
Contexte
Notre client, spécialisé dans le marketing, dispose d'un historique de plusieurs centaines de millions d'événements d’achat. Les objectifs de ce client sont d’analyser le parcours des consommateurs, d’identifier les habitudes d’achats (affinité à une marque) et surtout,de prédire le comportement du consommateur, en particulier le contexte qui va générer un acte d’achat.
Pour réaliser ce type d’analyse et de prédictions il est nécessaire d’utiliser une dimension centrée sur l’individu (noté Individu dans la suite du document) qui va permettre de rapprocher l’ensemble des événements liés à un même individu. Problème : Cette information n’est pas disponible dans le dataset du client.
Notre objectif est donc ici de trouver une solution pour générer cette information, en levant les difficultés suivantes :
- l’absence d'identifiant d’individu naturel (ie. ID...) dans le dataset initial ;
- l’incomplétude des données, leur invalidité et leur stockage anarchique.
Présentation des données
Les données du client sont stockées en CSV, elles ont été saisies par des opérateurs via différents systèmes d’information. Les données sont donc très hétérogènes et disparates. Des fautes, des oublis de saisie (trait d’union dans les prénoms, villes inconnues, code postal incomplet, etc.) sont régulièrement présents. Certaines informations sont mêmes fusionnées dans une seule colonne.
Voici un exemple illustratif de données sur lesquelles nous avons travaillé :
| NOM | ADRESSE | CP | COMMUNE | ... |
|---|---|---|---|---|
| Doe John | 47 Avenue de la Grande-Armée | 75 | Paris | ... |
| John | Avn de la Grande Armée | 75116 | Paris | ... |
Aussi, pour associer à chaque événement une dimension Individu nous mettons en place le processus suivant :
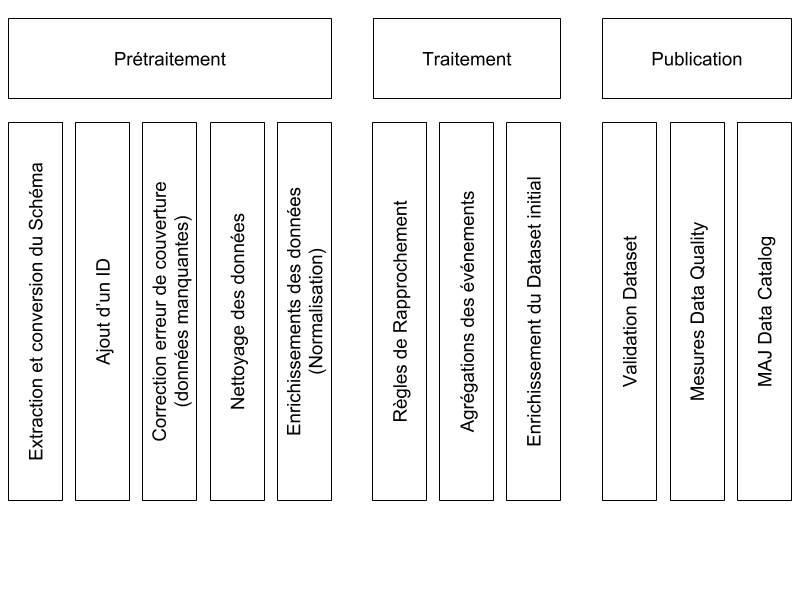
Ce processus est découpé en trois grandes étapes :
- Prétraitement : nettoyage, enrichissement des données... ;
- Traitement : rapprochement des évènements, enrichissement du dataset... ;
- Publication : validation et publication du dataset final
Frameworks.
Pour réaliser les différents traitements nous utilisons Spark 2.1.
Nous analysons nos données avec Apache Drill. Cet outil est un moteur SQL qui permet de consulter simplement des datasets. Il a l’avantage de prendre en charge de nombreux formats de stockage : CSV, Parquet, JSON, SGBD, NoSQL...
Les prétraitements mis en oeuvre
Pour rapprocher les événements sous un même individu, nous avons besoin de nettoyer les données en amont. Dans cette partie nous présentons 3 méthodes appliquées sur le dataset du client.
Consolidation et création d’un identifiant unique
Ce prétraitement permet :
- d'agréger toutes les sources de données dans un seul dataset ;
- de générer un identifiant unique pour chaque événement ;
- de consolider les données dans les bonnes colonnes.
Le format de sortie que nous avons retenu est le format Parquet, car il est naturellement supporté par nos différents outils (Spark, Apache Drill). De plus le stockage en colonnes est particulièrement efficace pour les agrégations, qui sont utilisées dans les règles de rapprochement qui seront appliquées par la suite.
Après ce prétraitement, nos données sont complétées de la sorte :
| ID | NOM | ADRESSE | CP | COMMUNE | ... |
|---|---|---|---|---|---|
| 1 | Doe John | 47 Avenue de la Grande-Armée | 75 | Paris | ... |
| 2 | John | Avn de la Grande Armée | 75116 | Paris | ... |
RNVP (Restructuration, normalisation et validation postale)
L’adresse d’une personne est une composante intéressante à utiliser dans le cadre de nos règles de rapprochement. Cependant nous remarquons que nous ne pouvons pas comparer directement les chaînes de caractères.
Par exemple, les deux entrées suivantes ne sont pas comparables :
| 47 Avenue de la Grande-Armée 75116 Paris |
| 47 AVN Grde Armée 75000 Paris |
Comme notre objectif est d’obtenir un matching parfait, nous n'utilisons pas de méthode de comparaison de caractère imprécise, comme par exemple la distance de Levenstein.
Nous utilisons donc un outil de RNVP pour normaliser les adresses. Cet outil permet de formater une adresse en respectant la norme postale (cf AFNOR NF Z 10-011).
En appliquant un traitement RNVP, on obtient pour les 2 adresses de l’exemple ci-dessus :
| Ligne 4 | 47 AVENUE DE LA GRANDE ARMEE |
| Code Postal | 75116 |
| Localité | PARIS |
À partir des référentiels postaux, l’outil de normalisation que nous utilisons permet d’obtenir en plus :
- un identifiant unique pour la voie (voie + localité) : HEXAVIA ;
- un identifiant unique pour l'adresse (Numéro + voie + Localité) : HEXACLE.
C’est à dire que l’exemple précités se composent des champs suivants :
| Ligne 4 | 47 AVENUE DE LA GRANDE ARMEE | ||||
| Code Postal | 75116 | ||||
| Localité | PARIS | ||||
| HEXAVIA | 01456889 | ||||
| HEXACLE | 75116IPPON |
| ID | NOM | ... | HEXAVIA | HEXACLE |
|---|---|---|---|---|
| 1 | Doe John | 01456889 | 75116IPPON | |
| 2 | John | 01456889 | 75116IPPON |
Nettoyage et normalisation des noms et prénoms
Dans les événements, les données liées au prénom et au nom sont fusionnées dans la même colonne. Dans certains cas, nous ne disposons que du prénom de l’individu. Notre objectif ici est donc de nettoyer et normaliser ces entrées imparfaites. Pour réaliser ce prétraitement nous utilisons la solution Normad qui permet d’identifier entre autre le nom et le prénom.
Cependant, cette solution ne fonctionne pas dans le cas ou le nom est un prénom (ex : NICOLAS SEBASTIEN). En étudiant les données, nous mettons en évidence la règle suivante : le nom est toujours saisi avant le prénom. Cette règle permet alors de lever cette ambiguïté.
Ainsi le dataset final se présente sous la forme suivante :
| ID | ... | HEXAVIA | HEXACLE | NOM_NORM | PRENOM_NORM |
|---|---|---|---|---|---|
| 1 | 01456889 | 75116IPPON | Doe | John | |
| 2 | 01456889 | 75116IPPON | John |
Règles de rapprochement
Après la phase de prétraitement, nous disposons d’un dataset propre pour mettre en place le rapprochement entre les événements.
Nous mettons en place 5 règles de rapprochement dont voici deux exemples :
- Deux événements concernent la même personne s'ils ont les mêmes nom, prénom, hexacle... ;
- Deux événements concernent la même personne s'ils ont les mêmes prénom, hexavia...
Pour implémenter les règles nous avons utilisé l'API SQL de Spark. Les règles sont simples et s’implémentent de la manière suivante :
select collect_set(id), nom, prenom, adresse from mouvement
where not_blank(nom) and not_blank(prenom) and not_blank(hexacle)
group by nom, prenom, hexacle
A la fin du traitement de rapprochement nous disposons de 5 datasets (un par règle) contenant une liste d'événements correspondants à un individu. Par exemple :
| Dataset | Listes |
|---|---|
| Règle 1 | [(1, 2, 3), (4, 9), ...] |
| Règle 2 | [(5, 6), ...] |
| Règle 3 | [(7, 8), ...] |
| Règle 4 | [(1, 6), ...] |
| Règle 5 | [(2, 8), ...] |
À la fin de l'étape précédente, nous disposons de 5 datasets qu'il faut fusionner. Chacun contient environ 100 millions d’enregistrements.
Après plusieurs tentatives, nous n'arrivons pas à procéder simplement au regroupement des données. Nous avons imaginé, par exemple, fusionner les listes une à une mais l’algorithme qui en découle est en O(n3). Avec une telle volumétrie, il n’était absolument pas envisageable de développer cet algorithme.
Regroupement par individu
Puisque considérer les datasets comme des listes n'aboutit à aucun résultat en un temps acceptable, nous choisissons de les traiter comme des ensembles de relations :
| Règle 1 | 1 ↔ 2 ↔ 3 et 4 ↔ 9 |
| Règle 2 | 5 ↔ 6 |
| Règle 3 | 7 ↔ 8 |
| Règle 4 | 1 ↔ 6 |
| Règle 5 | 2 ↔ 8 |
La structure qui modélise nos relations est un graphe. Un graphe est une collection d’éléments mis en relation. Il est composé de sommets (Vertices) reliés par des arêtes (Edges). Il peut être représenté sous la forme d’un couple G = (Vertice, Edges).
Dans notre cas :
Vertices
| src | dst | property |
|---|---|---|
| 1 | 2 | Règle 1 |
| 2 | 3 | Règle 1 |
| 4 | 9 | Règle 1 |
| 5 | 6 | Règle 2 |
| 7 | 8 | Règle 3 |
| 1 | 6 | Règle 4 |
| 2 | 8 | Règle 5 |
Ces relations nous amènent à la représentation suivante :

Cette représentation, nous permet, d’avoir une vision simple de notre problème.
Dans notre graphe, par construction, chaque sous-graphe représente l’ensemble des événements liés à un Individu. Nous devons donc identifier chaque sous-graphe connexe, c’est à dire l’ensemble des points reliés par une chaîne.
En théorie des graphes, résoudre ce problème; revient à chercher toutes les composantes connexes du graphe.
Pour identifier les évènements de chaque individu, il suffit de chercher toutes les sous-composantes connexes de notre graphe de relation.
Dans notre exemple on obtient :
| Individu | Evénements |
|---|---|
| 1 | 1,2,3,5,6,7,8 |
| 2 | 4, 9 |
Implémentation
Dans une première version de notre implémentation, nous utilisons l’implémentation "Connected Components" de la librairie GraphX. Puis, avec l’arrivée de GraphFrame, nous choisissons de privilégier cette librairie.
L'avantage de GraphFrame par rapport à GraphX réside dans :
- une implémentation utilisant des datasets (et non de RDD) plus simple à intégrer avec le code existant ;
- une plus grande rapidité d'exécution (20% gains) ;
- une plus faible consommation mémoire.
Un des inconvénients, est que GraphFrame utilise beaucoup plus fortement le disque dur que GraphX.
Voici un exemple d'implémentation avec GraphFrame :
val ds = regle1.union(regle2)
.union(regle3)
.union(regle4)
.union(regle5)
val edges = ds.flatmap(convert_src_dst).checkpoint()
Graphframe.fromEdges(edges).connectedComponents().run()
La fonction convertForGraph permet de convertir une liste d'identifiants en Row[src, dst] compréhensible pour GraphFrame (ie. (1,2,3,4) -> [(1,2), (1,3), (1,4)]).
À la fin du calcul, le dataset de sortie contient pour chaque sommet du graphe (ie. id), l’identifiant de son individu colonne component).
Le résultat obtenu est alors :
| id | component |
|---|---|
| 1 | 1 |
| 2 | 1 |
| 3 | 1 |
| 4 | 2 |
| 5 | 1 |
| 6 | 1 |
| 7 | 1 |
| 8 | 1 |
| 9 | 2 |
Métriques et volumétrie
Le dataset initial avait une volumétrie d’environ 300 Go. Une fois converti au format Parquet le dataset se réduit à 90 Go.
L’ensemble des prétraitements prend environ 40 heures : le facteur limitant étant les outils de RNVP et de normalisation des noms.
L'exécution des règles de rapprochement prend environ 15 minutes. Les règles génèrent de l’ordre de 500 millions de relations.
L’algorithme de graphe s'exécute en 15 minutes sur un Cluster GCP HighMem.
Conclusion
Avec ces méthodes, nous réussissons, en utilisant la théorie des graphes, à apporter une nouvelle dimension aux données de notre client. Ce travail est essentiel pour basculer dans une dimension prédictive. Ainsi, nous avons pu réaliser des modèles permettant de prédire lorsqu’un individu va effectuer un acte d’achat ou de vente.