

(Si vous préférez le format vidéo, nous avons présenté ce même sujet lors d'Android Makers. Vous pouvez visionner notre talk ici 🔗)
Tous les regards sont tournés vers l'IA, et le mobile n’y échappe pas ! Google se distingue une fois de plus avec son dernier modèle d'IA, Gemini ✨.
Mais Gemini qu’est-ce que c’est exactement ?
Et bien si vous connaissiez Bard vous pouvez lui dire adieu, car il devient Gemini (pour Generalized Multimodal Intelligence Network), une intelligence artificielle générative et multimodale de type transformer. Ce nouveau modèle de LLM a été annoncé lors de la conférence I/O en juin 2023 et présenté au public le 7 décembre 2023.
Notre intérêt s'est naturellement porté sur cette nouvelle IA parce que nous sommes impatients d'explorer et de comprendre son potentiel. Nous sommes particulièrement curieux de voir quels impacts peut avoir l’intégration d’une IA telle que Gemini dans le futur de nos applications.
Nous avons donc voulu mettre à l'épreuve l'idée d’embarquer Gemini, grâce au Google AI client SDK, directement dans une application Android pour découvrir tout ce qu’il est possible de faire en utilisant ce modèle. Vous pourrez, à travers cet article, voir en action les fonctionnalités disponibles dans le modèle Gemini 1.0 PRO ainsi que leurs méthodes associées.
L’API de Gemini n’est pas encore disponible en Europe, nous avons donc dû filouter pour vous proposer en avant-première un test de son intégration.
Informations générales sur Gemini 1.0
Langues :
Ce modèle prend en charge 38 langues.
SDK disponible :
Python, Android (Kotlin), Node.js, Swift et JavaScript sont supportés.
Données d’entraînements :
Les données fournies pour l'entraînement de Gemini s'arrêtent au début de l'année 2023. Les connaissances sur les événements postérieurs à cette date sont limitées.
Données personnalisées :
Le SDK client de Gemini ne permet pas l'entraînement du modèle avec des données personnalisées. Cependant, pour ajuster Gemini avec les données de votre propre entreprise, envisagez d'utiliser Vertex AI qui permet de personnaliser Gemini avec un contrôle total des données.
Android Min SDK :
Votre application Android doit viser l'API 21 ou supérieure.
Autre input :
Pour le moment, Gemini 1.0 PRO ne gère que le format texte et les images. Les modalités des inputs seront élargies pour Gemini 1.5 PRO afin d'inclure l'audio et la vidéo.
Pricing :
Parce que oui, il faut bien finir par parler du sujet qui fâche, donc voilà un récapitulatif des limitations imposées sur les requêtes en fonction du mode de paiement.
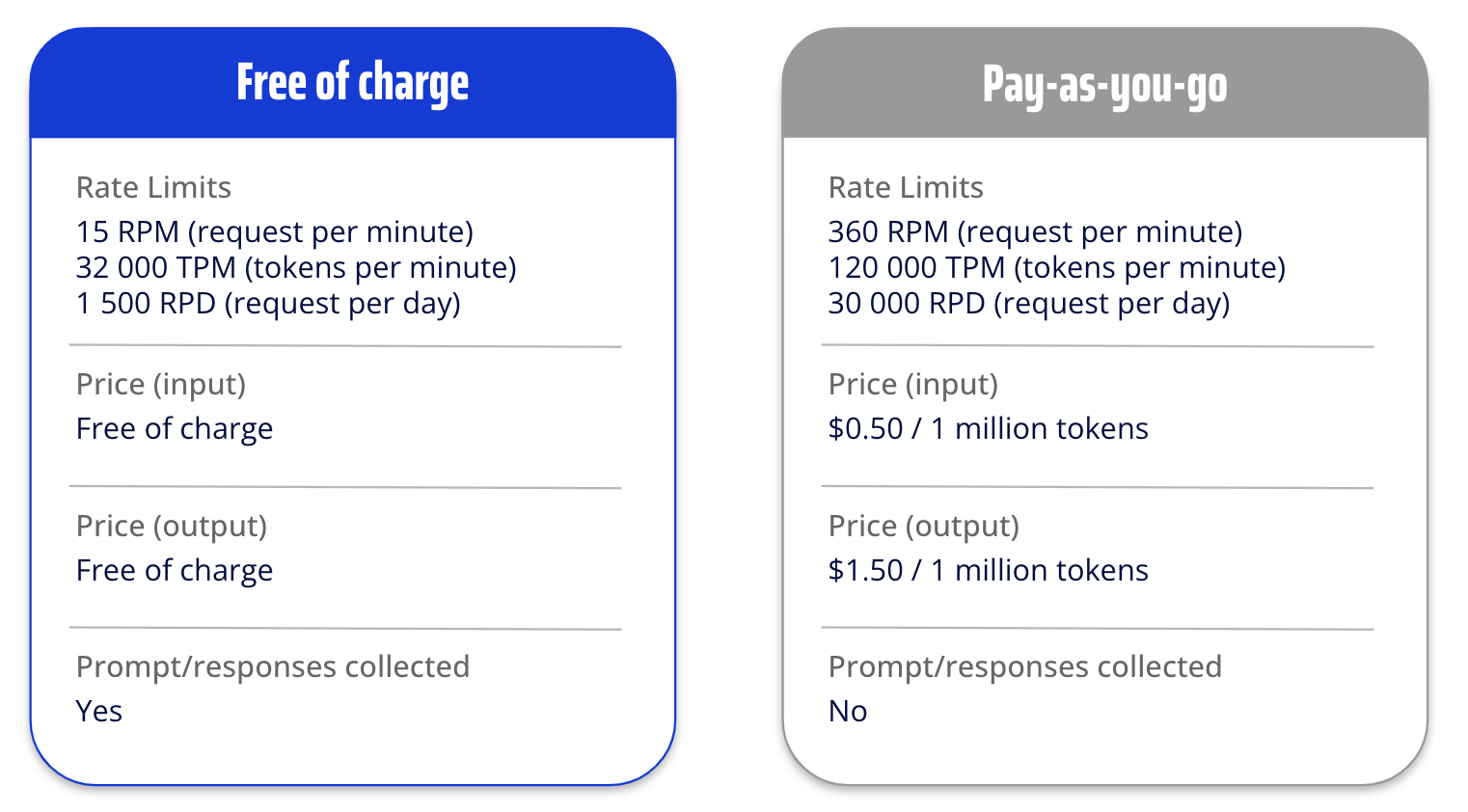
Création et intégration de Gemini dans un projet Android
On vous a convaincu et vous voulez, vous aussi, intégrer Gemini dans vos applications, ça tombe bien, on vous explique tout ici :
- La première étape si vous voulez tester Gemini sera de vous fournir un VPN. Vous pouvez choisir celui de votre choix tant que vous pouvez vous localiser dans un pays autre qu’en Europe. Nous sommes partis sur ProtonVPN pour son option gratuite (bien sûr, il existe d’autres fournisseurs qui vous permettront un accès limité, mais gratuit).
- La deuxième étape consiste à télécharger la version Preview d’Android Studio.
- Lancer ce nouvel Android Studio et créer un nouveau projet, puis sélectionner Gemini API Starter.

- Rendez-vous sur : https://ai.google.dev/ pour récupérer une clé d’API nécessaire pour avoir accès à l’API de Gemini dans votre application en cliquant sur “Get Gemini API key in Google AI Studio”.

- Puis cliquer sur “Get API key”.

- Enfin, cliquer sur “Create API key”.

- Plus qu’à copier cette clé généré.

- Et à l’insérer dans Android Studio et à cliquer sur Finish.

- Avoir la dernière version d’Android Studio.
- L’application doit viser l’API 21 ou plus.
Fonctionnalités du modèle Gemini à connaître
On a beaucoup abordé Gemini comme étant un modèle d’IA, mais c’est en réalité une famille de modèles d’IA générative. Dans Gemini 1.0 PRO on y retrouve donc 2 modèles, Gemini Pro et Gemini Pro Vision, qui comme on peut s’en douter, ont des différences assez significatives, et notamment dans le type de contenu qu’ils peuvent prendre en entrée (input). En effet, Gemini Pro Vision peut générer du contenu textuel à partir d’une image donnée et du texte, contrairement à Gemini Pro qui ne gère que les prompts textuels.
Et depuis peu, on peut aussi retrouver Gemini 1.5 PRO et Gemini 1.5 Flash que nous n’aborderons pas dans cet article.
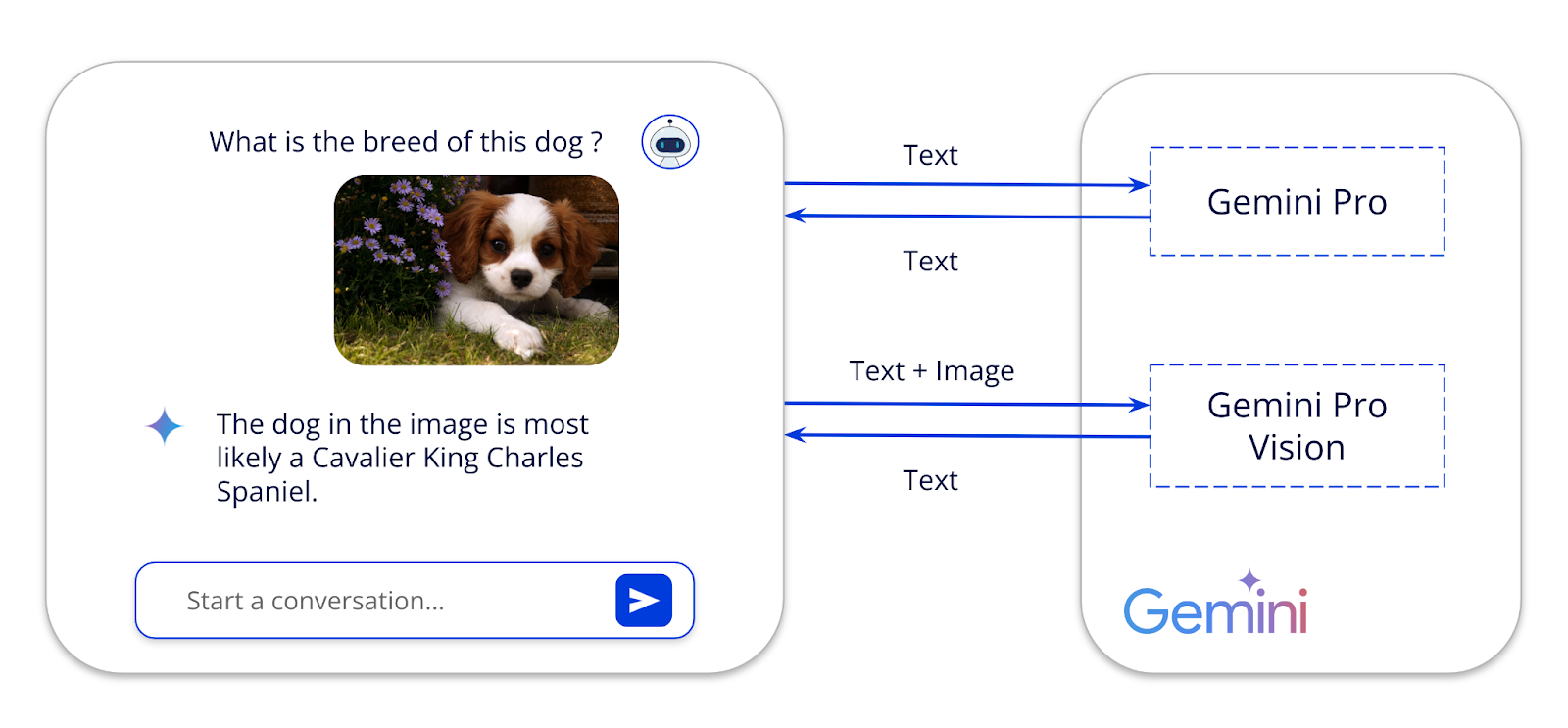
Pour bien comprendre, ce qu’offre le SDK de Google, nous allons passer en revue les différentes méthodes mis à notre disposition :
generateContent(inputContent)
Prend en paramètre un input et retourne le contenu généré par Gemini.
Gemini Pro: Ne gère que le texte en input.

Gemini Vision Pro: Gère le texte et l’image en input.

generateContentStream()
Au même comportement que generateContent(), sauf que l’on va recevoir une diffusion continue de réponses partielles.
startChat()
Permet d’initialiser une conversation à plusieurs tours (un chat autrement dit).
sendMessage()
Permet d'envoyer et d’ajouter à la conversation (au chat) un message entré par l’utilisateur.
sendMessageStream()
Au même comportement que sendMessage(), sauf que l’on va utiliser une diffusion continue pour un chat.
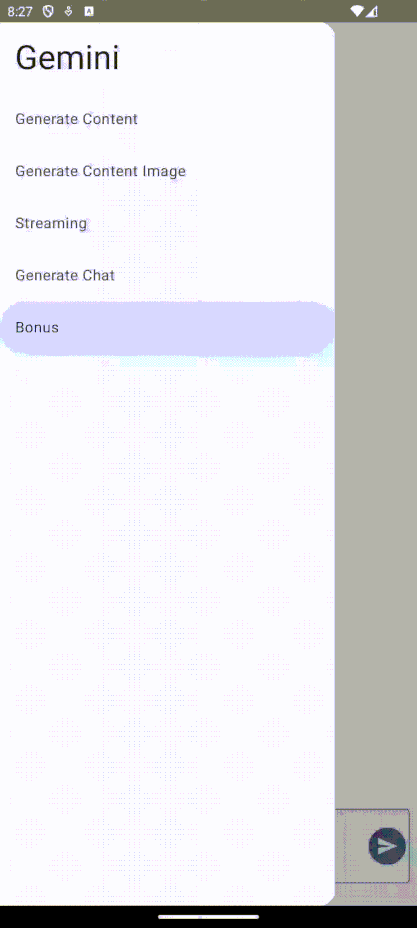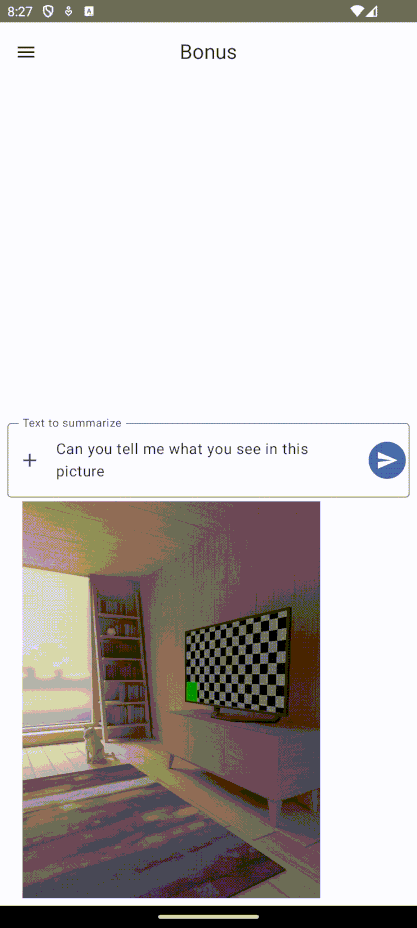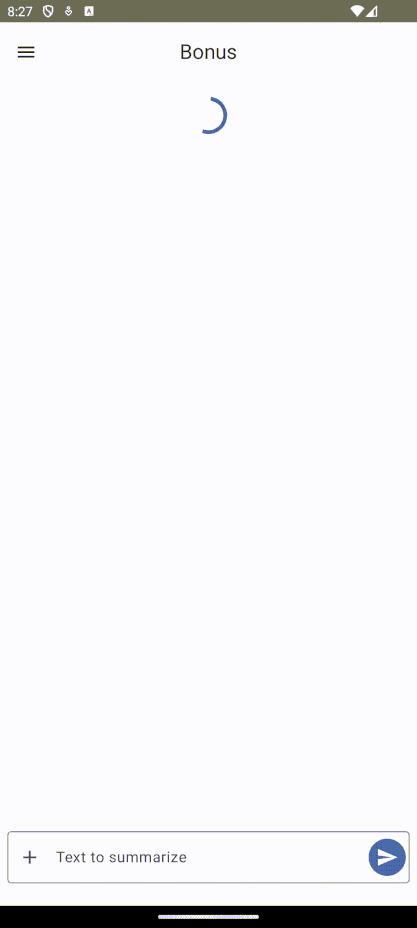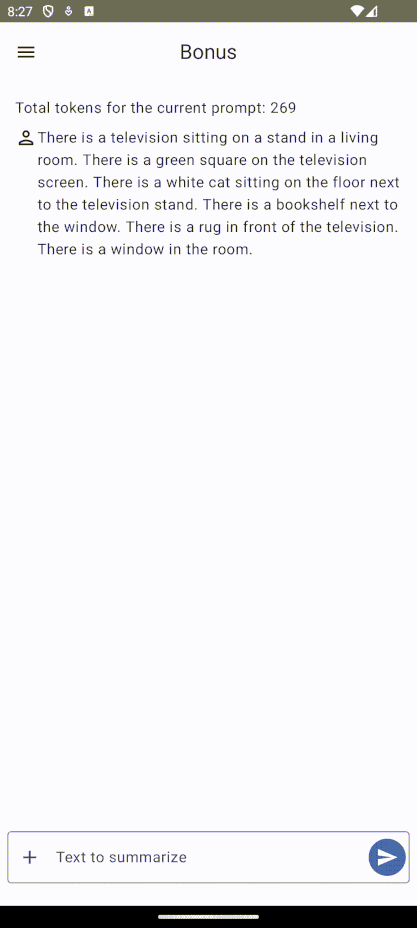
countTokens()
Permet de compter le nombre de tokens d’un prompt, ce qui permet de générer des réponses plus précises et concises, mais également de gérer le budget de tokens.
On peut aussi contrôler la génération de contenu et les niveaux de sécurité des réponses en changeant les paramètres de configuration du modèle. Pour en savoir plus, on vous redirige sur la documentation des Model parameters et des Safety settings.
Vous pouvez retrouver plus d’informations sur les fonctionnalités du modèle Gemini directement dans la documentation.
Le projet de démonstration présent dans cette partie est disponible ici 🔗.
Notre retour d’expérience
Dans le cadre de notre découverte et de la rédaction de cet article, nous avons réalisé un projet visant à tester les modèles Gemini en développant une application chatbot complète. Si cela vous intéresse, vous pouvez retrouver ce projet sur ce GitHub.
👍 Ce qu’on a aimé :
- Super facile à comprendre, à configurer et à intégrer, il y a peu d’étapes et de démarches pour créer un nouveau projet avec Gemini ou pour l’ajouter dans un projet déjà existant.
- Pas besoin d’être un.e expert.e en IA pour manipuler le SDK et ses modèles.
- Permet de gagner du temps si on a comme projet d’intégrer une IA générative dans nos applications, comme avec un chatbot par exemple.
👎 Ce qu’on a pas trop aimé :
- Lorsque l’on utilise le modèle Gemini Pro Vision, on est obligé d’avoir au moins une image dans notre prompt sinon on va recevoir une erreur. Il faut donc faire attention au modèle que l’on utilise en fonction de l’input.
- Le SDK Gemini n’est pas encore disponible en Europe ce qui fait que l’on a dû passer par un VPN pour y avoir accès et pouvoir faire ces tests, ce qui le rend difficilement accessible pour le moment.
- C’est un modèle et une technologie en constante évolution il faut donc rester à jour si l’on veut se servir de Gemini dans nos applications afin de pouvoir s’adapter aux changements.
Conclusion
Voilà, maintenant Gemini n'a plus de secret pour vous ! Vous pouvez, vous aussi, embarquer une IA générative directement dans votre application sans avoir une équipe d'experts data à vos côtés. Si ça, ce n'est pas génial 🤖.
Petit rappel au passage, lorsqu'on fait appel à une IA générative, il est important d'accorder une attention particulière au Prompt design, c'est-à-dire au processus de créer un prompt qui explicite la réponse attendue. En effet, rédiger des Prompt bien structurés est un élément essentiel si on veut s’assurer de la qualité des réponses du modèle et si l'on souhaite obtenir des résultats qui soient aux plus proches de nos attentes. Si vous êtes en manque d’inspiration, pas d’inquiétude, retrouvez des idées de prompt directement dans la documentation de Gemini: https://ai.google.dev/gemini-api/prompts.

