
Objectif : Comprendre comment articuler les avantages d’un orchestrateur autour de ses jobs Spark dans AWS, et en quoi est-ce un game changer ?
Intro et définitions
Apache Spark est l’une des technologies les plus en vogue pour l’analyse et le traitement de données volumineuses. De par sa performance et sa facilité de prise en main (intégrations en langages Scala, Python et SQL), impossible de passer à côté lorsque l’on travaille sur des problématiques big data. Ce framework open-source permet de distribuer un grand nombre de calculs sur des clusters de machines. Ces clusters peuvent être déployés on-premises sur Hadoop/HDFS ou alors de manière entièrement managée dans le Cloud public.C’est cette deuxième méthode que nous allons explorer ici avec la solution “map-reduce” d’AWS : Elastic MapReduce (ou Amazon EMR). Créé en 2009, ce service met à disposition des utilisateurs un cluster Hadoop provisionné sur des machines virtuelles EC2 (possibilité d’utiliser des clusters EKS, nous parlerons uniquement du service “EMR on EC2”). Dès sa première version, le géant américain intègre Spark qui devient le framework le plus exploité via le service. À travers la création de clusters éphémères, EMR permet de paramétrer le nombre d’instances à déployer et de puiser dans des systèmes de stockage de fichiers objets comme Amazon S3 par exemple.Nous verrons aussi comment orchestrer et scheduler ses jobs Spark dans EMR grâce à Apache Airflow. Ce service créé par Airbnb en 2014, permet la gestion de ses jobs et de ses workflows exclusivement en Python à travers une interface web très appréciée du public. Sous licence Apache open-source, cet outil est aussi proposé en mode managé à travers le service d’AWS : Amazon Managed Workflows for Apache Airflow (MWAA). L’avantage d’utiliser MWAA est que vous n’aurez pas besoin de maintenir une version d’Airflow sur Kubernetes par exemple, ce qui est assez difficile à manager. En revanche, l'inconvénient se trouve du côté des montées de versions par AWS qui ont souvent du retard, ce qui dans certains cas peut être problématique.
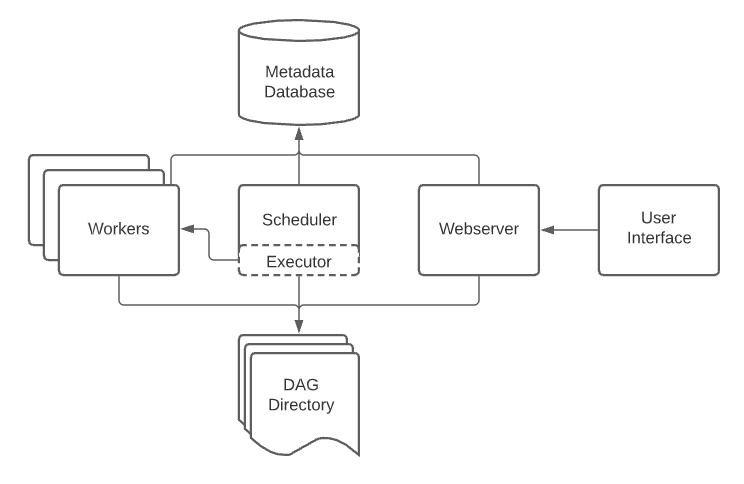
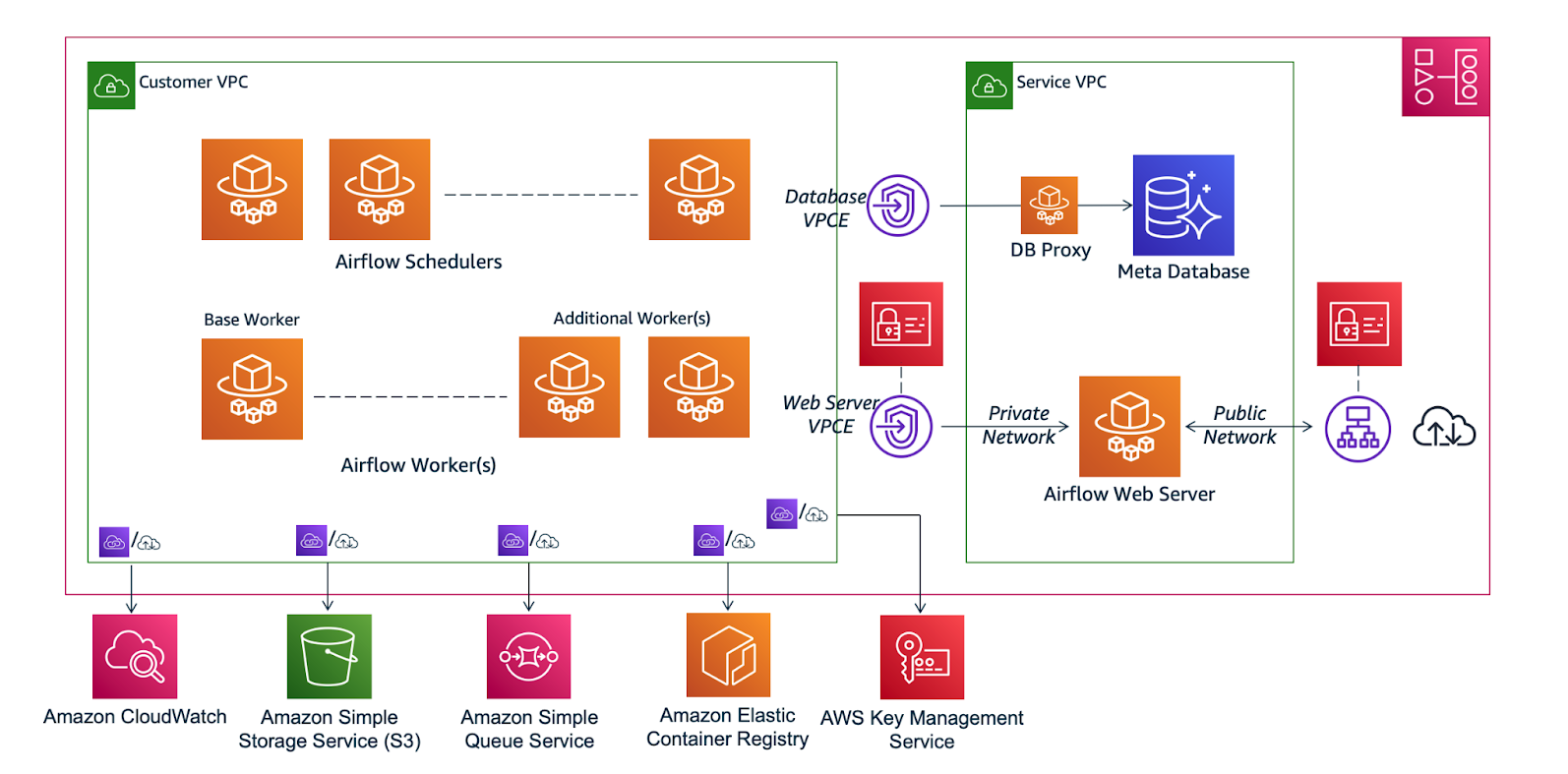
Pourquoi utiliser EMR avec Airflow ?
Les bienfaits d’un orchestrateur managé
Si vous recevez un grand nombre de données à traiter tous les jours, il vous faut paralléliser vos tâches pour gagner en performance et en scalabilité. Spark est le framework de traitement le plus utilisé et plus particulièrement son module Spark SQL, permettant d’appliquer du code sous forme de requêtes de bases de données relationnelles, le tout distribué sur des abstractions de programmation appelé DataFrame.
Lorsque vous devez gérer une dizaine de jobs Spark au quotidien sur un faible volume de données, rien ne vous empêche d’avoir une ou plusieurs machines virtuelles déployées avec un cronjob et renvoyant les logs dans un dossier spécifique. En revanche, cela risque de devenir compliqué lorsque vous passez à cent ou deux-cents jobs qui se lancent toutes les heures pour extraire, transformer et charger des téraoctets de données. D’autant plus qu’il vous faut un système d’alerting et de monitoring en cas de panne pour éviter un retard de livraison et ainsi entraîner le mécontentement de nos amis data scientist et analyst … Tout cela à travers une interface fiable, intuitive et agréable à utiliser. Vous avez besoin d’un orchestrateur ! Le leader dans ce domaine n'est autre qu’Airflow.Airflow repose sur plusieurs principes dont le premier est celui du DAG. Un DAG (pour Directed Acyclic Graph) n'est autre qu’un pipeline orienté ("Directed”) rassemblant un ensemble de tâches qui ne bouclent pas (“Acyclic”) et qui représentent des objets dépendants et en relation (“Graph”).
Chaque DAG est composé de tâches elles-mêmes représentées via des opérateurs. Parmi les opérateurs basiques, nous avons :
- BashOperator: pour exécuter un script Shell ou Bash.
- PythonOperator: pour exécuter un script Python.
- EmailOperator: pour envoyer un simple e-mail à travers les workers.
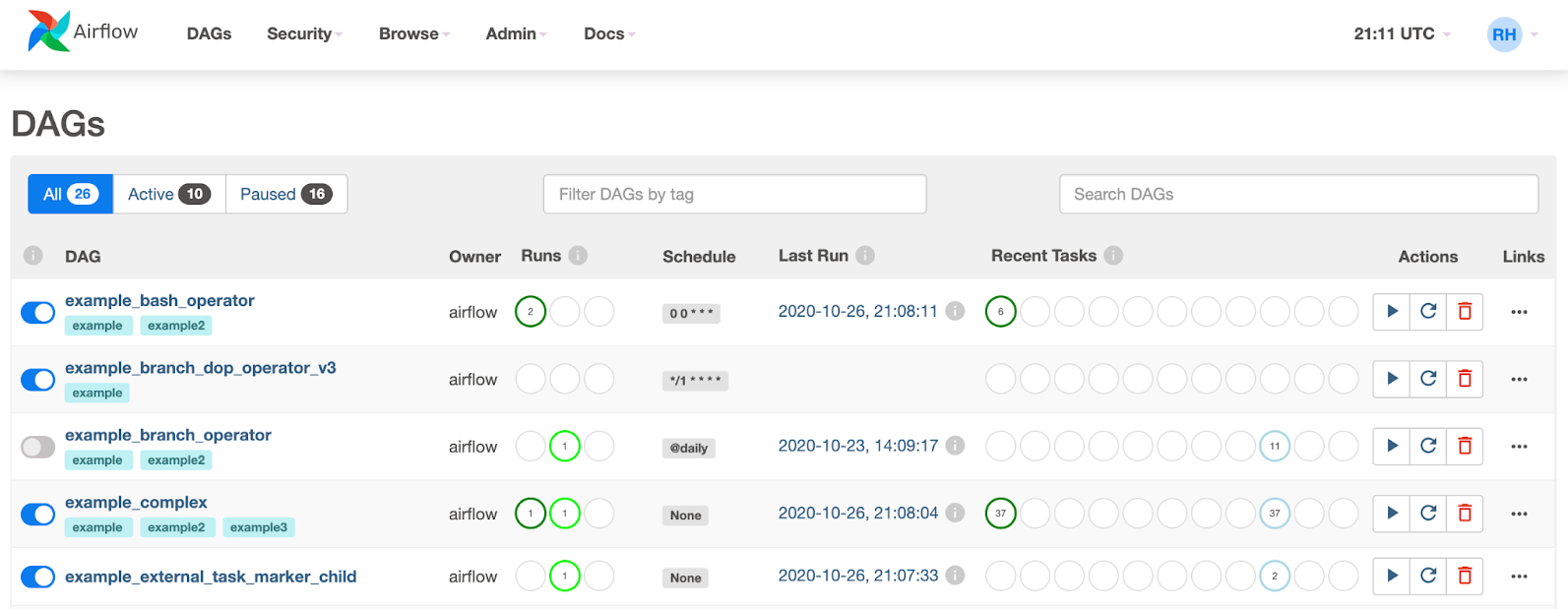
Voici un exemple d’un DAG simple :
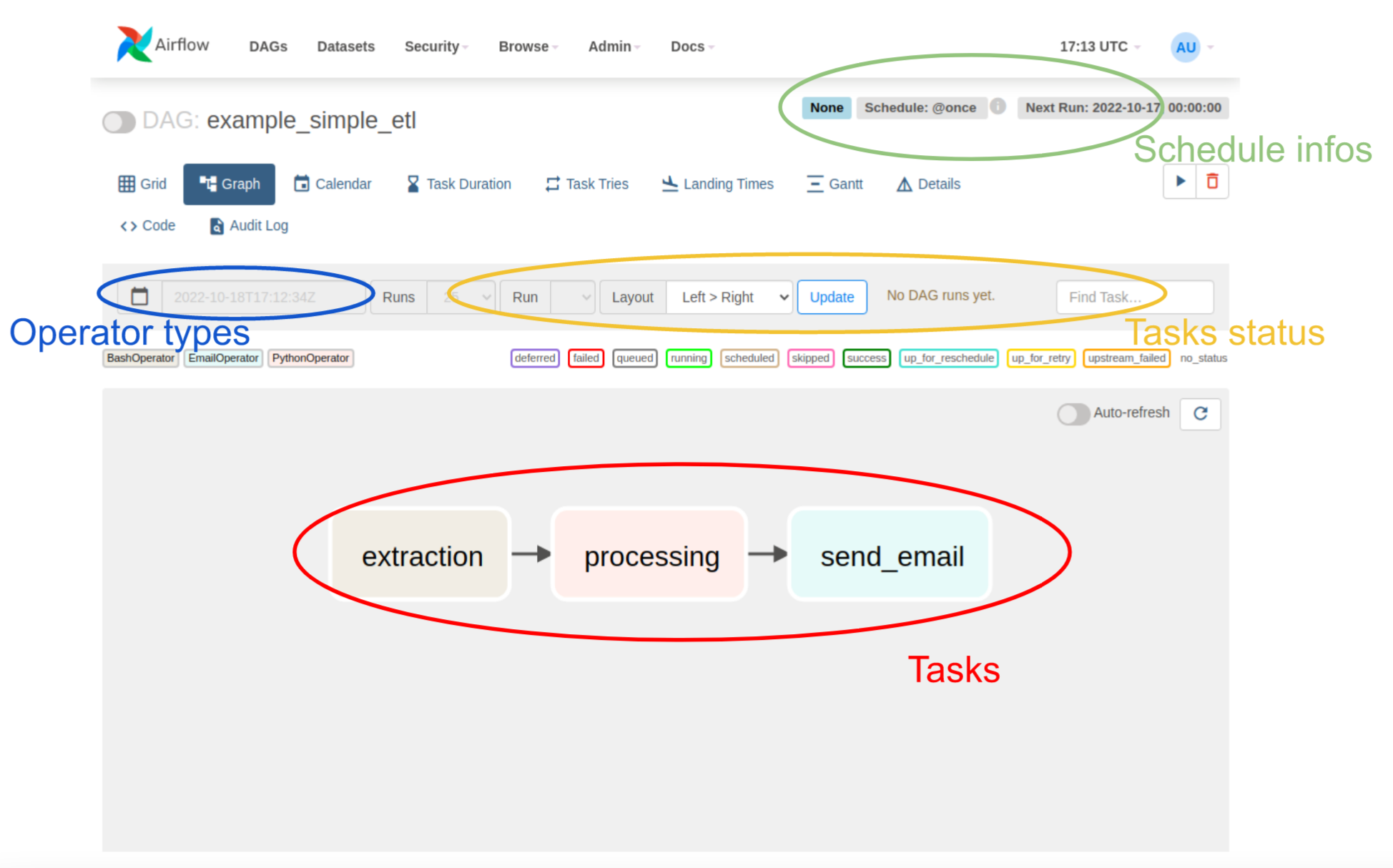
Et voici son code Python :
import dags_utils as utils
from datetime import timedelta
from airflow import DAG
from airflow.operators.bash import BashOperator
from airflow.operators.python import PythonOperator
from airflow.operators.email import EmailOperator
from airflow.utils.dates import days_ago
with DAG(
dag_id="example_simple_etl",
dagrun_timeout=timedelta(hours=2),
start_date=days_ago(1),
schedule_interval='@once'
) as dag:
extraction = BashOperator(
task_id='extraction',
bash_command='sh extract_daily_news.sh'
)
def filter_html_content(user):
return utils.filtered_html_for_user(user)
processing = PythonOperator(
task_id='processing',
python_callable=filter_html_content('John Doe')
)
send_email = EmailOperator(
task_id='send_email',
to='john.doe@gmail.com',
subject="Hello John, here's your daily news !",
html_content=f"Date: {{ ds }},
{utils.read_filtered_html_content()}"
)
extraction >> processing >> send_emailAirflow possède un grand nombre d'opérateurs qui permettent notamment d'interagir avec les services des différents cloud providers : Operators and Hooks Reference.
Les 3 opérateurs qui vont donc nous intéresser sont les suivants :
- EmrCreateJobFlowOperator : création et démarrage du cluster.
- EmrAddStepsOperator : ajouter un ou plusieurs steps à votre job flow.
- EmrWatchStepsOperator : détecte et écoute le step en running.
- EmrTerminateJobFlowOperator : extinction et suppression du cluster.
Dans les paramètres de ces opérateurs vous pouvez ainsi renseigner : le nombre de nœuds “maîtres”, le nombre de nœuds “esclaves”, le type d’instances EC2 (m5.xlarge, c5.2xlarge …), le type d’applications (Hive, Spark …), le resource manager (yarn, mesos, standalone …), le chemin vers votre application (fichier jar par exemple), les tags attribués à votre cluster ainsi que les rôles et security group qui seront attribués aux instances EC2.
En cas d’échec de tâches, Airflow propose aussi de mettre en place des “retry” c’est-à-dire de relancer la tâche en échec un certain nombre de fois jusqu’à la considérer réellement en faillite et qu’elle nécessite réparation. Par exemple, si un cluster échoue au démarrage à cause d’une erreur de bootstrapping AWS, ou alors si une API est en surcharge de requêtes, Airflow va automatiquement relancer la tâche après un certain délai.
Grâce à Airflow, on a donc une interface permettant de scheduler ses tâches, de manager ses pipelines à travers une interface web et de gérer la création et l’extinction de ses clusters Spark éphémères, le tout via des flows de tâches appelé DAG.
"Workflow as code"
Airflow est entièrement écrit en Python. Ce qui rend l’outil dynamique et facile à prendre en main étant donné qu’il s’agit du langage le plus utilisé par les data engineers.Un DAG s’instancie grâce à la classe ‘airflow.DAG’ :
dag = DAG(
dag id='demo1',
schedule_interval='0 * * * *',
start_date=datetime(2023, 1, 24)
)Le DAG “demo1” s'exécutera toutes les heures à partir du 24 Janvier 2023.Comme dit précédemment, un opérateur est un type de tâche qui peut prendre plusieurs formes. Grâce au principe de polymorphisme de Python, il est assez facile de customiser ces opérateurs de bases pour les adapter à son usage. Par exemple un opérateur pour exécuter dbt sur une image Docker, ou encore un monitoring operator qui pousse certaines métriques liées au dag dans Prometheus (on utilisera les classes mères DockerOperator et PythonOperator avec boto3).Il est donc aussi possible de customiser un opérateur “EmrCustomOperator” à partir des classes mères fournies par Airflow en préconfigurant le nombre d'instances et le CPU jusqu’au rôle IAM et security-group utilisé par les instances.Ainsi, n’importe quel développeur qui a besoin de créer son job peut utiliser ce "EmrCustomOperator" qui aura déjà tous les paramètres de bases et unifiés de votre plateforme data. Cela apporte de la flexibilité autour d’un environnement de travail centralisé, de la sécurité et un gain en performance considérable en créant un pipeline de données en quelques minutes.
Aussi, la variété des opérateurs et de leurs providers permet d’être flexible sur n’importe quel service d’AWS ou multi-cloud (Redshift, K8s, Snowflake, BigQuery …).
Parlons argent $
Il faut savoir que Amazon EMR ne facture que lorsque le cluster est activé, et non lors des étapes de bootstrap et de mise en service des machines. La tarification se compose d’une partie EMR, et d’une partie EC2. Le prix varie en fonction du type d’instance choisie et du temps d'exécution. Plus d’infos ici : Amazon EMR Pricing. Pour optimiser au mieux les coûts de son pipeline, il faut donc adapter ses clusters éphémères en fonction de ses besoins spécifiques. L’idée est qu'aucune ressource ne doit être sous-exploitée ni sur-exploitée. Pour cela il faut choisir le nombre d’exécuteurs par machine et le type de machine en fonction de la balance CPU / RAM / Disk dont nous avons besoin. Il faut éviter que des exécuteurs soient au repos à cause d’un mauvais paramétrage du cluster. Ceci peut être facilement vérifié à travers la Spark UI du cluster mise à disposition par dans EMR sous forme de page web. Nous pouvons voir ce qu’il se passe en détail au sein du cluster : chaque ressources utilisées avec les logs de tous les exécuteurs ainsi que les étapes de traitements.
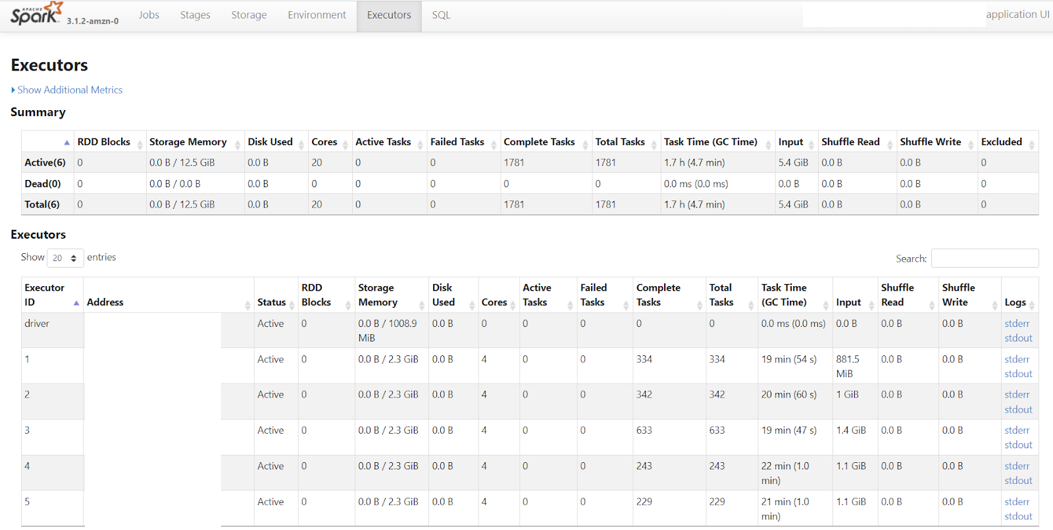
Pour éviter les grosses factures avec des clusters qui restent en attente des heures et/où qui ne sont pas éteints, il faut s’assurer que l'étape EmrTerminateJobFlowOperator ait bien été exécutée. Pour cela, Airflow peut retry cette tâche en cas de fail et si cela persiste, il est possible d’en alerter l'utilisateur à travers un opérateur de webhook spécialement conçu pour l’alerting dans Slack (operator SlackAPIPostOperator). On peut ainsi envoyer des alertes dans un canal commun jusqu’à ce que le dag soit réparé.


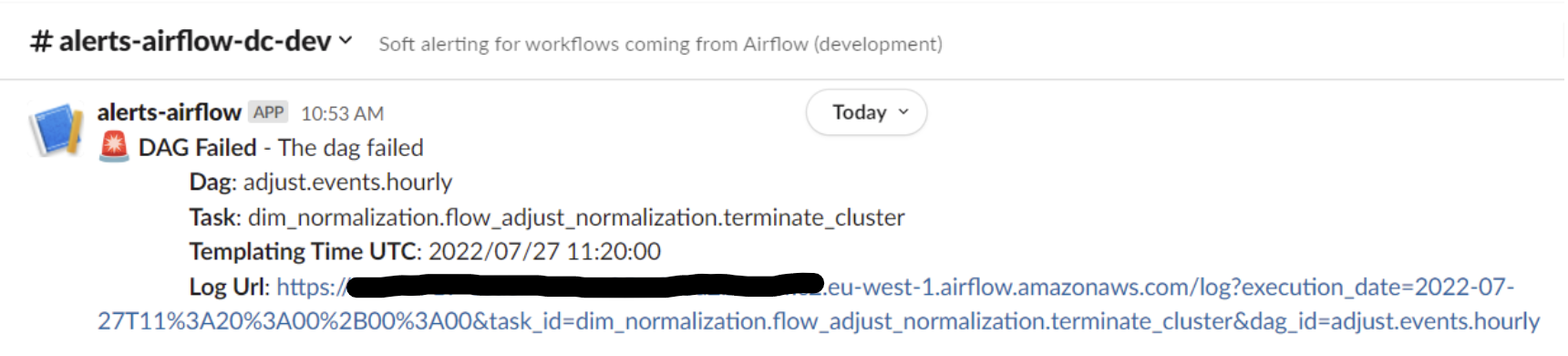
Pour assurer la bonne extinction des clusters, il est aussi possible d’utiliser plusieurs options d’Amazon EMR :
- 'KeepJobFlowAliveWhenNoSteps' : False → s’assurer que le cluster ne reste pas en attente lorsque toutes les étapes ont été effectuées.
- 'TerminationProtected' : False → s’assurer de pouvoir éteindre le cluster à n’importe quel moment de son exécution.
- Auto-termination-policy / IdleTimeout (depuis EMR 5.30) → permet de configurer un temps de timeout au-dessus duquel le cluster sera automatiquement éteint lorsque qu'il est en attente. Cette option n'est pas directement gérable via l'operateur d'Airflow. En revanche, il facilement possible de customiser l'operateur existant en utilisant l'API d'Amazon.
Enfin, il est possible de paramétrer EMR pour utiliser des EC2 spot instance, ce qui peut réduire considérablement les coûts. Utiliser Airflow, c’est créer une dépendance entre les DAG pour s’assurer qu’un job ne s’exécute pas tant qu’un autre n’est pas terminé où qu'une donnée n’est pas présente. Il s’agit des opérateurs de types “sensor” :
- ExternalTaskSensor (attend qu’une certaine tâche d’un DAG soient en success)
- S3KeySensor (attend qu’un objet soit présent avecun certain préfixeS3)
- TriggerDagRunOperator (démarre un DAG tier n’ayant pas de schedule)
- @Dataset (depuis Airflow 2.4, attend qu'un certain nombre de fichiers aient été updatés par un ou plusieurs DAG).
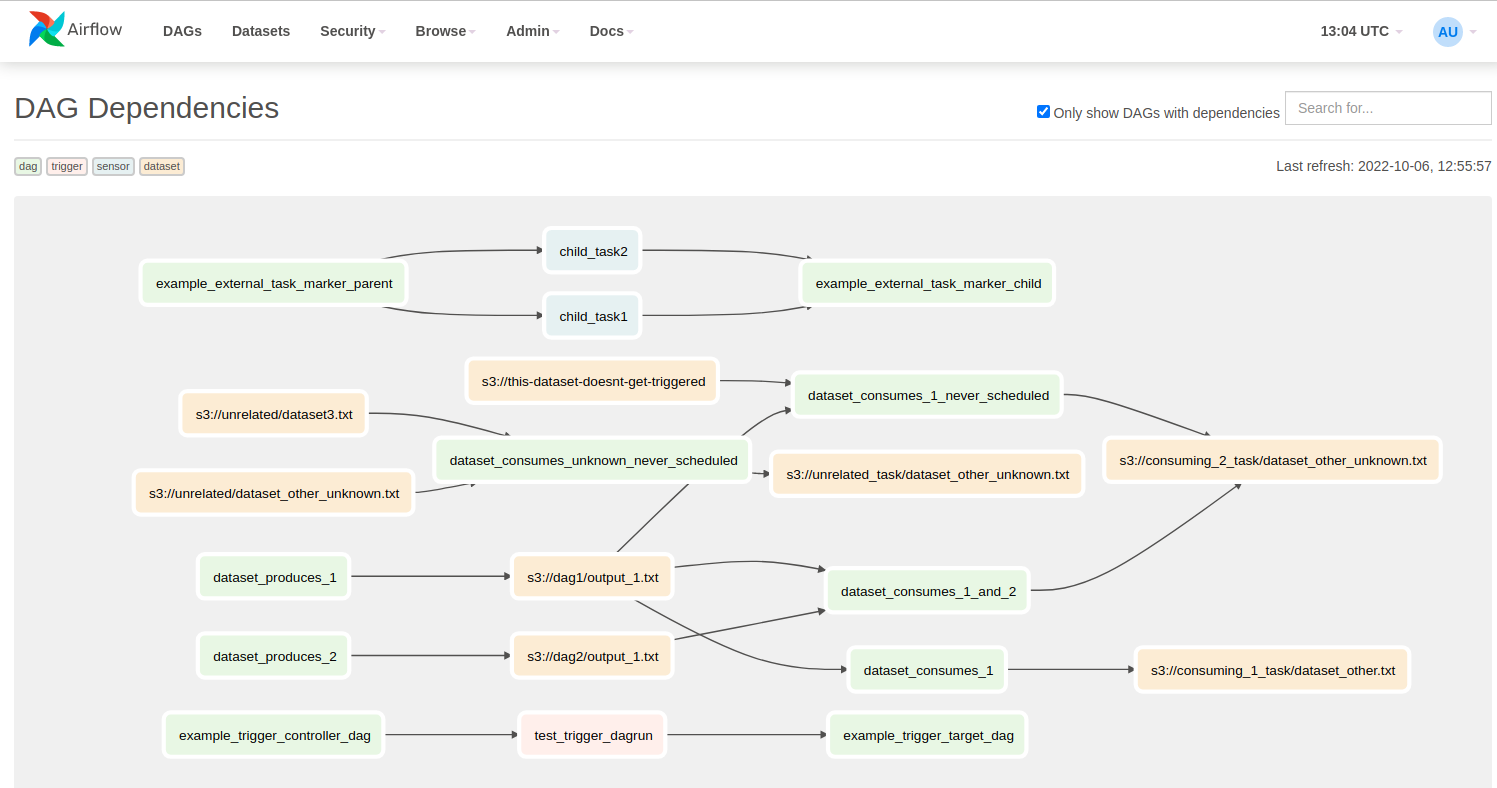
On peut voir ici les différents DAG et leurs dépendances (trigger, sensor, dataset …).
Use case : transformation de données daily from S3 to S3
Nous allons créer notre premier dag. L’idée est simple : nous avons des fichiers en entrée au format csv dans s3://my-S3-Bucket/raw-data/. À travers une application Spark préalablement compilée et stockée dans s3://my-S3-Bucket/jars/app-test-emr-job-1.0.0.jar dans la classe com.ippon.AppTestMyEmrJob, nous allons transformer ces données et les exporter au format parquet compressé vers s3://my-S3-Bucket/transformed-data/.
Ce pipeline tourne tous les jours à minuit et prend en paramètres le préfixe d'entrée, le préfixe de sortie, et la date d'exécution du dag. Pour cela, Airflow utilise le Jinja templating qui permet de déclarer des variables datées : “{{ ds }}” correspond à la date du DAG run. Le cluster déployé possède 1 driver et 3 exécuteurs, de type 'm5.x large'.
Définissons notre DAG Airflow :
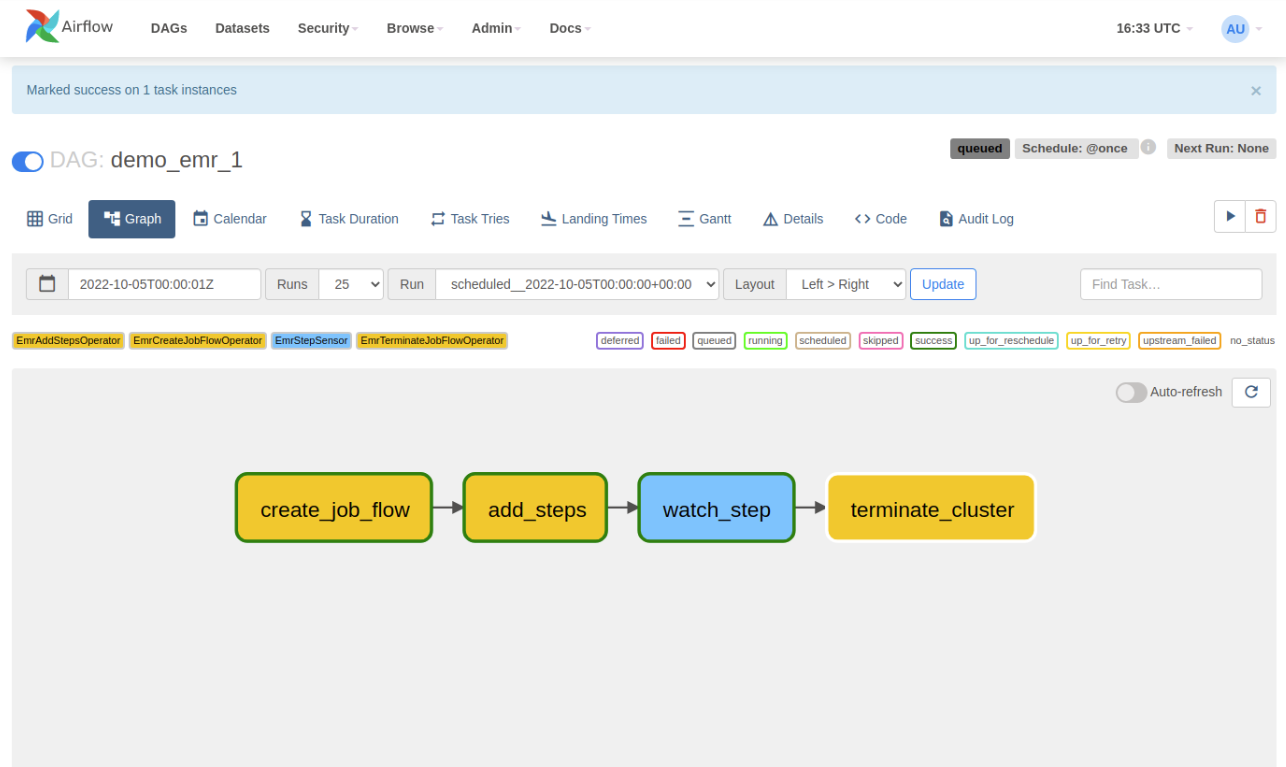
Voici le code python de notre projet :
import os
from datetime import timedelta, datetime
from airflow import DAG
from airflow.providers.amazon.aws.operators.emr import EmrCreateJobFlowOperator, EmrAddStepsOperator, EmrTerminateJobFlowOperator
from airflow.providers.amazon.aws.sensors.emr import EmrStepSensor
from airflow.utils.dates import days_ago
DAG_ID = os.path.basename(__file__).replace(".py", "")
DEFAULT_ARGS = {
'owner': 'Ippon',
'depends_on_past': False,
'email': ['airflow@ippon-example.com'],
'email_on_failure': False,
'email_on_retry': False,
}
SPARK_STEPS = [
{
'Name': 'my_test_step',
'ActionOnFailure': 'CONTINUE',
'HadoopJarStep': {
'Jar': 'command-runner.jar',
'Args': [
'spark-submit',
'--class', 'com.ippon.AppTestMyEmrJob',
'--deploy-mode', 'cluster',
'--master', 'yarn',
's3://my-S3-Bucket/jars/app-test-emr-job-1.0.0.jar',
'--source=', 's3://my-S3-Bucket/raw-data/*csv',
'--target=', 's3://my-S3-Bucket/transformed-data/',
'--date=', '{{ ds }}'
],
},
}
]
JOB_FLOW_OVERRIDES = {
'Name': 'my-demo-cluster',
'ReleaseLabel': 'emr-5.36.0',
'Applications': [
{
'Name': 'Spark'
},
],
'Instances': {
'InstanceGroups': [
{
'Name': "Master nodes",
'Market': 'ON_DEMAND',
'InstanceRole': 'MASTER',
'InstanceType': 'm5.xlarge',
'InstanceCount': 1,
},
{
'Name': "Slave nodes",
'Market': 'ON_DEMAND',
'InstanceRole': 'CORE',
'InstanceType': 'm5.xlarge',
'InstanceCount': 3,
}
],
'KeepJobFlowAliveWhenNoSteps': False,
'TerminationProtected': False,
'Ec2KeyName': 'mykeypair',
},
'VisibleToAllUsers': True,
'JobFlowRole': 'EMR_EC2_DefaultRole',
'ServiceRole': 'EMR_DefaultRole'
}
with DAG(
dag_id=DAG_ID,
default_args=DEFAULT_ARGS,
dagrun_timeout=timedelta(hours=2),
start_date=datetime.today(),
schedule_interval='@daily',
tags=['emr'],
) as dag:
cluster_creator = EmrCreateJobFlowOperator(
task_id='create_job_flow',
job_flow_overrides=JOB_FLOW_OVERRIDES
)
step_adder = EmrAddStepsOperator(
task_id='add_steps',
job_flow_id="{{ task_instance.xcom_pull(task_ids='create_job_flow', key='return_value') }}",
aws_conn_id='aws_default',
steps=SPARK_STEPS,
)
step_checker = EmrStepSensor(
task_id='watch_step',
job_flow_id="{{ task_instance.xcom_pull('create_job_flow', key='return_value') }}",
step_id="{{ task_instance.xcom_pull(task_ids='add_steps', key='return_value')[0] }}",
aws_conn_id='aws_default',
)
cluster_remover = EmrTerminateJobFlowOperator(
task_id='terminate_cluster',
job_flow_id="{{ task_instance.xcom_pull('create_job_flow', key='return_value') }}",
)
cluster_creator >> step_adder >> step_checker >> cluster_removerLes “XComs” d’Airflow permettent aux tasks de communiquer entre elles. Nous les utilisons ici pour transmettre l’identifiant du cluster et de l'étape créée, ce qui permet au EmrStepSensor de savoir où écouter, et au EmrTerminateJobFlowOperator de connaître le cluster à éteindre.
Les rôles IAM 'EMR_DefaultRole' et 'EMR_EC2_DefaultRole' sont les rôles par défaut lorsque l’on crée un cluster EMR. Ils ont les autorisations suffisantes pour que le cluster puisse communiquer entre ses machines et aussi vers l'extérieur. Afin d’être plus “least privilege access” compliant, il est préférable de créer ses propres IAM rôles avec Terraform en ne laissant que les bucket s3 nécessaires communiquer avec les instances EC2.
Une fois le cluster EMR crée, on peut observer ses infos dans la console AWS :
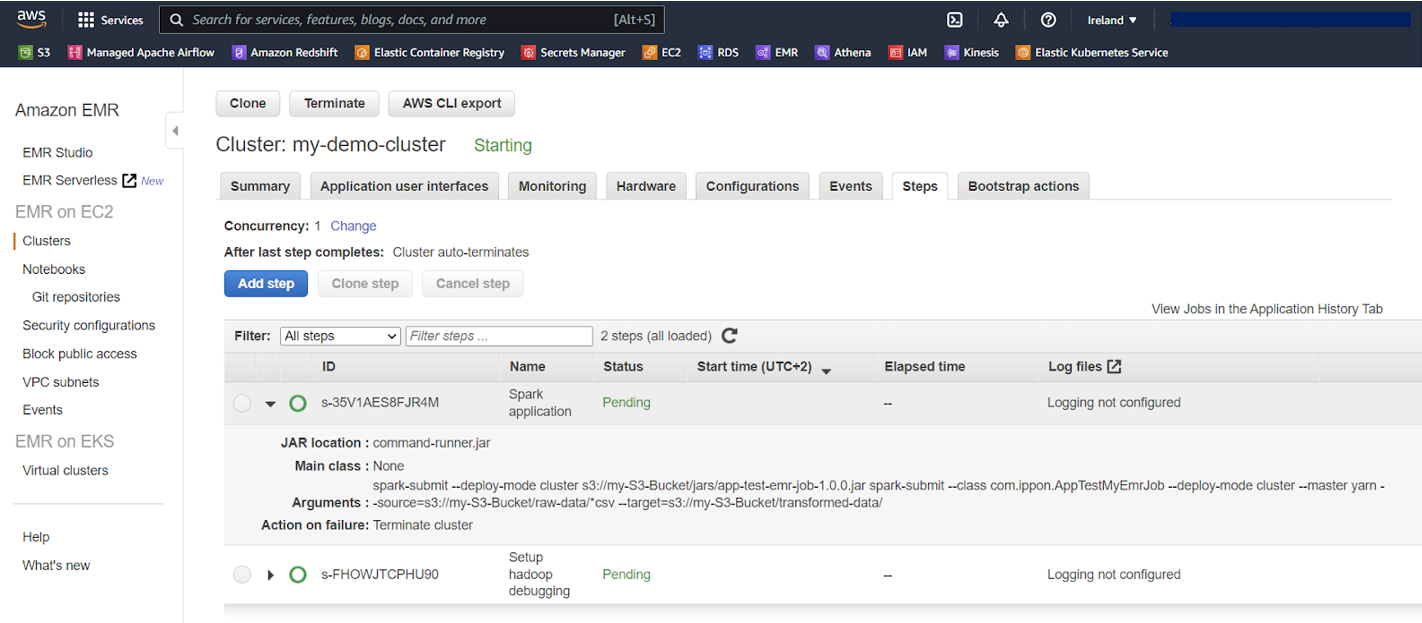
Ici, nous avons utilisé les paramètres 'ActionOnFailure': 'CONTINUE' et 'KeepJobFlowAliveWhenNoSteps': False. Le cluster va donc exécuter toutes les tâches qu’on lui ajoute (une seule en l'occurrence) et va automatiquement s’éteindre une fois toutes les tâches effectuées.
Nos données transformées sont maintenant disponibles dans S3 et prêtes à être consommées ! On peut ensuite imaginer avoir un crawler Glue pour les cataloguer en tant que table puis les requêter via Athena.
Conclusion
Apache Airflow permet d’avoir une vue d’ensemble d’un grand nombre de pipelines que compose une plateforme data. Il centralise aussi les technologies utilisées au sein d’un même outil. En revanche, les workers d’Airflow ne sont pas optimaux pour des calculs à très hautes volumétries. La meilleure façon d’utiliser cet outil est de le laisser n’être que le “chef d’orchestre” de votre plateforme pour donner l’ordre aux autres “instruments” de s'exécuter pour être en accord avec les autres : Spark, DBT, Kubernetes, Redshift … tout cela est possible grâce aux nombreux connecteurs développés par la communauté.
Le connecteur Amazon EMR permet de gérer ses nombreux clusters éphémères à partir d’instances EC2 et à travers une interface fiable en exécutant des applications Spark distribuées sur le Cloud AWS.
Airflow est un leader sur le marché des orchestrateurs open-source et a su évoluer avec son temps en adaptant ses connecteurs et son interface grâce à sa communauté active. Néanmoins, cet outil n’est pas parfait surtout en termes de maintien d’infrastructure et d’autres entreprises proposent des orchestrateurs totalement managés comme Dagster Cloud ou Prefect. Databricks, l’entreprise qui a créé Spark, propose aussi depuis peu son propre outil d’orchestration de jobs distribués.
