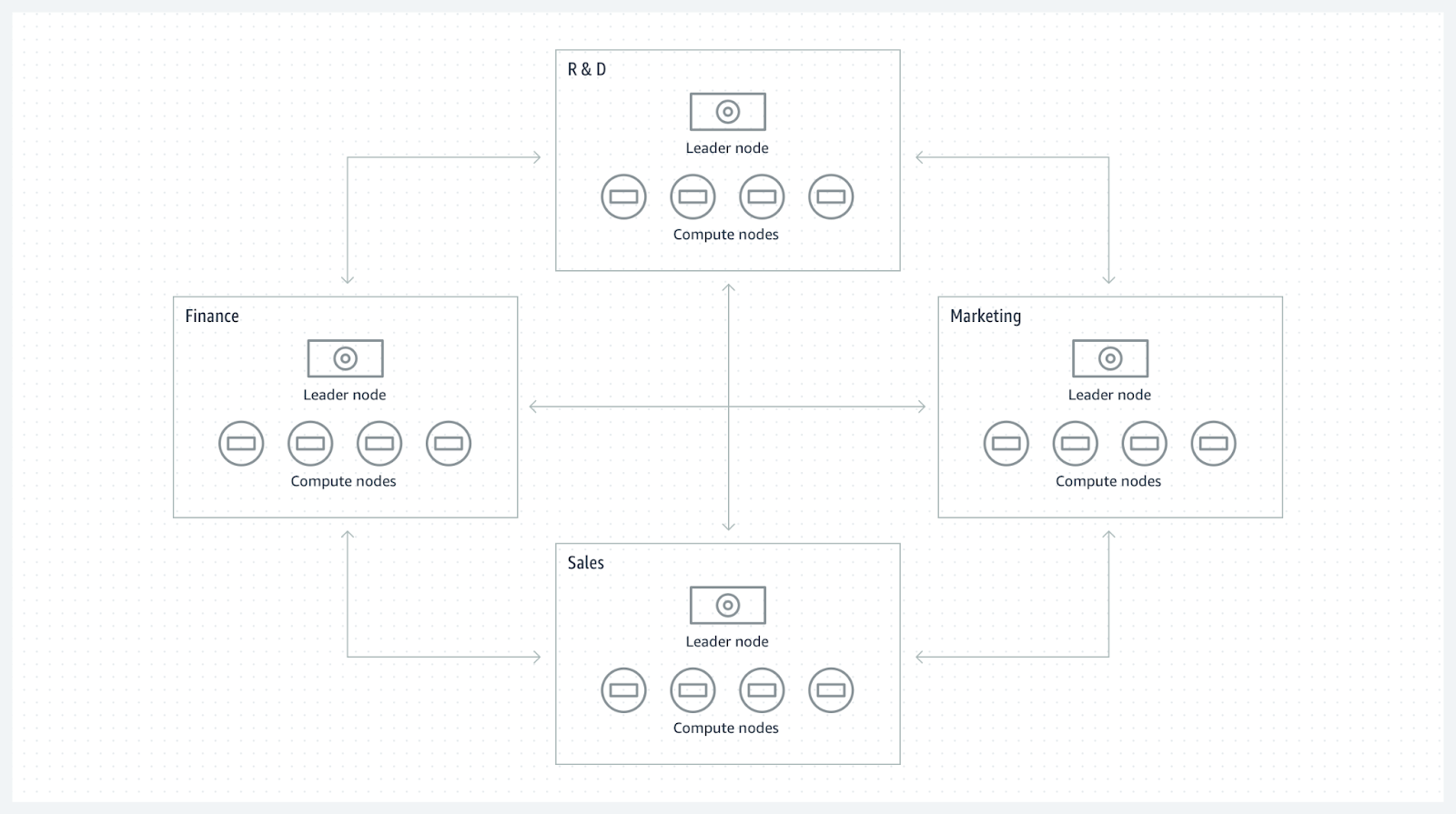
Exemple : la société Ippon met en place une architecture décentralisée avec un data mesh de quatre domaines data correspondant à quatre équipes distinctes : Finance, R&D, Marketing et Sales. Chacune de ces équipes possède un cluster Redshift en data sharing avec le reste de l'organisation. Chacune est responsable de son domaine et donc de son cluster. Elle peut ainsi choisir la taille de calcul à allouer en fonction des besoins de son équipe, de son budget et de ses accès.
3. Data-analytics as a service
Les organisations cherchent de plus en plus à monétiser leurs données en offrant des services analytiques à leurs clients ou partenaires. Le data sharing permet d’exposer comme un endpoint les données vers l'extérieur de manière sécurisée avec des permissions strictes, une gouvernance et un accès en temps réel sans réplication.
Cela permet d'améliorer les collaborations entre organisations/sociétés, le tout permettant de nouveaux modèles commerciaux et flux de revenus.
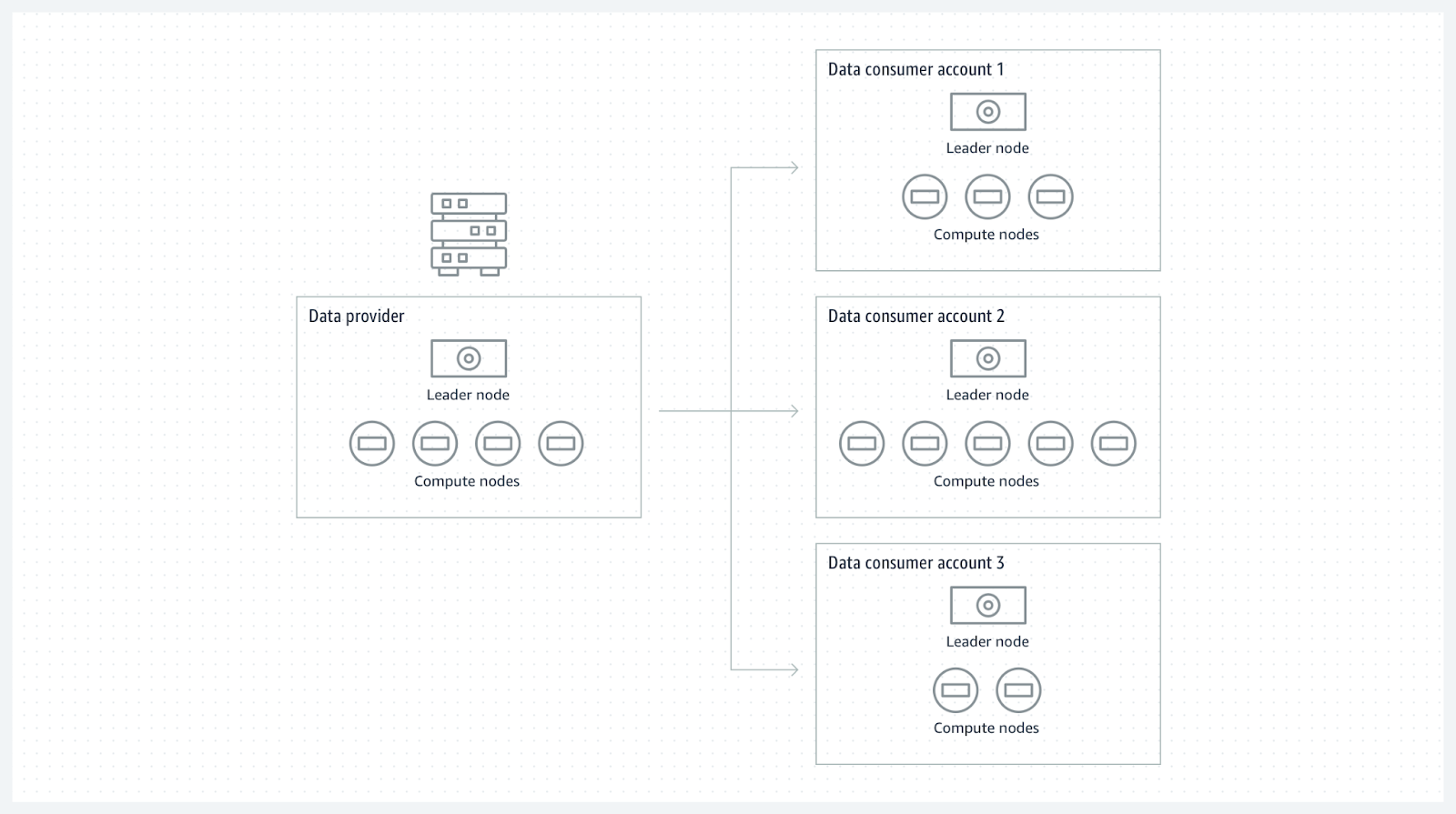
Exemple : la société Ippon souhaite mettre à disposition sa donnée stockée dans Redshift à son nouveau partenaire Cloud qui utilise aussi les services AWS. La société a créé un data share sur les données cibles en donnant accès à son partenaire. Ce dernier n’a plus qu’à utiliser un cluster Redshift pour consommer cette donnée et ainsi effectuer ses propres agrégations. Les principaux avantages sont la source unique de vérité en évitant des coûts supplémentaires de stockage et en donnant un accès privilégié uniquement sur les données concernées par le partage.
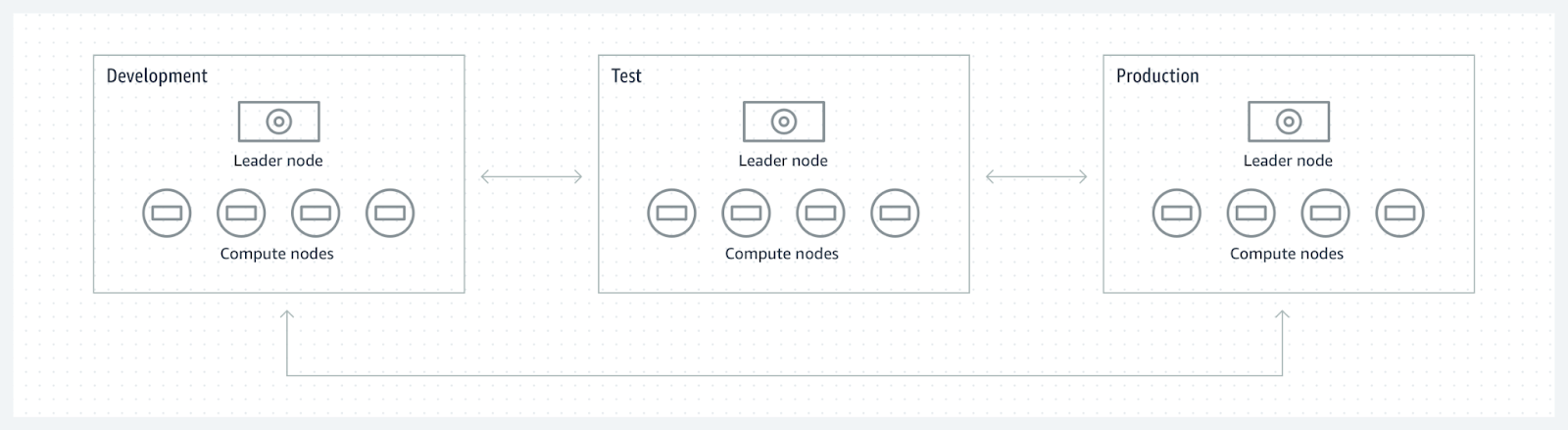
4. Agilité du développement
Le développement rapide et les tests sont cruciaux pour rester compétitifs et avoir une approche DevOps / DataOps. Le data sharing permet aux équipes de développement d'accéder de manière sécurisée aux données de production à des fins de test et d’implémentation, accélérant le cycle de développement. Ils ont la possibilité de travailler dans des clusters Redshift dédiés, sans risquer l'intégrité de l'environnement de production.
Cette approche accélère les cycles de développement mais aussi favorise l'innovation en rendant plus facile pour les stakeholders les expérimentations avec de vraies données dans un environnement contrôlé et up-to-date.
Exemple : la société Ippon souhaite développer de nouvelles features et implémenter un nouveau KPI visant à évaluer les performances d’un client. Pour cela, elle utilise les données dans Redshift et implémente des transformations SQL pour ajouter une colonne dans les tables existantes. Pour tester son code et ne pas impacter les tables de production, elle effectue son développement dans un environnement de test dédié où elle provisionne un cluster Redshift. Un data share a été créé sur les tables de production vers le cluster de test, ce qui permet aux équipes d’utiliser les vraies tables à jour en lecture et de développer leurs transformations dans un environnement de test avant de passer en production.
Conclusion
Dans la course aux plateformes data-analytics et au modern data warehouse, AWS revient en force avec la nouvelle fonctionnalité data sharing de Redshift, permettant la séparation du calcul et du stockage grâce à une couche d’abstraction hot / cold data. Cette élargissement du service s’ajoute à la liste des précédentes intégrations inter-services comme Redshift Spectrum (S3/Glue/lake-formation), zéro-ETL intégration (RDS, DynamoDB), les requêtes fédérées ou encore le connecteur Spark/Redshift (EMR).
AWS compte bien faire de Redshift sa plateforme centrale de data-analytics en prenant part à tous les cœur de métiers : data engineering, data science, data analysis, machine learning et gouvernance data. La principale force de Redshift restant son appartenance totale à l’écosystème AWS, qui rend facile son intégration avec ses autres services.
Amazon compte ainsi tenir tête à ses principaux concurrents dans le domaine des data platforms (Databricks et Snowflake) mais garde encore à son avantage de rester leader du marché Cloud-provider mondial (31% de part de marché en Q4 2023).
Ce 19 Mars 2024 a eu lieu la seconde édition du AWS Analytics - User Group Meetup, cette-fois ci autour de la Generative-AI à travers Redshift. L’objectif de cette nouvelle journée était de montrer comment Redshift évolue pour permettre l’intégration de services ML mais surtout comment le data sharing s’inscrit dans l’évolution du service vers les cas d’usages de demain comme l’Intelligence Artificielle.

Autres article autour de Redshift et d'AWS :