

Cet article conclu la série consacrée à Kubernetes et le Big Data.
Cas concret
Ce chapitre présente un état des lieux et une évaluation de la maturité des solutions Big Data à s'exécuter sur Kubernetes.
Toute solution est apte à s'exécuter sur Kubernetes. Une condition suffisante mais pas obligatoire étant de disposer d'une image Docker, ce qui est le cas de la plupart. C'est ce que l'on appelle un déploiement standalone.
Par contre, afin de profiter pleinement des avantages de la plateforme Kubernetes, voire même de proposer des fonctionnalités innovantes et absentes des déploiements standalone, il y a nécessité d'évolution de la solution.
Surtout, le fait de disposer de solutions adaptées va considérablement diminuer les besoins d'écriture des fichiers YAML de déploiement.
Traitements distribués
Spark
Depuis la version 2.3 il existe un quatrième mode de déploiement de Spark en plus des modes Mesos, Standalone et YARN. Il s'agit de Kubernetes ( https://spark.apache.org/docs/latest/running-on-kubernetes.html))
À l'origine de cette intégration il y a le projet https://github.com/apache-spark-on-Kubernetes/spark initié par Bloomberg, Google, Intel, ... dont les avancées sont peu à peu intégrées au projet principal.
Nous avons donc une intégration officielle et une intégration alternative.
La version alternative est plus avancée et offre en plus les fonctionnalités suivantes :
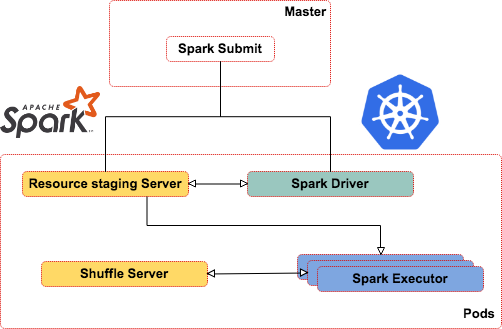
- Resource Staging Server.
- Spark External Shuffle Service.
Resource Staging Server : ce service permet de distribuer les dépendances d'un traitement Spark. Ce qui comprend les librairies, les fichiers de configurations, etc.
NB : les ressources doivent être disponibles localement sur le Pod exécutant le Spark-submit afin d'être distribuées au driver et aux exécuteurs.
Spark External Shuffle Service : ce service permet d'activer le mode Dynamic Allocation de Spark.
Le mode dynamique de Spark permet de moduler le besoin en ressources en fonction de la charge réelle de l'application (en arrêtant des Executor).
Pour cela, le service va persister les fichiers Spark de shuffle pour faciliter la reprise des traitements.
Cela permet, par exemple, à un traitement Spark streaming de consommation de messages Kafka de libérer des ressources lorsqu'il n'y a pas de messages.
Problème d'intégration de Spark avec Kubernetes
Outre la multiplication des projets, l'intégration de Spark avec Kubernetes souffre des problématiques suivantes :
- Driver/master temporaires : les Pods exécutant les driver/exécuteurs Spark sont éphémères (ne durent que le temps des traitements), il est donc complexe d'accéder aux logs ou à l'interface Spark UI (history server).
- Pas de version officielle pour les langages Python et R.
- Besoin d'une meilleure intégration avec la sécurité (données temporaires, accès HDFS).
- Pas de support de la console Spark (Spark Shell REPL).
Flink
Flink a depuis toujours été orienté Cloud, il n'est donc pas étonnant de trouver un support assez ancien de Kubernetes (depuis la version 1.2).
https://ci.apache.org/projects/flink/flink-docs-release-1.5/ops/deployment/kubernetes.html
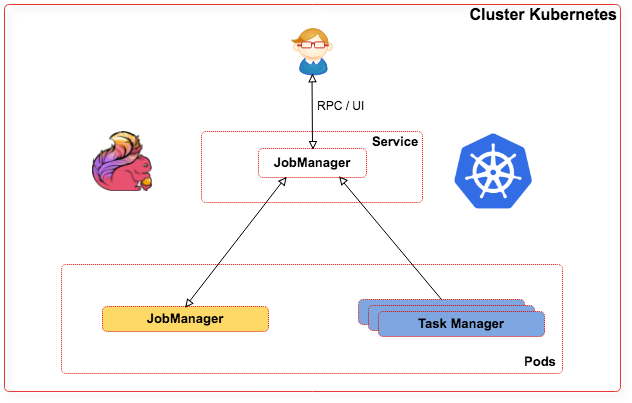
Architecture :
- JobManager : Service façade d'accès au Pod Jobmanager (RPC et web).
- n Pods Task Manager : cluster Flink.
- 1 Pod Jobmanager : gestion des traitements Flink.
Annoncée l'année dernière, la plateforme de streaming basée sur Flink de Data Artisan qui se nomme dA (first unveiled dA Platform) est disponible depuis mars 2018 et se base sur Kubernetes.
Cette plateforme propose :
- Une interface web et une API pour le management
- Une intégration facilitée avec les frameworks suivants :
- Métriques : InfluxDB, Grafana
- Logs : Logstash, ElasticSearch, Kibana
Problème d'intégration de Flink avec Kubernetes
Cependant, un déploiement de Flink pose actuellement les problèmes suivants :
Soumission d'un job
Impossible depuis l'extérieur du cluster Kubernetes (en utilisant le port-forwarding ou un load balancer), car les hostname/IP des Pods doivent correspondre (soumission et exécution).
Solution de contournement :
- Soumettre le job depuis le cluster Kubernetes.
- Utiliser l'interface ou l'API web de Flink ce qui pose des problèmes de sécurité.
Haute disponibilité du Job Manager
Il est conseillé de démarrer plusieurs Job Manager afin d'assurer la haute disponibilité avec Flink.
Le Job Manager stocke les informations essentielles dans Zookeeper afin d'assurer la reprise en cas de crash.
Kubernetes redémarre automatiquement les Pods en cas de crash il est donc conseillé de ne définir qu'un seul Job Manager.
En conséquence l'indisponibilité en cas de crash est courte mais réelle.
Chiffrement des échanges
Pour rappel, les Pods n'ont pas d'adresse IP ou de nom d'hôte fixe (Flink n'utilisant pas de StatefulSet).
Cela perturbe le chiffrement classique de Java (trustStore/keyStore) qui se base sur ces informations pour autoriser l'accès à une clé et un certificat.
La prochaine version d'Apache Flink (la 1.5), proposera une intégration renforcée avec Kubernetes et Mesos (Cf FLIP 6) afin de mieux gérer l'élasticité du cluster.
On trouvera notamment une solution qui va enfin permettre la soumission de traitements Flink en dehors du cluster (en utilisant une image Docker du jobmanager dont le rôle sera de lancer le traitement).
Messages
Kafka
L'utilisation de Kafka avec Kubernetes est rendue plus complexe du fait qu'il n'y ait pas d'image Docker officielle hormis celle de Confluent (la version Entreprise donc).
Pour la version Apache il existe le projet non officiel https://github.com/Yolean/kubernetes-kafka qui pose les problèmes suivants :
- Ce n'est pas la dernière version de Kafka.
- Intégration partielle avec Kubernetes.
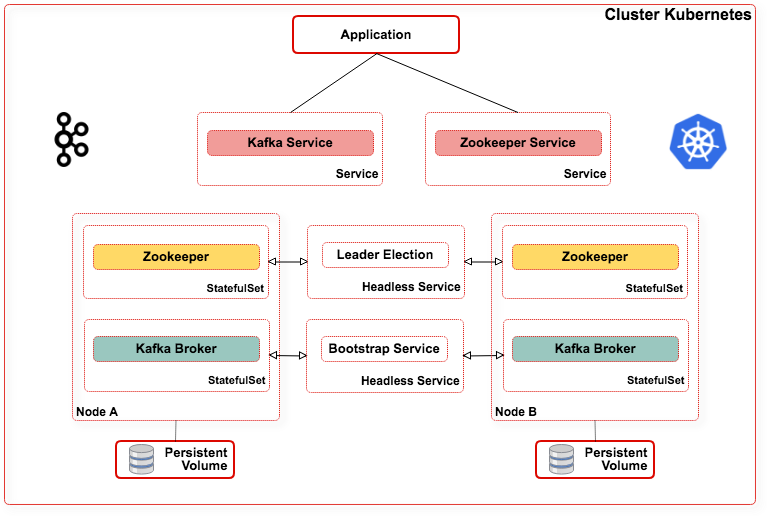
Afin de faciliter l'intégration avec Kubernetes, il existe un projet kafka operator : https://github.com/nbogojevic/kafka-operator.
Cet opérateur va se charger de la gestion des Topics Kafka au sein d'un cluster Kubernetes :
- Création et suppression,
- Nombre de partitions,
- Nombre de réplicas,
- Le délai de rétention,
- L'intégration avec les secrets de Kubernetes.
Afin d'éviter l'installation de Zookeeper lors du déploiement de Kafka sur Kubernetes, il existe un projet qui permet d'utiliser etcd à la place.
Kafka on etcd https://github.com/banzaicloud/apache-kafka-on-Kubernetes
Confluent Operator
Cet operator est issu de l'expérience de Confluent Cloud depuis un an (offre SAAS).
Plus de détails : https://www.confluent.io/blog/introducing-the-confluent-operator-apache-kafka-on-kubernetes/
Contenu Confluent Operator :
- Images Docker de la plateforme Confluent
- Template de déploiement,
- Architecture de référence,
- Kubernetes Operator API :
- Provisionnement et scalabilité automatique,
- Mises à jour automatiques,
- Répartition des données (partitions),
- Monitoring,
- Conservation de l'identité Kafka d'un Pod (broker id, configuration et stockage persistant) en cas de crash.
- Intégration avec Control Center
- Métriques additionnelles dans Prometheus
Compatible et testé avec les fournisseurs suivants :
- Pivotal Container Service (PKS),
- Mesosphere Kubernetes
- OpenShift,
- Google Kubernetes Engine (GKE),
- Amazon Elastic Container Service for Kubernetes (EKS),
- Azure Container Service (AKS).
Stockage
Bien évidemment dans le cloud on privilégiera les solutions natives de stockage (AWS S3, Google Cloud Storage, Azure Storage, ...).
Mais cela va à l'encontre d'un des postulats de départ : la portabilité de Kubernetes.
Pour un déploiement On-premise, on peut utiliser les solutions suivantes.
Minio
Minio a été fondée en 2014 par un ancien CTO de Gluster (célèbre système de fichiers distribués)
C'est une solution de stockage objet (Object Store) compatible S3.
Minio a été développé en langage Go et est fourni avec plusieurs SDK pour les langages Go, Java, JavaScript et Python.
Le code source du logiciel est accessible sur GitHub (sous licence Apache).
Dès le départ Minio a été conçu pour pouvoir fonctionner avec Docker et au plus près des applications c'est-à-dire sur sur le même nœud que les traitements associés.
De fait il diffère des solutions de stockage natives du cloud (S3, Google Cloud Storage).
Deux modes sont disponibles :
- standalone,
- distribué.
La scalabilité de Minio est limitée à l'agrégation de 16 disques dispersés sur un maximum de 16 nœuds différents.
Erasure-coding : le logiciel assure l'intégrité des données tant qu'au moins la moitié des disques du cluster reste disponible
Minio supporte aussi les mécanismes de notifications Lambda d'AWS
Le point le plus intéressant étant sa compatibilité complète avec S3, l'API et l'URI étant identique, les clients ne peuvent distinguer l'un ou l'autre.
Minio fourni un client spécifique minio-client mais on peut utiliser le client S3.
Minio Client fonctionne avec Minio, mais aussi avec toute forme de stockage compatible S3.
HDFS
Lors de l'intégration de Spark avec Kubernetes, l'équipe a travaillé sur l'intégration de HDFS avec Kubernetes. C'est donc un sous projet Spark/KUBERNETES.
Ils ont en particulier travaillé sur les points suivants de l'intégration HDFS/Spark avec Kubernetes :
- Data Locality,
- Sécurité.
En effet, dans la plupart des cas, les performances peuvent être améliorées en exécutant les traitements au plus proche des données.
Règles implémentées par ordre de priorité (Data Locality) :
- Node locality : fichier traité et executor co-localisé sur nœud.
- Rack locality : fichier traité et executor co-localisé dans le Rack.
- Node preference : possibilité de donner un nœud préférentiel pour le driver et les executors.
Sécurité (Amélioration de l'intégration avec Kerberos) :
Toujours en raison des IP changeantes des Pods, l'utilisation des tickets Kerberos directement par les executors est complexe.
Le driver et les executors vont donc utiliser les tokens HDFS (ces derniers utilisant les secrets Kubernetes).
La question du renouvellement des tickets se pose et a été résolue par l'utilisation de microservices dédiés.
Problèmes restant à résoudre :
- Performances,
- Haute disponibilité des Namenodes.
Rook
Rook (https://rook.io/) est un système de stockage distribué spécifique à Kubernetes et intégré à CNCF en Janvier 2018.
Rook est un produit open source disponible sous licence Apache.
Rook est compatible Ceph et propose trois modes différents :
- Objet (S3),
- Block,
- Fichier (POSIX).
Rook est toujours en version alpha et proposera dans l'avenir d'autres systèmes de stockage que Ceph et d'autres orchestrateurs que Kubernetes.
Dans sa version actuelle Rook a été développé comme un système natif de Kubernetes, ce qui lui permet entre autres de proposer :
- Une scalabilité simple,
- Du monitoring,
- Une gestion du failover,
- Une intégration à la sécurité de Kubernetes (RBAC),
- Un accès réseau direct.
Afin de faciliter la maintenance, Rook propose les fonctionnalités suivantes :
- Prise de snapshots,
- Cloning de données,
- Versioning des données.
Solutions NoSQL
Depuis l'arrivée des ReplicaSet et la persistance des données au redémarrage des Pods, l'utilisation des solutions NoSQL a été simplifiée.
Couchbase
Couchbase est probablement la solution la plus avancée quant à l'utilisation de Kubernetes car conçue pour le cloud dès le départ.
Architecture :
- Sync Gateway : Service d'accès depuis l'extérieur,
- n Pods Couchbase : cluster serveur Couchbase,
- Etcd : service de configuration permettant de constituer le cluster Couchbase (découverte des nœuds).
NB : Si Kubernetes utilise nativement un service etcd il n'est pas possible de l'utiliser directement, il faut monter un autre cluster.
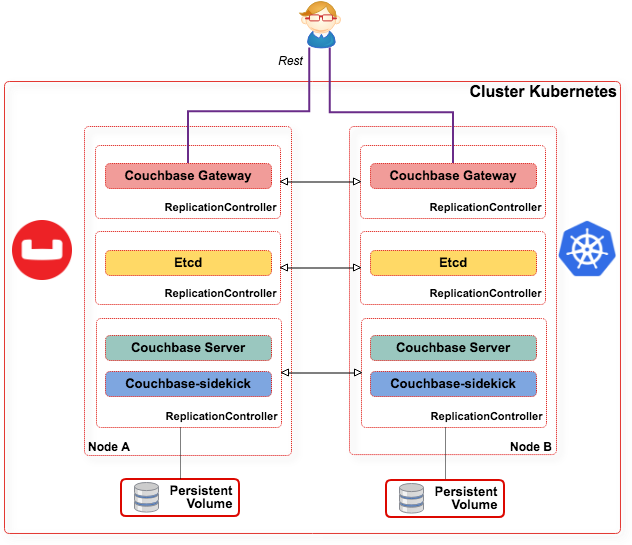
Afin de faciliter le déploiement, Couchbase propose Couchbase Operator qui permet de gérer :
- La configuration,
- La création,
- Le dimensionnement,
- Le logging d'un cluster Couchbase sur Kubernetes.
Couchbase Operator peut être utilisé sur une multitude de plateformes, on trouve de la documentation pour un déploiement sur GKE/GCE/AWS : https://github.com/couchbase/kubernetes
MongoDB
Il y a plusieurs projets de support de MongoDB sur Kubernetes avec une architecture un peu différente.
Une première architecture avec un service de configuration co-localisé avec le service mongod (sidecar). http://Kubernetesmongodb.net/
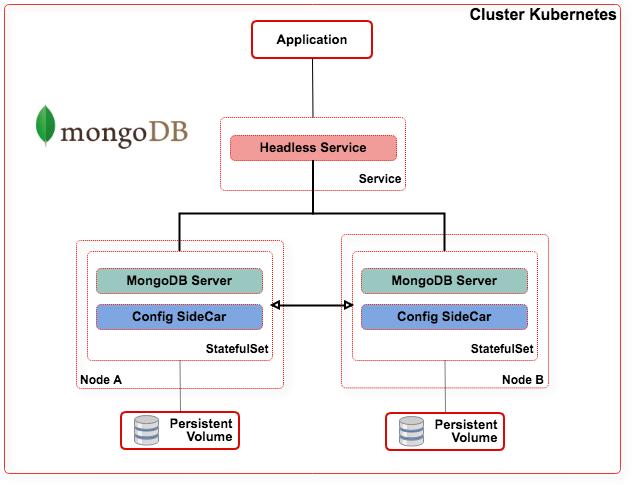
Ce service va vérifier toutes les 5 secondes la liste des Pods mongod actifs. En cas d'évolution (Ajout/suppression) un nouveau ReplicaSet est créé.
Le ReplicaSet est donc dynamique et variable en fonction des événements du cluster. Il est donc toujours conforme à la composition réelle du cluster.
Si ce fonctionnement présente des avantages, il est contraire à certains mécanismes natifs de MongoDB.
Il présente en effet les risques suivants :
- Perte du master, en cas de crash il est exclu automatiquement du cluster, ce qui peut entraîner la perte de données et augmente le risque de SplitBrain.
- Le principe de write concern (une majorité de nœuds du ReplicaSet de départ doivent être actifs au moment de l'écriture) est rendu inutile augmentant le risque de perte de données.
Pour toutes ces raisons on trouve une solution alternative et plus classique pour le déploiement de MongoDB.
https://kubernetes.io/blog/2017/01/running-mongodb-on-kubernetes-with-statefulsets
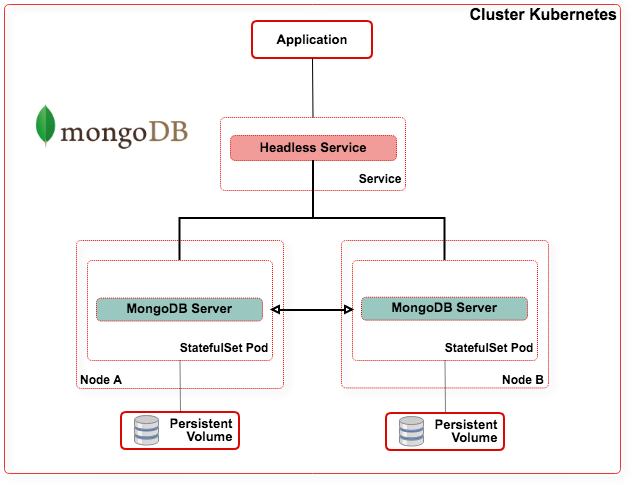
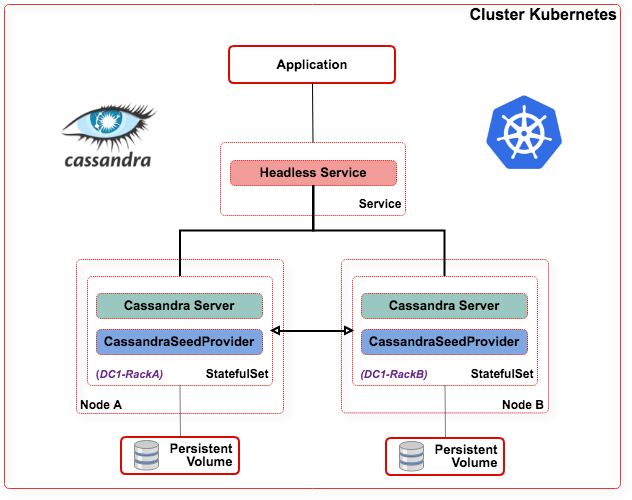
Cassandra
L'intégration de Cassandra avec Kubernetes est classique et rendue plus simple grâce à la nature décentralisée de Cassandra (contrairement à MongoDB).
Il est d'ailleurs intéressant de noter que c'est avec un cluster Cassandra que Kubernetes a validé sa solution Stateful (appelée alors PetSet) avant la sortie de la version 1.3.
Environ 1000 instances Cassandra ont permis de valider la version 1.3 et ainsi d'ouvrir la voie à des solutions stateful. (https://kubernetes.io/blog/2016/07/thousand-instances-of-cassandra-using-kubernetes-pet-set/)).
L'exemple le plus répandu d'utilisation de Cassandra sur Kubernetes est disponible dans la documentation officielle de Kubernetes : https://kubernetes.io/docs/tutorials/stateful-application/cassandra/).
À noter que cette intégration utilise une image Docker de Google Cloud.
Pour une version utilisant l'image officielle d'Apache Cassandra on peut utiliser le projet suivant : https://github.com/vyshane/cassandra-kubernetes.
Une des difficultés consiste dans la définition des seeds dans la configuration de Cassandra.
Il s'agit des nœuds que va contacter un nouveau service Cassandra au démarrage afin de déterminer si un cluster joignable n'est pas déjà lancé. Une solution consiste à mettre en dur les noms d'hôte des Pods mais cela ne facilite pas la scalabilité.
C'est pourquoi un service a été développé : https://github.com/kubernetes/examples/blob/master/cassandra/java/src/main/java/io/Kubernetes/cassandra/KubernetesSeedProvider.java))
Gestion localisation et multi-datacenter :
- La localisation des nœuds est possible grâce aux propriétés suivantes dans la définition du StatefulSet : DC et Rack
Conclusion
Kubernetes se montre parfaitement adapté pour accélérer le déploiement sur des conteneurs maintenant que l'adoption du Big Data par les entreprises s'étend et que le besoin de trouver une solution capable de les gérer sur une grande échelle se fait sentir.
Toutes les solutions Big Data ne sont pas au même niveau d'intégration et ne tirent pas encore pleinement profit des possibilités offertes par Kubernetes.
Autre frein à l'adoption de Kubernetes, le projet évolue à une vitesse folle : une nouvelle version tous les 3-4 mois depuis 2015.
Ce qui est un avantage en termes d'évolution est par contre un inconvénient en termes de stabilité.
D'ailleurs les solutions présentées dans cet article n'utilisent pas les dernières évolutions et avancées de la plateforme.
Les points sur lesquels les solutions doivent encore progresser :
- Améliorer les schedulers en tenant compte des spécificités du Big Data,
- Améliorer la colocalisation,
- Mieux s'intégrer avec la sécurité native de Kubernetes,
- …
Toutefois, certains que l'on peut qualifier de early adopters permettent d'entrevoir les possibilités offertes :
Comment Google a réussi à absorber le succès de Pokémon Go grâce à Kubernetes : Bringing Pokemon GO to life on Google Cloud
D'autres éditeurs ont misé sur Kubernetes, tel que Pachyderm dont la solution est une plateforme destinée aux Data Scientists pachyderm.io.
D'ailleurs Kubernetes présente un intérêt certain pour la Data Science.
En premier lieu par sa capacité à gérer l'infrastructure, ce qui permet de monter rapidement des plateformes (pour une campagne par exemple).
Aller plus loin
Voici une liste de liens qui vont vous permettre d'aller plus loin.
Quickstart guide for Kubernetes on DC/OS https://github.com/mesosphere/dcos-kubernetes-quickstart
Comparaison des offres Cloud : https://www.sumologic.com/blog/cloud/kubernetes-aws-azure-gcp/
Multi-tenancy-in-kubernetes : https://blog.jessfraz.com/post/hard-multi-tenancy-in-kubernetes/
A complete example of a big data application using Kubernetes : https://github.com/Chabane/bigdata-playground
Solutions CNCF : https://landscape.cncf.io/
Jenkins X (CI/CD solution for modern cloud applications on Kubernetes) : https://jenkins-x.io/
2018 Docker Usage Report : https://sysdig.com/blog/2018-docker-usage-report/
Awesome Kubernetes : Awesome Kubernetes
