

Cet article présente les nouveautés évoquées lors du Databricks DATA + AI World Tour Paris qui s’est tenu le 20 novembre 2024.
La thématique centrale de cet évènement fut la démocratisation du monde de la donnée, au travers de la Data Intelligence Platform de Databricks, avec une forte teinte IA (Générative ou non).
Qu’est-ce que la démocratisation des données ?
C’est le principe de donner accès aux bonnes données, au bon moment et aux bonnes personnes. C’est ce qu'on appelle la gouvernance, qui est assurée par le projet Unity Catalog, maintenant open source. L'objectif est de rendre l'accès aux données plus facile et rapide pour tous les collaborateurs d'une même entreprise, au-delà des profils seulement techniques. Tout cela dans différents buts : réduire les temps de prises de décisions, favoriser l'innovation, augmenter l'efficacité opérationnelle et faciliter la collaboration entre les équipes.
Afin de servir ce but, Databricks a présenté la Data Intelligence Platform :
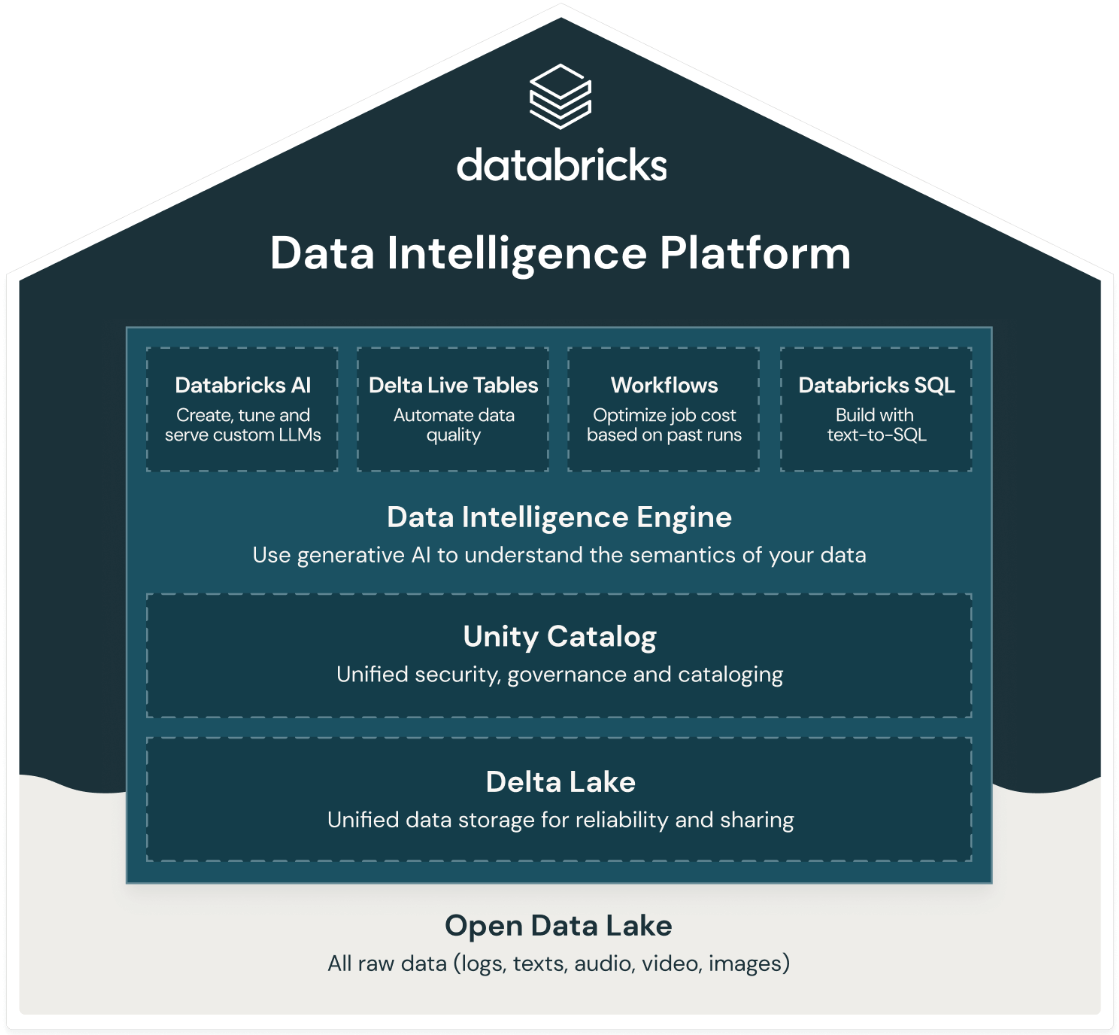
La “simple” Data Platform reposait sur la fondation du lakehouse (Delta Lake), sur laquelle vient se rajouter une couche de gouvernance unifiée (Unity Catalog) ainsi que les moteurs de transformation et requêtage des données.
La Data Intelligence Platform insère une nouvelle couche (Data Intelligence Engine) dans laquelle l’IA générative est omniprésente. En effet, elle permet de comprendre la sémantique des données propres à chaque client en analysant à la fois les données et métadonnées sur l’ensemble de la chaîne de transformation (depuis la source jusqu’à l’exposition des données), mais également leurs usages (requêtes effectuées, dashboards, lineage…).
Cela permet de réduire les barrières qui peuvent persister pour un utilisateur d’une data plateform comme, par exemple, le manque de compétence technique ou d'information à propos de la donnée.
Voici quelques fonctionnalités permises par cette couche de Data Intelligence :
- accès à la donnée en langage naturel : requêtage des données en langage naturel avec l’outil d’IA générative (Genie) traduisant automatiquement la demande en requête SQL,
- automatisation de l’optimisation des performances des clusters : gestion automatique du partitionnement et de l’indexation,
- détection automatique de données sensibles,
- cataloging sémantique : identifier le modèle des données, comprendre la manière dont elles sont utilisées, analyser la relation entre ces données et la valeur qu'elles apportent au niveau business,
- détection de la mauvaise utilisation d’une notion business (type de requête inhabituelle).
A noter également que la plateforme Databricks est maintenant disponible en 100% serverless (pour le data warehouse, l’IA, la BI, l’orchestration et l’ETL, le streaming).
Delta Lake UniForm
La fonctionnalité Delta Lake Universal Format (UniForm) est disponible sur Databricks pour favoriser l’interopérabilité avec le format Apache Iceberg - le format Apache Hudi qui est prévu prochainement.
Ces 3 formats (Delta Lake, Apache Iceberg, Apache Hudi) ont le point commun de stocker la donnée en format parquet. Ce qui les diffère est leur façon de stocker les métadonnées.
UniForm permet de stocker les données une seule fois dans le Delta Lake et de les exposer à n’importe quel moteur compatible avec Delta Lake ou Apache Iceberg (et bientôt Apache Hudi).
UniForm reste une étape intermédiaire dans l’interopérabilité des formats. En effet, Databricks a racheté Tabular, qui a créé le format Apache Iceberg en 2024. Le but est, à terme, de faire converger ces deux formats de données vers un format unique, ce qui permettra une plus grande interopérabilité entre les différentes plateformes du marché.
Mosaic AI
Databricks a fait l’acquisition de la société MosaicML en 2023, une plateforme leader en IA générative.
Cette acquisition, en plus du background fortement teinté d’IA au sein de Databricks, a permis d'intégrer nativement à la plateforme un ensemble d’outils unifiés qui permettent de développer, déployer, évaluer et gérer des applications d’IA (du machine learning jusqu’à la GenAI).
Databricks fournit une “boîte à outils” complète pour un grand nombre de cas d’usages. On peut aussi bien faire un PoC de RAG rapidement, qu’un flow complexe de modèles de deep learning. On peut choisir les “morceaux” de cette boîte à outil en fonction de nos besoins et en s’interconnectant facilement avec d’autres fournisseurs de solutions.
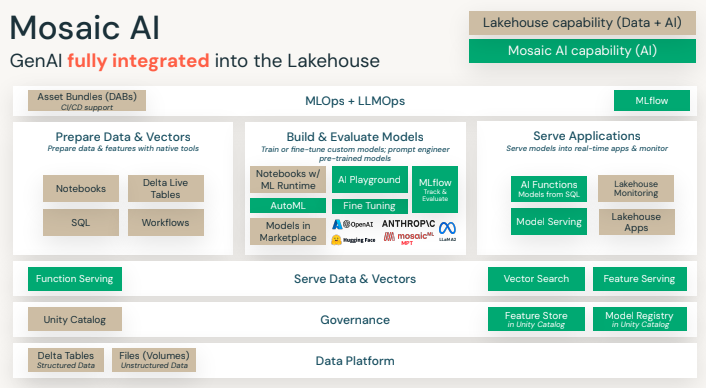
Nous allons maintenant voir quelques exemples d’outils fournis par Mosaic AI.
Mise à disposition des modèles d’IA et Model Serving
Les derniers modèles open-source sont disponibles directement dans le catalogue “system” et le schéma “ai” de Unity Catalog :
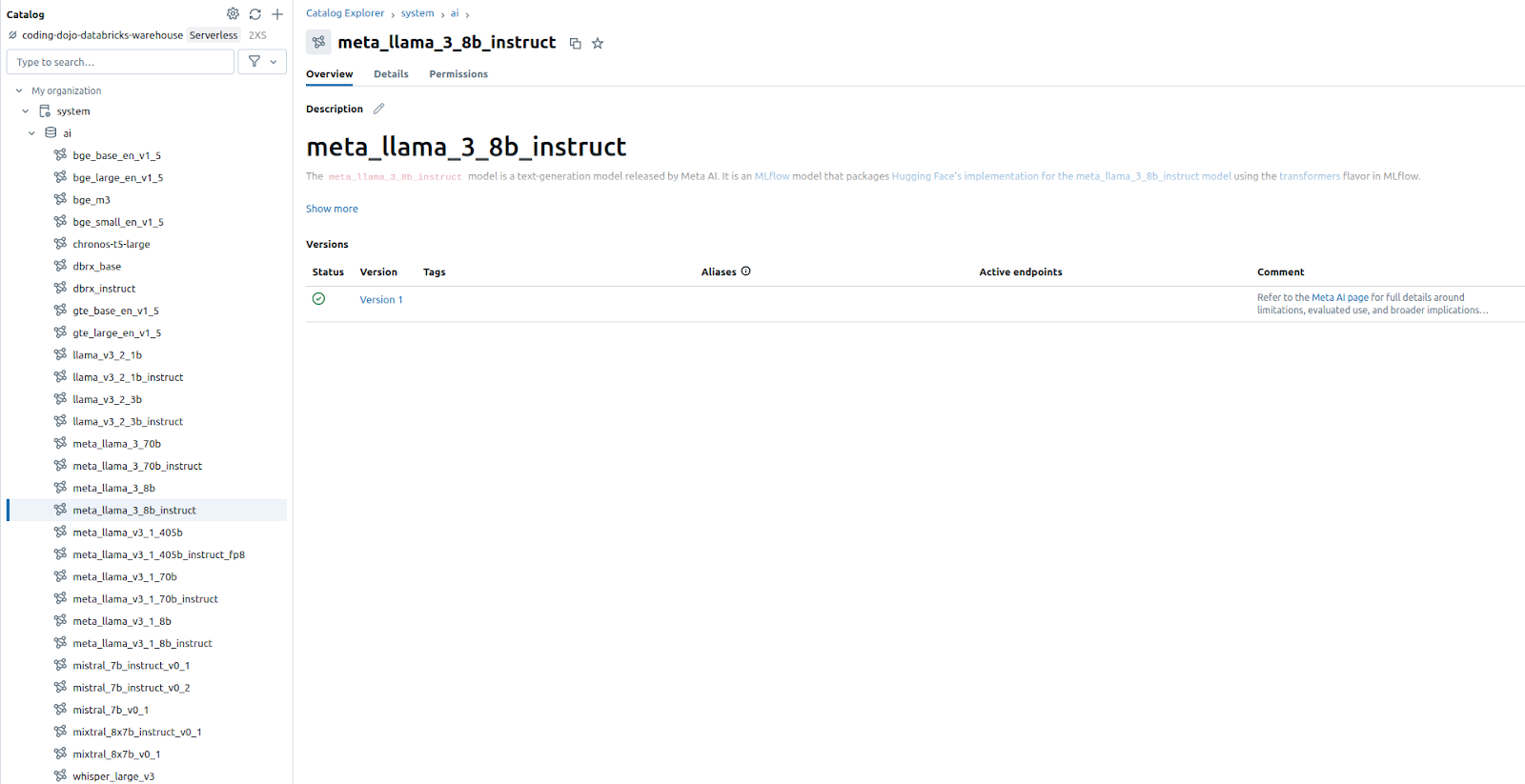
Cela facilite le model serving et le fine tuning de ces modèles.
L’interface “Model Serving” permet :
- de créer un serving endpoint pour un modèle,
- de requêter, en un seul endroit, n’importe quel modèle : que ce soit un modèle personnalisé, un modèle fondation open-source ou un modèle externe propriétaire.

AI Gateway
Au-dessus de Model Serving vient la couche AI Gateway, qui permet une seule gouvernance pour l’accès aux APIs de l’ensemble des modèles, y compris les modèles externes. Lorsqu’un serving endpoint est créé, on peut choisir les options du AI Gateway qui vont dicter les règles d’accès pour l’utilisation de ce modèle.

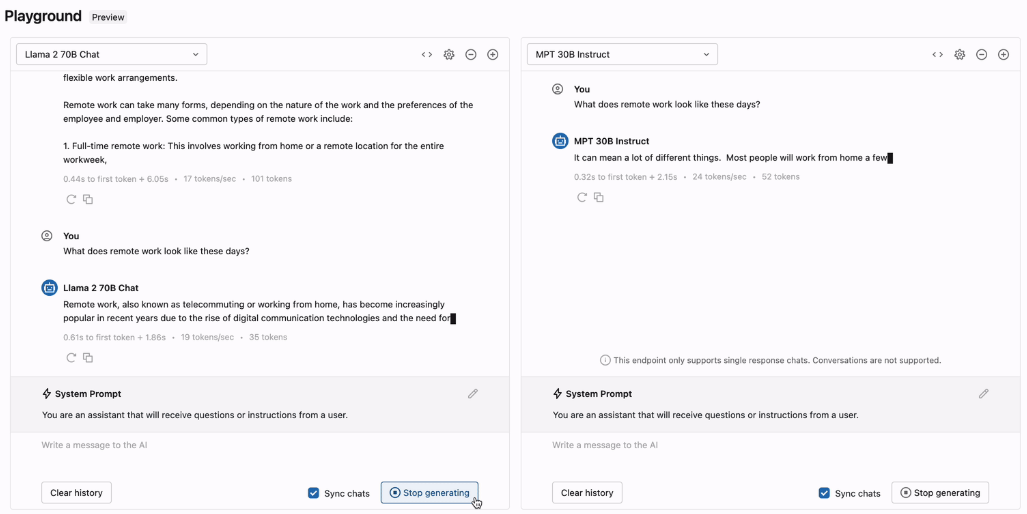
Playground
La fonctionnalité “Playground" permet de tester et comparer facilement différents modèles de LLMs au travers d’une interface de chat :
Compound AI systems
Les “Compound AI Systems” sont des systèmes d’IA qui associent différents composants qui interagissent entre eux. Par exemple, un RAG est un “Compound AI System”, puisqu’il utilise à la fois un modèle de LLM et un système d’extraction de données.
Cela permet de contrôler la logique d’un système sans avoir à développer des algorithmes d’IA “surpuissants” pour traiter tous les sujets.
Databricks dispose d’un “Agent Framework”, un framework qui intègre nativement les agents, qui permettent de développer rapidement une application RAG.
La fonctionnalité “Vector Search” permet d’indexer son corpus de documents dans une base de données vectorielle native à la plateforme Databricks. Il est intéressant de noter que l’alimentation de cette base de données peut se gérer de façon incrémentale.
“Tools Catalog” permet d’utiliser des fonctions (gouvernées par Unity Catalog) pour faire appel à un type de LLM ciblé. Par exemple, on peut créer différentes fonctions - reflétant un cas d’usage - et l’agent choisit l'outil approprié pour répondre (un appel à API, un appel à un modèle de LLM spécialisé pour exécuter la tâche en question…).
Evaluation du modèle
MLFlow peut être utilisé pour l’évaluation de n’importe quel modèle de GenAI tout comme il peut déjà le faire pour des modèles de machine learning ou de deep learning.
Des agents peuvent également être utilisés pour évaluer les modèles :
- de façon automatique avec la récupération de métriques,
- de façon manuelle en intégrant du feedback humain.
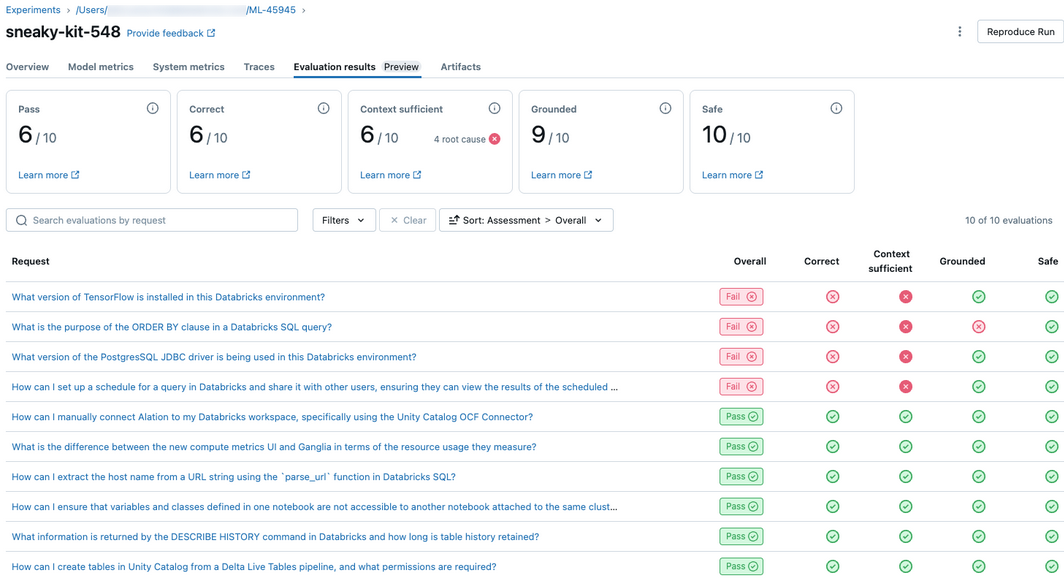
En effet, il y a une nouvelle fonctionnalité qui permet de visualiser l’évaluation de la réponse du LLM. Cette évaluation est réalisée par un autre LLM en se basant sur les critères suivants (cf. image ci-dessous) :
- Correctness : est-ce que la réponse est factuellement correcte ?
- Sufficient Context : est-ce qu’il y a assez de contexte dans la réponse ?
- Groundedness : est-ce que la réponse est ancrée dans le contexte de la question ?
- Safety : est-ce que la réponse ne contient pas des mots bannis, non safe pour les utilisateurs ?
Lakeflow
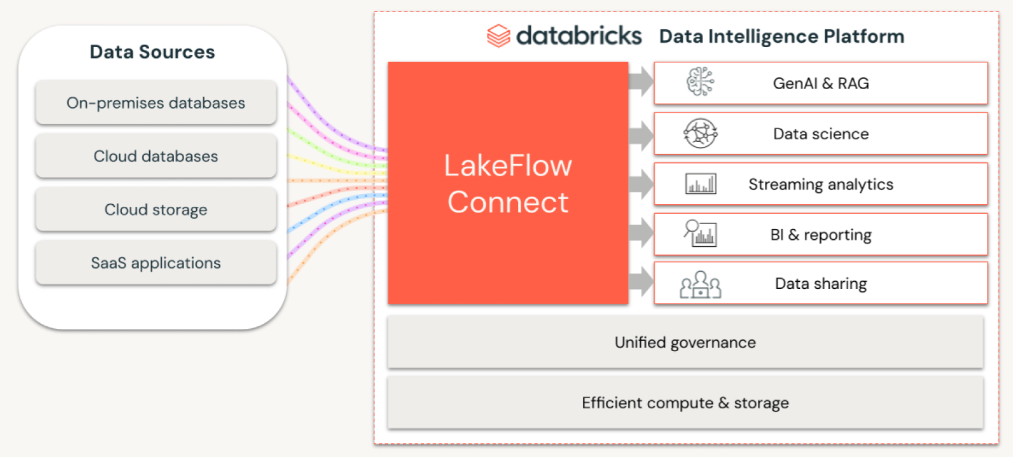
Lakeflow est un framework d’unification de l’ingestion, de la transformation et de l’orchestration. Il s’agit d’aller encore plus loin que les Delta Live Tables dans les services managés et que l’interface d’orchestration (Workflows).
A date, seul Lakeflow Connect (pour l’ingestion) est en preview, les autres briques LakeFlow Pipeline et Lakeflow Jobs sont encore en cours de développement chez Databricks, pour une sortie probable l’année prochaine.
Lakeflow Connect
Lakeflow Connect fournit des connecteurs d’ingestion complètement natifs et gérés par Databricks, ce qui facilite grandement l’ingestion des sources de données. En arrière-plan, il s’agit de pipelines Delta Live Tables qui tournent en serverless.
Ces connecteurs ont été construits suite à l’acquisition de la société Arcion par Databricks en 2023. Cette société est leader de la réplication de données en temps réel.
Ces connecteurs sont simples et sans maintenance :
- ils gèrent l’évolution des schémas,
- ils permettent de l’observabilité et des alertes,
- ils gèrent les erreurs et les retries,
- ils permettent le mapping de schémas,
- ils permettent de faire de l'échantillonnage,
- ils permettent de faire différent types de SCD.
Le renaming de schémas et le mapping de colonnes sont eux en cours de développement.
Ces connecteurs sont également complètement intégrés au lakehouse :
- ils sont intégrés à Unity Catalog et à Workflows,
- ils peuvent être utilisés pour les RAG,
- ils permettent une interface unique pour les pipelines,
- un seul compte est nécessaire pour gérer l’ensemble des ingestions.
L’incrémentalité est également gérée en lecture, en écriture et pour les transformations.
Les configurations de réseau sont natives (ingestion à l’intérieur d’un même VPC, Private Link par exemple).
Voici le résultat de l’ingestion dans Workflows :

Voici le statut actuel des connecteurs disponibles et à venir, sachant qu’ils sont sujets à d’éventuels changements :

Les performances attendues sont de l’ordre de 14 minutes pour ingérer 14 millions de lignes réparties sur 100 objets et 100 minutes pour ingérer 194 millions de lignes réparties sur 100 objets. Bien entendu, il s’agit d’un ordre de grandeur et cela peut varier en fonction des différents cas d’usage.
Pour aller plus loin, la documentation Databricks est disponible :
Data Democratization: Embracing Trusted Data to Transform Your Business https://www.databricks.com/blog/data-democratization-embracing-trusted-data-transform-your-business#:~:text=Data%20democratization%20gives%20the%20right,understand%20and%20use%20it%20properly.
Data Intelligence Platforms https://www.databricks.com/blog/what-is-a-data-intelligence-platform
MosaicAI https://www.databricks.com/product/machine-learning
AI Playground https://docs.databricks.com/en/large-language-models/ai-playground.html
Vector Search https://docs.databricks.com/en/generative-ai/vector-search.html
LakeFlow https://www.databricks.com/blog/introducing-databricks-lakeflow