
Ce post découle d’une série de posts sur Apache Spark par Alexis Seigneurin et s’appuie sur celui de Florence Herrou sur Metrics de Dropwizard.
Nous aborderons dans cet article comment procéder pour extraire des métriques métiers d’une application Java pour ensuite les traiter avec Spark.
La théorie
Lorsque nous avons une application en production, il est toujours intéressant d’avoir des informations sur ses points critiques et comment les utilisateurs interagissent avec.
Pour faire cela, l’intégration du framework Metrics de Dropwizard développé par Coda Hale pour la société Yammer nous permet d’effectuer des mesures sur les différents éléments de notre application Java, mesures que Metrics exporte périodiquement.
Et du côté analyse de données, nous avons Apache Spark, un outil de traitement distribué de gros volumes de données, qui se distingue de ses concurrents en proposant une même API pour traiter aussi bien un gros volume de données figées que des données envoyées périodiquement dans un flux (traitement batch et traitement en streaming).
Au niveau traitement, l’API de Spark nous propose toute une gamme d’opérations allant du MapReduce au Machine Learning. Tous ces traitements peuvent ensuite être stockés facilement dans une base, dans un système de fichiers ou par exemple envoyés dans un moteur de recherche type ElasticSearch.
En combinant ces deux outils, nous nous retrouvons donc avec, d’un côté, un Reporter de Metrics qui va envoyer périodiquement des données dans un flux, qui lui, est écouté par un Receiver de Spark Streaming qui traite ces données reçues au fur et à mesure.
Ces explications peuvent être schématisées de la façon suivante :
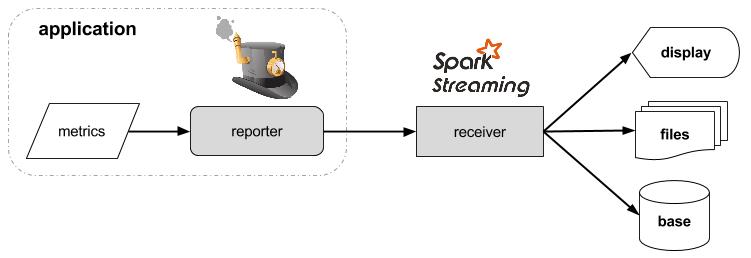
Après une première approche théorique, nous allons voir chacun des éléments plus en détail.
Metrics

Dans la librairie Metrics, le reporting se fait au moyen de Reporters en charge de l’encapsulation des métriques obtenues sur l’application et de l’envoi périodique de celles-ci à un système tiers ou sur la sortie voulue.
Dans le but d’envoyer les données de notre application dans Spark, nous avons créé notre propre Reporter qui récupère périodiquement les différentes mesures enregistrées, les sérialise et les envoie dans une socket à destination d’une application Spark.
L’instanciation de notre Reporter se fait de la manière suivante :
SparkReporter sparkReporter = SparkReporter.forRegistry(metricRegistry) .convertRatesTo(TimeUnit.SECONDS) .convertDurationsTo(TimeUnit.MILLISECONDS) .build("localhost", 9999); sparkReporter.start(10, TimeUnit.SECONDS);
Spark Streaming
![]()
Comme il s’agit de données envoyées périodiquement, nous sommes dans un cas de traitement en streaming et donc adapté au traitement par Spark Streaming.
Dans le cas où, au contraire, on souhaite d’abord stocker les données reçues et les traiter dans un futur proche ou lointain, il existe des Reporters de Metrics pour stocker les données dans Cassandra, ElasticSearch, etc… On peut lancer un traitement Spark sur ces données stockées ensuite via un batch mais ce n’est pas le but de ce post.
Dans ce post d’Alexis Seigneurin, nous avons vu que Spark Streaming est capable de lire des flux provenant de différents types de sources.
Cependant, dans notre cas, nous avons eu besoin d’écrire notre propre Receiver pour se connecter à notre Reporter.
Ce choix découle d’une volonté de notre part de garder ce reporting le plus simple possible, c’est-à-dire de ne pas ajouter de solutions tierces pour faire le lien entre notre application et Spark alors qu’une connexion directe entre les deux répond amplement à notre problème. Autrement, nous aurions pu utiliser une solution comme Apache Kafka pour transmettre les données sachant que Spark Streaming propose déjà un Receiver pour Kafka.
Pour instancier notre Receiver fait maison, qui se charge de lire le flux et de désérialiser les données, l’API de Spark Streaming met à disposition la méthode receiverStream() utilisée de la manière suivante :
SparkConf conf = new SparkConf() .setAppName(“JavaAppToSparkApp”) .setMaster(“local[2]”); JavaStreamingContext ssc = new JavaStreamingContext(conf, new Duration(10000)); ssc.receiverStream(new MetricsReceiver(9999)) .print();
Dans cet exemple, nous avons donc lancé un contexte Spark avec pour nom “JavaAppToSparkApp” s’exécutant en local (“local[2]” pour spécifier un thread pour la lecture du flux entrant et un thread pour l’exécution des traitements). Et on a indiqué au contexte qu’il lançait ses traitements sur les données toutes les 10 secondes.
Ici on affiche donc dans la console les 10 premiers éléments reçus toutes les 10 secondes (opération “print()”) :
Pour information, “ssc.receiverStream(…)” nous retourne un DStream de HashMap<String, Object>>.
Devenir un Spark JHipster
Pour tester ce reporting de Metrics vers Spark Streaming, il existe une solution facile : le lancement d’une application JHipster en activant le bon Reporter.
 Petit rappel :
Petit rappel :
JHipster, un générateur Yeoman utilisé pour créer un project Spring + AngularJS, implémente la librairie Metrics par défaut et peut être configuré pour envoyer des métriques en JMX et à un serveur Graphite (par défaut, l’envoi de données en JMX est activé et celui à Graphite désactivé).
La pratique :
Une fois notre application JHipster créée (suivre le [post](/2014/11/19/jhipster-dans-la-pratique/) de Michaël Pages), l’instanciation du SparkReporter se trouve dans la classe “MetricsConfiguration”. À cet endroit, on peut choisir la période d’envoi des données vers Spark :sparkReporter.start(1, TimeUnit.MINUTES);Concernant le flux sur lequel seront envoyées nos métriques, la configuration se fait dans les fichiers “applications-dev.yml” et “application-prod.yml” où on peut activer/désactiver le reporting vers Spark et choisir le chemin, les valeurs par défaut étant :
metrics: spark: enabled: false host: localhost port: 9999
Et c’est tout. Tout du moins, il ne reste plus qu’à lancer l’application JHipster.
Pour cela, il suffit de faire un mvn spring-boot:run
Ça y est, vous êtes un Spark JHipster !
Conclusion
Comme on a pu le voir, l’intégration de ce reporting d’une application Java vers Spark Streaming se fait de manière simple.
Pour utiliser ce Reporter et Receiver dans un projet, il est juste nécessaire d’ajouter cette dépendance :
Le code correspondant est disponible sur le compte Github d’Ippon Technologies :
Dans chacun des deux repositories se trouve un exemple que vous pouvez essayer avec Docker :
- Une application JHipster envoyant des données.
- Une application Spark qui reçoit les données et affiche les 10 premières sur la console.
