

Nous allons voir en quoi consiste JHipster-UML : pourquoi il a été créé, à quoi il sert et comment l’utiliser.
JHipster, créé par Julien Dubois, est un générateur Yeoman d’applications Spring + AngularJS.
Il permet de créer une application prête à être déployée aussi vite que possible, et il suffit donc de répondre à quelques questions pour que JHipster crée une application sur-mesure.
La création des entités se fait de manière identique : des questions sont posées pour connaître le nom de l’entité, puis le nom et les détails de chacun de ses attributs (type et contraintes). À la suite de cela, les fichiers nécessaires sont créés (classes Java, objets d’AngularJS, etc.).
Répéter ce processus semble, pour un nombre faible d’entités, assez rapide et peu pénible. En revanche, si un utilisateur de JHipster souhaite ajouter au-delà d’une demi-douzaine d’entités, cela peut vite devenir problématique pour lui car :
-
Créer autant d’entités prendrait beaucoup de temps, et ce temps aurait pu être passé à travailler sur autre chose de peut-être plus important ;
-
Plus il devra créer d’entités, plus les chances de se tromper (erreur de typo, mauvais type choisi, etc.) lors de la création de l’une d’elles seront élevées ;
-
S’il y a une erreur, il devra soit annuler la création, soit éditer un fichier JSON (généré par JHipster) manuellement.
Ainsi, l’idée de remplacer ce processus par un autre qui n’aurait aucun de ses désavantages était de plus en plus intéressante. C’est pour cela que JHipster-UML a été conçu.
Présentation de JHipster-UML
JHipster-UML est un module NPM qui peut être utilisé en parallèle à JHipster pour créer toutes vos entités et leurs relations entre elles à partir d’un diagramme de classes. Notre projet est également disponible sur GitHub.
Comment ça marche ?
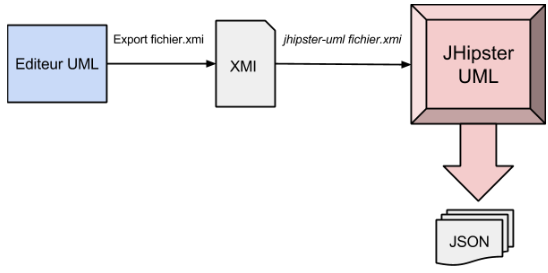
Créez un diagramme de classes avec un des éditeurs UML supportés par JHipster-UML (pour l’instant UML Designer, Modelio et GenMyModel). Une fois créé, exportez votre diagramme dans un fichier au format XMI. Dans la racine de votre projet JHipster, entrez la commande :
jhipster-uml <votre fichier xmi>
JHipster-UML va créer dans le dossier .jhipster tous les fichiers JSON de chaque entité et ensuite faire appel à JHipster avec la commande yo jhipster:entity pour chaque entité qui générera tout le code.
Les utilisateurs cibles
Avec JHipster-UML nous visons plusieurs catégories de personnes :
- Les utilisateurs de JHipster sont ceux qui peuvent profiter le plus de notre outil car ils suivent les nouveautés de JHipster (sur GitHub, Twitter, etc.), et sont prêts à tester et remonter les problèmes ;
- Les architectes (logiciel, base de données) et plus généralement les personnes qui font de l’UML sont notre deuxième cible. Si ceux-ci n’utilisent pas JHipster, ils peuvent être intéressés par ce que propose JHipster-UML, et au final ramener des utilisateurs potentiels à JHipster.
Nous avons comme but d’élargir la population d’utilisateurs de JHipster en les faisant utiliser JHipster-UML.
Comparaison de création d’entités JHipster vs JHipster-UML
Ci-dessous un tableau montrant le temps mis à créer tout un domaine avec l’ancienne méthode de question/réponse et avec JHipster-UML:
| 12 entités, 17 relations | |
| JHipster | 1h15 |
|
JHipster-UML |
30 min |
- d’être plus efficace,
- d’éviter les erreurs,
- de faire des corrections plus facilement,
- et d’avoir une vision globale du projet donc gagner du temps.
Pourquoi le XMI ?
Pour interpréter un diagramme UML nous avons décidé d’utiliser le format XMI. L’avantage de ce format est qu’il a été créé par le groupe OMG avec des spécifications documentées. Mais tous les éditeurs UML ne supportent pas l’export en XMI, et quand ils le supportent, il y a des différences au niveau de la syntaxe du fichier. Cela nous pose un problème pour son parsing, mais nous avons proposé une solution que nous présenterons dans la section d’architecture.
À cause de cette contrainte nous devons rajouter un parser pour un éditeur précis, pour l’instant (version 1.0.3) nous supportons ces éditeurs :
- GenMyModel ;
- UML Designer ;
- Modelio ;
- et Visual Paradigm.
Architecture
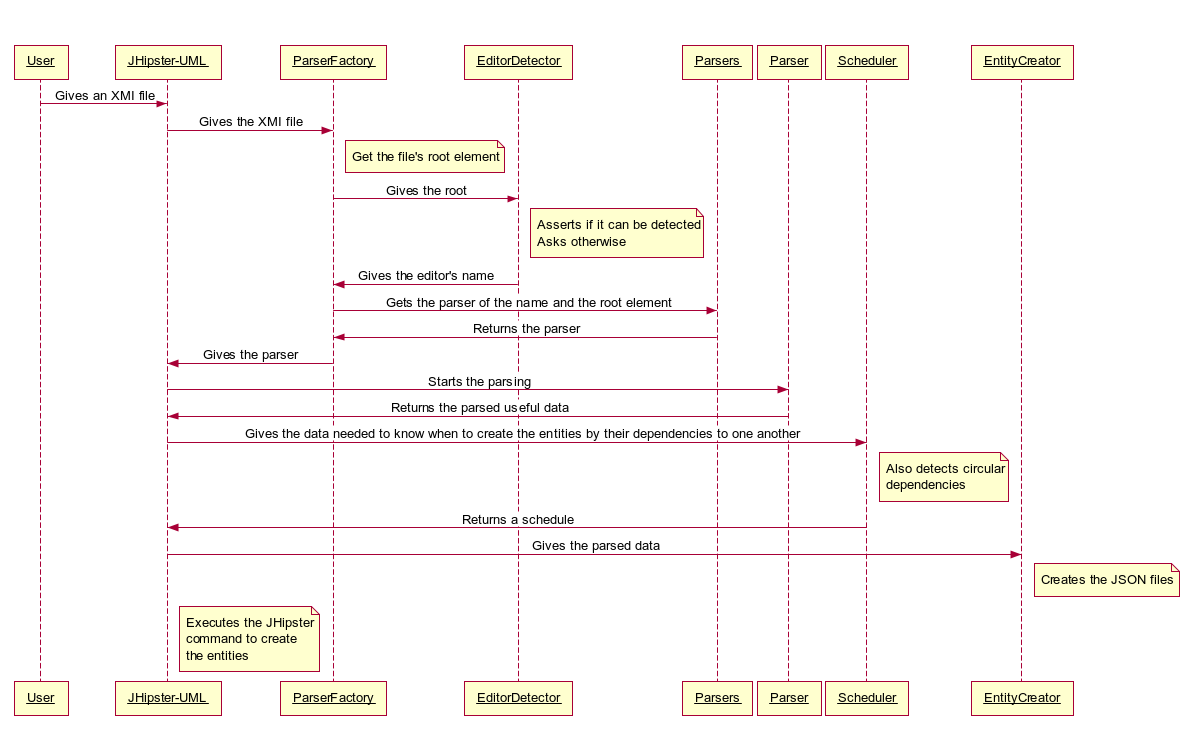
Notre architecture se base sur une division des tâches principales :
- Le parsing d’un fichier XMI pour récupérer les informations utiles ;
- La création des fichiers JSON pour la génération des fichiers par JHipster ;
- L’ordonnancement de la création des entités en fonction de leurs dépendances respectives.
Comme mentionné précédemment, les différences entre les structures internes des fichiers XMI nous a fait penser à une solution qui nous permettrait d’être souples au niveau du support de nouveaux éditeurs, et d’être capables de pouvoir rapidement effectuer un changement (mineur ou majeur) au niveau du code.
C’est pour cela que nous utilisons, au pire cas, un parser par éditeur UML (dans le meilleur cas, un parser peut être réutilisé).
La détection de l’éditeur qui a créé un fichier XMI se fait de manière quasi-transparente pour l’utilisateur. Soit son éditeur est détecté et le parsing se lance, soit il devra choisir parmi une liste d’éditeurs supportés (parsers implantés).
Une fois que le parsing est achevé, notre créateur d’entités se charge de générer les fichiers JSON qui seront utilisés par JHipster pour créer les fichiers des entités. Ici, nous sommes clairement dépendants de JHipster dans la mesure où la structure interne des fichiers JSON nous est imposée par l’outil. L’élimination, ou du moins la réduction, de cette dépendance est une piste que nous explorons.
Enfin, puisque nous ne pouvons pas “simplement” lancer la génération de chaque entité dans un ordre quelconque à cause des dépendances entre chaque entité (associations One-to-One, etc.), nous utilisons un algorithme d’ordonnancement qui se charge de déterminer un ordre de création (cet ordre peut ne pas être le seul ordre possible).
L’algorithme arrive à savoir si une dépendance circulaire existe au niveau des dépendances. Dans ce cas, il arrive à le savoir après n itérations (n étant le nombre d’entités présentes).
Voici la séquence d’enchaînement des actions :
Évolutions
JHipster-UML est déjà un grand pas vers la simplification de l’utilisation de JHipster. Nous espérons le rendre encore plus accessible, mais nous ne sommes qu’à la première étape du projet JHipster-UML, nous avons encore des axes d’améliorations à explorer. Nous pensons par exemple que la création d’entités avec un éditeur UML peut être restrictif dans le cas de la création de types, et la création de contraintes pour les attributs n’est pas possible sur la plupart des éditeurs. C’est pourquoi nous sommes en train de réaliser un éditeur lightweight de diagrammes de classes spécialisé JHipster pour suppléer à la solution existante.
Nous essayons également de simplifier la création des entités par les moyens collaboratifs existants (avec Google, GitHub, etc.) en créant un DSL (Domain Specific Language) qui serait un moyen plus simple et plus agréable de créer des entités plutôt que modifier les fichiers JSON de “dump” de JHipster.
Mais nous voulons améliorer l’existant. C’est pourquoi nous avons créé un questionnaire rapide pour connaître vos habitudes, il nous permettra de rendre JHipster-UML plus adapté à vos besoins.