

Nous avons vu dans une première partie ici comment uv s’inscrit dans l’écosystème Python, ainsi que ses principales fonctionnalités. Maintenant vade retro théorie ennuyeuse, sortez vos meilleurs Shell et VSCode, et suivez-moi pas à pas dans la mise en place d’un projet de A à Z pour mieux comprendre les différentes options proposées par uv.
Travaux pratiques
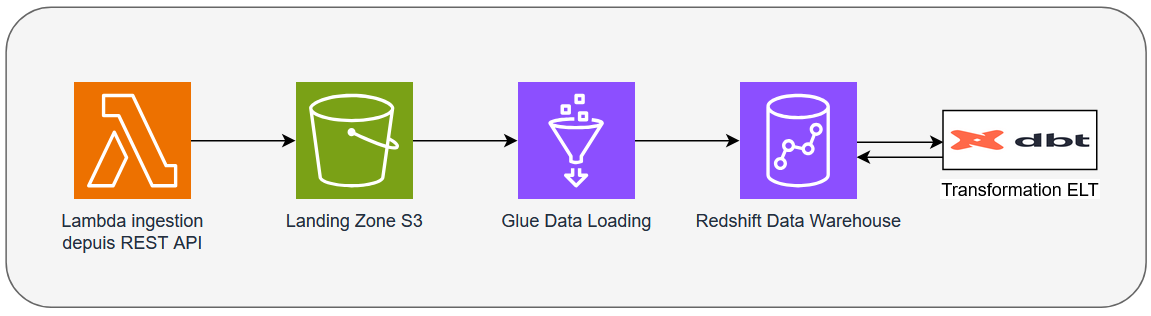
Dans le cadre de cette démonstration, je vous propose la mise en place d’un projet très simple, utilisant AWS, qui se contente de charger des données sur une landing zone S3 par appel d’une API REST quelconque à travers le service Lambda. On utilisera ensuite Glue pour monter cette donnée sur un Data warehouse Redshift. Sur celui-ci, toutes les transformations ELT seront organisées par dbt.
Parce que c’est super important pour mon histoire, il faut un nom pour ce magnifique projet. Je vous propose DécoUVerte.
Au moment où j’écris ces lignes, je travaille avec:
uv: 0.6.14
Python pour Lambda: 3.13
Python pour Glue 5.0: 3.11
dbt: 1.9.4
Il se peut que, malgré tout, l’exécution des mêmes commandes, avec les mêmes versions de chaque outil aient des rendus différents sur vos machines. Ça peut être dû au cache d’uv, mais in fine la différence globale ne devrait pas nuire à la compréhension.
Initialisation du répertoire
Il va falloir commencer par créer le répertoire de travail, le module racine qui va gérer tout notre projet (l’équivalent d’un pom aggregate1 Maven).
uv init --no-pin-python --description "Un projet de découverte UV" deco-uv-erte
uv init à la racineOn reconnaît l’usage de la commande init vue précédemment, avec cependant de nouveaux paramètres :
--descriptionpermet de rajouter la métadonnée “description” dans la table [project]. C’est facultatif, et c’est tout à fait envisageable de gérer ce genre de choses au sein du README, mais je souhaitais vous en montrer la possibilité au moins une fois, pour l’exemple.--no-pin-pythona en revanche un comportement plus intéressant. En effet, les modules déclarés par pyproject définissent un intervalle de versions valides de Python. Par exemple dans mon cas, j’ai dans mon pyproject requires-python = ">=3.12". uv interprète cet intervalle et va ensuite choisir une version compatible pour exécuter le code. Pour des raisons de reproductibilité, cette version est ensuite persistée dans un fichier .python-version. Le paramètre --no-pin-python est là pour lui dire “attend, ne choisis pas de version de Python tout de suite, je n’ai pas fini”.
Comme aucun code Python ne sera traité par le module racine, nous n’avons pas besoin de définir de back end. Pour aller plus loin, nous pouvons également supprimer le fichier main.py, et même, dans notre cas, la ligne requires-python = ">=3.12" du pyproject (on choisira une version propre à chacun de nos modules plus tard).
Lambda d’ingestion
On va créer un nouveau module ingestion dans un répertoire lambda au sein du module racine. On appelle ce module nouvellement créé un “workspace”.
uv init lambda/ingestion --python 3.13 --no-readme --description "Lambda d'ingestion pour notre super projet découverte" --build-backend hatchPas de magie, uv init lambda/ingestion --python 3.13 crée un module dans un nouveau répertoire lambda/ingestion, avec la version Python 3.13. On connaît déjà --description, --no-readme est une nouveauté. Cette option va nous permettre de gérer un unique README à la racine plutôt que d’en créer un par module. Comme pour la description, cela n’impacte pas le fonctionnement du projet, à votre guise pour l’usage.
Build back end
Jetons un oeil aux fichiers créés :
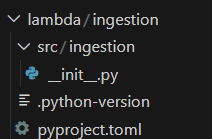
uv init pour la lambda d'ingestion[project]
name = "ingestion"
version = "0.1.0"
description = "Lambda d'ingestion pour notre super projet découverte"
authors = [
{ name = "XXX", email = "XXX@YYY.fr" } # vos informations personnelles apparaîtront ici
]
requires-python = ">=3.13"
dependencies = []
[project.scripts]
ingestion = "ingestion:main"
[build-system]
requires = ["hatchling"]
build-backend = "hatchling.build"--build-backendgénère par défaut un src layout, on voit bien l’arborescence src/ingestion.- Ici, on a implicitement créé une
--app. C’est ce paramètre en conjonction avec--build-backendqui définit la fonction main de notre application comme point d’entrée (la table [project.scripts] du pyproject.toml) - Par défaut, un package distribuable est généré avec des métadonnées supplémentaires, en l'occurrence l’auteur.
Dans notre cas particulier, un script exécutable localement fait très peu sens (le service Lambda réclame sa propre spécification de point d’entrée). Je vous propose donc de simplement supprimer la table [project.scripts].
Pour ne pas nuire à la lisibilité, on va également supprimer la ligne author.
On aurait très bien pu informer uv de ne pas générer ces lignes et s’épargner leur suppression, avec les paramètres `--lib et `--author-from none`. Cependant, notre projet jouet présente le défaut de ne pas contenir de module script pertinent, et je tenais à vous montrer ce qui était généré !
Workspace
Le fichier pyproject à la racine a également été modifié:
| Avant | Après |
|---|---|
[project] name = "deco-uv-erte" version = "0.1.0" description = "Un projet de découverte UV" readme = "README.md" dependencies = [] |
[project] name = "deco-uv-erte" version = "0.1.0" description = "Un projet de découverte UV" readme = "README.md" dependencies = [] [tool.uv.workspace] members = [ "lambda/ingestion", ] |