

Dans l'univers en constante évolution de l'apprentissage automatique, la mise en production des modèles de machine learning (ML) est cruciale. Le Machine Learning Operations, ou MLOps, systématise et optimise leur déploiement, gestion et maintenance. Cet article détaille le cycle de vie complet d'un produit basé sur l'apprentissage automatique, depuis la collecte initiale des données jusqu'à l'automatisation des pipelines CI/CD, en incluant le développement, l'entraînement et la surveillance des modèles.
Collecte et préparation des données
La première étape consiste à collecter et préparer les données nécessaires au développement de modèles de machine learning. Cette phase implique l'identification et l'intégration de sources de données variées, mais également leur nettoyage, prétraitement et l'ingénierie des données. Ces étapes sont essentielles pour garantir la qualité et la pertinence des données face au problème spécifique à résoudre.
La préparation des données est un processus itératif et agile pour explorer, combiner, nettoyer et transformer les données brutes en ensembles de données organisés pour l'intégration de données, la data science et les cas d'utilisation en analytique/intelligence d'affaires. Cette phase de préparation, bien que seulement intermédiaire, est souvent la plus coûteuse en termes de ressources et de temps, en raison de son importance pour prévenir la propagation d'erreurs et la distorsion des insights obtenus.
Pour comprendre l'impact des biais sur les données, examinons quelques exemples courants en ML :
Biais de sélection: Ce biais se manifeste lorsque les ensembles de données d'entraînement ne représentent pas correctement la diversité de la population cible. Par exemple, si un modèle de reconnaissance de marques de voiture est entraîné principalement avec des images de voitures d’un certain fabricant, il peut mal identifier les voitures d’autres marques.
Biais de confirmation : Ce biais survient lorsqu'on choisit des features qui confirment une hypothèse préexistante, compromettant la généralisabilité du modèle.
Biais de mesure : Des capteurs calibrés différemment peuvent amener un modèle à apprendre des erreurs de mesure plutôt que des tendances réelles, comme par exemple un diagnostic médical basé sur l'équipement d'un hôpital spécifique au lieu des symptômes réels.
Le pipeline d'ingénierie des données:
Après avoir détaillé le processus initial de collecte et de préparation, le pipeline d'ingénierie des données nous conduit à travers des étapes pour transformer les données brutes en formats exploitables, assurant ainsi que les modèles de machine learning puissent être entraînés de manière efficace.
Cette dernière comprend plusieurs étapes:
- Ingestion des données : Cette première étape consiste à collecter des données via différents cadres et formats. Elle peut également inclure la génération de données synthétiques ou l'enrichissement des données existantes.
- Exploration et validation : Cette étape inclut le profilage des données pour obtenir des informations sur le contenu et la structure des données. Le résultat de cette étape est un ensemble de métadonnées, telles que les valeurs maximales, minimales et moyennes.
- Nettoyage des données : Ce processus implique la reformatage de certains attributs et la correction des erreurs dans les données, comme l'imputation des valeurs manquantes.
- Étiquetage des données : À cette étape, chaque point de données est classé dans une catégorie spécifique, essentielle pour la formation de modèles supervisés.
- Division des données : La division des données en ensembles d'entraînement, de validation et de test est cruciale pour tester et valider le modèle durant les étapes clés de l'apprentissage machine.
La préparation des données est fondamentale pour la qualité des modèles de machine learning développés, mais aussi pour l'efficacité globale du processus de MLOps, en garantissant que chaque étape ultérieure repose sur une base de données solide et fiable.
Développement et entraînement du modèle
Une fois les données collectées et préparées, nous entrons dans le cœur du workflow de machine learning : le développement du modèle par les data scientists. Cette étape cruciale implique la sélection de l'algorithme de machine learning approprié et l'ajustement de ses paramètres, un processus connu sous le nom de tuning des hyperparamètres, pour optimiser les performances du modèle. Le modèle est ensuite entraîné à l'aide des données préparées, une phase qui intègre également le feature engineering pour mieux exploiter les informations disponibles. Après l'entraînement, le modèle subit une série d'évaluations pour s'assurer qu'il répond aux objectifs initialement définis.
La dernière étape du processus de développement est l'empaquetage du modèle. Le modèle ML final est exporté dans un format spécifique (par exemple, PMML, PFA, ou ONNX) permettant ainsi son intégration facile. Cette standardisation assure que le modèle peut être facilement déployé et utilisé par des applications sans nécessiter de modifications ou de configurations spécifiques.
En somme, le développement et l'entraînement du modèle dans le cadre du MLOps ne se limite pas à la création d'un algorithme, il englobe une suite complète d'opérations pour garantir que le modèle est prêt à être déployé de manière efficace et fiable.
Déploiement et surveillance du modèle
Après le développement et l'entraînement, le modèle de machine learning doit être déployé en production pour réaliser des prédictions sur de nouvelles données. Ce processus comprend le packaging du modèle et de ses dépendances, ainsi que son déploiement sur une plateforme choisie.
Une fois en production, le modèle doit être constamment surveillé pour assurer son bon fonctionnement et détecter tout problème potentiel. Nous faisons référence ici au monitoring, un des piliers principaux du ML Ops, dont il est question en détail sous cet article.
Pour faciliter le déploiement et le suivi efficace des modèles en production, plusieurs outils sont essentiels. Le model registry est important pour gérer les différentes versions du modèle déployé, permettant de suivre, de comparer et potentiellement de revenir à des versions antérieures si nécessaire. En parallèle, un méta store documente les métadonnées associées aux différentes exécutions de la pipeline, facilitant ainsi la traçabilité et la reproductibilité des modèles. Un autre outil est le feature store, qui centralise et gère les caractéristiques des données utilisées pour l'entraînement et l'inférence, assurant la cohérence et la qualité des données à travers les différents modèles. Enfin, l'intégration de triggers ou déclencheurs automatiques est importante pour initier le réentraînement des modèles en réponse à des changements dans les données ou les performances.
Ces composantes conjuguées - model registry, metastore, feature store, et triggers - garantissent que le modèle reste performant dans un environnement de production dynamique, et assurent également une gestion optimisée des ressources data et modèle.
Qu’est ce qu’un model registry?
Un registre de modèles ou model registry est un système centralisé qui gère les différentes versions des modèles de machine learning. C'est un composant essentiel pour orchestrer le déploiement et la maintenance efficace des modèles en production. Voici une description plus détaillée des fonctionnalités clés d'un registre de modèles :
- Versionnement des modèles : Il conserve un historique de toutes les versions d'un modèle, permettant un retour facile à des versions antérieures si nécessaire.
- Gestion du cycle de vie : Le registre facilite la gestion de tout le cycle de vie des modèles, depuis leur création jusqu'à leur déploiement en production et leur éventuel retrait.
- Accès et permissions: Il contrôle qui peut accéder aux modèles en fonction des rôles des utilisateurs, assurant que seules les personnes autorisées peuvent apporter des modifications, déployer ou retirer un modèle.
- Audits et conformité: Il offre un historique complet des modifications, des déploiements et des performances des modèles, chose importante pour les audits internes et la conformité réglementaire.
- Simplification du déploiement: Avec un registre de modèles, le déploiement de modèles en production est simplifié grâce à la standardisation des processus de déploiement à travers des interfaces bien définies.
Qu’est ce qu’un méta store?
Un metastore ML, est un système centralisé conçu pour enregistrer et gérer les métadonnées associées aux divers processus d'un pipeline de machine learning. Ce système joue un rôle crucial dans la gestion des workflows de ML en facilitant la traçabilité, la reproductibilité et la comparaison des données et des artefacts à travers le temps. Voici une définition plus détaillée de ce que comprend un metastore ML :
- Enregistrement des versions : Le metastore ML conserve les informations sur les versions des pipelines et des composants exécutés.
- Suivi temporel : Il enregistre les dates et heures de début et de fin des exécutions, ainsi que la durée nécessaire pour accomplir chaque étape du pipeline. Cette fonctionnalité est essentielle pour optimiser les performances du pipeline et identifier les goulots d’étranglement.
- Détails de l'exécution : Le metastore documenté qui a exécuté le pipeline et avec quels paramètres.
- Gestion des artefacts : Il stocke des pointeurs vers les artefacts produits par chaque étape du pipeline, tels que l'emplacement des données préparées, les résultats des validations et les statistiques calculées. Cette gestion permet de reprendre le pipeline à partir de la dernière étape complétée en cas d'interruption, sans nécessiter de réexécuter les étapes précédentes.
- Références aux modèles : Le metastore peut également conserver des références au modèle entraîné lors de sessions précédentes, ce qui facilite le rollback à des versions antérieures du modèle.
- Comparaison des performances : Enfin, il enregistre les métriques d'évaluation pour les modèles sur les ensembles d'entraînement et de test.
Qu’est ce qu’un feature store ?
Un feature store, est une plateforme centralisée qui sert à standardiser la définition, le stockage et l'accès aux features (attributs) utilisées pour l'entraînement et l'inférence des modèles de ML. Ce système offre une interface qui permet la récupération rapide des features pour les besoins d'inférence en temps réel ou par batchs, ainsi que pour les processus d'entraînement des modèles.
Le feature store apporte de nombreux avantages aux data scientists et aux équipes de ML :
- Réutilisation des features : Il permet aux utilisateurs d'identifier et de réutiliser des ensembles de features existants, évitant ainsi la nécessité de redéfinir ou de recréer des features similaires pour chaque nouveau projet.
- Uniformité: En centralisant les features et leurs métadonnées, le feature store aide à maintenir une uniformité à travers les différents modèles et applications.
- Distribution efficace des données : Il assure la diffusion des features les plus récentes, garantissant que toutes les applications et modèles utilisent les données les plus à jour pour leurs calculs.
- Cohérence entraînement/inférence : Le feature store sert de source unique de données lors des phases d'entraînement et d'inférence, assurant ainsi une cohérence entre les environnements de développement et de production. Cette approche prévient les écarts potentiels entre les performances du modèle lors de l'entraînement et de l'inférence, un phénomène souvent causé par des différences dans les données utilisées dans ces deux phases.
- Facilitation des tests et de l'entraînement continu : Les data scientists peuvent extraire des échantillons de données du feature store pour tester de nouvelles idées ou configurations sans affecter les systèmes en production. Pour l'entraînement continu, le pipeline peut automatiquement accéder aux caractéristiques mises à jour, permettant des ajustements dynamiques basés sur les nouvelles données collectées.
Qu’est ce qu’un trigger de pipeline ML?
Un trigger est un mécanisme qui déclenche automatiquement une action spécifique dans le pipeline, comme le réentraînement d'un modèle, en fonction de certains critères ou conditions prédéfinis. Voici quelques exemples courants de situations qui peuvent activer un trigger dans un système de ML :
- À la demande : Un trigger manuel est activé par un utilisateur ou un processus qui exécute ponctuellement le pipeline de ML.
- Selon un programme : Ce type de trigger est basé sur une planification prédéfinie, où le pipeline est configuré pour se réexécuter à des intervalles réguliers (quotidiens, hebdomadaires, mensuels).
- En fonction de la disponibilité de nouvelles données : Ce trigger lance le réentraînement du modèle lorsque de nouvelles données d'entraînement deviennent disponibles.
- En fonction de la dégradation des performances du modèle : Si une baisse significative des performances du modèle est détectée, par exemple par une diminution de la précision ou de la performance en production suite à un drift des données, un trigger peut automatiquement initier un réentraînement pour maintenir l'efficacité du modèle.
- En fonction de changements significatifs dans la distribution des données : Si des modifications importantes sont observées dans la distribution des données utilisées pour les prédictions, indiquant que le modèle pourrait devenir obsolète, un trigger peut être activé pour réentraîner le modèle sur de nouvelles données afin de corriger cette dérive et améliorer l'adaptabilité du modèle aux nouvelles conditions.
Automatisation du pipeline CI/CD
Pour permettre l'intégration et la livraison continue dans le ML Ops, il est essentiel d'automatiser le processus. Cela implique la mise en place d'un pipeline CI/CD, qui est un flux de travail automatisé facilitant la livraison du logiciel de la source à la production. Les étapes typiques de ce pipeline incluent la mise à jour du code source, la compilation du code avec ses dépendances, l'exécution de tests automatisés pour valider la fonctionnalité du code, et le déploiement final du logiciel en production après réussite de tous les tests.
L'objectif est d'intégrer et de déployer efficacement toutes les mises à jour des modèles, assurant ainsi une mise à jour et une amélioration continue des modèles déployés. Les modèles de machine learning, en particulier, nécessitent une attention particulière car ils peuvent se dégrader en précision ou ne pas s'adapter aux changements dans les données.
Le système CI/CD englobe plusieurs composants essentiels, chacun jouant un rôle important dans le processus d'intégration et de livraison continues pour le machine learning :
- Contrôle des sources : Gestion de la version du code source et suivi des modifications.
- Testing: Automatisation des tests pour assurer la qualité du code et construction des artefacts nécessaires pour le déploiement.
- Services de déploiement : Mécanismes pour déployer automatiquement les modèles et les applications dans divers environnements de production ou de test.
- Model registry : Centralisation de la gestion des différentes versions des modèles de machine learning.
- Feature store : Stockage et gestion centralisés des features utilisées pour l'entraînement et l'inférence.
- Méta store : Conservation des informations détaillées sur les processus d'entraînement et les performances des modèles.
- Orchestrateur de pipeline de ML : Automatisation et coordination des différentes étapes du pipeline de machine learning, de l'entraînement à la mise en production.
Ces outils facilitent non seulement le développement et l'expérimentation mais aussi l'intégration et la livraison continues du pipeline, le déclenchement automatisé des réentraînements et des déploiements, ainsi que la surveillance continue de la performance.
Le schéma suivant montre la mise en œuvre de la pipeline ML avec intégration CI/CD:
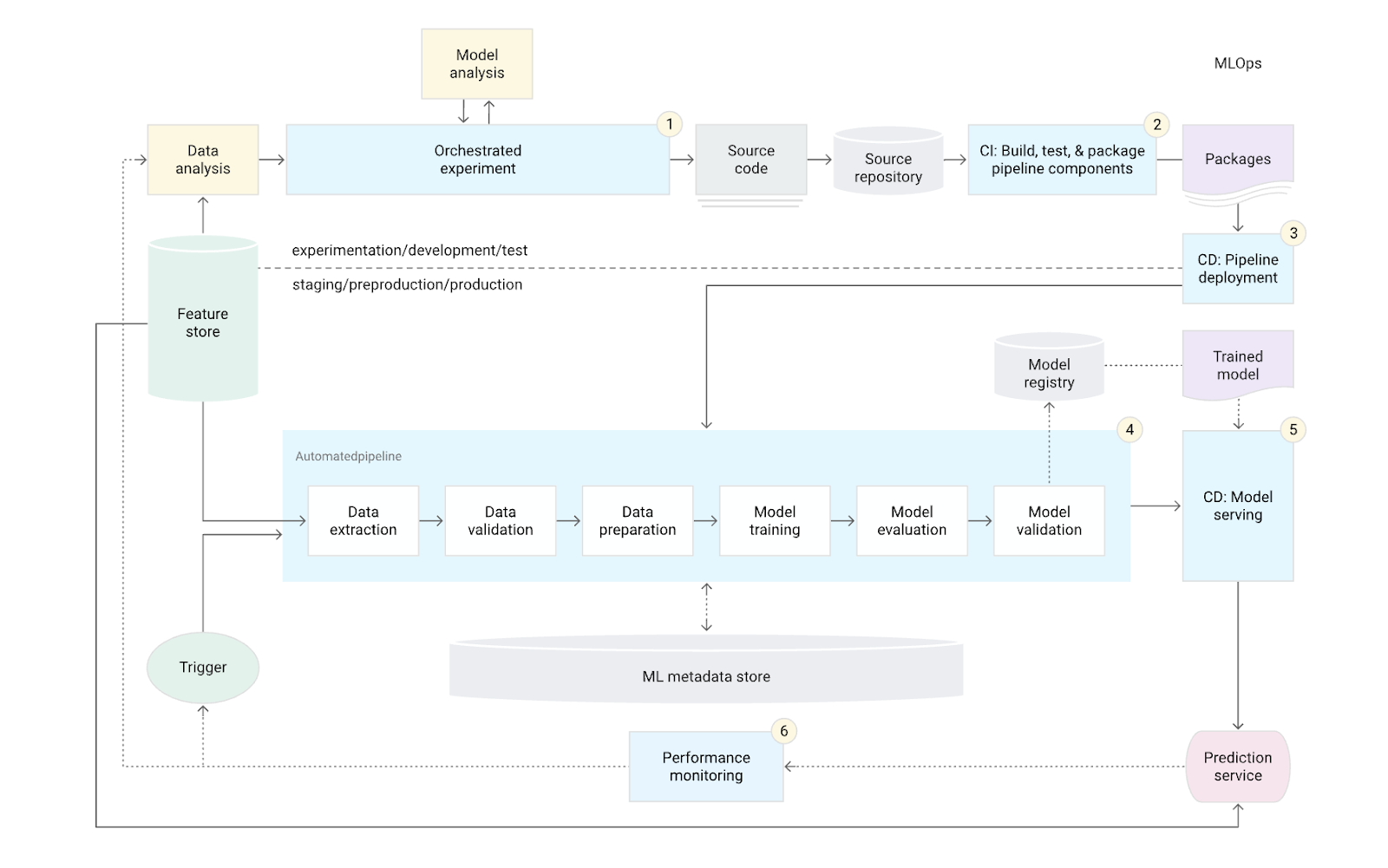
source: https://cloud.google.com/
Le diagramme ci-dessous illustre les étapes du pipeline de machine learning, intégrant des routines automatisées de CI/CD :
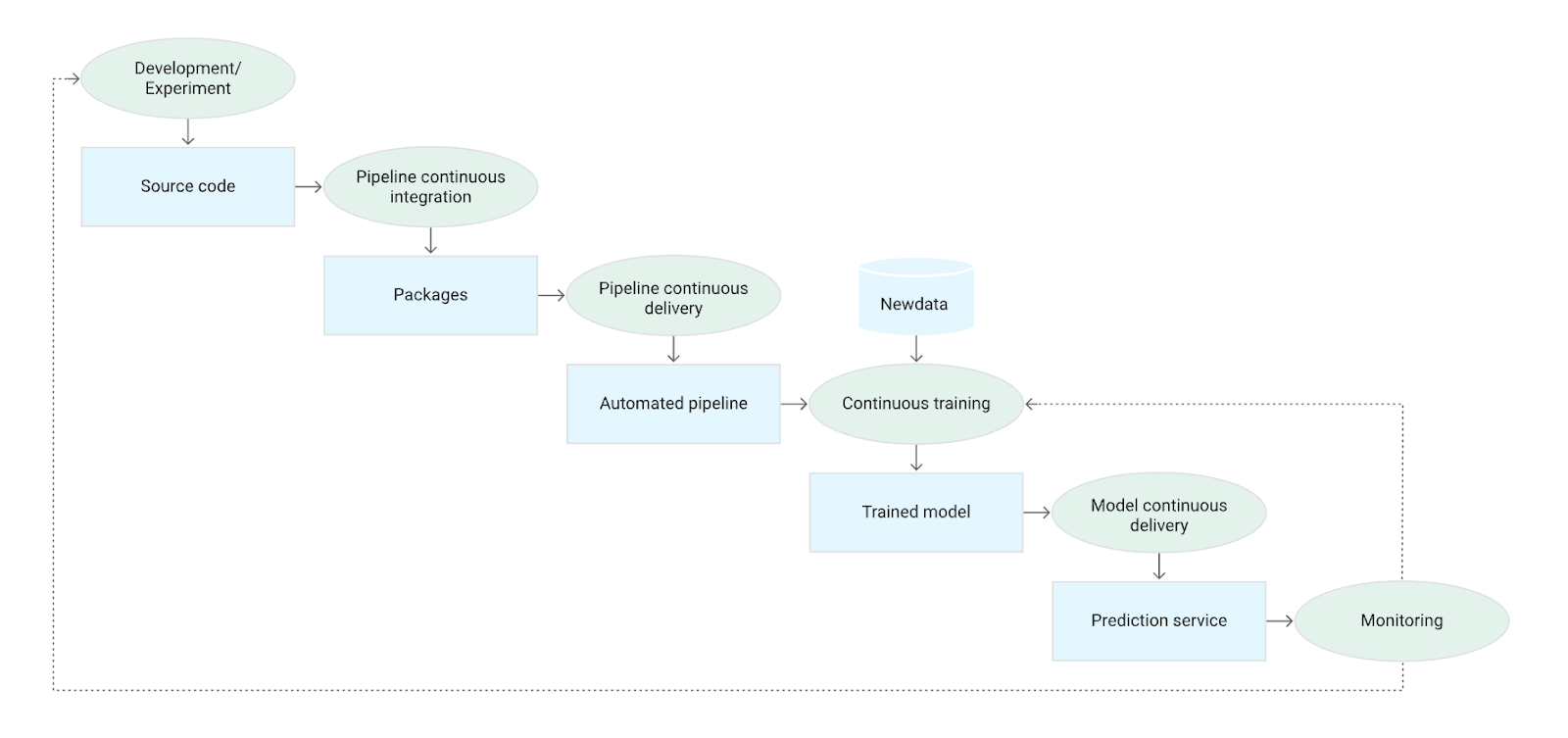
source: https://cloud.google.com/
Ainsi nous pouvons observer les différentes étapes du cycle de vie d’un produit ML dans le cadre du ML Ops, du début de l’expérimentation à l’automatisation du pipeline CI/CD.
Le ML Ops n'est pas seulement une extension des pratiques de développement logiciel classiques ; il intègre des techniques spécifiques au machine learning pour améliorer la fiabilité, la scalabilité et l'efficacité des systèmes d'intelligence artificielle. En suivant le cycle de vie complet d'un produit ML, depuis la préparation des données jusqu'à l'intégration et la livraison continues, les entreprises peuvent s’assurer que leurs modèles de machine learning restent performants et pertinents.