

dbt (data build tool) est un outil qui permet de transformer les données en exécutant des requêtes SQL directement sur un Data Warehouse. Pour plus d’informations sur le fonctionnement d’un projet dbt, je vous conseille l’article d’Arnaud Col : Découvrir dbt !
dbt possède une version hébergée : dbt Cloud, une interface web intuitive qui contient un IDE pour le développement. Elle permet de gérer directement ses projets Git et d’orchestrer ses jobs. Cependant, dbt Cloud a un coût (si plus d'un utilisateur) et l’évolution récente du modèle de pricing peut amener à se poser des questions quant à son utilisation. L’outil de CI/CD de GitHub, GitHub Actions, permet de déployer dbt et de s’abstraire en partie de dbt Cloud. Nous allons donc voir, à travers cet article, comment orchestrer ses jobs dbt avec cet outil. Pour plus de détails sur l’utilisation de Github Actions et la construction des workflows, je vous invite à consulter l’article de Timothée Aufort : GitHub Actions en … action !
L’ensemble du code présenté ci-dessous se trouve sur ce repository GitHub.
Pré-requis
Configurer son IDE
Puisque l’on se passe de dbt Cloud, il faut avoir un IDE correctement configuré pour pouvoir utiliser dbt. La configuration de l’IDE pour dbt n’est pas très intuitive donc je vous conseille l’article de Jérémy Nadal pour configurer VSCode : Passer de dbt Cloud à VSCode.
Configurer un dbt profile
Créer un fichier profiles.yml dans un répertoire .dbt_profiles (vous pouvez choisir n’importe quel nom, ou même le mettre à la racine, mais vous aurez besoin de l’emplacement plus tard). Ce fichier contient les informations de votre Data Warehouse et permet la connexion à celui-ci à chaque run de dbt.
project_name: #Changer pour le nom de votre projet
target: dev #Target par défaut
outputs:
dev:
account: "{{env_var('SNOWFLAKE_ACCOUNT')}}"
database: "{{env_var('SNOWFLAKE_DATABASE_DEV')}}"
password: "{{env_var('SNOWFLAKE_PASSWORD_DEV')}}"
role: "{{env_var('SNOWFLAKE_ROLE_DBT_DEV')}}"
schema: "{{env_var('DEV_SCHEMA_NAME')}}"
threads: 4
type: snowflake
user: "{{env_var('SNOWFLAKE_USER_DBT_DEV')}}"
warehouse: "{{env_var('WAREHOUSE_DEV')}}"
prod:
account: "{{env_var('SNOWFLAKE_ACCOUNT')}}"
database: "{{env_var('SNOWFLAKE_DATABASE_PROD')}}"
password: "{{env_var('SNOWFLAKE_PASSWORD_PROD')}}"
role: "{{env_var('SNOWFLAKE_ROLE_DBT_PROD')}}"
schema: "{{env_var('PROD_SCHEMA_NAME')}}"
threads: 4
type: snowflake
user: "{{env_var('SNOWFLAKE_USER_DBT_PROD')}}"
warehouse: "{{env_var('WAREHOUSE_PROD')}}"
ci:
account: "{{env_var('SNOWFLAKE_ACCOUNT')}}"
database: "{{env_var('SNOWFLAKE_DATABASE_DEV')}}"
password: "{{env_var('SNOWFLAKE_PASSWORD_DEV')}}"
role: "{{env_var('SNOWFLAKE_ROLE_DBT_DEV')}}"
schema: "{{env_var('PR_SCHEMA_NAME')}}"
threads: 4
type: snowflake
user: "{{env_var('SNOWFLAKE_USER_DBT_DEV')}}"
warehouse: "{{env_var('WAREHOUSE_DEV')}}"
Si vous utilisez un autre warehouse que Snowflake, changez les paramètres en fonction de celui-ci.
Une target par environnement est définie dans le fichier. Si vous avez des environnements supplémentaires, il faut ajouter des targets dans le fichier avec les paramètres correspondants. La target par défaut est définie comme dev. Pour lancer sur une autre target, il faut utiliser la commande dbt run --target target_name.
Maintenant que tout est configuré et que vous avez construit vos premiers modèles sql, voyons comment déployer dbt !
Déployer dbt
La première étape va être de tester le code dbt lors de chaque pull request pour vérifier que tout fonctionne correctement et comme attendu avant de merger. Le premier workflow pr.yml, qui doit être mis dans le dossier .github/workflows du projet, va ressembler à ceci :
name: CI_PR
run-name: ${{ github.actor }} lints & tests
on:
pull_request:
branches:
- main
jobs:
lint_dbt:
name: lint_dbt
runs-on: ubuntu-latest
steps:
- name: Checkout code
uses: actions/checkout@v2
- uses: ./.github/actions/install-python
with:
RequirementFilePath: ./requirements.txt
- name: Linting
run: |
sqlfluff lint --dialect snowflake
test_ci:
name: test_dbt_ci
runs-on: ubuntu-latest
env:
SNOWFLAKE_PASSWORD_DBT_DEV: ${{ secrets.SNOWFLAKE_PASSWORD_DBT_DEV }}
DBT_ENV_SECRET_GIT_TOKEN: ${{ secrets.DBT_ENV_SECRET_GIT_TOKEN }}
steps:
- name: Checkout code
uses: actions/checkout@v2
- uses: ./.github/actions/install-python
with:
RequirementFilePath: ./requirements.txt
- name: Integration tests
env:
PR_SCHEMA_NAME: DBT_CI_${{ github.event.number }}
DBT_PROFILES_DIR: ${{ vars.DBT_PROFILES_DIR }}
run: |
dbt deps --target ci
dbt seed --full-refresh --target ci
dbt run --target ci
dbt test --target ci
Le workflow est déclenché lors de chaque pull request vers la branche main (et se relance lors de chaque nouveau push sur la branche tant que la pull request est ouverte).
Il se constitue de deux jobs différents :
- un premier de linting pour vérifier la syntaxe du code sql,
- un second pour effectuer des tests sur les données.
Les variables d’environnement sont mises dans les secrets/variables du repository github (settings puis secrets and variables).
Pour la variable du schema name, la commande ${{ github.event.number }} permet de récupérer le numéro de la pull request.
Pour ces deux jobs et les suivants, l’étape de checkout est obligatoire car elle permet à GitHub d’avoir accès aux différents fichiers.
Pour que GitHub ait accès aux commandes dbt, il faut qu’il installe les dépendances nécessaires. Ceci est fait avec l’action install-python (qui utilise python pour installer dbt). Une action GitHub est une “fonction/bout de code” réutilisable dans différents workflows. Pour définir une action, il faut créer un action.yml dans un dossier .github/actions/action_name.
Voici à quoi ressemble l’action install-python :
name: Install Python tooling
description: "Install python tools and dbt"
inputs: #Variable d'entrée de l'action
PythonVersion:
description: "PythonVersion"
required: false
default: 3.10.7
RequirementFilePath:
description: "Path to the requirements.txt"
required: false
default: "./requirements.txt"
runs:
using: "composite"
steps:
- name: Set up Python
uses: actions/setup-python@v2
with:
python-version: ${{ inputs.PythonVersion }} # Specify your desired Python version
- name: Install dependencies
shell: bash
run: |
python -m pip install --upgrade pip
pip install -r ${{ inputs.RequirementFilePath }}
Une fois que tous les tests sont passés, il faut déployer les modèles lors du merge de la pull request sur la branche de dev (main ici).
Le workflow main.yml commence donc avec ceci :
name: Deploy_dbt_dev
run-name: ${{ github.actor }} deploys dbt
on:
push:
branches:
- main
Pour déployer en production, c’est la même chose avec le nom de la branche de production à la place. Il faut également penser, lors de commandes dbt, à changer le nom de la target pour respectivement "dev" et "prod".
La dernière étape est de faire tourner des jobs dbt des modèles de données de manière automatique afin que les nouvelles données soient transformées. Pour cela, il faut utiliser un cron :
name: scheduled_run
on:
schedule:
- cron: '30 13 * * *'#Le workflow se lance tous les jours à 13h30 UTC
L’inconvénient du cron est qu’il ne permet pas de choisir sur quelle branche il se lance. Il va toujours se déclencher sur la branche par défaut (main/master). Donc, pour déclencher le workflow sur, par exemple, la branche production, il faut préciser la branche lors du checkout :
steps:
- name: Checkout code
uses: actions/checkout@v2
with:
ref: prod
Voici le workflow complet de scheduled_run_prod.yml :
name: scheduled_run_prod
on:
schedule:
- cron: '30 13 * * *'#Le workflow se lance tous les jours à 13h30 UTC
jobs:
scheduled_run:
name: scheduled_run
runs-on: ubuntu-latest
env:
SNOWFLAKE_PASSWORD_DBT_PROD: ${{ secrets.SNOWFLAKE_PASSWORD_DBT_PROD }}
DBT_ENV_SECRET_GIT_TOKEN: ${{ secrets.DBT_ENV_SECRET_GIT_TOKEN }}
steps:
- name: Checkout code
uses: actions/checkout@v2
with:
ref: prod
- uses: ./.github/actions/install-python
with:
RequirementFilePath: ./requirements.txt
- name: Run dbt
env:
DBT_PROFILES_DIR: ${{ vars.DBT_PROFILES_DIR }}
PROD_SCHEMA_NAME: ${{ vars.PROD_SCHEMA_NAME }}
run: |
dbt deps --target prod
dbt run --target prod
dbt test --target prod
La CI/CD de votre projet dbt est désormais complète ! La syntaxe du code SQL et un échantillon de vos données sont d’abord testés lors d’une pull request (pr.yml). Puis vos modèles dbt ainsi que la documentation dbt sont générés lors d’un merge/push sur vos branches de développement (main.yml) et de production (prod.yml). Enfin, vos tables de données sont mises à jour et testées continuellement via le déclenchement du scheduled_run.yml (dev et prod) en fonction du paramétrage du cron.
Slim CI
dbt permet de ne lancer que les modèles qui ont été modifiés, ce qui permet de mettre en place une Slim CI et donc d’économiser des ressources et du temps de calcul.
Tous les projets dbt contiennent un fichier manifest.json, présent dans le dossier target/, qui représente l’état actuel du projet et qui se modifie à chaque lancement d’une commande dbt. La commande dbt run --select @state:modified --state comparison_manifest, avec comparison_manifest étant un manifest antérieur à celui actuel, permet de n'exécuter que les modèles ayant subis une modification.
L’objectif de la Slim CI est donc de stocker le manifest.json et de le récupérer à chaque appel de la CI, c’est-à-dire à chaque déclenchement du pr.yml , afin de le comparer à celui actuel du projet.
Pour stocker le fichier, plusieurs options sont possibles en fonction de votre cloud provider. L’une d’entre elles est de le stocker sur un bucket S3.
Le main.yml va donc contenir une étape supplémentaire pour publier le manifest.json sur le bucket S3. Dans ce cas, il faut également penser à configurer les informations d’authentification AWS (qui sont rentrées dans les secrets GitHub ici). On va donc avoir ceci dans notre main.yml :
- name: Configure AWS Credentials
uses: aws-actions/configure-aws-credentials@v1
with:
aws-access-key-id: ${{ secrets.AWS_ACCESS_KEY_ID }}
aws-secret-access-key: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
aws-region: eu-west-1
- name: Copy manifest file to s3 bucket
run: |
aws s3 cp ./target/manifest.json s3://bucket_name/
Maintenant que le manifest est stocké sur le bucket S3 (et se met à jour à chaque déclenchement du main.yml), il faut aller le récupérer à chaque déclenchement de la CI. Le fichier pr.yml va donc également avoir une étape supplémentaire :
- name: Configure AWS Credentials
uses: aws-actions/configure-aws-credentials@v1
with:
aws-access-key-id: ${{ secrets.AWS_ACCESS_KEY_ID }}
aws-secret-access-key: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
aws-region: eu-west-1
- name: Get manifest from s3
run: |
aws s3 cp s3://bucket_name/manifest.json ./
Ici, le manifest est déposé dans la racine du projet dbt. Mais il est possible de le mettre n’importe où, sauf à l’emplacement du manifest actuel du projet, pour ne pas que celui-ci soit remplacé.
Pour que la Slim CI soit effective, il faut maintenant changer les commandes dbt pour prendre en compte la comparaison des deux manifests (dans le pr.yml), en précisant l’emplacement du manifest récupéré depuis le bucket S3 :
- name: Integration tests
env:
PR_SCHEMA_NAME: DBT_CI_${{ github.event.number }}
DBT_PROFILES_DIR: ${{ vars.DBT_PROFILES_DIR }}
run: |
dbt deps
dbt seed --full-refresh --target ci
dbt run --select @state:modified --state ./ --target ci
dbt test --select @state:modified --state ./ --target ci
Publier la documentation dbt sur GitHub Pages
La documentation dbt, qui peut être générée avec la commande dbt docs generate, est au départ seulement disponible en local (avec la commande dbt docs serve) mais il existe différentes possibilités de la publier, dont l'utilisation des GitHub Pages.
Pour créer une GitHub Pages, il faut choisir une branche puis le répertoire qui contient les fichiers nécessaires à la création de la page web. Le répertoire est soit la racine, soit un répertoire docs. Dans le cas de cet article, la branche a été nommée gh-pages.
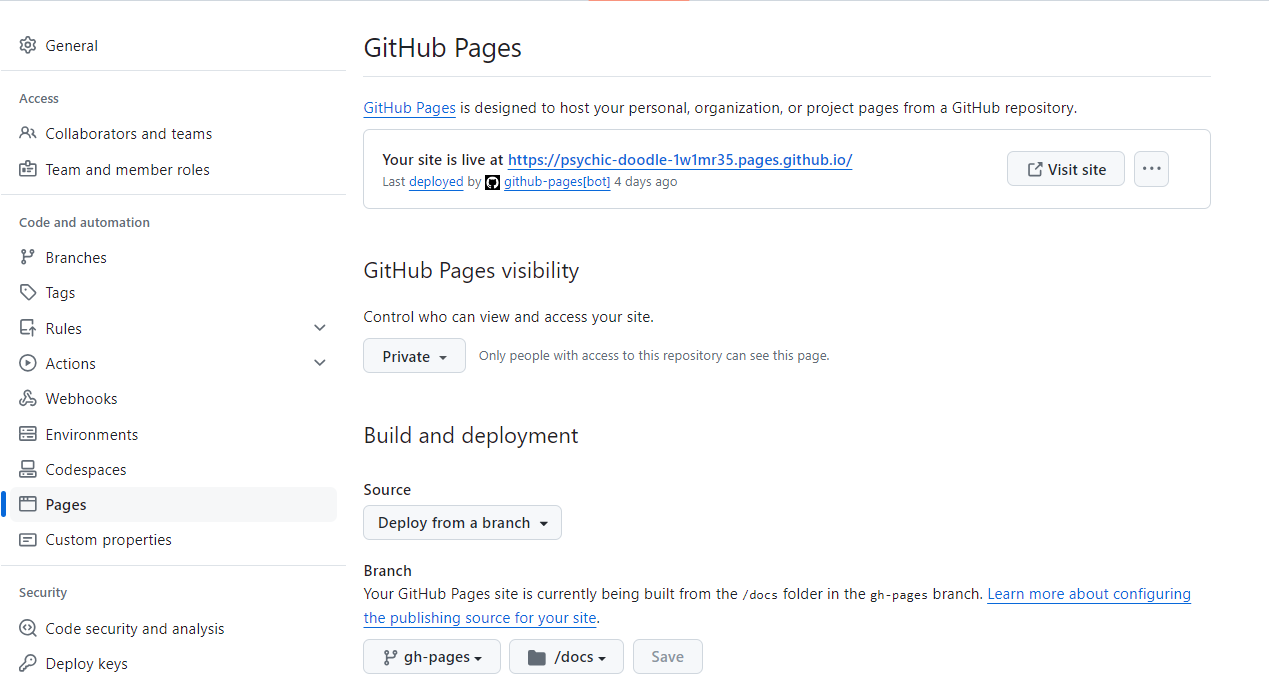
Dans dbt, la commande dbt docs generate crée tous les fichiers dans le dossier target/.
Il faut donc, pour créer la GitHub Pages contenant la documentation dbt, créer une branche (gh-pages dans l’article) qui contient, soit dans la racine, soit dans un répertoire docs, le dossier target/ uniquement. Une solution possible est de faire comme ceci :
#!/bin/bash
git checkout --orphan gh-pages
dbt deps --target dev
dbt docs generate --target dev
mv docs tmp_docs
mv target docs
git config --global user.email "github_actions_bot@example.com"
git config --global user.name "github_bot"
git add -f docs
git commit -m "update documentation" docs
git push --force https://$DBT_ENV_SECRET_GIT_TOKEN@github.com/repository_name
Ce script (publish_docs.sh) renomme temporairement le dossier docs/ du projet dbt pour que le dossier target/ soit renommé docs/ à la place, avant de push sur le repository git sur la nouvelle branche gh-pages. Il est important de configurer un nouvel user et email puisque c’est un bot de GitHub qui va réaliser le commit et le push, même si les valeurs n’ont pas d’importance.
Il faut ensuite, dans le main.yml ou prod.yml, rajouter une étape qui fait tourner le script ci-dessus pour que le workflow déploie la documentation (cf workflow complet) .
Cependant, le workflow ne peut pas directement écrire sur un repository git. Il n’a pas les permissions nécessaires pour ceci. Il faut donc lui rajouter des droits d’écritures :
permissions: write-all
Au final, le workflow main.yml va être :
name: Deploy_dbt_dev
run-name: ${{ github.actor }} deploys dbt
on:
push:
branches:
- main
permissions: write-all
jobs:
dev:
runs-on: ubuntu-latest
env:
SNOWFLAKE_PASSWORD_DBT_DEV: ${{ secrets.SNOWFLAKE_PASSWORD_DBT_DEV }}
DBT_ENV_SECRET_GIT_TOKEN: ${{ secrets.DBT_ENV_SECRET_GIT_TOKEN }}
steps:
- name: Checkout code
uses: actions/checkout@v2
- uses: ./.github/actions/install-python
with:
RequirementFilePath: ./requirements.txt
- name: Deploy dbt dev
env:
DEV_SCHEMA_NAME: ${{ vars.DEV_SCHEMA_NAME }}
DBT_PROFILES_DIR: ${{ vars.DBT_PROFILES_DIR }}
run: |
dbt deps –target dev
dbt run --target dev
dbt compile --target dev #génère la documentation
- name: Configure AWS Credentials
uses: aws-actions/configure-aws-credentials@v1
with:
aws-access-key-id: ${{ secrets.AWS_ACCESS_KEY_ID }}
aws-secret-access-key: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
aws-region: eu-west-1
- name: Copy manifest file to s3 bucket
run: |
aws s3 cp ./target/manifest.json s3://bucket_name/
- name: Publish docs gh-pages
env:
DBT_PROFILES_DIR: ${{ vars.DBT_PROFILES_DIR }}
DEV_SCHEMA_NAME: ${{ vars.DEV_SCHEMA_NAME }}
run: ./cicd/publish_docs.sh
Désormais, à chaque déploiement de dbt sur la branche main (en dev ici), la documentation va être automatiquement générée et publiée sur une GitHub Pages (via la création de la branche gh-pages), dont le lien est accessible dans les settings (onglet pages) du repository git.
Conclusion
L’utilisation de GitHub Actions permet de se passer en partie de dbt Cloud et l’association avec un IDE tel que VSCode permet une meilleure expérience de développement.
Dans cet article, nous avons vu comment déployer dbt sur plusieurs environnements, faire tourner des jobs réguliers sur les modèles de données, optimiser du temps et des ressources avec la Slim CI et enfin de publier la documentation du projet dbt pour qu’elle soit hebergée sur GitHub Pages.
Documentation GitHub Actions : https://docs.github.com/fr/actions
Documentation dbt : https://docs.getdbt.com/docs/introduction