

Quicksight est l’outil de BI (Business Intelligence, informatique décisionnelle) de AWS. Il permet d’exposer et de visualiser les données stockées dans AWS (Redshift, RDS …) ou ailleurs (base de données on-premise, …).
Il propose la création d’analyses et de dashboards permettant de mettre en avant les données des organisations dans le but d’aider à la prise de décision.
Pour faciliter le déploiement dans les différents environnements, les visualisations créées sur Quicksight peuvent être terraformées. Cette méthode permet d’appliquer les avantages de l’infrastructure-as-code à la visualisation:
- La reproductibilité entre les différents environnements (dev, recette, pré-prod, prod).
- Le versioning des dashboards.
- La limitation des erreurs humaines.
- La collaboration facilitée pour la création des dashboards.
Pendant la mise en place de ce dashboard, j’ai rencontré un obstacle : les documentations Quicksight et Terraform ne sont pas toujours évidentes à interpréter.
La documentation Terraform est incomplète (les visualisations Quicksight incluent des paramètres spécifiques qui ne sont pas présents dans la documentation). Il n’y a pas de documentation sur les fonctionnalités avancées comme les “controls” et les “parameters”.
La documentation de l’API Quicksight peut être compliquée à utiliser pour la mise en place.
Dans cet article, nous allons créer pas à pas le dashboard suivant :
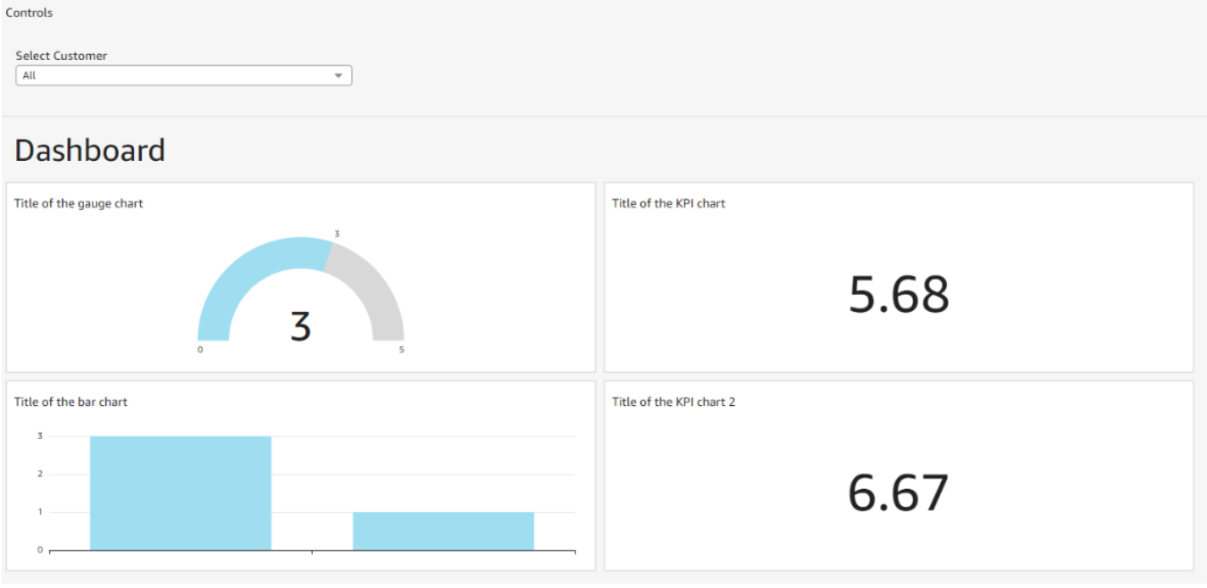
Dashboard à créer
Il contient quatre graphiques :
- 1 jauge,
- 1 histogramme,
- 2 KPIs (Key Performance Indicators).
En haut du dashboard se trouve une liste déroulante, un “control”, qui permet de filtrer les visuels.
Pour cet exemple, les données sont stockées dans Redshift. Dans la base, elles sont organisées en architecture médaillon (bronze, silver, gold). Les données remontées dans Quicksight sont celles de la table gld__customers de la couche gold.
Elle se présente sous cette forme :

Table gld__customers
Architecture du répertoire
|- data.tf
|- iam.tf
|- quicksight_datasources.tf
|- quicksight_dataset.tf
|- terraform-vars.tfvars
|- variables.tf
|- quicksight_dasboard.tf
En fin d’article, j’aborderai la notion d’analyse Quicksight et je vous montrerai comment l’intégrer dans votre projet. Nous ajouterons un nouveau fichier Terraform :
|- quicksight_analysis.tf
Les variables
variables.tf
Les variables utilisées dans ce projet sont les suivantes :
################################################
# Users Variables
################################################
variable "users" {
description = "Map of Quicksight users"
type = map(object({
email = string
}))
}
################################################
# Dataset Variables
################################################
variable "dataset_column_to_select" {
type = map(object({
name = string
type = string
}))
}
terraform-vars.tfvars
################################################
# Project variables
################################################
project = "project_name"
environment = "dev"
account = "non-prod"
extra_tags = {}
################################################
# Users Variables
################################################
users = {
user1 = {
email = "abd@def.fr"
},
user2 = {
email = "ghi@jkl.fr"
}
}
################################################
# Dataset variables
################################################
dataset_column_to_select = {
customer_id = {
name = "customer_id"
type = "STRING"
},
name = {
name = "name"
type = "STRING"
},
last_name = {
name = "last_name"
type = "STRING"
},
age = {
name = "age"
type = "INTEGER"
},
job_id = {
name = "job_id"
type = "STRING"
},
salary = {
name = "salary"
type = "INTEGER"
}
}
Les sources externes : data.tf
Nous commençons par importer les data sources (ressources créées en dehors de ce projet Terraform). Nous récupérons le cluster Redshift ainsi que les credentials pour s’y connecter.
#######################################
# Retrieve Redshift password secret
#######################################
data "aws_secretsmanager_secret" "redshift_master_password" {
name = "redshift-master-password"
}
data "aws_secretsmanager_secret_version" "secret_version" {
secret_id = data.aws_secretsmanager_secret.redshift_master_password.id
}
data "aws_redshift_cluster" "redshift_cluster" {
cluster_identifier = "redshift-cluster"
}
#######################################
# Retrieve AWS account infos
#######################################
data "aws_caller_identity" "current" {}
Configuration IAM : iam.tf
Dans cette partie, nous configurons un rôle IAM et une connexion VPC pour AWS Quicksight. Ils permettent à Quicksight d'accéder au cluster Redshift via un réseau privé.
resource "aws_iam_role" "vpc_connection_role" {
assume_role_policy = jsonencode({
Version = "2012-10-17"
Statement = [
{
Effect = "Allow"
Action = "sts:AssumeRole"
Principal = {
Service = "quicksight.amazonaws.com"
}
}
]
})
inline_policy {
name = "QuicksightVPCConnectionRolePolicy"
policy = jsonencode({
Version = "2012-10-17"
Statement = [
{
"Sid" : "PassRolePolicyQuicksight",
"Effect" : "Allow",
"Action" : "iam:PassRole",
"Resource" : "arn:aws:iam::xxxxx:role/aws-quicksight-service-role-v0"
},
{
"Sid" : "ExecutionRolePolicyQuicksight",
"Effect" : "Allow",
"Action" : [
"quicksight:DeleteVPCConnection",
"quicksight:DescribeVPCConnection",
"quicksight:ListVPCConnections",
"quicksight:UpdateVPCConnection",
"quicksight:CreateVPCConnection",
"ec2:DescribeSecurityGroups",
"ec2:DescribeSubnets",
"ec2:DescribeVpcs",
"ec2:CreateNetworkInterface",
"ec2:ModifyNetworkInterfaceAttribute",
"ec2:DeleteNetworkInterface",
"iam:ListRoles"
],
"Resource" : "*"
}
]
})
}
}
resource "aws_quicksight_vpc_connection" "vpc_connection_to_redshift" {
vpc_connection_id = "vpc-connection-redshift"
name = "VPC connection to Redshift"
role_arn = aws_iam_role.vpc_connection_role.arn
security_group_ids = ["sg-id"]
subnet_ids = ["subnet-id1", "subnet-id2"]
}
Création des sources de données : quicksight_datasource.tf
Dans cette partie, nous déclarons les sources de données Quicksight (ici, notre cluster Redshift).
Nous y ajoutons des paramètres (cluster_identifier et database_name) ainsi que les credentials.
Dans cette configuration, une seule personne possède les autorisations pour récupérer les informations de la datasource. Le principal peut être variabilisé afin que plusieurs personnes puissent les récupérer.
resource "aws_quicksight_data_source" "redshift_data_source" {
data_source_id = "quicksight_redshift_data_source"
name = "Redshift Database"
parameters {
redshift {
cluster_id = data.aws_redshift_cluster.redshift_cluster.cluster_identifier
database = data.aws_redshift_cluster.redshift_cluster.database_name
}
}
credentials {
credential_pair {
username = jsondecode(data.aws_secretsmanager_secret_version.secret_version.secret_string)["username"]
password = jsondecode(data.aws_secretsmanager_secret_version.secret_version.secret_string)["password"]
}
}
type = "REDSHIFT"
vpc_connection_properties {
vpc_connection_arn = aws_quicksight_vpc_connection.vpc_connection_to_redshift.arn
}
permission {
actions = [
"quicksight:DescribeDataSource",
"quicksight:DescribeDataSourcePermissions",
"quicksight:PassDataSource"
]
principal = "arn:aws:quicksight:eu-xxx-3::user/default/abc@def.fr"
}
}
Documentation AWS Datasource
Création des datasets : quicksight_dataset.tf
Maintenant que la source de données est définie, il faut indiquer les datasets à importer.
On définit les paramètres du dataset : data_set_id, name, ainsi que son mode d’import, DIRECT_QUERY ou SPICE :
- SPICE (Super-fast, Parallel, In-memory Calculation Engine) permet de mettre en cache les données requêtées. Cela permet notamment de visualiser les données même si le cluster Redshift est éteint. Cette option peut être intéressante quand le volume de données est encore faible. Si vous choisissez cette option, pensez à surveiller les coûts engendrés par SPICE car ils peuvent vite augmenter.
- En utilisant l’option DIRECT_QUERY, les données sont requêtées directement à la source. Elle doit donc être disponible.
On indique également les colonnes à importer et la datasource à interroger. On termine par donner les permissions aux utilisateurs concernés. Vous remarquerez qu’ici, l’utilisateur est variabilisé.
# Definition du dataset
resource "aws_quicksight_data_set" "gld__customers" {
data_set_id = "quicksight_redshift_dev_gld__customers"
name = "gld__customers"
import_mode = "DIRECT_QUERY"
physical_table_map {
physical_table_map_id = "example-id"
custom_sql {
# Choix des colonnes à importer
dynamic "columns" {
for_each = var.dataset_column_to_select
content {
name = columns.value.name
type = columns.value.type
}
}
data_source_arn = aws_quicksight_data_source.redshift_data_source.arn
name = aws_quicksight_data_source.redshift_data_source.name
sql_query = "select * from public.gld__customers"
}
}
# Établir les permissions pour les utilisateurs
dynamic "permissions" {
for_each = var.users
content {
actions = [
"quicksight:DescribeDataSet",
"quicksight:DescribeDataSetPermissions",
"quicksight:PassDataSet",
"quicksight:DescribeIngestion",
"quicksight:ListIngestions"
]
principal = "arn:aws:quicksight:eu-west-3:${data.aws_caller_identity.current.account_id}:user/default/${permissions.value.email}"
}
}
}
Le dashboard : quicksight_dashboard.tf
Pour rappel, le dashboard, nous allons créer contient quatre graphiques:
- Une jauge (Gauge chart)
- Un histogramme (Bar chart)
- Deux KPIs (Key Performance Indicators)
Nous allons également ajouter un “control”, une liste déroulante qui permet de filtrer les visualisations.
Pour mieux comprendre l'implémentation de la partie dashboard, voici un schéma montrant son organisation :
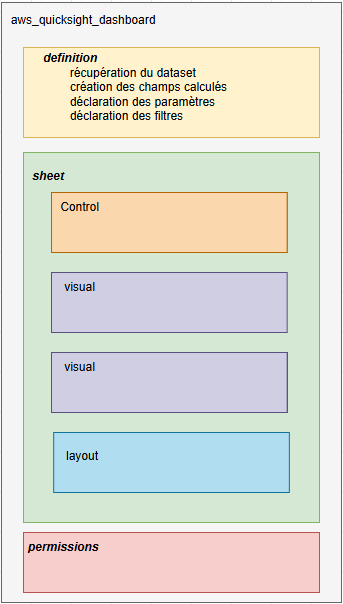
Artchitecture de la section dashboard
Une première partie concernera la définition du dashboard. Elle contiendra les informations nécessaires à sa création (import de la donnée, création des champs calculés, déclaration des paramètres et des filtres).
Ensuite, la partie sheet comprendra la définition du control, des graphiques et la mise en page. Enfin, une partie permissions donnera les droits de visualiser et d'intéragir avec le dashboard.
Préparation du dashboard
# Création du dashboard
resource "aws_quicksight_dashboard" "quicksight-dashboard" {
dashboard_id = "quicksight-dashboard"
name = "quicksight-dashboard"
version_description = "version"
definition {
# Récupération du dataset
data_set_identifiers_declarations {
data_set_arn = aws_quicksight_data_set.gld__customers.arn
identifier = "gld__customers"
}
Calcul d’une nouvelle valeur à partir d’un champ
Création d'un nouveau champ (max_salary) à partir d'un champ existant (salary).
Ce champ sera appelé plus tard dans un graphique.
calculated_fields {
data_set_identifier = "gld__customers"
name = "max_salary"
expression = "max({salary})"
}
Documentation : Calculated_fields
Déclaration des paramètres
Création d’un paramètre pour filtrer sur le champ customer_id :
# Déclaration des parameters
parameter_declarations {
string_parameter_declaration {
name = "selectcustomer"
# le paramètre peut avoir plusieurs valeurs
parameter_value_type = "MULTI_VALUED"
default_values {
dynamic_value {
default_value_column {
column_name = "customer_id"
data_set_identifier = "gld__customers"
}
}
}
}
}
Documentation : Parameter
Création des filtres
# Création d'un groupe contenant un ou plusieurs filtres (ici un seul)
# Un filter_group est appliqué à un même groupe de graphiques
filter_groups {
filter_group_id = "filter-by-customer"
# Appliquer le filtre à tous les datasets de la feuille
cross_dataset = "ALL_DATASETS"
status = "ENABLED"
filters {
category_filter {
filter_id = "customer_id"
column {
column_name = "customer_id"
data_set_identifier = "gld__customers"
}
configuration {
custom_filter_configuration {
match_operator = "EQUALS"
# Inclure les valeurs nulles dans le résultat
null_option = "ALL_VALUES"
# fait référence au paramètre déclaré plus haut
parameter_name = "selectcustomer"
}
}
}
}
# Spécification du scope sur lequel appliquer les filtres
scope_configuration {
selected_sheets {
sheet_visual_scoping_configurations {
sheet_id = "dashboard"
# Choisir "SELECTED_VISUALS" pour l'appliquer à un seul graphique
scope = "ALL_VISUALS"
# Décommenter si l'option SELECTED_VISUALS est choisie et ajouter l'id du graphique
# visual_id = "visual_id"
}
}
}
}
Documentation : Filters
Construction de la “feuille” qui contiendra les graphiques
sheets {
title = "Dashboard"
sheet_id = "dashboard"
Création du “control”
Comme indiqué plus haut, le control est une liste déroulante permettant de filtrer les données des graphiques.
# Configuration du control
parameter_controls {
# Liste déroulante
dropdown {
parameter_control_id = "select-customer"
# référence au paramètre déclaré précédemment
source_parameter_name = "selectcustomer"
title = "Select Customer"
# Sélection d'un champ seulement ou de
# plusieurs champs (MULTI_SELECT) dans la liste déroulante
type = "SINGLE_SELECT"
display_options {
select_all_options {
# afficher (VISIBLE) ou non l'option "select_all"
visibility = "HIDDEN"
}
}
selectable_values {
link_to_data_set_column {
column_name = "customer_id"
data_set_identifier = "gld__customers"
}
}
Documentation : ParameterControl
Cascading control
Le cascading control est intéressant lorsque vous avez plusieurs controls. Il permet d’afficher les valeurs suivant ce qui a été sélectionné dans les autres controls.
Pour cet exemple, nous n’avons qu’un seul control, mais voici le code à ajouter si vous en avez plusieurs et que vous souhaitez les lier entre eux.
cascading_control_configuration {
source_controls {
# id du contrôle lié
source_sheet_control_id = var.source_sheet_control_id
column_to_match {
# nom de la colonne liée
column_name = var.source_control_column_name
data_set_identifier = var.data_set_identifier
}
}
}
}
}
Documentation : CascadingControlConfiguration
Création des graphiques
Jauge
Jauge
# Création des graphiques
visuals {
gauge_chart_visual {
visual_id = "gauge-chart"
title {
format_text {
plain_text = "Title of the gauge chart"
}
}
chart_configuration {
gauge_chart_options {
arc {
arc_thickness = "LARGE"
arc_angle = 180.0
}
arc_axis {
range {
max = 5
min = 0
}
}
primary_value_font_configuration {
font_size {
relative = "LARGE"
}
}
}
field_wells {
values {
numerical_measure_field {
field_id = "1"
column {
data_set_identifier = "gld__customers"
column_name = "age"
}
aggregation_function {
simple_numerical_aggregation = "AVERAGE"
}
}
}
}
}
}
}
Documentation : GaugeChartVisual
Histogramme
Histogramme
visuals {
bar_chart_visual {
visual_id = "bar-chart"
title {
format_text {
plain_text = "Title of the bar chart"
}
}
chart_configuration {
bars_arrangement = "CLUSTERED"
orientation = "HORIZONTAL"
field_wells {
bar_chart_aggregated_field_wells {
category {
categorical_dimension_field {
field_id = "1"
column {
data_set_identifier = "gld__customers"
column_name = "job_id"
}
}
}
values {
categorical_measure_field {
field_id = "2"
column {
data_set_identifier = "gld__customers"
column_name = "customer_id"
}
aggregation_function = "COUNT"
}
}
}
}
}
}
}
Documentation : BarChartVisual
KPIs

KPIs
# Premier KPI
visuals {
kpi_visual {
visual_id = "kpi-chart"
title {
format_text {
plain_text = "Title of the KPI chart"
}
}
chart_configuration {
field_wells {
values {
numerical_measure_field {
field_id = "1"
column {
data_set_identifier = "gld__customers"
column_name = "salary"
}
aggregation_function {
simple_numerical_aggregation = "AVERAGE"
}
}
}
trend_groups {
categorical_dimension_field {
field_id = "2"
column {
data_set_identifier = "gld__customers"
column_name = "job_id"
}
}
}
}
}
}
}
# Second KPI
visuals {
kpi_visual {
visual_id = "kpi-chart-2"
title {
format_text {
plain_text = "Title of the KPI chart 2"
}
}
chart_configuration {
field_wells {
values {
categorical_measure_field {
field_id = "1"
# Use the calulated field
column {
data_set_identifier = "gld__customers"
column_name = "max_salary"
}
}
}
}
}
}
}
Documentation : KPIVisual
Mise en page
# Configuration du layout
layouts {
configuration {
grid_layout {
elements {
element_id = "gauge-chart"
element_type = "VISUAL"
column_index = 0
column_span = 15
row_index = 0
row_span = 5
}
elements {
element_id = "bar-chart"
element_type = "VISUAL"
column_index = 0
column_span = 15
row_index = 6
row_span = 5
}
elements {
element_id = "kpi-chart"
element_type = "VISUAL"
column_index = 15
column_span = 15
row_index = 0
row_span = 5
}
elements {
element_id = "kpi-chart-2"
element_type = "VISUAL"
column_index = 15
column_span = 15
row_index = 6
row_span = 5
}
canvas_size_options {
screen_canvas_size_options {
resize_option = "RESPONSIVE"
}
}
}
}
}
}
}
Permissions
# Appliquer les permissions aux utilisateurs
dynamic "permissions" {
for_each = var.users
content {
actions = [
"quicksight:ListDashboardVersions",
"quicksight:QueryDashboard",
"quicksight:DescribeDashboard"
]
principal = "arn:aws:quicksight:eu-west-3:${data.aws_caller_identity.current.account_id}:user/default/${permissions.value.email}"
}
}
}
Documentation :
Dashboard
Dashboard Definition
L’analyse : quicksight_analysis.tf
Le dashboard permet seulement aux utilisateurs d’interagir avec les données. L’analyse nous donne la possibilité de faire des modifications dans les visuels.
La configuration d’une analyse est très similaire à celle d’un dashboard. Il reste cependant quelques différences dans les permissions et dans les paramètres de définition de l’analyse.
Toute la partie définition est la même que pour le dashboard.
# Création de l'analyse
resource "aws_quicksight_analysis" "quicksight-analysis" {
analysis_id = "quicksight-analysis"
name = "quicksight-analysis"
definition {
sheets {
title = "Dashboard"
sheet_id = "dashboard"
{...}
}
}
}
Permissions
# Appliquer les permissions aux utilisateurs
dynamic "permissions" {
for_each = var.users
content {
actions = [
"quicksight:RestoreAnalysis",
"quicksight:UpdateAnalysisPermissions",
"quicksight:DeleteAnalysis",
"quicksight:QueryAnalysis",
"quicksight:DescribeAnalysisPermissions",
"quicksight:DescribeAnalysis",
"quicksight:UpdateAnalysis"
]
principal = "arn:aws:quicksight:eu-west-3:${data.aws_caller_identity.current.account_id}:user/default/${permissions.value.email}"
}
}
}
Documentation :
Analysis
Analysis Definition
Conclusion
Nous venons de créer un dashboard Quicksight contenant plusieurs graphiques et options. Si vous souhaitez approfondir le sujet ou mettre en place d’autres types de graphiques, je vous conseille de vous référer à la documentation de l’API Quicksight.
