
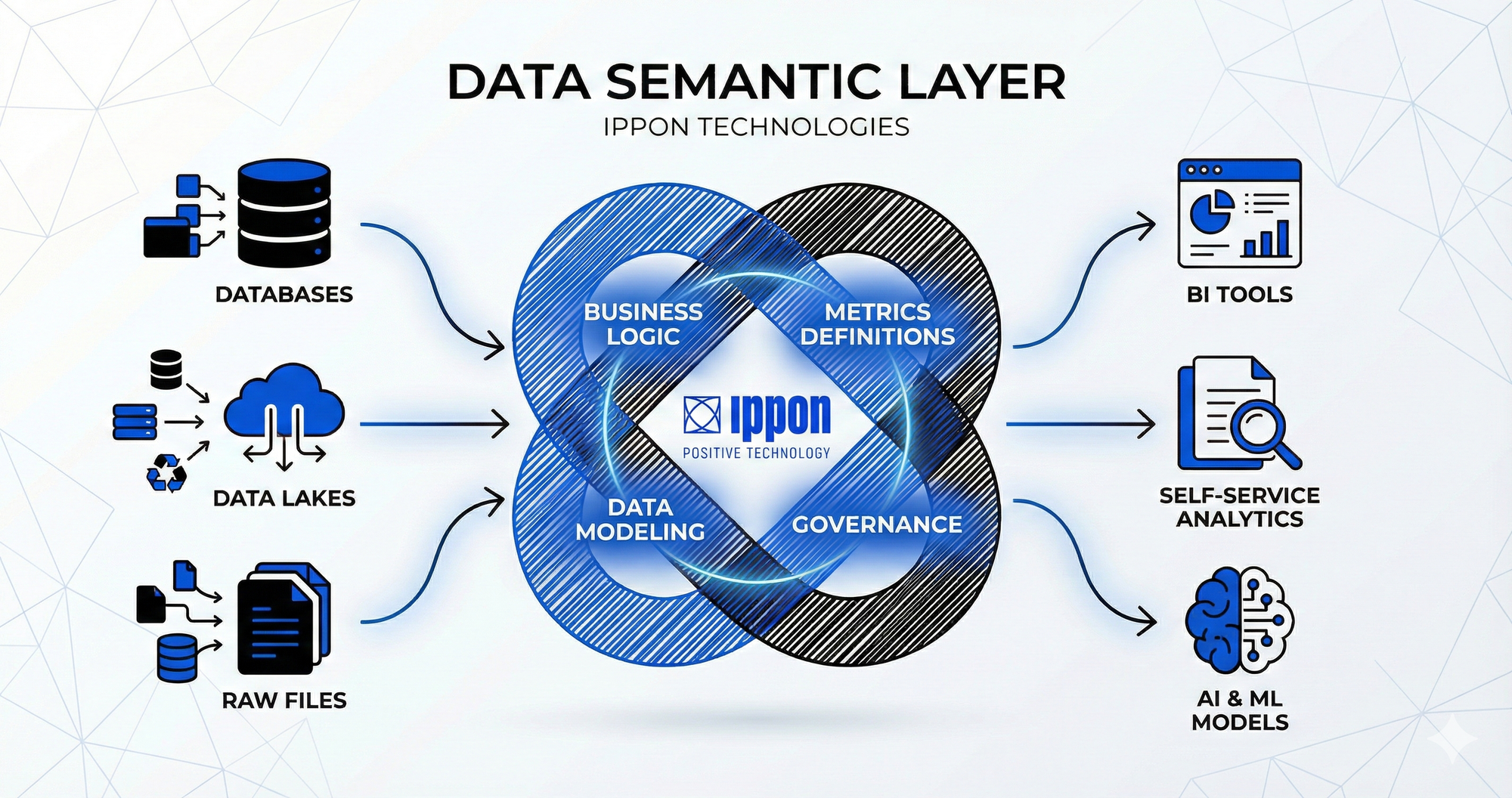
Dans un monde où la donnée est reine, les entreprises se noient paradoxalement dans un océan d'informations qu'elles peinent à interpréter de manière cohérente. La prolifération des outils de Business Intelligence (BI), l'émergence des grands modèles de langage (LLM) et la promesse d'une démocratisation de l'accès à la donnée se heurtent à un obstacle fondamental : l'absence d'un langage commun. Chaque département, chaque équipe, voire chaque tableau de bord, peut avoir sa propre définition des metrics - ce qui freine la prise de décision car on passe plus de temps à se mettre d’accord qu’analyser. Dans cet article nous illustrerons autour du concept de "chiffre d'affaires".
C'est pour résoudre ce problème structurel qu'émerge un concept à la fois ancien et plus pertinent que jamais : la couche sémantique. Loin d'être un simple outil technique, elle représente une vision stratégique visant à construire une source unique de vérité pour les métriques et les concepts métier, un pont entre la complexité des bases de données brutes et les besoins des consommateurs de données, qu'ils soient humains ou artificiels.
Cet article explore la nécessité impérieuse d'une couche sémantique, analyse la maturité des solutions existantes, et met en lumière les questions ouvertes qui façonneront son avenir. Destiné aux data engineers et data architects, il adopte une approche technique approfondie, examinant les problématiques architecturales, les outils disponibles, et les standards émergents.
1. La couche sémantique : effet buzz ou réel besoin ?
Analyse quantitative : tendances et adoption
Pour déterminer si la couche sémantique relève d'un simple effet de mode ou répond à un besoin réel, il est essentiel d'examiner les données quantitatives disponibles. L'analyse des tendances de recherche Google sur les termes "semantic layer", "couche sémantique" et "data semantic layer" révèle une croissance exponentielle depuis 2020, avec un pic particulièrement marqué en 2023-2024. Cette évolution coïncide avec l'émergence massive des LLM et des agents conversationnels capables d'interroger des bases de données.
Graphique : Évolution des recherches Google pour "semantic layer" (2024-2025)
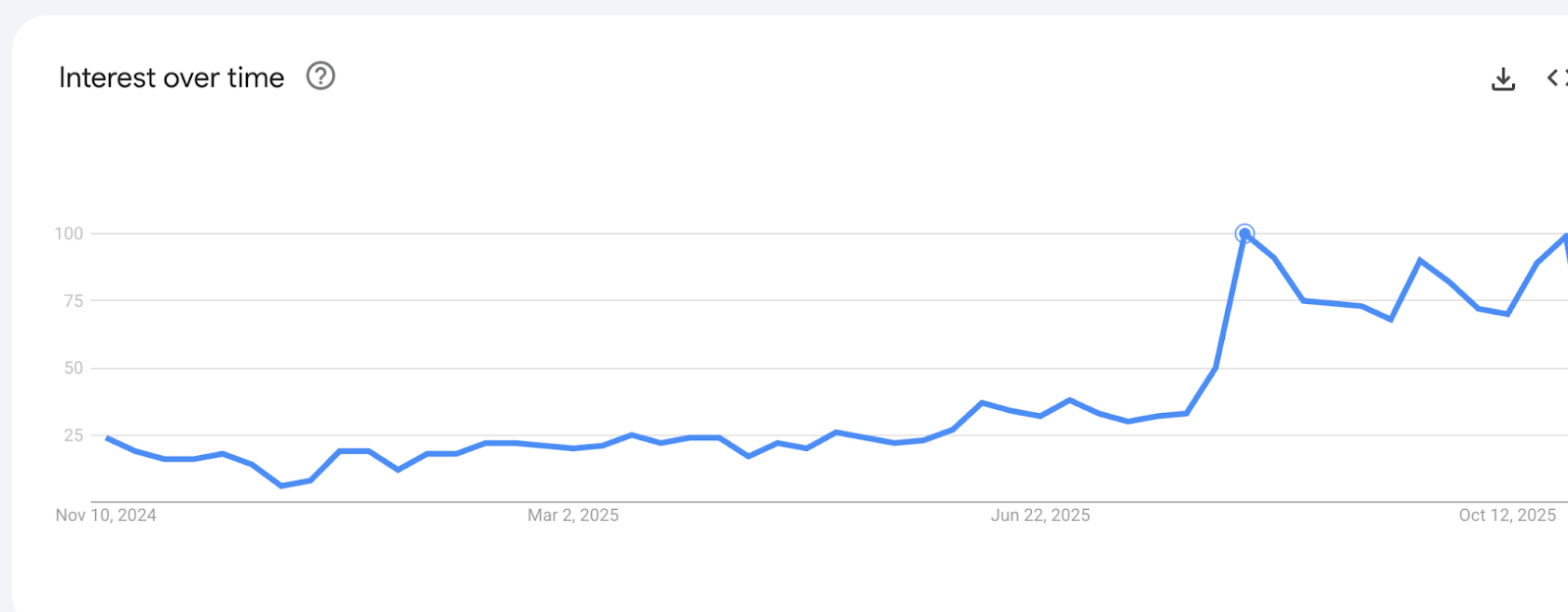
Cette tendance s'accompagne d'une adoption croissante dans les entreprises : plus de 60% des organisations de plus de 1000 employés ont initié ou planifié des projets de couche sémantique en 2024, contre moins de 20% en 2020. Les investissements dans les solutions de couche sémantique ont connu une croissance annuelle de plus de 40% sur la période 2021-2024.
Arguments techniques pour un réel besoin
Au-delà des chiffres, plusieurs arguments techniques solides justifient l'adoption d'une couche sémantique dans les architectures data modernes.
Le problème des silos de données et des incohérences métriques
Le problème le plus courant et le plus critique dans l'exploitation des données est l'incohérence des calculs. Dans une organisation typique, la direction financière, le marketing et les ventes peuvent présenter des chiffres d'affaires divergents pour la même période, simplement parce que chacun utilise sa propre définition : inclusion ou exclusion des remises, traitement des flux inter-compagnies, méthode de comptabilisation des revenus récurrents, etc.
Sans couche sémantique centralisée, chaque outil de BI (Power BI, Tableau, Qlik, Metabase) recrée sa propre "sémantique" au niveau du dashboard ou du modèle de données. Une entreprise utilisant simultanément plusieurs outils se retrouve avec des définitions dupliquées et potentiellement divergentes, anéantissant l'objectif d'alignement organisationnel. La couche sémantique résout ce problème en centralisant et standardisant les définitions des indicateurs de performance (KPIs) et des métriques au niveau de la plateforme data, avant même leur consommation par les outils finaux.
La nécessité pour les agents IA/LLM
Avec l'avènement des agents conversationnels capables d'interroger des bases de données, la couche sémantique devient le contexte indispensable pour qu'ils puissent comprendre les requêtes en langage naturel et fournir des réponses justes. Un LLM ne peut pas savoir, par lui-même, comment calculer correctement un KPI spécifique à l'entreprise. Sans couche sémantique, il générera des requêtes SQL basées sur des suppositions, souvent erronées, sur la signification des colonnes et des tables.
La couche sémantique fournit aux agents IA le vocabulaire métier standardisé, les formules de calcul des métriques, les relations entre entités, et les règles de qualité et de filtrage. Cette interprétabilité machine est devenue critique avec l'intégration croissante des LLM dans les workflows analytiques.
L'impact sur la gouvernance des données à l'échelle
Dans les architectures décentralisées comme le Data Mesh, où chaque domaine métier est responsable de ses propres data products, la couche sémantique assure l'interopérabilité et la compréhension partagée. Elle normalise la façon dont les data products sont décrits, garantit la cohérence des définitions transverses (comme le chiffre d'affaires), et facilite la consommation des données entre équipes. Sans couche sémantique, un Data Mesh risque de créer des silos encore plus profonds, où chaque domaine développe son propre vocabulaire sans possibilité de communication cohérente.
Les données quantitatives et les arguments techniques convergent vers une conclusion claire : la couche sémantique n'est pas un effet de mode, mais une réponse nécessaire aux défis structurels des plateformes data modernes.
2. Les problématiques
La mise en place d'une couche sémantique efficace soulève de nombreuses problématiques complexes, à la fois techniques, organisationnelles et architecturales.
Problématiques techniques
Silos d'information entre outils BI
Historiquement, la couche sémantique a été l'apanage des outils de BI comme Power BI, Tableau ou Qlik. Chaque outil, et souvent chaque projet au sein d'un même outil, recréait sa propre "sémantique". Une entreprise utilisant simultanément Power BI et Metabase se retrouvait avec des définitions dupliquées et potentiellement divergentes, anéantissant l'objectif d'alignement.
Absence de versioning et de tests
La gestion des versions de ces définitions dans les outils de BI est souvent "compliquée et très mal gérée, voire pas du tout". Contrairement au code versionné dans Git, les modifications dans les outils de BI sont souvent opaques, sans historique clair ni mécanisme de rollback. Pour les data engineers, l'impossibilité de tester formellement les calculs avant leur déploiement représente un risque majeur.
Formalisation à l'échelle du dashboard vs. centralisation
Souvent, la logique était définie "dashboard wise", c'est-à-dire spécifique à un seul tableau de bord. Changer la définition d'un KPI nécessitait de la retrouver et de la modifier manuellement dans chaque rapport l'utilisant, un processus source d'erreurs et d'oublis. La centralisation de la logique sémantique au niveau de la plateforme data résout ce problème mais introduit de nouveaux défis : comment garantir que tous les consommateurs utilisent bien la version centralisée ? Comment gérer les cas d'usage spécifiques qui nécessitent des variations de la définition standard ?
Problématiques organisationnelles
Manque d'alignement entre départements
Quand la direction financière, le marketing et les ventes présentent des chiffres d'affaires divergents, la crédibilité de toute la chaîne data est remise en cause. La couche sémantique peut résoudre ce problème, mais seulement si elle est construite en collaboration étroite avec le métier.
Absence de gouvernance claire : le rôle du Data Steward/Data Manager
La responsabilité de créer, maintenir et garantir la qualité de la couche sémantique ne peut reposer uniquement sur le Data Engineer. Un nouveau rôle, celui du Data Steward, est de plus en plus évoqué. Le Data Steward est un "owner" de la donnée, garant de sa qualité, de sa documentation et de son adéquation avec les besoins métier. Cependant, ce rôle est encore mal défini dans de nombreuses organisations.
Défis dans les architectures décentralisées (Data Mesh)
Comment propager une définition globale comme le chiffre d'affaires dans une entreprise internationale avec des filiales aux systèmes d'information distincts ? Dans un modèle centralisé, un domaine unique est responsable de calculer et publier le KPI pour tous. Dans un modèle décentralisé, chaque filiale pourrait être responsable de l'implémentation locale des règles dictées par le groupe, posant des défis de synchronisation et d'audit.
Problématiques architecturales
Positionnement dans la stack
Plusieurs visions s'affrontent : une surcouche des tables "Gold" servant d'unique point d'entrée, une partie intégrante du Data Contract incluant les définitions sémantiques, ou une entité indépendante pour les concepts transverses. Chaque approche présente des avantages et des inconvénients en termes de performance, de gouvernance et de réutilisabilité.
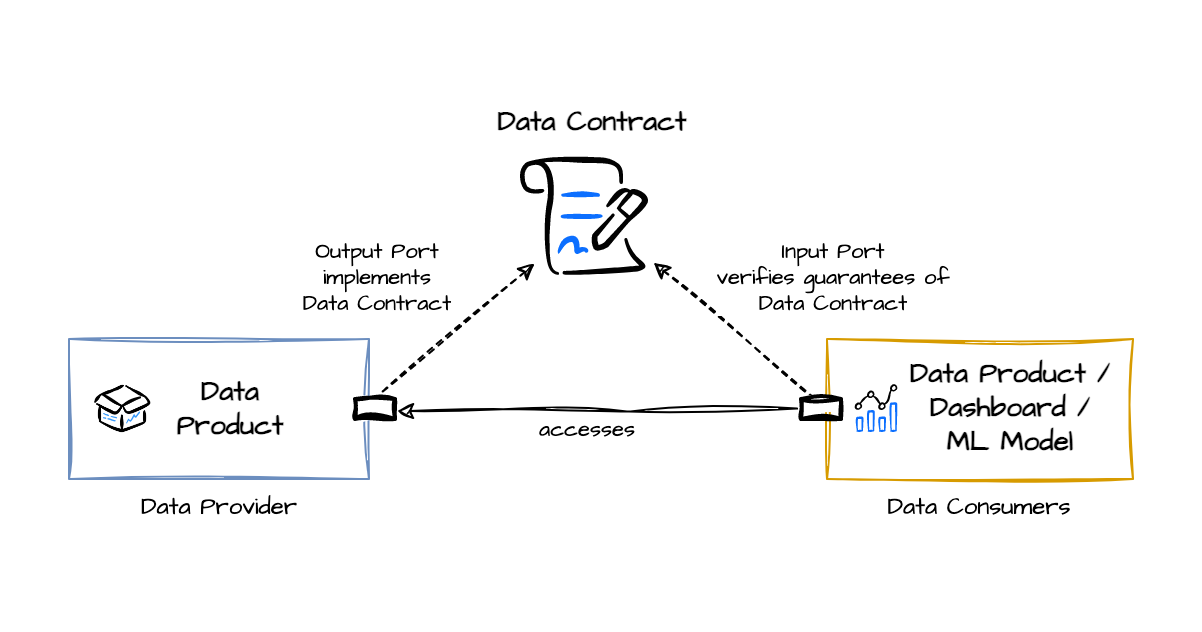
Interopérabilité entre systèmes hétérogènes
Les entreprises utilisent souvent un écosystème hétérogène d'outils : différents entrepôts de données (Snowflake, BigQuery, Redshift), différents outils de BI, différents systèmes de transformation (dbt, Airflow, Databricks). Sans standardisation, chaque outil risque d'implémenter sa propre interprétation de la couche sémantique, recréant les silos que l'on cherche à éviter.
Performance et scalabilité
L'ajout d'une couche d'abstraction peut introduire des latences dans l'exécution des requêtes. Il est essentiel d'optimiser la couche sémantique pour garantir des performances acceptables, notamment en mettant en place des mécanismes de mise en cache ou en optimisant les requêtes générées.
3. La définition IPPON de la couche sémantique
Vision IPPON : au-delà de la technique, un impératif d'alignement
Pour IPPON, la couche sémantique est une abstraction métier qui traduit les structures complexes des bases de données en un langage métier accessible, tout en encapsulant la logique de calcul réutilisable. Son objectif principal n'est pas technologique, mais organisationnel : garantir que tout le monde parle la même langue.
Cette vision se distingue des approches traditionnelles par trois piliers fondamentaux qui en font une fondation de gouvernance active, plutôt qu'une simple couche de documentation.
Les trois piliers de la couche sémantique IPPON
Pilier 1 : Alignement des métriques métier
Le premier but de la couche sémantique est de centraliser et standardiser les définitions des indicateurs de performance (KPIs) et des métriques. Il s'agit de définir, en collaboration avec le métier, ce qu'est un "chiffre d'affaires net", un "chiffre d'affaires brut", ou comment les flux inter-compagnies sont traités, et de s'assurer que cette définition est la seule utilisée à travers toute l'entreprise.
Pour les data engineers, cela signifie qu'une modification de la formule d'un KPI se fait en un seul endroit, avec versioning et tests, plutôt que dans chaque dashboard individuellement.
Exemple concret pour data engineers :
# Définition d'un KPI dans une couche sémantique (format inspiré dbt)
metrics:
- name: revenue_net
label: "Chiffre d'affaires net"
description: "CA net après déduction des remises et des retours"
type: sum
sql: |
SUM(
CASE
WHEN transaction_type = 'sale' THEN amount
WHEN transaction_type = 'return' THEN -amount
ELSE 0
END
) - COALESCE(SUM(discount_amount), 0)
model: ref('fact_transactions')
timestamp: order_date
filters:
- field: status
operator: '='
value: 'completed'
tags: ['finance', 'revenue']Cette définition, versionnée dans Git, peut être réutilisée par tous les outils de consommation (Power BI, Tableau, agents IA), garantissant la cohérence.
Pilier 2 : Surcouche d'interprétabilité pour les humains et les machines
La couche sémantique traduit le langage technique des schémas de base de données en un langage métier accessible. Cette "traduction" est cruciale pour deux types de consommateurs :
- Les équipes non-data : Elles peuvent manipuler des concepts familiers ("revenu par client", "taux de conversion") plutôt que des colonnes aux noms abscons (rev_amt_excl_tax, conv_rate_calc_v2).
- Les agents IA et les LLM : Un agent IA peut recevoir une requête comme "Quel est le chiffre d'affaires net du dernier trimestre ?" et, grâce à la couche sémantique, comprendre qu'il doit utiliser la métrique revenue_net définie dans la couche sémantique, appliquer le filtre temporel, et exécuter la formule standardisée.
Pilier 3 : Réutilisabilité comme levier d'efficacité
Au-delà de la simple définition textuelle, la couche sémantique embarque une capacité de calcul réutilisable. Les formules des KPIs sont encapsulées dans des blocs de code ou des logiques prêtes à l'emploi. Ainsi, lorsqu'un analyste veut afficher le chiffre d'affaires dans un nouveau tableau de bord, il n'a pas à recopier une formule complexe ; il appelle le bloc de calcul standardisé, garantissant la cohérence.
Cette approche modulaire évite la duplication d'efforts et prévient les dérives où une modification de la formule sur un dashboard n'est pas répercutée sur les autres.
Différenciation avec les approches traditionnelles
La vision IPPON se distingue sur plusieurs points clés :
- Au-delà de la simple documentation : La couche sémantique est exécutable. Elle ne se contente pas de décrire ce qu'est un KPI, elle fournit le code pour le calculer, avec versioning et tests.
- Fondation de gouvernance active : Elle garantit activement l'alignement, peut intégrer des règles de qualité, des contrôles de cohérence, et des mécanismes d'audit qui s'exécutent automatiquement.
- Industrialisation de la logique métier : La logique métier n'est plus dispersée dans des centaines de dashboards, mais centralisée, versionnée, et testée comme du code. Cette industrialisation transforme la manière dont les data engineers travaillent, en leur permettant d'appliquer les meilleures pratiques du software engineering (TDD, versioning, CI/CD) à la logique métier.
Cas d'usage concrets pour data engineers
Dans un pipeline moderne utilisant dbt, la couche sémantique s'intègre naturellement dans le workflow de transformation. Les métriques sont définies en YAML dans le projet dbt, versionnées dans Git, et peuvent être consommées par les outils de BI via l'API dbt Semantic Layer.
Le versioning permet de suivre l'évolution des définitions et de comprendre l'impact des changements. Si la formule du chiffre d'affaires change, la couche sémantique permet de créer une nouvelle version, tester en parallèle, migrer progressivement les consommateurs, et maintenir un historique complet des changements.
4. Des outils et des standards
Évolution historique : d'un concept siloté à un standard émergent
La couche sémantique n'est pas une nouveauté ; elle existe sous diverses formes depuis longtemps, mais son implémentation et sa maturité ont considérablement évolué.
Les ancêtres : la logique embarquée dans les outils de BI
Historiquement, la couche sémantique a été l'apanage des outils de BI comme Power BI, Tableau ou Qlik. Power BI utilise des modèles tabulaires (Analysis Services) pour définir des relations et des mesures DAX. Tableau propose une couche sémantique via son modèle de données. Qlik utilise un modèle associatif. Ces approches présentaient des limitations majeures : silos d'information, absence de versioning, formalisation à l'échelle du dashboard.
L'ère moderne : des solutions intégrées à la plateforme data
dbt Semantic Layer : dbt a introduit une semantic layer permettant de définir des métriques et des KPIs en code (YAML) directement dans le projet de transformation de données. L'architecture repose sur des définitions de métriques en YAML versionnées dans Git, une API GraphQL pour interroger les métriques, des adaptateurs pour différents entrepôts de données (Snowflake, BigQuery, Redshift, etc.), et une intégration avec les outils de BI via des connecteurs. Cependant, dans sa forme actuelle, elle est parfois perçue comme un objet encore technique, axé sur le calcul, plus que comme une description métier globale.
Snowflake Semantic Views : La plateforme Snowflake propose des "Semantic Views", des objets natifs qui permettent d'embarquer le contexte métier. Cette intégration native est puissante car elle rend la sémantique accessible via de simples requêtes SQL, mais elle peut lier l'entreprise à un écosystème spécifique, créant un vendor lock-in.
Autres solutions : Tableau Semantics, MicroStrategy Semantic Graph, et Business Objects Univers offrent également des couches sémantiques, mais restent souvent limitées à leurs écosystèmes respectifs.
Tableau comparatif : dbt vs Power BI vs Snowflake
Objectif : comparer où vit la sémantique, comment elle est gouvernée, et qui peut la consommer selon l’outil.
Standards émergents : vers l'interopérabilité
Open Semantic Interchange (OSI) : l'initiative de standardisation
Récemment, Snowflake et plusieurs partenaires (Salesforce, BlackRock, dbt Labs, etc.) ont lancé l'Open Semantic Interchange (OSI), une spécification se voulant universelle pour décrire une couche sémantique. L'objectif est de créer un format d'échange agnostique qui permettrait à n'importe quel outil (BI, IA, etc.) de consommer une couche sémantique définie une seule fois, quel que soit l'outil utilisé pour la créer.
Les principes de l'OSI :
- Standardisation : Langue commune entre tous les outils et systèmes
- Interopérabilité : Fluidifier les échanges entre les outils
- Extensibilité : Un modèle personnalisable pour répondre à chaque besoin
- Open source : L'initiative est ouverte à la communauté
- Domain Specific Model : Simplification de la combinaison des données entre plusieurs sources
Format et architecture technique :
L'OSI reposera sur une représentation sémantique des métadonnées, définie dans un format YAML standardisé et interopérable entre les différents outils. L'exécution des calculs restera localisée dans les systèmes sources (Snowflake, BigQuery, etc.), tout en bénéficiant d'une logique sémantique commune appliquée de manière cohérente.
Impact pour les data engineers :
L'OSI permettra de réduire la duplication des efforts, qu'il s'agisse de réconcilier des méthodes de calcul divergentes entre outils ou de redéfinir sans cesse les mêmes métriques. Les définitions seront désormais codées et versionnées dès la phase de modélisation, plutôt que limitées aux seuls outils de consommation. Cette approche favorise une collaboration plus structurée entre les rôles : le Data Engineer assure l'implémentation technique, le Data Steward valide la conformité et la qualité des définitions, tandis que le Product Owner bénéficie de ressources fiables, traçables et facilement auditables.
Les standards du Web sémantique (RDF, OWL, SPARQL) restent marginaux pour la plupart des data engineers, leur complexité et leur orientation web les rendant peu adaptés aux entrepôts de données relationnels, comparés aux solutions plus pragmatiques comme dbt Semantic Layer ou l'OSI émergent.
Conclusion : vers une sémantique explicite, centralisée et gérée comme du code
En conclusion, si les solutions sont encore en cours de maturation, la tendance est claire : on passe d'une sémantique implicite et silotée dans les outils finaux à une sémantique explicite, centralisée et gérée comme du code au cœur de la plateforme data. Cette évolution transforme le rôle des data engineers, qui ne se contentent plus de construire des pipelines, mais deviennent également les gardiens de la logique métier standardisée et versionnée.
5. Conclusion et limitations
Synthèse : de "nice-to-have" à composant architectural central
La couche sémantique est en train de passer du statut de "nice-to-have" confiné aux outils de BI à celui de composant architectural central et indispensable de toute plateforme data moderne. L'impulsion donnée par l'IA, qui a besoin de ce contexte pour fonctionner, ne fait qu'accélérer une formalisation qui était nécessaire depuis longtemps.
Pour les data engineers et data architects, la couche sémantique représente une opportunité de transformer la manière dont la logique métier est gérée : de la dispersion dans des centaines de dashboards à la centralisation, le versioning et les tests comme du code. Cette transformation s'accompagne d'outils matures (dbt Semantic Layer) et de standards émergents (OSI) qui facilitent son implémentation.
Limitations actuelles
Cependant, la mise en place d'une couche sémantique efficace n'est pas exempte de défis et de limitations.
Maturité des solutions encore en évolution
Bien que les solutions existantes soient fonctionnelles, elles sont encore en cours de maturation. L'OSI, par exemple, est une initiative récente dont l'impact concret reste à mesurer. Les outils comme dbt Semantic Layer évoluent rapidement, mais peuvent encore présenter des limitations dans certains cas d'usage complexes.
Complexité de mise en œuvre
Développer et maintenir une couche sémantique nécessite des ressources significatives : expertise technique, compréhension métier approfondie, et temps de développement. Pour les petites organisations, cet investissement peut être prohibitif. Même pour les grandes entreprises, la complexité de l'alignement entre équipes techniques et métier représente un défi majeur.
Défis de gouvernance organisationnelle
La technologie ne résout pas tout ; la gouvernance humaine est essentielle. Le rôle du Data Steward, bien qu'émergent, reste mal défini dans de nombreuses organisations. L'articulation entre Data Steward, Product Owner data, et Data Engineer nécessite une clarification qui dépasse le cadre technique. Dans les architectures décentralisées (Data Mesh), la propagation de définitions globales à travers des filiales aux systèmes d'information distincts pose des défis de synchronisation et d'audit complexes.
Dépendance à la qualité des modèles sémantiques
L'efficacité de la couche sémantique dépend fortement de la qualité des modèles sémantiques et de leur capacité à évoluer avec les besoins de l'organisation. Un modèle sémantique mal conçu ou obsolète peut créer plus de confusion qu'il n'en résout, générant des erreurs systémiques difficiles à détecter.
Perspectives d'avenir
Malgré ces limitations, les perspectives d'avenir sont prometteuses.
Adoption croissante de l'OSI
Si l'OSI est adopté par les principaux vendeurs et outils du marché, il pourrait devenir le standard de facto pour les couches sémantiques, résolvant le problème d'interopérabilité qui a longtemps freiné leur adoption. Cette standardisation faciliterait grandement le travail des data engineers, qui pourraient définir une couche sémantique une fois et la consommer partout.
Transformation méthodologique : approche Contract-First
La couche sémantique peut transformer la manière dont nous construisons des produits de données, en passant d'une approche où la documentation est faite après le développement à une approche où la sémantique est définie en amont. Cette démarche s'apparente au Test-Driven Development (TDD) ou au Behavior-Driven Development (BDD) du software engineering.
Avant d'écrire une seule ligne de code de pipeline, le Data Engineer, le Data Steward et le Product Owner définiraient ensemble le "contrat sémantique" : les entités, leurs attributs, les KPIs, les règles de qualité et les exemples de tests. Cette approche Contract-First structure le travail, réduit les allers-retours coûteux avec le métier, et accélère le développement.
Impact de l'IA sur l'accélération du développement
Une couche sémantique bien définie, incluant des tests, devient un prompt parfait pour un LLM qui peut alors générer une grande partie du code du pipeline. Le Data Engineer se concentre alors sur les tâches à plus forte valeur ajoutée comme l'optimisation des performances, la gestion de la scalabilité, et l'architecture globale. Cette synergie entre couche sémantique et IA pourrait révolutionner la productivité des équipes data, tout en garantissant la cohérence et la qualité grâce à la formalisation préalable de la logique métier.
Message final pour les data engineers
En adoptant une approche où la définition sémantique précède le développement, nous ne nous contentons pas de construire des pipelines de données ; nous construisons une intelligence collective, partagée et actionnable. La couche sémantique est un investissement dans la clarté, la confiance et l'agilité, qui transformera non seulement la manière dont les entreprises consomment leurs données, mais aussi la manière dont nous, data engineers, exerçons notre métier.
Les défis restent nombreux : il faut trouver le bon positionnement architectural, clarifier les rôles et responsabilités (notamment celui du Data Steward), et s'aligner sur les standards émergents comme OSI. Mais le plus grand changement est peut-être culturel et méthodologique. En passant d'une logique métier dispersée et implicite à une logique centralisée, versionnée et testée, nous élevons notre pratique au niveau des meilleures pratiques du software engineering.
La couche sémantique n'est pas une solution miracle, mais elle constitue un levier puissant pour les organisations cherchant à tirer pleinement parti de leurs données. Pour les data engineers et data architects, elle représente une opportunité de construire des plateformes data plus robustes, plus maintenables, et plus alignées avec les besoins métier. C'est un défi technique et organisationnel complexe, mais c'est aussi une transformation nécessaire et inévitable dans l'évolution des architectures data modernes.
6. Lexique (glossaire)
Data Mesh
Approche d’architecture data décentralisée : la responsabilité des données est portée par des domaines métier (ownership), les données sont publiées comme des data products, et l’ensemble est coordonné par une gouvernance fédérée et une plateforme self-serve.
Couche sémantique (Semantic Layer)
Couche d’abstraction qui traduit la structure technique (tables/colonnes/jointures) en concepts métier (entités, dimensions, métriques), afin d’assurer une interprétation cohérente entre outils (BI) et consommateurs (humains/LLM).
Metrics layer / couche de métriques
Sous-ensemble de la couche sémantique focalisé sur le calcul standardisé des métriques (règles d’agrégation, filtres, fenêtre temporelle, grain, règles d’exclusion), afin d’éviter la duplication de logique “dashboard-wise”.
KPI (Key Performance Indicator)
Indicateur “pilote” (souvent un petit nombre) qui permet de suivre un objectif métier (ex : croissance, rentabilité, conversion). Un KPI est généralement calculé à partir d’une ou plusieurs métriques, et doit être défini (périmètre, formule, exclusions, fréquence, owner).
Modèle sémantique Power BI (Semantic model / ex-dataset)
Dans l’écosystème Power BI, le modèle sémantique (anciennement “dataset”) joue le rôle de couche sémantique interne à Power BI : il regroupe tables, relations, mesures DAX, hiérarchies, sécurité (RLS), etc. C’est très puissant pour standardiser dans Power BI, mais cela reste “Power BI–centré” si l’entreprise veut partager la même sémantique entre plusieurs outils (BI/IA/SQL).
dbt Semantic Layer
Composant dbt (appuyé sur MetricFlow) permettant de définir des métriques “comme du code” et de les exposer de manière réutilisable (ex : pour BI/consommation applicative), en déplaçant la logique métrique hors des outils de visualisation.
MetricFlow
Moteur (utilisé par dbt Semantic Layer) qui gère la définition et la requêtabilité des métriques (jointures, grains, règles d’agrégation, etc.).
Semantic Views (Snowflake)
Objets Snowflake destinés à capturer un “modèle sémantique” et à le rendre exploitable (notamment dans des cas d’usage d’analytique/IA), pour rapprocher la description métier de la couche d’exécution.
OSI (Open Semantic Interchange)
Spécification/initiative visant à standardiser un format d’échange de couche sémantique pour permettre l’interopérabilité entre outils (BI, IA, plateformes data). À ne pas confondre avec le “modèle OSI” des réseaux.
Data product
Produit de données “consommable” (datasets + contrats + documentation + SLA + ownership) publié par un domaine, avec une logique de produit plutôt que de simple extraction technique (concept central en Data Mesh).
Data contract (contrat de données)
Contrat explicite entre producteurs/consommateurs décrivant schéma, qualité, sémantique, SLA, règles de compatibilité et de versioning. Dans une approche contract-first, il peut inclure des éléments de couche sémantique (définitions, exemples, tests).
7. Références
Définitions (concepts)
- Data Mesh : Thoughtworks Technology Radar — Data mesh
- OSI (Open Semantic Interchange) : Open Semantic Interchange (OSI)
- Data contracts :
Outils / documentation
- dbt Semantic Layer : dbt — dbt Semantic Layer
- Power BI :
- Snowflake : Snowflake Docs — SHOW SEMANTIC VIEWS
- OSI (annonce) : Snowflake — Open Semantic Interchange initiative (announcement)
- Data contracts (outil) : Data Contract CLI (GitHub)


