

Afin de garantir des produits de qualité et des performances optimales, les entreprises sont amenées à investir dans la modernisation de leurs services. Parmi ces investissements, la mise en place d’un système de monitoring efficace se distingue comme l’un des leviers les plus stratégiques et à forte valeur ajoutée. En offrant une visibilité continue sur les systèmes, il permet non seulement d’anticiper les dysfonctionnements, mais aussi d’optimiser les processus en temps réel.
Traditionnellement, le monitoring est perçu comme un domaine technique, centré sur des indicateurs comme la disponibilité des serveurs, la consommation des CPU ou encore les temps de réponse d’une API. Ces données sont certes cruciales pour évaluer l’état de santé d’un service, mais elles ne suffisent pas à garantir qu’un service fonctionne correctement du point de vue de l’utilisateur final.
En effet, il existe un écart fréquent entre ce que ces indicateurs montrent et ce que les utilisateurs vivent réellement lors de l’utilisation de notre service. Un service peut être techniquement opérationnel, mais fonctionnellement inutilisable.
C’est précisément là qu’intervient le monitoring métier : un outil permettant aux équipes non techniques de suivre, comprendre et piloter la qualité de service telle qu’elle est perçue par les utilisateurs finaux.
Le monitoring technique ne dit pas tout, pensons alors technico-fonctionnel
Comme nous l’avons vu, le monitoring technique est un premier pas essentiel pour appréhender l’état de santé d’un service numérique. Sans monitoring technique solide, il est impossible de mettre en place un monitoring métier automatisé et fiable.
En effet, si une brique technique du système est instable, l’expérience utilisateur sera inévitablement impactée. Autrement dit, un monitoring métier efficace ne peut exister sans une base technique bien instrumentée.
Ces deux types de monitoring couvrent des réalités différentes et seront donc complémentaires :
Cette vision technico-fonctionnelle permet de croiser les signaux techniques et les indicateurs métier pour obtenir une lecture plus complète, plus fiable, et plus utile de la qualité de service rendue aux utilisateurs.
C’est sur cette base hybride que le monitoring métier prend tout son sens, en traduisant la santé technique d’un service en valeur réellement perçue par les utilisateurs.
Passer de la vision technique à la vision métier
Une fois les fondations techniques bien posées, il devient possible d’adopter une vision métier du monitoring. Cela consiste à changer de perspective : il ne s’agit plus seulement de contrôler le bon fonctionnement des composants d’un service, mais de s’assurer que l’application délivre réellement le service attendu par les utilisateurs.
Traditionnellement, pour obtenir cette vision, les équipes métier ou produit interrogent directement, mais à posteriori, les utilisateurs finaux : entretiens, ateliers, remontées terrain… Cette approche est riche, mais elle présente plusieurs limites :
- Elle mobilise du temps humain (au moins deux personnes, sur plusieurs heures).
- Elle offre une vue ponctuelle, souvent rétrospective.
- Et elle repose sur des perceptions qui peuvent être subjectives ou incomplètes.
Le monitoring métier, lui, permet d’intercepter et tracer cette information en continu, sans sollicitation manuelle, et avec des données objectives sur des parcours réellement utilisés.
Ce type d’interviews, coûteux en temps et en ressources, peut ainsi être réorienté vers des usages à forte valeur, comme le recueil de besoins ou l’exploration terrain. L’observabilité de la disponibilité métier ne dépend alors plus de la résilience silencieuse des utilisateurs finaux, mais repose sur des indicateurs objectifs, continus et mesurables.
En pratique, cela revient à monitorer les parcours métiers clés :
- Est-ce qu’un salarié peut déposer une note de frais ?
- Est-ce qu’un client peut finaliser une commande ?
- Est-ce qu’un agent peut générer un contrat sans erreur ?
Le monitoring métier s’intéresse à l’expérience réelle. Il s’appuie souvent sur :
- Des scénarios synthétiques (parcours automatisés simulant un utilisateur réel),
- Ou du Real User Monitoring (RUM) pour suivre ce que font réellement les utilisateurs.
Contrairement aux indicateurs techniques, les métriques métier sont actionnables :
- Le taux de succès d’un parcours permet de repérer immédiatement une rupture fonctionnelle.
- Les délais moyens observés peuvent alerter sur une dégradation de performance métier.
- Les volumes d’actions réussies/échouées orientent les priorisations.
Ce changement de regard transforme le monitoring en outil stratégique pour les équipes métier. Il ne s’agit plus seulement de constater qu’un système est disponible, mais de savoir si les parcours critiques du quotidien sont réellement opérationnels.
Un outil de pilotage métier
Le monitoring métier ne se limite pas à détecter des anomalies fonctionnelles : c’est aussi un véritable levier de pilotage pour les équipes métier. Il leur offre enfin une visibilité directe sur ce qui se passe réellement dans les services numériques qu'elles portent, utilisent et/ou supervisent.
Concrètement, il permet :
- Un gain en réactivité : en cas de dégradation, les équipes peuvent être alertées en temps réel, sans attendre une vague de tickets utilisateurs. Cela permet d’agir plus vite et de limiter les impacts métier.
- Une priorisation selon l’impact réel : un bug détecté sur un parcours critique (ex : validation de commande ou de contrat) peut être remonté et traité avant une anomalie mineure. Ce n’est plus la "gravité perçue par la technique" qui prime, mais l’effet métier constaté.
- Un suivi de la qualité de service dans le temps : grâce aux indicateurs métier (taux de succès, délai moyen d’exécution, erreurs fonctionnelles), les équipes peuvent surveiller les performances de leurs services comme on suit un tableau de bord de production, et ainsi avoir un réel aperçu de l’état de santé de leur service.
- Un renforcement du dialogue entre équipes techniques et les équipes métier : le monitoring métier permet de partager une base commune de données entre les métiers et la technique. Plutôt que de débattre d’émotions ou de ressentis, les échanges s’appuient sur des faits mesurés.
Avec ce type de monitoring, les directions métier et les responsables de processus ne dépendent plus uniquement des équipes techniques pour évaluer la santé d’un service.Ils deviennent pleinement acteurs de sa surveillance et de son amélioration, grâce à des outils concrets pour piloter l’expérience utilisateur au quotidien.
Comment mettre en place un monitoring métier sur son projet ?
Une fois que la mise en place d’un monitoring technique solide est faite, il est possible de passer à la mise en place d’un monitoring axé métier. Ce type de dashboarding suppose une agrégation des données provenant des différents dashboards techniques, afin de mettre en lumière certaines informations pouvant aider à la prise de décision ou à la supervision de l’état de santé réel d’un parcours critique.
La supervision métier représente une évolution vers une forme d’hypervision, qui ne se limite plus à surveiller chaque système indépendamment, mais qui agrège et structure les données issues de différentes sources de supervision préexistantes, notamment mise en place via le monitoring technique. Ce passage à une vision consolidée pose néanmoins un défi majeur : garantir la qualité, la cohérence et l’exploitation efficace de données souvent hétérogènes.
Ce changement de paradigme peut également rencontrer des résistances, notamment culturelles ou organisationnelles. Pour y faire face, il est essentiel d’associer les équipes dès les premières phases du projet, de démontrer rapidement la valeur ajoutée d’une telle démarche, et d’accompagner la montée en compétence autour des nouveaux outils et usages. Avec une approche progressive et encadrée, il est tout à fait possible de bâtir un dispositif efficace, durable et compréhensible par toutes les équipes métier.
Pour se faire, il est possible de suivre cette méthodologie :
- Mettre en place un dashboarding technique fiable
Avant toute restitution métier, il faut s'assurer que les données sont bien disponibles, fiables et exploitables. Cela passe par la mise en place de dashboards techniques qui permettent de surveiller la fraîcheur, la complétude et la qualité des données en amont. Cette étape sert de filet de sécurité : elle garantit que les indicateurs métiers à venir reposeront sur un socle robuste.
Une Definition of Done (DoD) doit être formalisée dès le départ. Il s'agit d'un ensemble de critères objectifs qui permettent de dire qu'une donnée ou un parcours est "prêt à être instrumenté". Par exemple, sur un parcours de connexion à un site, la DoD pourrait inclure : un taux de succès supérieur à 98 %, un temps de réponse moyen inférieur à 500 ms, des logs complets sur 100 % des tentatives de connexion, et une alimentation des données dans le système d’analyse en moins de 5 minutes après l’événement.
Pour aller plus loin dans la mise en place du dashboard technique, je vous propose d’aller voir les excellents articles de Jean-Michel Cante sur les bases de l’observabilité informatique: Comprendre les bases 1 et 2.
Ce cadre évite de construire des dashboards métiers sur des fondations instables ou partielles.
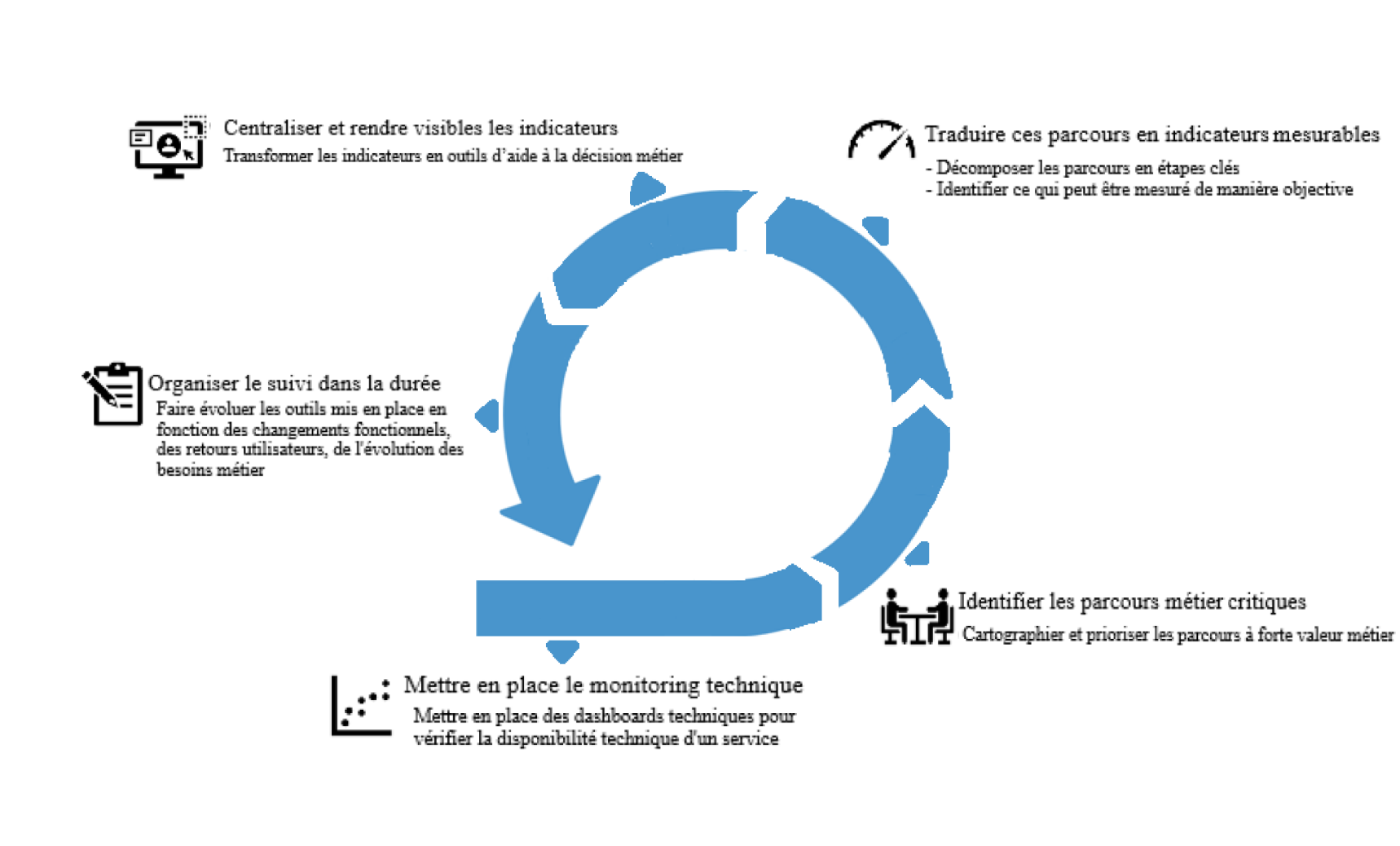
- Identifier les parcours métier critiques :
Avant toute instrumentation, il faut savoir ce que l’on veut surveiller. Cela passe par un travail en commun entre les équipes techniques et métiers pour cartographier les parcours à fort impact.
L’objectif est avant tout de prioriser les parcours à forte valeur métier, visibles, fréquents ou sensibles.
- Traduire ces parcours en indicateurs mesurables
Une fois les parcours métier identifiés, il s’agit de les décomposer en étapes clés et d’identifier ce qui peut être mesuré de manière objective. Le but : obtenir des indicateurs concrets, compréhensibles et exploitables par les métiers comme par les équipes techniques.
Voici quelques types d’indicateurs à envisager :
- Points de passage réussis ou en échec
Exemple : un appel à un endpoint retourne une erreur 403 sur une étape précise d’un parcours, révélant un blocage fonctionnel. - Temps entre deux actions métier
Exemple : un utilisateur crée un compte sur un site, mais ne reçoit l’email de confirmation qu’après plusieurs jours. Si l’on observe un délai moyen anormalement long (ex : 7 jours) et un taux d’abandon élevé, cela peut révéler une défaillance dans le processus d’envoi ou de réception de l’email. - Non-respect de règles métier ou erreurs fonctionnelles
Exemple : un formulaire peu restrictif laisse passer des saisies invalides. Lors de l’appel backend, de nombreuses erreurs 400 sont remontées. Cela suggère un manque de validation côté front.
Il est possible de s’appuyer sur les logs existants (applicatifs ou fonctionnels) : c’est souvent un bon point de départ. Si besoin, les applications peuvent être enrichies pour tracer davantage d’informations métier (ex : état de validation, étape atteinte, erreurs utilisateur…).
- Centraliser et rendre visibles les indicateurs
Une fois ces indicateurs identifiés, encore faut-il les rendre accessibles, lisibles et actionnables pour les équipes concernées. Il ne s’agit pas simplement de stocker des données, mais de les transformer en outils d’aide à la décision métier.
Plusieurs canaux peuvent être mis en place :
- Dashboards partagés
Exemple : création de tableaux de bord dédiés dans l’outil de monitoring utilisé par l’IT (Grafana, Kibana…), mais adaptés à la lecture métier.
- Alertes personnalisées sur des seuils métier
Exemple : envoi automatique d’une alerte sur votre plateforme de communication préférée dès qu’un taux de succès descend en dessous de 80 % sur un processus critique.
- Rapports périodiques automatisés
Exemple : envoi hebdomadaire d’un email synthétisant les données clés du monitoring métier sur un périmètre donné (volume de parcours réussis/échoués, délais moyens, anomalies…)
Certains outils techniques peuvent être adaptés à cette couche métier, à condition de travailler la lisibilité et la granularité des données exposées.
- Organiser le suivi dans la durée
Avoir un monitoring efficace c’est bien, mais encore faut-il le suivre. La mise en place de ce type de surveillance est exigeante, mais s’il n’évolue pas, l’effort mis sera vain. Pour que cet outil reste un dispositif vivant il faut prévoir que celui-ci sera amené à évoluer en fonction :
- Des changements fonctionnels,
- Des retours utilisateurs,
- De l’évolution des besoins métier…
Il est donc important d’intégrer ce monitoring dans les routines de pilotage afin qu’il puisse référer d’un état présent, mais aussi évoluer avec les différents enjeux qui peuvent apparaître au fur et à mesure qu’il vit.
Mettre en place un monitoring métier, ce n’est pas juste brancher un outil. C’est :
- Comprendre les vrais enjeux métier,
- Traduire ces enjeux en métriques observables,
- Partager la supervision entre IT et métiers,
- Et en faire un levier de pilotage quotidien.
Le schéma ci-dessous résume les cinq étapes pour mettre en place du monitoring métier abordés dans cette section :
Exemple d’application
Dans le cadre de ma mission actuelle, un changement de logiciel de monitoring a représenté une opportunité structurante pour refondre notre dispositif de supervision. Cette transition a été l’occasion non seulement de remettre en place les fondamentaux du monitoring technique, mais également d’y adosser un monitoring métier plus orienté vers la valeur.
J’interviens au sein d’un client composé de plusieurs équipes, au sein d’une équipe dite "socle" selon la typologie de Team Topologies. De par cette position centrale, notre service est soumis à un impératif de stabilité et de disponibilité élevé. Pour répondre à cette exigence, nous devons nous appuyer sur une solution de monitoring et d’alerting fiable, précise et réactive, permettant de détecter rapidement tout incident de production.
- Reposer les bases
Le projet a débuté par une migration d’outil, nécessitant le transfert de l’ensemble des dashboards existants vers la nouvelle solution. Plutôt que de reproduire à l’identique les tableaux de bord existants, nous avons pris le parti d’en profiter pour remettre à plat notre dispositif, afin de combler les lacunes identifiées dans l’outil précédent. Cette démarche a été guidée par les nouvelles capacités offertes par la solution retenue.
- Trouver l’essentiel
Pour structurer notre monitoring métier, nous avons adopté une approche orientée “valeur” en nous posant une question simple, mais structurante : Sur quoi sommes-nous attendus ? Dans notre cas, notre équipe est responsable du système d’authentification et de gestion des permissions utilisateurs. Elle joue également un rôle de passerelle entre la DSI et la Digital Factory. À ce titre, certaines fonctionnalités ont été qualifiées de critiques, car elles conditionnent le bon fonctionnement de nombreux services.
Ces fonctionnalités critiques font l’objet d’un double monitoring, à la fois technique et métier. À l’inverse, les fonctionnalités secondaires ne sont supervisées que sous l’angle technique.
Dans ce cadre, nous nous concentrerons ici sur un parcours clé de notre périmètre : la création de comptes.
Le monitoring technique repose principalement sur l’analyse des appels aux différents endpoints utilisés pour la création de comptes. En raison de la présence de code legacy, plusieurs endpoints coexistent encore, chacun étant intégré à un dashboard spécifique indiquant le volume d’appels dans le temps. Ce suivi permet d’identifier rapidement une baisse d’activité ou un comportement anormal. A titre d’exemple, je vous transmets un de nos dashboard d’une fonctionnalité avec plusieurs endpoints sous la forme de graphe cumulé du nombre d’appels à chaque endpoint en fonction du temps :
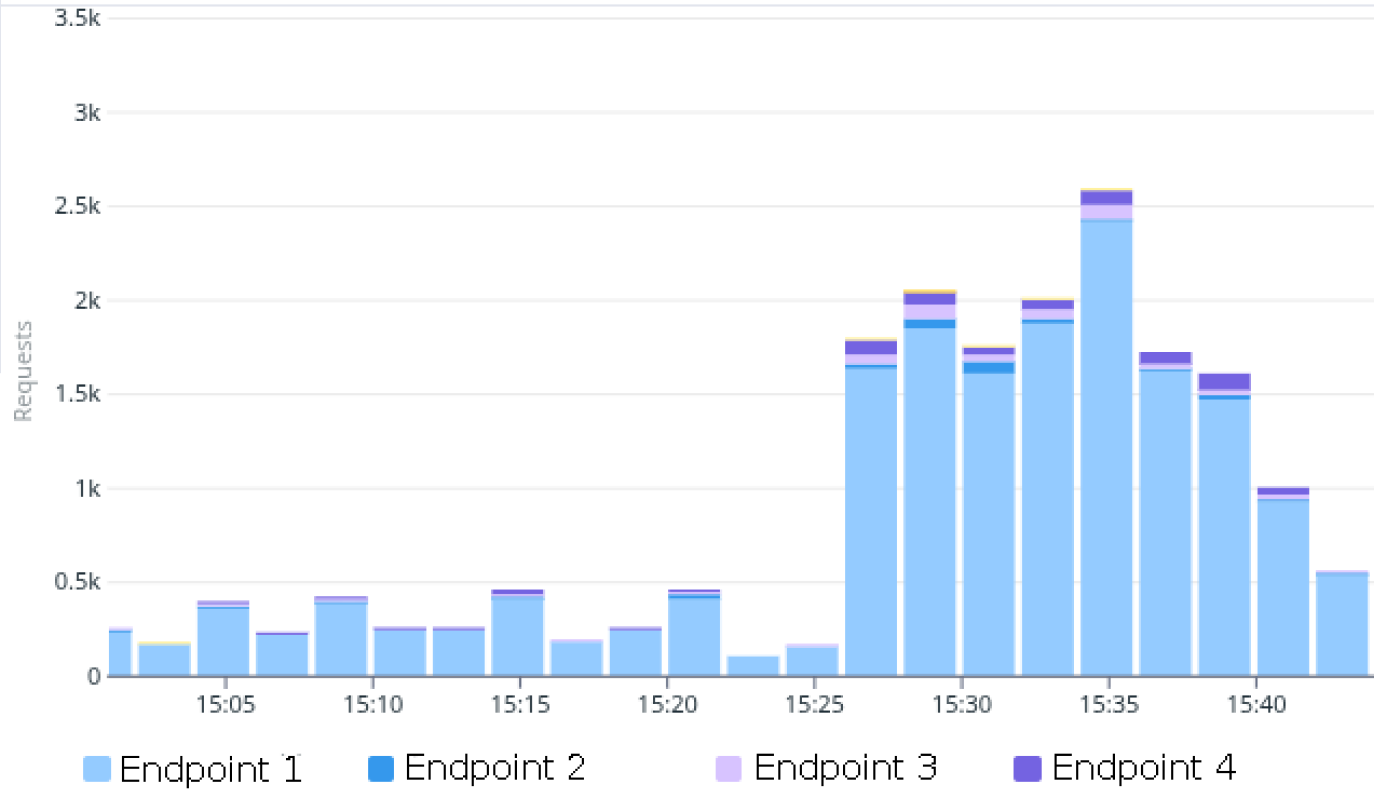
Pour approfondir ce sujet, je recommande vivement la conférence de Vivien Maleze sur OpenTelemetry, qui propose une approche complète de l'observabilité distribuée.
- Quel indicateur ?
Du point de vue métier, nous avons défini un indicateur central : le nombre quotidien de comptes créés. Ce volume est naturellement sujet à des variations, notamment selon les jours de la semaine ou les périodes de congés scolaires. L’enjeu consiste alors à déterminer un seuil critique en dessous duquel on estime qu’un dysfonctionnement est probable.
Lorsque ce seuil n’est pas atteint sur une période donnée, l’indicateur passe en alerte (niveau orange ou rouge) et déclenche une notification. Cela permet de détecter un problème métier même en l’absence d’erreur technique explicite.
- Montrer et alerter
Une fois les indicateurs définis, il convient de les rendre lisibles et directement exploitables. Nous avons mis en place des dashboards épurés, orientés autour de parcours critiques, et intégrant à la fois des KPI (taux de succès, volume d’événements, ratio d’erreurs) et des visualisations temporelles ou proportionnelles (histogrammes, graphes, camemberts).
Afin de faciliter la lecture, nous appliquons des conventions de couleurs classiques : vert pour une situation nominale, orange pour les signaux faibles, rouge pour les alertes critiques. Pour une meilleure accessibilité, il est possible d’ajouter à ce code couleur des pictogrammes. L’objectif est de permettre à un observateur, quel que soit son niveau de technicité, de répondre rapidement à la question : Comment va réellement mon service ?

Un bon dashboard ne suffit pas : il faut l’ancrer dans les pratiques de l’équipe. Chez nous, la consultation des dashboards est ritualisée. Chaque début de journée, nous effectuons un tour d’horizon des indicateurs, afin de nous assurer de la bonne santé des systèmes, tant sur le plan technique que métier. Cette routine peut également s’inscrire dans un rituel d’équipe quotidien (daily stand-up, revues hebdomadaires, etc.).
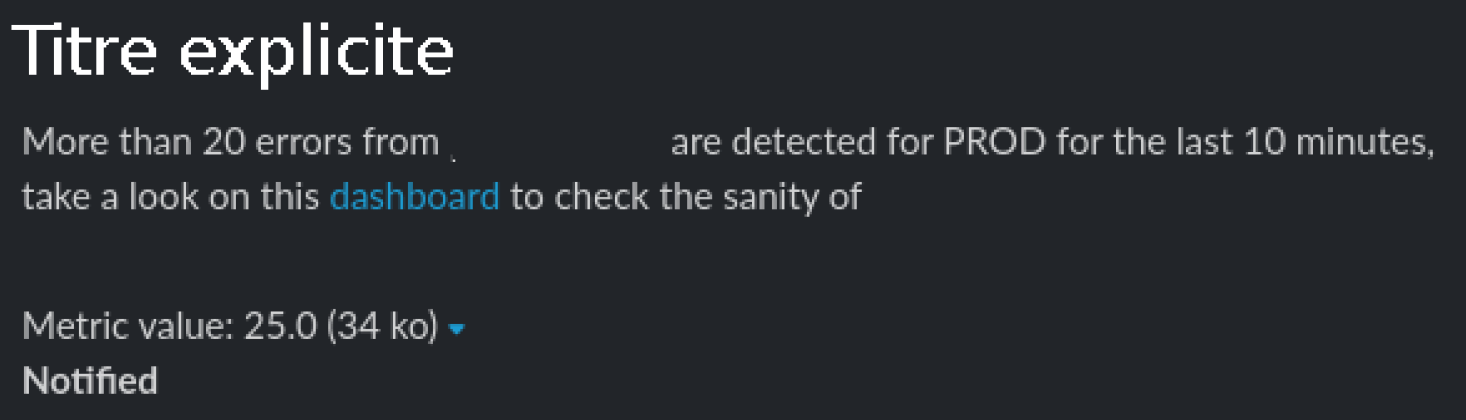
Parallèlement, nous avons mis en place un système d’alerting temps réel via notre outil de communication interne et email. Chaque alerte doit être compréhensible immédiatement : elle inclut un titre explicite, précisant l’indicateur concerné, le niveau d’alerte, ainsi qu’un lien direct vers le dashboard associé pour permettre une investigation rapide.
L’objectif est de fournir aux équipes les moyens d’identifier rapidement l’origine d’une anomalie sans multiplier les outils ou les interprétations.
- Et après ?
Enfin, un dispositif de monitoring n’est jamais figé. Il doit évoluer au fil des transformations produits. Un exemple récent illustre cette nécessité : l’ajout d’un nouveau parcours de création de comptes a modifié significativement notre volumétrie. Ne l’ayant pas répercuté dans nos seuils critiques, nous avons manqué une alerte importante, qui a été détectée par une autre équipe.
Cette expérience rappelle l’importance de l’itération continue : chaque alerte, chaque incident, chaque retour utilisateur doit être une opportunité de se reposer la question clé : Pourquoi n’avons-nous pas identifié ce dysfonctionnement plus tôt ? Et comment pouvons-nous y remédier durablement ?
Conclusion
Dans un écosystème numérique de plus en plus complexe, la supervision des services ne peut plus se limiter à des indicateurs purement techniques. Un service peut être "up", les serveurs opérationnels, les APIs répondre correctement… et pourtant, l’utilisateur ne parvient pas à accomplir son action.
Le monitoring métier vient combler ce fossé entre disponibilité technique et expérience réelle. Il permet aux équipes métier de ne plus être dépendantes des remontées utilisateurs ou des équipes techniques pour comprendre ce qui se passe concrètement sur le terrain.
En rendant visible les parcours clés, en suivant des indicateurs fonctionnels simples et en automatisant leur surveillance, on passe d’une logique réactive à une logique proactive, orientée valeur d’usage.
C’est à la fois un chantier technique et un changement culturel : un outil de pilotage partagé, qui aligne les métiers et la technique autour d’un objectif commun — la qualité de service perçue par les utilisateurs finaux.
En adoptant une approche technico-fonctionnelle du monitoring, les organisations gagnent en réactivité, en transparence et en alignement. Pour aller plus loin, je vous invite à vous référer aux articles DORA sur le monitoring et l’observabilité et sur l’alerting.
Et surtout, elles mettent enfin l’utilisateur final au centre de leur supervision — là où il aurait toujours dû être.
Cette démarche n’est qu’une première étape vers un mouvement plus large : celui d’un monitoring orienté valeur. Il est tout à fait possible d’aller plus loin en croisant ces données métier avec des indicateurs d’adoption, de satisfaction ou d’usage réel.
C’est là que se dessine le product monitoring : un outil au service des équipes produit pour piloter la valeur, l’engagement et l’impact des fonctionnalités livrées.