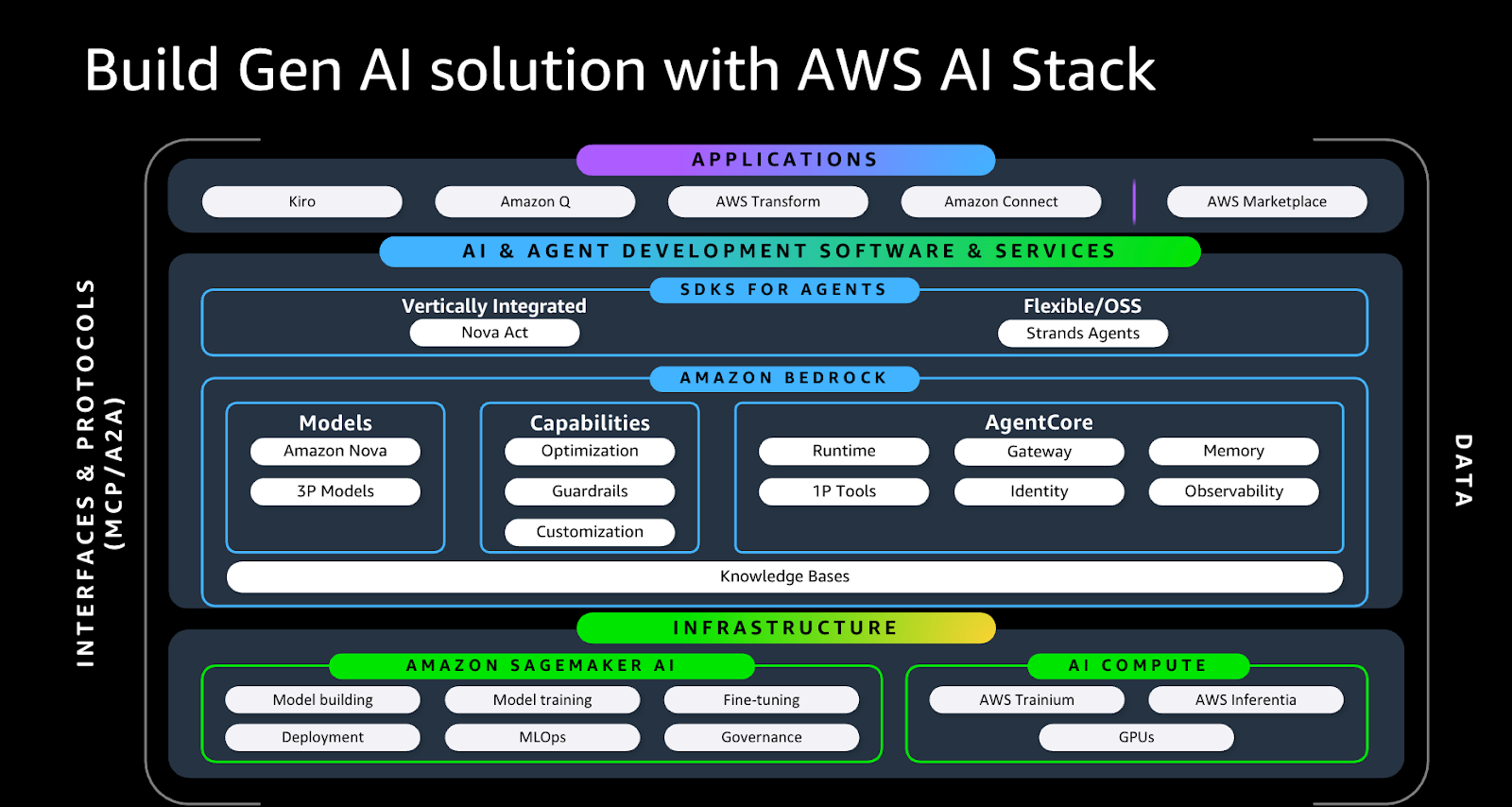
Le salon AWS re:Invent 2025 a été placé, comme on pouvait s’y attendre, sous le signe de l’IA générative. La plupart des annonces qui y ont été faites étaient liées, de près ou de loin, à l’IA. Sujet majeur de l’année 2025 dans ce domaine, les agents IA ont été très présents lors des différentes conférences qui se sont déroulées tout au long de la semaine.
Cette omniprésence nous laisse entrevoir les convictions d’AWS dans ce domaine et la manière dont l’entreprise organise ses services pour favoriser l’agentification des systèmes d’IA afin d’en accélérer l’adoption globale.
Cet article vous propose un panorama des services cloud AWS permettant de concevoir un agent IA de bout en bout. Nous explorerons ensemble, étape par étape, le cycle complet de développement et de déploiement d’un agent IA en utilisant l’écosystème AWS, à la suite des dernières annonces.
Rappel sur la notion d’agent
Avant de commencer, un petit rappel sur la notion d’agent IA telle qu’elle est entendue dans cet article. Cela nous permettra également de mettre en évidence les difficultés liées au développement de ce type de système et de mieux comprendre ensuite aux quels problèmes la stack AWS apporte des réponses.
Un agent est un modèle de langage que l’on utilise d’une certaine manière afin de lui fournir la capacité d’appeler des fonctions et de produire des réponses en fonction des résultats de ces appels. De manière triviale, un agent est un LLM (Large Language Model) doté d’une capacité d’action sur son environnement.
Un agent moderne est composé de trois éléments : un LLM, une boucle d’appel et des outils qu’il peut choisir d’invoquer.
Jusqu’à récemment, AWS proposait principalement les services Bedrock et SageMaker AI. SageMaker est la plateforme de machine learning d’AWS couvrant l’ensemble du cycle de vie des modèles. Elle fournit des services de transformation et de préparation des données, des environnements de développement et d’expérimentation basés sur JupyterLab, ainsi que des capacités d’entraînement à la demande. SageMaker permet également de stocker et de versionner les artefacts issus de l’entraînement, puis de les exposer via différents types d’endpoints. Au-delà du développement, la plateforme intègre une couche complète de déploiement et de MLOps, incluant la gestion des pipelines, le monitoring des modèles et des données, les stratégies de déploiement progressif (blue/green, canary), l’auto-scaling et l’adaptation des endpoints selon les contraintes de performance, de coût et de latence.
Bedrock permet de gérer la partie communication avec les LLM. Il présente l’avantage de fournir un accès aux modèles closed source les plus performants de plusieurs acteurs majeurs de l’IA (Anthropic, Mistral et AWS Nova, entre autres), ainsi qu’à des modèles open source proposés par de grands acteurs comme Google (Gemma) et GPT OSS, sans oublier les modèles open source disponibles sur Hugging Face via des endpoints SageMaker, le tout à travers une API unique. Il n’est donc pas nécessaire de développer des connecteurs spécifiques pour chaque fournisseur, ni de gérer séparément les permissions d’accès à chaque modèle.
Finalement, le problème consistant à fournir des outils à l’agent a été grandement résolu par le fameux protocole MCP, développé en open source par Anthropic. Ce protocole fournit une spécification pour les fournisseurs d’outils, permettant à n’importe quel modèle d’agent de les découvrir et de les utiliser sans nécessiter d’autre développement que la connexion aux « serveurs » hébergeant ces outils.
Développement d’un pilote : Strands Agents
La première phase du développement d’un agent est le prototypage. On inclut là-dedans tout ce qui va de l’expérimentation au POC. Pour couvrir cette phase, AWS propose un SDK (Software Development Kit) appelé Strands Agents. Ce SDK peut, par exemple, être utilisé dans un notebook SageMaker AI afin d’expérimenter rapidement.
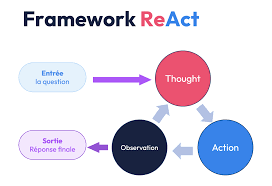
Ce SDK propose de nombreuses fonctions built-in pour accélérer les tâches relativement communes et les fonctionnalités récurrentes. Par exemple, la boucle agentique ReAct est fournie sous forme de classe et peut être appelée en une seule ligne de code. De même, les outils les plus couramment utilisés dans les agents sont disponibles « sur étagère » et permettent, sous le capot, d’utiliser des serveurs MCP locaux préconfigurés. Cela inclut, par exemple, l’outil de recherche internet ou l’outil de calcul, fondamental pour dépasser les limites des LLM en matière de calcul.
En complément, le SDK propose des fonctionnalités plus avancées pour la gestion de la mémoire à court et à long terme. Ces deux espaces de stockage permettent à l’agent de se repérer respectivement au sein d’un seul appel et entre plusieurs appels, afin de s’améliorer en continu. Une autre fonctionnalité intéressante est la gestion du multi-agent. L’un des problèmes des agents est la dégradation des performances à mesure que l’on ajoute des outils. Strands Agents propose des aides à la création de flottes d’agents spécialisés, en suivant des patterns avec un agent orchestrateur ou des flottes d’agents.
Enfin, la librairie permet également des comportements beaucoup plus avancés. Lors d’une session, un snippet de code a été présenté, permettant de laisser un agent créer ses propres outils et agents subalternes afin d’atteindre son objectif. Il a également été montré comment permettre à l’agent de mettre à jour son system prompt entre chaque itération de la boucle agentique.
Évaluer les performances rigoureusement : Managed MLflow
Nous avons développé un pilote convaincant ; il faut maintenant rendre l’approche plus rigoureuse afin de ne pas expérimenter à l’aveugle lors des évolutions futures. Pour cela, une solution présentée par AWS consiste à utiliser leur service managé MLflow. Il s’agit d’une plateforme permettant de tracer les différentes expérimentations selon les paramètres utilisés (modèle choisi, prompt utilisé, paramètres d’appel, ensemble d’outils à disposition, etc.).
Il est à noter que la version managée par AWS intègre des facilités spécifiques à la GenAI. Dans un tel contexte, il est relativement complexe de définir des métriques efficaces, mais tout ce qui peut servir de baseline est bon à prendre. Pour l’agentic AI, les métriques de performance peuvent porter sur l’exactitude des réponses, en utilisant des approches de type LLM as a Judge, des métriques classiques de NLP comme ROUGE, ou encore des vérifications de contenus précis dans les réponses. Il est également possible de définir un ensemble d’exemples avec des appels d’outils attendus afin d’évaluer la capacité du LLM à comprendre correctement les outils mis à sa disposition et à planifier leur utilisation de manière efficace.
L’ensemble de ces éléments permettra de disposer d’une baseline de performance lorsque l’on ajoutera des outils à l’agent, que l’on fera évoluer la mémoire long terme ou que l’on changera simplement de modèle sous-jacent.
Optimiser le modèle sous-jacent : Nova Forge
Une étape que l’on a tendance à aborder en dernier est l’optimisation du modèle servant de base à l’agent.
Durant la phase expérimentale, on se focalise principalement sur la qualité des réponses de l’agent, ce qui est logique puisque l’objectif est d’abord de prouver la faisabilité du cas d’usage.
Il existe toutefois d’autres axes d’optimisation fondamentaux pour la mise en production, en particulier pour des systèmes massivement utilisés. Deux de ces axes sont l’optimisation des coûts, pour des considérations de ROI, et l’optimisation de la latence, pour des enjeux d’expérience utilisateur.
Dans ce cadre, on se retrouve confronté à un compromis entre les modèles « frontière » les plus avancés (plus d’un trillion de paramètres pour GPT-5) et des modèles plus petits.
Une partie de l’optimisation de la latence peut provenir de l’infrastructure, mais dans le cadre d’AWS, la majorité de la charge s’exécute sur des puces Trainium ; il n’y a donc pas réellement d’optimisation à aller chercher de ce côté-là entre les modèles.
En revanche, AWS propose un tout nouveau service, Nova Forge, qui permet de se brancher sur les modèles Nova à différentes étapes de l’entraînement et de rejouer la fin de celui-ci (pré-entraînement, mid-training, alignement par reinforcement learning, fine-tuning ou PEFT) sur ses propres données. L’objectif est d’obtenir des modèles plus petits, mais spécialisés sur les tâches à résoudre, afin d’optimiser le compromis entre coût d’inférence, latence et performance. De plus, un modèle fine-tuné de cette manière encapsule dans ses paramètres une connaissance métier spécifique, permettant de réduire la taille des prompts et d’optimiser encore davantage les coûts et la latence. Cette fonctionnalité est disponible dans SageMaker AI.
NB : Cette phase d’optimisation n’est pas obligatoire, et le coût en calcul et en temps d’ingénierie nécessaire à l’entraînement doit être compensé par les économies réalisées sur les coûts d’inférence.
Déployer en production : Agent Core
Nous disposons désormais d’un agent performant et optimisé pour répondre à son cas d’usage ; nous avons accompli la moitié du travail.
Il reste toutefois toute la phase d’industrialisation afin de passer réellement du POC à un produit exploité en production par des utilisateurs finaux. Cela inclut, entre autres, des considérations d’observabilité, d’authentification, d’évaluation des agents et d’isolation des données.
Pour répondre à ces enjeux, AWS annonce la disponibilité générale de la plateforme Bedrock Agent Core, qui prend en charge l’ensemble de ces problématiques afin d’accélérer significativement le déploiement et la gestion runtime des agents.
La plateforme est structurée autour de neuf piliers :
Runtime : un environnement d’exécution compatible avec les librairies standards (LangChain / LangGraph), serverless, isolé pour l’agent et ses outils, et optimisé pour éviter les cold starts. L’approche serverless permet de bénéficier de l’auto-scaling sans avoir à gérer l’infrastructure.
Memory : une gestion entièrement personnalisable de la mémoire à court et à long terme, permettant à l’agent de se souvenir efficacement du début de son raisonnement ou de ses exécutions passées afin de favoriser un apprentissage continu.
Gateway : un outil permettant de wrapper des MCP, des API ou des fonctions Lambda existantes en outils directement utilisables par les agents dans Agent Core. Il facilite l’intégration d’outils externes en serverless tout en ajoutant des couches de sécurité supplémentaires.
Identity : un service dédié à l’authentification, garantissant que les outils sont appelés avec les credentials de l’utilisateur. Cette fonctionnalité est essentielle pour mesurer la consommation de tokens par utilisateur, détecter des usages détournés et appliquer les mêmes normes de sécurité que pour les autres services.
Observability : une vue de debug, intégrée à CloudWatch, permettant de tracer les appels à l’agent et de reconstituer l’ensemble de la chaîne de raisonnement et des appels aux outils effectués en production. Des métriques avancées sont également disponibles pour le monitoring des outils (mémoire, threads, événements, etc.).
Code Interpreter : un environnement sandboxé permettant l’exécution de code avec des dépendances et des permissions maîtrisées, afin de minimiser les effets de bord.
Managed Browser : similaire au Code Interpreter, mais fournissant cette fois un navigateur à l’agent, lui permettant d’interagir avec des interfaces graphiques. À noter que le modèle Nova Act a été conçu spécifiquement pour ce cas d’usage.
Évaluation : un service de monitoring continu des performances du système agentique, reposant sur des métriques built-in (par exemple des templates de prompts pour une approche LLM as a Judge) ou des métriques personnalisées, afin de surveiller le comportement de l’agent en production. Ce service est notamment utile pour détecter l’impact négatif potentiel de la mémoire long terme après plusieurs milliers d’appels.
Policy : l’équivalent de guardrails pour les agents. Ce service permet d’intercepter et de bloquer les comportements interdits sur la base de règles strictes. Ces règles peuvent être définies de manière déclarative ou en langage naturel, puis automatiquement converties en règles formelles.
Toutes ces fonctionnalités permettent de rajouter la couche de Sécurité, d'Infrastructure et de Monitoring absolument nécessaires pour s'assurer d'un produit pérenne en production. La caractéristique serverless et l'intégration complète aux autres services permet d'éliminer une grande partie de la complexité technique en la déléguant à AWS. On peut ainsi passer plus de temps à investir sur les phases de design produit et d'expérimentations pour maximiser la pertinence et l'impact des solutions proposées.
Conclusion
Dans cet article, nous avons dressé un état des lieux des produits dédiés au développement d’agents IA chez AWS fin 2025. Ces capacités, allant de l’infrastructure jusqu’au maintien en production, permettent de soutenir le déploiement de l’IA, qui, selon nous, dépassera les solutions de type chatbot pour évoluer vers des systèmes agentiques optimisés, reposant sur des modèles plus frugaux.