
Cet article est le dernier dans la série des articles sur mon bot Twitter qui joue et qui gagne. Il aborde l’utilisation du framework Akka et des autres bibliothèques que j’ai utilisées dans le bot.
La série complète :
- l’origine du projet
- l’architecture
- l’implémentation (c’est cet article !)
 Des exemples d’acteurs
Des exemples d’acteurs
Le premier acteur
Les acteurs sont des petits bouts de code qui communiquent via des messages. Ces messages peuvent contenir des informations structurées ou juste être un simple message. En Scala, la déclaration d’un acteur se fait ainsi :
import akka.actor.Actor
class RequeueActor extends Actor {
def receive = { … }
}
Et c’est tout pour le début. receive est la seule méthode que vous devez utiliser pour devenir un acteur. Cette méthode est ensuite appelée par le système de gestion des acteurs avec des objets ou des classes qui représentent le message. L’usage traditionnel est de fabriquer des case object stockés dans l’objet compagnon de la classe acteur :
object RequeueActor {
case object Requeue
case object RequeueComplete
}
On peut ensuite les référencer via RequeueActor.Requeue par exemple. Et lors de la réception d’un message, on va utiliser le pattern-matching de Scala pour s’adapter au message :
case RequeueActor.Requeue => { ... }
case RequeueActor.OtherMessage => { ... }
case _ => { ... }
Si jamais vous avez envie de passer des paramètres lors de vos envois de message, c’est possible ! Il suffit d’avoir des case class au lieu d’object pour les rendre paramétrables :
object TwittProcessor {
case class FollowAndRT(userId: Long, statusId: Long)
case class SearchFor(query: String)
}
Ainsi, lors des appels de ces messages, vous allez fabriquer les messages en les paramétrant directement :
processor ! TwittProcessor.FollowAndRT(userId, tweetId)
Justement, voyons comment on parle à un acteur !
Communication entre acteurs
Afin de permettre une exécution harmonieuse de l’ensemble des acteurs, vous allez passer par akka.Main.main() fournie par le système Akka pour permettre de lancer un Acteur au niveau supérieur. Dans mon application, cet acteur est un Manager. Ce Manager va à son tour lancer un HarvesterActor avec un message pour qu’il aille chercher les données sur Twitter.
import akka.actor.Props
// Point d'entrée principal du programme. Appelle Akka avec un Manager
object Main {
def main(args: Array[String]): Unit = {
akka.Main.main( Array(classOf[Manager].getName) )
}
}
class Manager extends Actor {
override def preStart(): Unit = {
val harvester = context.actorOf(Props[HarvesterActor], "harvester")
harvester ! HarvesterActor.Harvest
}
def receive = {
case msg => logger.info(s"Received message $msg")
}
}
On voit que pour récupérer un acteur d’un type donné, on passe par context.actorOf qui va se charger de créer l’acteur dans le contexte courant. Le nom de l’acteur servira dans les messages de log. Ça peut toujours servir de mettre quelque chose de raisonnable dedans. Enfin, on appelle l’acteur en lui envoyant un message avec la syntaxe :
actorRef ! message
Cette syntaxe est de type fire and forget. Une fois le message envoyé, vous ne vous attendez pas à une réponse de la part de l’acteur cible. Il existe d’autres façons de communiquer avec les acteurs, mais celle-ci permet de conserver un fort découplage entre vos acteurs et les données qu’ils manipulent. message peut être un simple case object sans paramètre ou une case class avec des paramètres. L’ensemble est transmis à votre système d’acteurs et vous n’avez plus qu’à gérer la réception plus tard dans votre acteur concerné :
class TwittProcessor extends Actor with LazyLogging {
def receive = {
case TwittProcessor.SearchFor(search: String) => { ... }
case TwittProcessor.FollowAndRT(userId, statusId) => { ... }
}
}
Se réveiller régulièrement
Dans le cadre du bot Twitter, je devais me réveiller régulièrement, pour aller faire des recherches dans Twitter et traiter les résultats. Une façon naïve de faire l’implémentation aurait été de faire un acteur qui boucle et dort pendant une certaine durée pour ensuite appeler un autre acteur qui, lui, ferait la recherche :
class BoringActor extends Actor {
def receive = {
case BoringActor.forever => {
while(true) {
Thread.sleep(60000)
val harvester = context.actorOf(Props[HarvesterActor], "harvester")
harvester ! HarvesterActor.Harvest
}
}
}
}
Mais c’est assez moche comme façon de faire. Du coup, j’ai préféré passer par un Executor (de java.util.concurrent) qui possède la fonction bien nommée newSingleThreadScheduledExecutor qui va nous permettre d’appeler du code à nous de manière régulière. Au final, l’API Java automatise ces appels pour nous et nous permet de ne pas écrire de code trop sale. Notre Scheduler présente ainsi une API simple et efficace pour les tâches périodiques :
object Scheduler {
import java.util.concurrent.Executors
import scala.compat.Platform
import java.util.concurrent.TimeUnit
private lazy val sched = Executors.newSingleThreadScheduledExecutor();
def schedule(f: => Unit, time: Long) {
sched.schedule(new Runnable {
def run = f
}, time , TimeUnit.MILLISECONDS);
}
def every(f: => Unit, period: Long) {
sched.scheduleAtFixedRate(new Runnable {
def run = f
}, 0, period, TimeUnit.MILLISECONDS)
}
}
Gérer les API fragiles – Le CircuitBreaker
Dans certains cas, votre système extrêmement robuste d’acteurs va devoir interagir avec le monde extérieur pour communiquer. Autant dire que si ce n’est pas le cas, vous pouvez tout aussi bien utiliser un langage plus exotique dans lequel la communication avec le monde extérieur est plus difficile. Mais comme notre but est bien d’interagir avec Twitter, nous devons être capable de discuter avec lui pour échanger des données.
Or parfois, vous allez immanquablement vous retrouver face à ces problèmes lors de certains requêtes. Vous avez alors deux solutions : soit votre code explose (même s’il gère l’exception, vous allez devoir la remonter, la gérer et décider que faire ensuite), soit vous vous appuyez sur les patterns proposés par Akka pour gérer votre code.
Dans cette section, nous allons découvrir le pattern du circuit breaker (disjoncteur en français, mais je crois que personne n’utilise ce terme pour parler de ce pattern).
Le circuit breaker
Le pattern du circuit breaker fonctionne exactement comme un disjoncteur physique, comme celui que vous avez pour votre salle de bain, sauf qu’il sert à vous protéger du grand méchant internet. Par défaut, il est fermé et laisse passer vos requêtes de manière transparente, tout en surveillant que votre code est content et ne fait pas d’erreur.
Dès qu’une erreur a lieu ou qu’une requête met trop de temps à répondre, il va surveiller encore plus attentivement vos communications. Si trop d’erreurs (exceptions ou expirations de délais) se produisent, il bascule en mode OUVERT. À partir de ce moment là, toutes vos requêtes échoueront avec une exception de manière automatique, jusqu’à ce que le circuit breaker refroidisse. Il passe alors en mode SEMI-OUVERT : la prochaine requête sera exécutée normalement et si elle réussit, le circuit repasse en mode FERMÉ. Si elle échoue, il repasse en mode OUVERT jusqu’à ce qu’il refroidisse à nouveau.
Voici un petit schéma de fonctionnement du système :
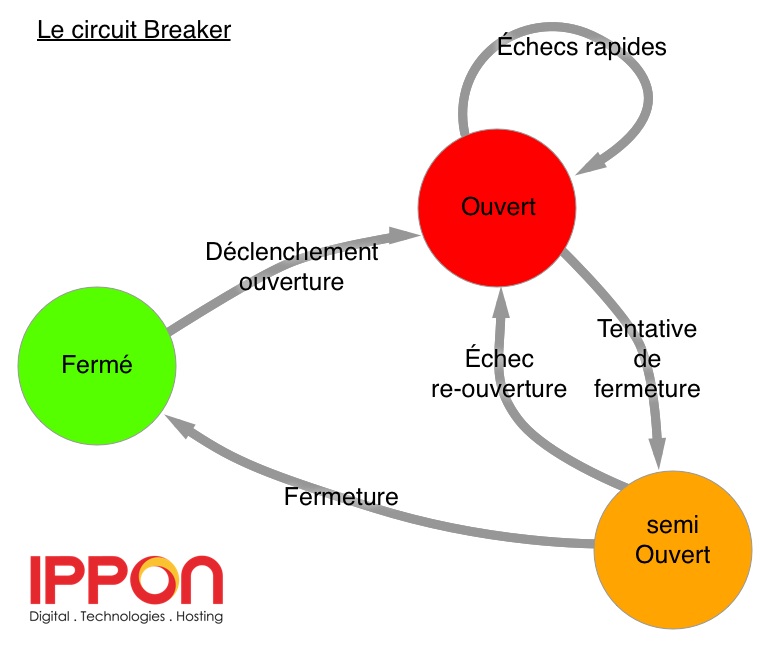
Ce genre de mécanisme permet plusieurs avancées dans votre architecture :
- en cas de souci, votre infrastructure ne risque pas de se mettre à ramer trop longtemps avant de détecter la panne : aucun risque d’entraînement parce qu’un de vos fournisseurs est en danger.
- vous ne risquez pas de faire des dizaines, centaines ou même milliers de requêtes à un service qui est déjà en carafe, aggravant par là même son état.
- le fonctionnement automatique du circuit breaker vous permet de vous affranchir de la gestion de panne de ce côté là pour vous concentrer sur la gestion des exceptions qui auront lieu dans votre système si le circuit est ouvert.
Utilisation avec les acteurs
Pour utiliser le circuit breaker, on va simplement l’intercaler dans notre code là où on désire qu’il protège nos installations. Comme avec un disjoncteur normal. D’abord, on le fabrique et on le configure :
val breaker =
new CircuitBreaker(context.system.scheduler,
maxFailures = 2,
callTimeout = 10.seconds,
resetTimeout = 50.minute).onOpen(notifyMeOnOpen())
Celui-ci est réglé pour s’ouvrir au bout de deux échecs, sur des appels qui prennent au plus 10 secondes. Ensuite, il reste ouvert pendant 50 minutes avant de se refermer. Notez qu’on peut être prévenu lorsqu’il change d’état, ce qui peut avoir un certain intérêt si jamais vous voulez corréler correctement l’ouverture du circuit breaker avec, par exemple, une augmentation du taux d’erreur qui doit probablement suivre de votre côté. Inutile de chercher un coupable quand on le connaît déjà.
Ensuite, vous pouvez utiliser le circuit breaker à chaque appel vers votre système extérieur. Pour le bot, j’ai choisi d’isoler uniquement Twitter lors des écritures, mais j’aurai pu choisir d’isoler aussi mes accès base de données, ou tous mes accès Twitter. Encore une fois, c’est un choix que vous pouvez modifier facilement :
def receive = {
case TwittProcessor.SearchFor(search: String) =>
val harvester = context.actorOf(Props[HarvesterActor], "resultStore")
harvester ! breaker.withSyncCircuitBreaker(performSearch(search))
case TwittProcessor.FollowAndRT(userId, statusId) =>
val user = TwittProcessor.following.findOne(MongoDBObject("_id" -> userId))
user match {
case Some(u) => logger.info(s"Already following $userId")
case None => breaker.withSyncCircuitBreaker(followUser(userId))
}
breaker.withCircuitBreaker(Future(retweet(statusId)))
}
Et hop ! Votre code est ainsi protégé des divagations et autres quotas de Twitter.
Évidemment, Akka implémente toute une panoplie de patterns prêts à l’usage dont il serait idiot de se passer. Pour plus d’information, vous pouvez jeter un oeil ici.
Twitter4j
Pour la communication avec Twitter, j’utilise la bibliothèque Twitter4j qui fournit une boîte à outil conséquente sur laquelle je ne vais pas trop m’attarder, à part 2-3 petits points.
OAuth2 et API Keys
L’authentification chez Twitter passe systématiquement par OAuth2. Ce protocole d’authentification assez complexe à implémenter correctement permet de déléguer une partie des appels systèmes que vous pourriez vouloir faire en tant qu’utilisateur à un programme qui ne peut seulement faire que ce que vous lui avez autorisé à faire.
L’ensemble passe par un jeu de clés que vous devez stocker chez vous, pour chaque utilisateur de votre API, en plus de vos clés à vous. Soit 4 clés si vous avez un seul utilisateur. C’est vite compliqué à gérer et OAuth2 encourage à avoir un code très propre côté client pour éviter de se prendre les pieds dans le tapis.
Pour le bot Twitter, toutes ces informations sont stockés dans un fichier twitter4j.properties qui est lu automatiquement lors du démarrage de l’application pour créer le singleton RemoteServices :
object RemoteServices {
val mongoConn = MongoConnection()
val mongoDB = mongoConn("ouiouistiti")
var users = mongoDB("users")
val mongoColl = mongoDB("tweets")
val creds = scala.io.Source.fromFile("creds.txt").mkString.split("\n")
val searches = creds(0).split("\\|")
val banned = creds(1).split("\\|").map(_.toLong)
val twitter = {
val tf = new TwitterFactory()
tf.getInstance()
}
}
Même si le code final est assez laid, parce que je n’ai pas vraiment pris le temps de le rendre élégant, il reste qu’on voit quand même que créer un singleton avec Scala est trivial, y compris si sa construction nécessite des étapes un peu complexes (telles que lire un fichier).
Recherche
La recherche utilise une API en lecture seule de Twitter, et à ce titre peut fonctionner même si votre accès à l’API a été fortement limité pour vous. Son utilisation est vraiment très simple et directe :
def performSearch(currentSearch: String) = {
logger.info(s"Searching for $currentSearch")
val query = new Query(currentSearch)
query.setResultType(Query.ResultType.recent)
val result = getOrLogAndThrow(RemoteServices.twitter.search(query))
HarvesterActor.StoreResult(currentSearch, result)
}
On cherche ici les derniers tweets les plus récents, parce que c’est bien ce qui intéresse le bot. Mais dans l’absolu, vous pouvez aussi demander ceux qui sont les plus intéressants. Donc, il est facile de scruter tout le réseau social pour en extraire des choses intéressantes. Une fois la recherche faite, je compte le nombre de RT des messages et j’essaye de remonter au tweet originel, parce que c’est celui-là que je veux retweetter pour tenter de gagner :
def firstTweet(someTweet: Status): Status = {
if (someTweet.isRetweet) {
val status = RemoteServices.twitter.showStatus(someTweet.getRetweetedStatus.getId)
firstTweet(status)
} else {
someTweet
}
}
Le modèle objet de Twitter est très agréable à utiliser et l’API fortement lazy de Twitter4j permet d’éviter de faire des appels à gogos sur l’API Twitter. Un vrai bonheur !
RT
Pour écrire, vous devez avoir un accès en écriture aux comptes utilisateurs que vous manipulez. Mais ensuite, l’API reste simplissime pour faire ces appels :
def RTStatus(statusId: Long) = {
try { RemoteServices.twitter.tweets.retweetStatus(statusId) }
catch {
case e: TwitterException =>
if (e.resourceNotFound)
logger.info(s"Status $statusId not found.")
else
throw e
case e: Throwable => throw e
}
}
Cette fonction retweete un Status, dont on lui passe l’identifiant et gère le cas où le tweet n’existe plus (Hé oui, parfois, on vous donnera un identifiant de tweet qui n’existe plus comme source de retweet !).
C’est un simple appel et tout le reste du code ne sert qu’à la plomberie interne de gestion d’erreur.
Conclusion, le code et la suite ?
Bon, ben on a fait le tour. Vous pouvez aller voir le code du bot sur github et en faire diantre ce que vous voulez.
Le bot actuel a été mis en hivernage, parce que j’ai réussi à me faire bannir de Twitter au moment ou j’ai voulu rajouter une petit FIFO pour gérer les abonnés (la plupart des comptes n’ont pas le droit de suivre plus de 1000 comptes à la fois et le bot en suit plus de 1000 aussi). De toutes façons, je n’ai pas gagné assez de lots pour que l’expérience soit rentable, en dehors de la connaissance technique que j’en ai retirée. Le moins qu’on puisse dire, c’est qu’étudier les followers de ce compte est assez fascinant : on y trouve des robots (coucou les copains), des CMs en mal de followers et des gens probablement normaux qui se sont égarés par là. C’est d’autant plus fascinant (et inquiétant) que ce bot n’aura finalement twitté qu’une fois ou deux avec un statut tapé par mes petites mains. Le reste n’aura été que des RTs.
Essayez de faire du Scala et de faire des bots sur Twitter et faites-vous aussi bannir. Pour éviter de vous griller complètement, créez des comptes qui ne sont pas rattachés à votre compte principal, c’est la seule précaution à prendre pour éviter de vous faire bannir complètement un jour.
Il y a tellement d’applications que vous pouvez essayer de faire sur ce grand réseau qu’il serait dommage de ne pas en profiter : les Buffer, Hootsuite et Nuzzel ont tous bâti leur modèle économique sur l’utilisation massive de l’API Twitter.
