

L'intégration continue et le déploiement continu (CI/CD) sont devenus des pratiques incontournables. Au cœur de ces pipelines se trouve un composant essentiel mais souvent mal compris : le GitLab Runner. Cet agent d'exécution est le moteur qui transforme vos fichiers .gitlab-ci.yml en actions concrètes.
Dans cet article, nous allons explorer en profondeur les différents types d'executors de GitLab Runner.
L’objectif n’est pas uniquement de lister ces executors, mais de comprendre leurs implications concrètes : architecture, sécurité, coûts, scalabilité et contraintes opérationnelles. Car derrière un simple choix d’executor se cachent souvent des décisions structurantes pour votre plateforme CI/CD.
Avant de comparer les executors entre eux, il est indispensable de comprendre comment fonctionne réellement un GitLab Runner. Sans cette base, il est difficile de mesurer les impacts réels de chaque choix, notamment en matière de sécurité et d’architecture réseau.
Les fondamentaux des GitLab Runners
Qu'est-ce qu'un GitLab Runner ?
Un GitLab Runner est un agent logiciel qui exécute les jobs définis dans vos pipelines CI/CD. Contrairement à ce que l'on pourrait penser intuitivement, c'est le Runner qui contacte GitLab (via son API), et non l'inverse. Cette architecture en "pull" présente plusieurs avantages en termes de sécurité et de flexibilité réseau.
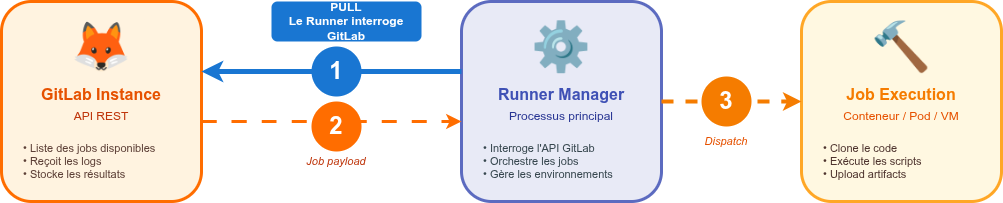
Quelle est l’architecture d’un GitLab Runner et comment s’exécutent les jobs ?
Avant de plonger dans les spécificités de chaque executor, il est crucial de comprendre la distinction entre deux concepts fondamentaux :
Le Runner Manager : C'est le processus principal qui tourne en permanence sur votre infrastructure. Il est responsable de :
- Interroger régulièrement l'API GitLab pour récupérer les nouveaux jobs
- Gérer le cycle de vie des environnements d'exécution
- Communiquer les résultats à GitLab
En d’autres termes, le Runner Manager joue le rôle de chef d’orchestre : il coordonne l’exécution des jobs sans jamais exécuter directement le code métier.
L'environnement d'exécution : C'est là où votre job s'exécute réellement. Selon l'executor choisi, il peut s'agir d'un conteneur Docker, d'un pod Kubernetes, d'une machine virtuelle, etc.
Les flux réseau
Un point souvent négligé mais capital pour la sécurité et l'architecture réseau : la distinction entre les flux de gestion du Runner Manager et les flux de données du Runner Helper.
Flux du Runner Manager (gestion des jobs)
Le Runner Manager communique avec l'API GitLab pour :
- Récupérer les jobs disponibles avec le runner token
- Envoyer les logs et le statut d'exécution en temps réel
- Transmettre le job payload (métadonnées du job) aux environnements d'exécution
Flux du Runner Helper (données du job)
C'est le Runner Helper, déployé dans chaque environnement d'exécution, qui communique directement avec GitLab pour :
- Cloner le code source du repository
- Télécharger les artifacts et le cache
- Uploader les artifacts générés et le cache mis à jour
Le Runner Helper utilise le job token (fourni dans le job payload) pour ces opérations, et non le runner token.
Implications pour l'architecture réseau
Cette architecture a des conséquences importantes :
✅ Ce que vous gagnez :
- Sécurité du Runner Manager : Un seul point d'accès vers l'API GitLab pour la gestion des runners
- Contrôle centralisé : Tous les jobs passent par le Runner Manager qui orchestre l'exécution
- Simplicité de configuration : Le Runner Manager est le seul composant à enregistrer avec un runner token
⚠️ Ce que vous devez prévoir :
- Accès réseau pour les environnements d'exécution : Chaque conteneur/pod/VM doit pouvoir accéder à GitLab pour télécharger le code et les artifacts
- Configuration du pare-feu : Les environnements d'exécution ont besoin d'une connexion sortante vers GitLab (généralement HTTPS/443)
- Isolation réseau limitée : Vous ne pouvez pas placer vos environnements d'exécution dans un réseau totalement isolé sans accès à GitLab
Au-delà de l'accès à GitLab, votre code applicatif peut nécessiter un accès réseau pour :
- Cloner des dépendances depuis npm/PyPI/Maven/Docker Hub
- Accéder à des APIs externes
- Se connecter à des bases de données ou services cloud
Dans ce cas, c'est votre responsabilité de configurer l'accès réseau approprié pour les environnements d'exécution.
Quelles configurations sont communes à tous les executors GitLab Runner ?
Quelle que soit le type d'executor choisi, certaines configurations sont universelles
concurrent : Définit le nombre de jobs pouvant s'exécuter simultanément sur ce Runner. Cette valeur doit être ajustée en fonction de vos ressources disponibles.
check_interval : Fréquence (en secondes) à laquelle le Runner interroge GitLab pour récupérer de nouveaux jobs. Une valeur plus basse réduit la latence mais augmente la charge sur l'API GitLab.À noter : GitLab Runner supporte également le long polling.Lorsque cette fonctionnalité est activée, le Runner maintient une requête ouverte vers GitLab et reçoit les jobs dès qu’ils sont disponibles, réduisant fortement la latence tout en limitant le nombre d’appels à l’API. Dans ce cas, le paramètre check_interval a peu d’impact, car le Runner n’interroge plus GitLab de manière active.
[runners.cache] : Configuration du cache pour accélérer vos builds. Le cache est géré et stocké au niveau du Runner Manager. Il peut être stocké localement sur le serveur du Runner ou sur un object storage distant (S3, GCS, Azure Blob, Ceph). Le Runner Manager se charge de distribuer le cache aux environnements d'exécution au début du job et de le récupérer à la fin.
Cache vs Artifacts : Ne confondez pas le cache et les artifacts :
- Cache : Géré par le Runner Manager, sert à accélérer les builds (dépendances, node_modules, etc.). Configuration dans le config.toml du Runner.
- Artifacts : Gérés par l'instance GitLab elle-même (stockage côté serveur GitLab). Ce sont des fichiers produits par vos jobs et conservés pour être utilisés par d'autres jobs ou téléchargés. Configuration dans .gitlab-ci.yml.
Comprendre l’architecture globale ne suffit toutefois pas à expliquer comment un job est exécuté concrètement. Pour cela, il faut s’intéresser à un composant souvent invisible, mais absolument central : le Runner Helper.
Quel est le rôle du Runner Helper dans l’exécution des jobs GitLab ?
Avant de plonger dans les différents executors, il est important de comprendre le rôle du Runner Helper, un composant souvent invisible mais crucial dans l'exécution de vos jobs.
Qu'est-ce que le Runner Helper ?
Le Runner Helper est un petit binaire Go injecté par le Runner Manager dans chaque environnement d'exécution. Il agit comme un agent local qui gère toutes les opérations de bas niveau nécessaires au bon déroulement du job.
Ses responsabilités principales :
- Clonage du repository Git : Le Helper clone votre code source au bon commit
- Gestion des artifacts :
- Téléchargement des artifacts des jobs précédents (dépendances entre stages)
- Upload des artifacts générés vers GitLab à la fin du job
- Gestion du cache :
- Téléchargement du cache depuis l’url passée par le Runner Manager
- Upload du cache mis à jour
- Préparation de l'environnement : Variables d'environnement, fichiers de configuration
- Collecte des logs : Capture de la sortie standard et d'erreur pour l'envoyer à GitLab
- Gestion du cycle de vie : Nettoyage après l'exécution du job
Architecture avec le Helper :
Selon l'executor :
- Docker : Le Helper tourne dans un conteneur dédié qui monte les volumes nécessaires
- Kubernetes : Le Helper est le container principal du pod, le(s) build container(s) sont des containers additionnels
- Docker Autoscaler : Le Helper tourne dans le conteneur sur la VM provisionnée
En résumé, le Runner Helper est l’exécutant local du job. Il fait le lien entre les intentions décrites dans le `.gitlab-ci.yml` et leur exécution réelle dans l’environnement choisi.
Maintenant que nous savons comment un job est exécuté techniquement, intéressons-nous aux environnements dans lesquels il peut s’exécuter. Commençons par l’executor le plus répandu : Docker.
Comment fonctionne l’executor Docker de GitLab Runner et quand l’utiliser ?
Fonctionnement
L'executor Docker est probablement le plus populaire des executors GitLab. Son principe est simple : pour chaque job, le Runner Manager crée un nouveau conteneur Docker basé sur l'image spécifiée dans votre .gitlab-ci.yml.
Architecture
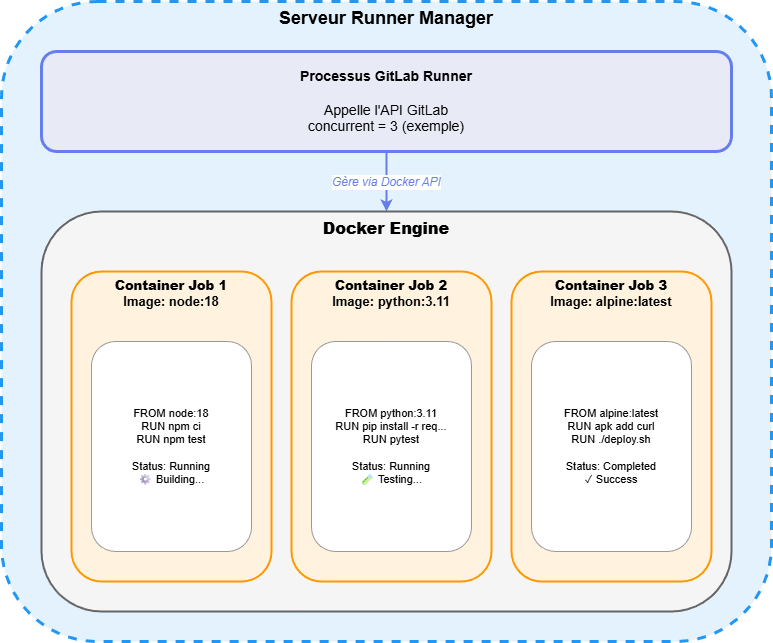
Installation rapide
L'installation de l'executor Docker est particulièrement simple :
# Installation du Runner
curl -L "https://packages.gitlab.com/install/repositories/runner/gitlab-runner/script.deb.sh" | sudo bash
sudo apt-get install gitlab-runner
# Enregistrement avec l'executor Docker
sudo gitlab-runner register \
--url "https://gitlab.com/" \
--registration-token "YOUR_TOKEN" \
--executor "docker" \
--docker-image "alpine:latest" \
--description "docker-runner"
C’est généralement avec l’executor Docker que surgissent les premières questions sérieuses de sécurité, notamment lorsque les pipelines commencent à construire des images ou à manipuler le système hôte.
Services privilégiés : un équilibre entre puissance et sécurité
L'une des décisions les plus importantes lors de la configuration d'un Runner Docker concerne l'utilisation du mode privilégié.
Mode privilégié activé (services_privileged = true)
Avantages :
- Permet de construire des images Docker dans vos jobs (Docker-in-Docker)
- Accès complet aux fonctionnalités du système
- Nécessaire pour certains outils de virtualisation
Risques :
- Les conteneurs peuvent potentiellement s'échapper de leur isolation
- Accès complet au système hôte en cas de compromission
- Peut permettre l'escalade de privilèges
Mode privilégié désactivé (recommandé)
Pour la plupart des cas d'usage, il est préférable de désactiver le mode privilégié. Si vous devez absolument l'utiliser, vous pouvez limiter les risques en activant une allowlist des services autorisés via allowed_privileged_services.
Configurations spécifiques importantes
Volumes et cache
[[runners]]
[runners.docker]
volumes = ["/cache"]
disable_cache = false
Pull policy
[[runners]]
[runners.docker]
pull_policy = ["if-not-present", "always"]
Contrôle quand Docker télécharge les images. if-not-present économise de la bande passante, always garantit les dernières versions.
MTU (Maximum Transmission Unit)
Si vous rencontrez des problèmes de connexion réseau dans vos conteneurs, le MTU peut être en cause.
Le MTU définit la taille maximale d'un paquet réseau. Par défaut, Docker utilise un MTU de 1500 octets, mais votre infrastructure réseau sous-jacente peut avoir un MTU plus faible (par exemple 1450 en cas de tunneling VPN/VXlan/IPSEC qui ajoute des en-têtes supplémentaires).
Le problème : Si le MTU du conteneur (1500) est supérieur au MTU de la VM ou du réseau physique (1450), les paquets trop gros seront fragmentés ou rejetés, provoquant des erreurs réseau difficiles à diagnostiquer.
Il est donc possible de le configurer pour le runner GitLab :
[[runners]]
[runners.docker]
mtu = 1450 # Ajustez selon votre infrastructure réseau
Lorsque les besoins en scalabilité augmentent ou que l’infrastructure est déjà basée sur Kubernetes, l’executor Docker montre rapidement ses limites. C’est là qu’intervient l’executor Kubernetes.
Comment fonctionne l’executor Kubernetes de GitLab Runner et quels sont ses avantages ?
L’executor Kubernetes apporte une scalabilité native et une isolation robuste, mais impose également un cadre de sécurité plus strict que Docker classique. Ces contraintes influencent directement certains usages courants de GitLab CI.
Fonctionnement
L'executor Kubernetes apporte l'élasticité et la scalabilité native du cloud à vos pipelines CI/CD. Plutôt que de gérer des conteneurs directement, le Runner crée des pods Kubernetes éphémères pour chaque job.
Architecture
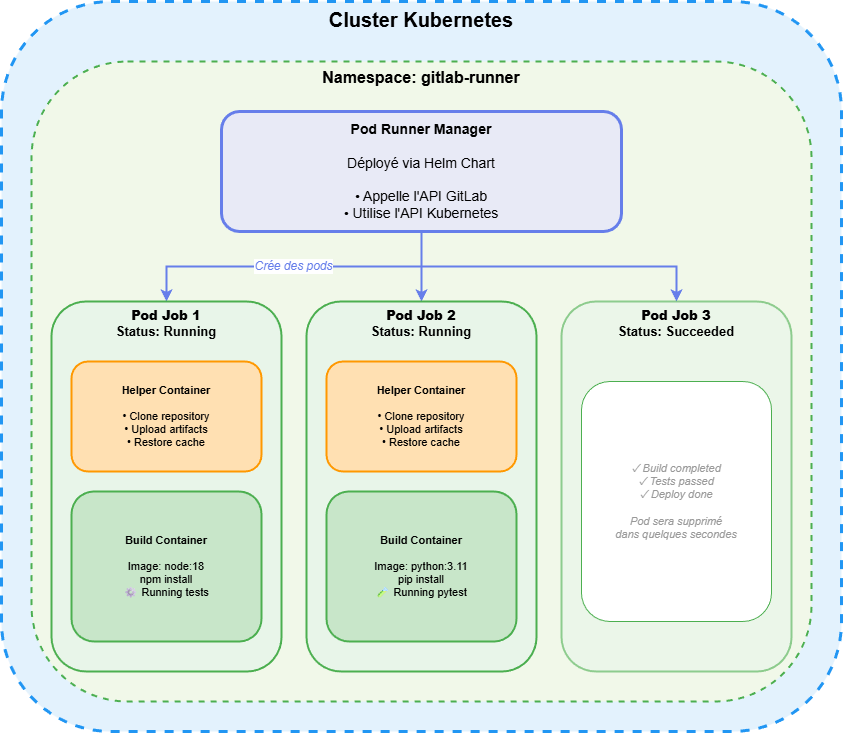
Installation via Helm
L'installation d'un Runner Kubernetes se fait idéalement via le Helm chart officiel :
# Ajouter le repository Helm
helm repo add gitlab https://charts.gitlab.io
helm repo update
# Créer un fichier values.yaml
cat > values.yaml <<EOF
gitlabUrl: https://gitlab.com/
runnerRegistrationToken: "YOUR_TOKEN"
rbac:
create: true
runners:
config: |
[[runners]]
[runners.kubernetes]
namespace = "gitlab-runner"
image = "alpine:latest"
cpu_request = "100m"
memory_request = "128Mi"
cpu_limit = "1"
memory_limit = "1Gi"
EOF
# Installer le Runner
helm install gitlab-runner gitlab/gitlab-runner -f values.yaml
Avantages de l'executor Kubernetes
Scalabilité automatique : Kubernetes gère automatiquement la création et la destruction des pods selon la charge. Pas besoin de provisionner des machines à l'avance.
Isolation robuste : Chaque job tourne dans son propre pod, offrant une isolation réseau et de ressources native à Kubernetes.
Gestion des ressources : Avec les requests et limits, vous pouvez garantir des ressources minimales et éviter qu'un job monopolise tout le cluster.
Inconvénients et limitations
Complexité de déploiement : Nécessite un cluster Kubernetes opérationnel et une compréhension des concepts K8s.
Gestion du cache d'images : Comme avec tous les executors éphémères, les jobs sont plus lents car ils doivent toujours télécharger/uploader le contenu du cache sur le réseau, ce qui est plus lent qu'utiliser un disque local GitLab. Pour optimiser les performances, structurez votre Dockerfile pour mettre les parties qui changent fréquemment vers la fin du fichier et utilisez des images de base plus petites GitLab. Considérez également la mise en place d'un registry mirror local.
Non recommandé pour le build Docker en mode privilégié : C'est une limitation importante à connaître. Techniquement, il est possible de construire des images Docker via Docker-in-Docker (DinD) en mode privilégié avec l'executor Kubernetes, mais ce n'est pas du tout recommandé. Voici pourquoi :
- Risque de sécurité majeur : Lorsque le mode privilégié est activé, un utilisateur exécutant un job CI/CD pourrait obtenir un accès root complet au système hôte du runner, avec la permission de monter et démonter des volumes. Dans un cluster Kubernetes, cela signifie qu'un job malveillant pourrait compromettre l'ensemble du cluster.
- Politiques de sécurité Kubernetes : Les Pod Security Standards (PSS), qui ont remplacé les PodSecurityPolicy depuis Kubernetes 1.25, peuvent être appliqués au niveau du namespace via des labels. Par exemple :
apiVersion: v1
kind: Namespace
metadata:
name: gitlab-runners
labels:
pod-security.kubernetes.io/enforce: baseline # ou restricted
Ces labels déterminent le niveau de politique de sécurité appliqué (privileged, baseline, ou restricted). Les niveaux baseline et restricted bloquent généralement les conteneurs privilégiés, ce qui empêche DinD de fonctionner sans modification de la configuration du namespace.
Alternatives recommandées pour le build d'images : Si vous devez construire des images Docker dans Kubernetes, utilisez plutôt des alternatives comme Buildah qui ne nécessitent pas de privilèges.
Debugging plus complexe : Les logs sont distribués entre plusieurs composants Kubernetes (pods, events, logs du kubelet) et peuvent être plus difficiles à consulter qu'avec un simple conteneur Docker.
Spécificités importantes
L'entrypoint n'est pas respecté par défaut
C'est un piège fréquent : contrairement à l'executor Docker, Kubernetes ignore l'ENTRYPOINT et le CMD de vos images par défaut. Le Runner injecte ses propres commandes.
Solution : Si vous avez besoin de l'entrypoint, utilisez un script d'initialisation dans votre job ou créez une image spécifique pour GitLab CI.
Gestion des volumes
runners:
config: |
[[runners]]
[runners.kubernetes]
[runners.kubernetes.volumes]
[[runners.kubernetes.volumes.empty_dir]]
name = "docker-certs"
mount_path = "/certs/client"
medium = "Memory"
Node Selectors et Affinity
Pour diriger vos jobs vers des nœuds spécifiques :
[runners.kubernetes]
[runners.kubernetes.node_selector]
"workload-type" = "ci-cd"
[runners.kubernetes.node_tolerations]
"ci-cd=true:NoSchedule" = ""
Bonnes pratiques
- Utilisez des noeuds et namespaces dédiés pour isoler les runners du reste de vos workloads
- Configurez des resource quotas pour éviter qu'un pipeline runaway consomme tout le cluster
- Configurez les pod security policies pour limiter les privilèges des jobs
- Implémentez une politique de garbage collection pour nettoyer les pods en erreur
- Utilisez un registry cache (comme Harbor) pour accélérer le pull des images
Entre la simplicité de Docker et la complexité Kubernetes, certaines équipes recherchent un compromis : une forte isolation, une scalabilité dynamique, sans adopter Kubernetes. C’est précisément ce que proposent Docker Machine, puis Docker Autoscaler.
Quelle est la différence entre Docker Machine et Docker Autoscaler dans GitLab Runner ?
Docker Machine : l'ancienne génération
Docker Machine était l'executor historique pour la mise à l'échelle automatique des Runners. Il permettait de créer des machines virtuelles à la demande sur divers cloud providers (AWS, GCP, Azure, etc.) pour exécuter les jobs.
Le Runner Manager utilise l'outil docker-machine pour provisionner des VMs, installer Docker dessus, puis exécuter les jobs dans des conteneurs sur ces machines.
Depuis la version 14.0 de GitLab Runner, Docker Machine est officiellement déprécié. GitLab recommande de migrer vers Docker Autoscaler, son successeur moderne.
Docker Autoscaler : la nouvelle génération
Docker Autoscaler est le remplaçant de Docker Machine, conçu pour être plus performant, plus flexible et mieux maintenu.
Architecture de Docker Autoscaler

Installation de Docker Autoscaler
L'installation nécessite le plugin Fleeting correspondant à votre cloud provider :
# Installation du Runner
sudo apt-get install gitlab-runner
# Installation du plugin Fleeting (exemple AWS)
sudo gitlab-runner fleeting install
# Configuration
cat > /etc/gitlab-runner/config.toml <<EOF
concurrent = 10
check_interval = 0
[[runners]]
name = "autoscaler-runner"
url = "https://gitlab.com/"
token = "YOUR_TOKEN"
executor = "docker-autoscaler"
[runners.docker]
image = "alpine:latest"
[runners.autoscaler]
plugin = "fleeting-plugin-aws"
capacity_per_instance = 1
max_use_count = 100
max_instances = 10
[runners.autoscaler.plugin_config]
name = "ci-runner"
region = "eu-west-1"
instance_type = "t3.medium"
ami = "ami-0c55b159cbfafe1f0"
security_group = "sg-xxxxx"
subnet_id = "subnet-xxxxx"
[runners.autoscaler.connector_config]
username = "ubuntu"
key_path = "/path/to/private-key.pem"
EOF
Avantages de Docker Autoscaler
Scalabilité dynamique : Créez automatiquement des instances uniquement quand nécessaire, et détruisez-les quand elles ne sont plus utilisées.
Isolation complète : Chaque instance est éphémère et détruite après utilisation, garantissant une isolation maximale entre les jobs. Vous pouvez même configurer max_use_count = 1 pour forcer la destruction de l'instance après un seul job, ou utiliser capacity_per_instance > 1 pour mutualiser plusieurs jobs sur une même instance si vous privilégiez l'efficacité au coût de l'isolation.
Performance : Meilleure gestion des pools d'instances que Docker Machine, avec des temps de provisioning réduits.
Inconvénients
Complexité de configuration : Nécessite une bonne compréhension de votre cloud provider et de ses APIs.
Temps de démarrage : Le provisioning d'une nouvelle VM prend généralement 30 secondes à 2 minutes.
Coûts potentiels : Les APIs cloud et les snapshots peuvent générer des coûts additionnels.
Debugging : Les logs sont sur des instances éphémères, pensez à les centraliser (CloudWatch, Stackdriver, etc.).
Dans quels cas utiliser Docker Autoscaler dans vos pipelines GitLab ?
Builds nécessitant des ressources spécifiques
Certains jobs nécessitent des instances GPU pour le machine learning, ou des instances avec beaucoup de RAM pour les compilations. Docker Autoscaler permet de provisionner des types d'instances différents selon les jobs.
[[runners]]
[runners.autoscaler.plugin_config]
instance_type = "p3.2xlarge" # Instance GPU
[runners.tags]
tags = ["gpu", "ml"]
[[runners]]
[runners.autoscaler.plugin_config]
instance_type = "c5.4xlarge" # Instance CPU optimisée
[runners.tags]
tags = ["compile", "cpu"]
Environnements de test isolés
Pour des tests de sécurité ou d'intégration nécessitant une isolation maximale, créer une VM éphémère par job garantit l'absence de contamination entre les exécutions.
Build Docker avec DinD privilégié et forte isolation
C'est l'un des cas d'usage les plus pertinents pour Docker Autoscaler. Si vous gérez des runners de groupe ou d'instance GitLab (accessibles par de nombreuses équipes), et que vous devez autoriser le build Docker avec Docker-in-Docker en mode privilégié, vous faites face à un dilemme de sécurité :
- Problème : Avec Docker Executor classique, un conteneur privilégié peut potentiellement s'échapper et compromettre le serveur hôte, impactant tous les autres jobs
- Solution Docker Autoscaler : Chaque job tourne dans sa propre VM éphémère, détruite après usage. Même si un job malveillant compromet sa VM, il ne peut pas impacter les autres jobs. La VM est détruite et le problème disparaît.
Configuration recommandée pour ce cas :
[[runners]]
name = "autoscaler-docker-build"
executor = "docker-autoscaler"
[runners.docker]
image = "docker:24-dind"
services_privileged = true # Autorisé car isolé dans une VM
[runners.autoscaler]
max_use_count = 1 # Une VM = un seul job pour isolation maximale
capacity_per_instance = 1 # Pas de jobs en parallèle sur la même VM
max_instances = 50
Ce pattern est particulièrement recommandé pour les équipes Platform/DevOps qui gèrent des runners mutualisés entre plusieurs projets ou équipes.
Bonnes pratiques
- Utilisez des AMIs pré-configurées avec Docker déjà installé pour réduire le temps de provisioning
- Configurez le max_use_count pour recycler les instances régulièrement et éviter l'accumulation de problèmes
- Implémentez un monitoring des coûts cloud pour éviter les surprises
- Utilisez des spot instances quand possible pour réduire les coûts de 60-90%
[runners.autoscaler.plugin_config]
use_spot_instances = true
spot_price_max = "0.10"
- Configurez des idle instances pour réduire la latence des premiers jobs
[runners.autoscaler]
idle_count = 2
idle_time = "20m"
- Centralisez vos logs avant la destruction des instances
- Utilisez des tags GitLab pour router les jobs vers le bon type d'instance
Pour obtenir davantage de précisions sur cet executor et son déploiement, nous vous encourageons à consulter notre article de blog intitulé : Mettez à l'échelle vos runners GitLab de manière simple et sécurisée avec docker-autoscaler.
Quel executor GitLab Runner choisir selon votre cas d’usage ?
Après avoir exploré les différents executors de GitLab Runner, il est temps de faire un récapitulatif pour vous aider à choisir la solution la plus adaptée à votre contexte car il n’existe pas de “meilleur executor” universel. Il existe uniquement des executors plus ou moins alignés avec vos contraintes réelles : sécurité, coûts, variabilité de charge et compétences internes.
Docker Executor : le choix polyvalent
Choisissez Docker si :
- Vous débutez avec GitLab CI/CD
- Vous avez une infrastructure relativement stable avec une charge prévisible
- Vous voulez une solution simple et rapide à mettre en place
- Votre charge de travail justifie quelques serveurs dédiés
- Vous avez besoin de construire des images Docker et acceptez le risque du mode privilégié (runners dédiés à une équipe)
Évitez Docker si :
- Vous avez des pics de charge importants et imprévisibles
- Vous cherchez une scalabilité automatique
- Vous gérez des runners mutualisés avec besoin de DinD privilégié (préférez Autoscaler)
Kubernetes Executor : la scalabilité cloud-native
Choisissez Kubernetes si :
- Vous avez déjà un cluster Kubernetes opérationnel
- Vous recherchez une scalabilité automatique et élastique
- Vous gérez beaucoup de jobs concurrents
- Vous êtes à l'aise avec l'écosystème Kubernetes
- Vos builds n'utilisent pas Docker-in-Docker privilégié
Évitez Kubernetes si :
- Vous n'avez pas d'expertise Kubernetes dans l'équipe
- Vous cherchez une solution simple pour débuter
- Vous n'avez pas de cluster Kubernetes
- Vous devez absolument utiliser DinD en mode privilégié pour vos builds
Docker Autoscaler : la puissance du cloud
Choisissez Docker Autoscaler si :
- Vous avez des charges de travail très variables
- Vous avez besoin d'isolation maximale entre les jobs
- Vous devez gérer différents types de workloads (GPU, CPU intensif, etc.)
- Vous êtes prêt à investir du temps dans la configuration
- Vous gérez des runners mutualisés (groupe/instance) avec besoin de DinD privilégié - c'est le cas d'usage idéal
Évitez Docker Autoscaler si :
- Vos jobs sont très courts et fréquents (le provisioning sera un goulot)
- Vous n'avez pas de budget cloud
- Vous préférez la simplicité à l'optimisation
- Vous n'avez pas d'expertise sur votre cloud provider
Pour aller plus loin
Les GitLab Runners sont un sujet vaste et en constante évolution. La documentation officielle reste votre meilleure alliée pour approfondir les configurations spécifiques à votre environnement. N'hésitez pas à expérimenter avec les différents executors dans un environnement de test avant de les déployer en production.
L'écosystème CI/CD continue d'évoluer rapidement, et GitLab apporte régulièrement de nouvelles fonctionnalités à ses Runners. Restez à l'écoute des release notes pour découvrir les dernières améliorations et optimiser continuellement vos pipelines.
Quelle que soit l'option que vous choisirez, gardez en tête que le meilleur executor est celui qui répond le mieux à vos besoins spécifiques, pas nécessairement le plus complexe ou le plus récent. Commencez simple, mesurez, puis optimisez selon vos véritables contraintes.
