
Apache Flume, un top-level project d’Apache, est disponible en version 1.6.0 depuis le 20 mai 2015. Tour d’horizon des nouvelles fonctionnalités.
Petit rappel des faits
Apache Flume est un service distribué et tolérant à la panne utilisable pour de la collecte et de l’agrégation de gros volumes de données.
Les distributions Hadoop intègrent Flume pour l’ingestion de ces logs dans HDFS et des frameworks comme Spark Streaming proposent également une API pour pouvoir ingérer des données depuis Flume.
Pour faire transiter des données via Flume, il est nécessaire de définir un agent qui regroupera les composants, à savoir des sources, channels, interceptors et sinks, en charge des tâches suivantes :
- récupérer les données depuis une source
- les faire transiter sur un chemin
- les filtrer, réaliser des opérations dessus
- les envoyer vers une destination.
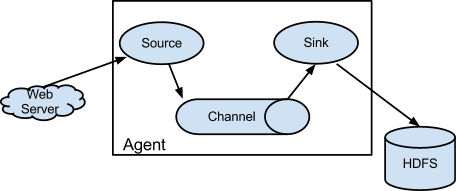
Cet agent, avec ses traitements, est défini dans un fichier de configuration qui est, par la suite, fourni en paramètre à l’exécution de Flume.
Cette façon de procéder de Flume permet de mettre en place des chaînes d’agents pour réaliser des traitements plus complexes :

De plus, Flume met à disposition des Interceptors pour modifier, filtrer des évènements, ainsi que des Serializers pour agir sur le format des données en sortie.
Les évènements transitant à travers Flume sont constitués d’un en-tête regroupant des informations sur ceux-ci et d’un corps contenant le log.
L’en-tête est utile pour stocker les informations servant à filtrer et rediriger un évènement vers une destination en particulier.
Les nouveautés de la 1.6.0
Avec l’arrivée de cette version en mai, 152 patchs ont été ajoutés au projet depuis la version 1.5.2 sortie le 18 novembre 2014 (change log).
Différentes fonctionnalités sont apparues, notamment :
- la collecte et l’envoi de données vers Apache Kafka
- l’utilisation de Kafka comme Channel
- l’envoi de données vers Hive avec le nouveau support de Hive Streaming
- une authentification End-to-End dans Flume
- l’implémentation d’un Interceptor avec des regex Search-and-Replace
Flume avec Kafka
Grâce à cette version, Apache Kafka peut être utilisé comme support pour chacun des composants de Flume, à savoir en tant que Source, Channel et Sink. Cela implique qu’il est possible d’utiliser Kafka à la fois pour chaîner ses agents Flume et pour faire transiter ses données entre les sources et les sinks.
Sur les versions antérieures, ce chaînage entre agents doit être réalisé au moyen d’Avro, comme on peut le voir sur le schéma précédent.
L’Interceptor Search-and-Replace
Grâce à l’implémentation de cet Interceptor, on peut agir directement sur le corps du log qui transite dans Flume depuis le fichier de configuration fourni pour l’exécution d’un agent.
Sans cet Interceptor, il est nécessaire d’avoir recours à un Serializer fourni, soit par Flume ou alors, implémenté par nos propres soins, qu’on applique au moment de l’écriture de notre log dans le Sink.
Le Hive Sink
Ce Sink, apparu dans cette version et déconseillé actuellement dans le cadre d’une utilisation en production, apporte des fonctionnalités intéressantes pour ceux qui couplent Flume et Hive.
Dans les versions précédant la 1.6.0, il était nécessaire d’utiliser le HDFS Sink afin de pousser nos données traitées avec Flume sur HDFS et de créer une table externe Hive pointant sur le répertoire HDFS les contenant.
Enfin, dans le cas de données partitionnées, il faut mettre à jour cette table externe pour lui ajouter les partitions traitées au fur et à mesure (maj réalisée via un “alter table” sur les valeurs de partition), ce qui aura pour effet de rendre visible les données incluses dans ces dernières.
Le nouveau Hive Sink se différencie du HDFS Sink sur la disponibilité des données dans Hive après traitement puisqu’il intègre la gestion automatique des partitions directement dans Flume et qu’au lieu de manipuler des tables externes, ce sera des tables internes de Hive.
En résumé
Dans ce post de blog, je n’ai donné qu’un avant-goût des dernières fonctionnalités proposées dans Apache Flume 1.6.0.
Si vous souhaitez en savoir plus sur ces dernières ou tout simplement découvrir celles non abordées dans ce post, je vous invite à consulter la documentation de Flume.
