
Depuis quelques mois, la suite Elastic s’est enrichie d’un outil de Machine Learning non supervisé, c’est-à-dire qu’on travaille avec des données non étiquetées.
Dans le premier article, nous avons introduit un certain nombre de concepts. Dans ce second article, nous allons traiter de l'architecture et du positionnement du produit.
Architecture
En local avec docker-compose
Personnellement, j’utilise docker-compose pour exécuter une stack Elasticsearch sur laquelle X-Pack est activé. Vous pourrez récupérer les éléments nécessaires depuis Github avec la commande suivante :
git clone -b x-pack https://github.com/deviantony/docker-elk.git
Pour injecter des données, plutôt que d’utiliser Logstash dans Docker je trouve plus simple de le télécharger (ici : https://www.elastic.co/downloads/logstash) et de l’exécuter en local.
Développement
Pour activer les fonctionnalités de ML sur un nœud, il faut positionner le flag node.ml:true, comme on le fait habituellement pour les capacités node.master et node.data.
Pour un environnement de développement, on peut se contenter d’un seul ou deux nœuds qui portent toutes les capacités (master, data et ML).
Production
Mais pour un environnement de production, on voudra avoir des nœuds spécifiques pour les traitements de ML. Les traitements peuvent consommer des ressources significatives et ingérer les sources de données (datafeeds dans le vocabulaire Elasticsearch) de manière planifiée. La fonctionnalité de machine learning est activée par défaut sur un cluster Elasticsearch. Nous vous conseillons donc de la désactiver sur vos nœuds dédiés master et client (voir ML Settings).
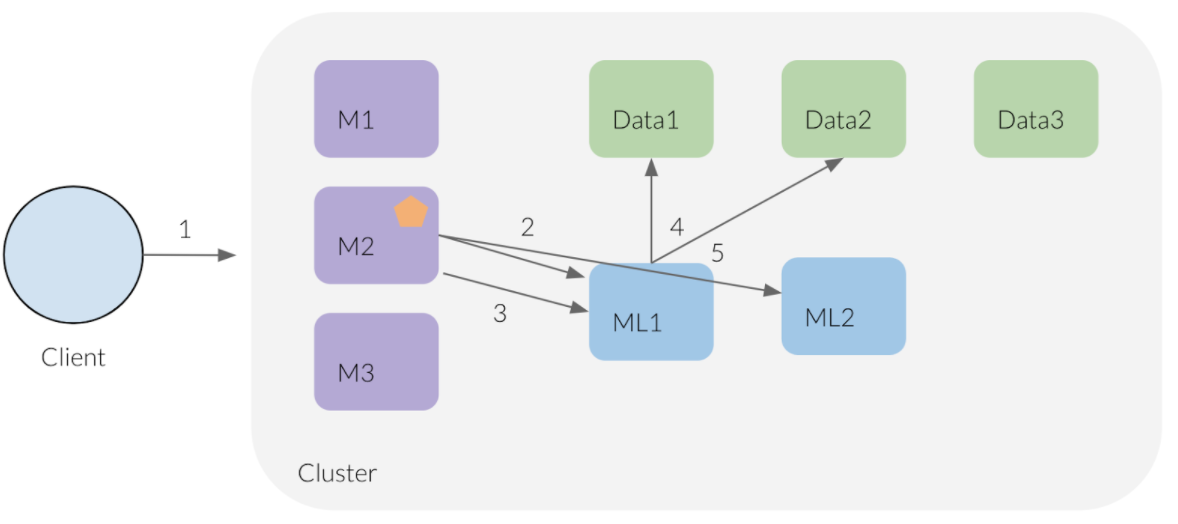
Le workflow est le suivant :
- Le client soumet un job au cluster.
- Le nœud coordinateur qui reçoit la requête répartit le job sur les noeuds ML disponibles (
node.ml=true). - Le nœud coordinateur choisit un nœud ML pour exécuter le job.
- Le nœud ML requête les données (data feed) à intervalle régulier.
- Il stocke les résultats dans les data nodes.
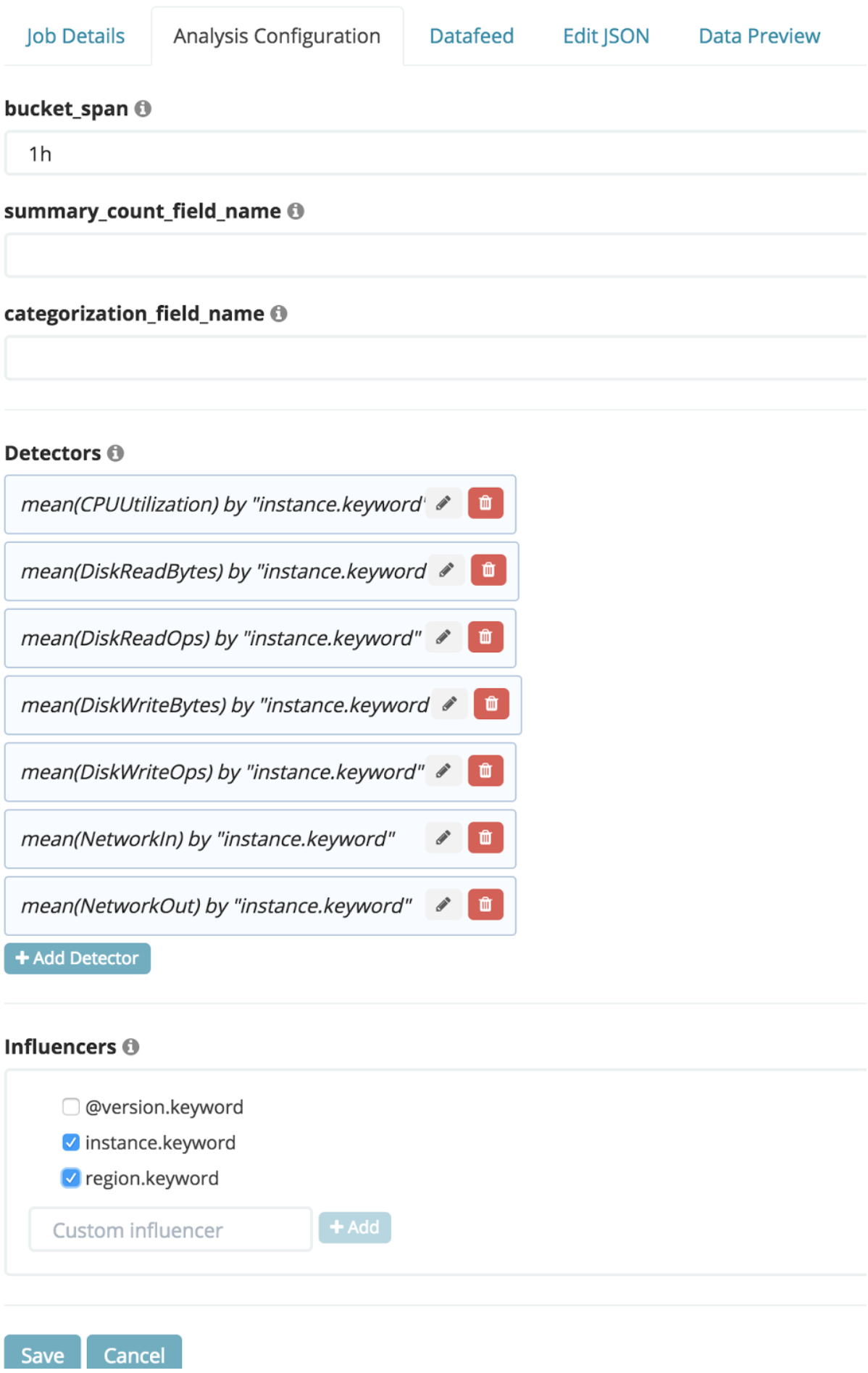
Exemple d'Advanced Job
Pour créer ce job, on importe des données extraites depuis cloudwatch d’AWS. Pour configurer le job, on choisit de calculer la moyenne selon l’instance pour 7 métriques sur un bucket span qu’on fixe à 1h pour regrouper suffisamment de données puis on sélectionne les influencers.
Avec l’anomaly explorer, on peut visualiser les données réparties selon les influencers : soit le nom de l’instance, soit le nom de la région.

Dans la colonne de gauche, on observe en un coup d’œil que le top influencer parmi les régions est sa-asia-1.
Si on clique sur un des rectangles, on peut visualiser chacun des graphes comme par exemple celui-ci :
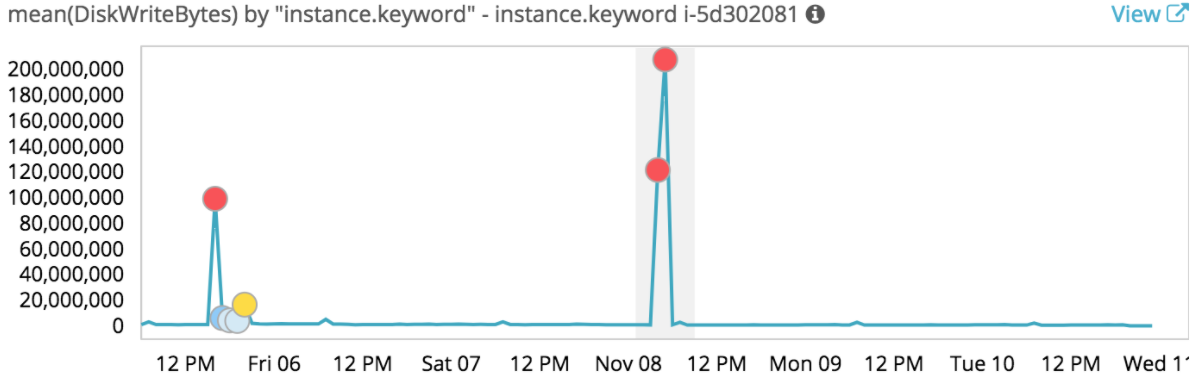
Sur ce graphe on voit en un coup d’œil les valeurs aberrantes qui ont participé à un taux d’erreurs important pour cette instance et cette plage de temps.
Machine Learning API
Quand on crée un job, une API est exposée pour donner accès à l’anomaly detector avec une requête HTTP. On peut donc l’appeler pour obtenir les résultats de la détection d’anomalies :
GET _xpack/ml/anomaly_detectors/advanced-cloudwatch/results/records
Mais ce qui est intéressant, c’est d’appeler cette API régulièrement pour ne récupérer que les nouvelles anomalies depuis le dernier appel.
Ensuite, on peut déclencher un traitement spécifique pour remonter cette anomalie aux services concernés. Pour cela on peut utiliser X-Pack:Alerting pour programmer les alertes.
On Demand Forecasting
Nouveauté apportée par la version 6.1 sortie en décembre 2017, cette fonctionnalité permet de prédire les futures données d’une série temporelle. On peut ensuite comparer les données qui arrivent réellement au fil de l’eau avec la prévision. Ce peut être utile pour réaliser par exemple un capacity planning des ressources monitorées dans Elasticsearch (CPU, RAM, I/O, etc).
Voici un article qui introduit cette nouveauté.
Points forts
L’intégration est très bien faite avec toute la suite Elastic. En particulier, l’utilisation de Kibana pour construire les jobs de Machine Learning et bien sûr pour visualiser les résultats. Avec une mention spéciale pour l’anomaly explorer qui est un outil simple à utiliser pour explorer intuitivement les anomalies.
Autre point fort : on utilise la même suite d’outils pour collecter, stocker puis analyser et visualiser ses données temporelles.
Points faibles
Le besoin auquel X-Pack Machine Learning répond est très spécifique, autrement dit la variété des cas d’utilisation dans lesquels on pourrait l’employer ne semble pas très vaste.
Il faudra s’affranchir d’une souscription X-Pack pour utiliser cet outil.
Par rapport à la concurrence
X-Pack n’est pas un Data Studio comme Dataiku qui peut se connecter à des sources de données variées et embarque un grand nombre d’algorithmes.
Splunk propose aussi des fonctionnalités similaires avec son Machine Learning Toolkit qui embarque de nombreux algorithmes permettant de faire de la prédiction (par exemple de consommation électrique d’un serveur) ou de la détection d'aberrations (par exemple sur les ventes réalisées dans un supermarché). Des exemples de cas d’utilisation sont donnés sur cette page.
En plus des algorithmes, on a accès à tout l'écosystème de Splunk pour indexer, analyser et visualiser les données. Mais seule la version enterprise de Splunk supporte le ML Toolkit.
Conclusion
Si vous collectez et analysez déjà vos données avec la suite Elastic, que vous possédez déjà X-Pack et que vous souhaitez mettre en place des traitements de Machine Learning pour détecter les valeurs anormales, l’outil Machine Learning de X-Pack semble être un excellent candidat.
Si ce n’est pas le cas, vous avez plusieurs modèles de Machine Learning qui se prêtent bien à la détection d’anomalies dans une série temporelle. Je vous recommande la lecture de cet article qui fait le tour de la question.
La rapidité de prise en main de X-Pack Machine Learning et la possibilité d’exposer des API et de déclencher des alertes permettent d’imaginer de nombreux usages. L’analyse automatique des séries temporelles pour dégager une tendance et détecter rapidement les valeurs aberrantes permettent d’identifier rapidement :
- Les déviations par rapport au temps en valeur, nombre ou fréquence.
- Les signaux faibles.
- Les comportement inhabituels pour un individu d’une population.
J'espère que cette série d'articles vous aura donné envie de jouer avec cette nouvelle fonctionnalité de la suite Elastic.
