

Dans l'univers en constante évolution de l'intelligence artificielle et du développement logiciel, le Machine Learning Operations (ML Ops) devient crucial pour les entreprises désireuses de maximiser le potentiel du machine learning. Le ML Ops, qui combine les meilleures pratiques du développement de modèles de machine learning (ML) et des opérations informatiques, simplifie le déploiement et la gestion des modèles ML en production, garantissant leur performance et leur fiabilité. Ce processus vise l'automatisation complète du cycle de vie des modèles, depuis leur création jusqu'à leur déploiement, en mettant l'accent sur une intégration et une livraison continue, le contrôle qualité des données, et un suivi en temps réel. Il encourage la collaboration entre les data scientists, les ingénieurs ML et les équipes opérationnelles, accélérant ainsi le lancement de solutions de machine learning, tout en veillant à leur évolutivité et à leur conformité.
Inspiré du DevOps, le ML Ops se concentre sur l'automatisation des processus, depuis le développement des modèles jusqu'à leur maintenance, en passant par leur intégration continue, la gestion de la qualité des données, et le suivi permanent. Cette méthode favorise une collaboration étroite entre les différents acteurs pour une mise en œuvre efficace des modèles, en assurant leur performance et leur conformité.
Définir une vision claire pour le produit ML est la première étape déterminante de son cycle de vie, posant les fondations du projet en alignant les objectifs technologiques et les besoins de l'entreprise. Pour plus de détails sur l'importance de cette phase, je vous recommande mon article précédent, "Vision produit d'un projet ML", qui examine comment définir une vision produit pour guider avec succès un projet de ML.
Principes ML Ops
Voici les principes majeurs du ML Ops que nous allons explorer ensemble :
- automatisation et Intégration continue,
- versionning,
- testing,
- monitoring,
- reproductibilité.
Automatisation
Le niveau d'automatisation des pipelines de données, de modèles et de code détermine la maturité du processus ML. L'objectif principal d'une équipe spécialisée en ML Ops est d'automatiser l'intégration des modèles de machine learning, que ce soit directement au sein du système logiciel ou comme un composant de service indépendant.
Ceci implique l'automatisation intégrale des processus du workflow de machine learning, éliminant le besoin d'interventions manuelles. Les déclencheurs pour l'entraînement et le déploiement automatiques des modèles peuvent être des événements planifiés, des notifications par messagerie ou de surveillance, ainsi que des modifications des données, du code d'entraînement des modèles, ou du code de l'application.
Pour intégrer le ML Ops, trois niveaux d'automatisation sont distingués, allant de l'entraînement et déploiement manuels à l'automatisation totale des pipelines ML et CI/CD :
- Dans un premier temps, le processus est manuel dans la phase de démarrage, impliquant que la préparation des données, ainsi que l'entraînement et le test des modèles, sont réalisés à la main, fréquemment à l'aide d'outils tels que les Jupyter Notebooks.
- Dans un second temps, l'automatisation du pipeline de ML progresse en permettant l'entraînement automatique des modèles, activé par la réception de nouvelles données, et inclut également la validation des données et des modèles.
- Finalement, l'automatisation complète du pipeline CI/CD marque le point culminant du processus, caractérisée par le déploiement rapide et sécurisé des modèles de ML en production, grâce à l'automatisation de la construction, du test et du déploiement des composants.
Intégration continue
Pour comprendre le déploiement des modèles, il est essentiel de préciser ce que sont les ressources ML : cela inclut le modèle de machine learning, ses paramètres et hyperparamètres, les scripts pour l'entraînement et les données utilisées pour l'entraînement et les tests. Une ressource ML peut être destinée à être intégrée soit dans un service (comme un microservice), soit dans des éléments particuliers de l'infrastructure. Un service de déploiement est responsable de l'orchestration, du logging, de la surveillance et de la gestion des alertes pour garantir la stabilité des modèles de machine learning, du code et des données.
Le ML Ops constitue une méthodologie d'ingénierie qui adopte des pratiques dédiées pour améliorer le cycle de vie des applications de machine learning qui sont les suivantes :
- Intégration continue (CI) : Cette approche étend l'intégration et la validation automatique du code et des éléments, en y ajoutant l'évaluation régulière de la qualité et de la consistance des données ainsi que des performances des modèles de ML, ce qui est crucial pour s'assurer de leur conformité avec les buts du projet.
- Livraison continue (CD) : Cette pratique vise à faciliter non seulement le déploiement automatique des applications, mais également à permettre aux pipelines d'entraînement ML de déployer de façon indépendante les services de prédiction, diminuant ainsi le délai pour lancer en production des modèles mis à jour et optimisés.
- Entraînement continu (CT) : Cette méthode facilite l'adaptation et l'amélioration constantes des modèles de ML, grâce à un réentraînement automatique sur des données récentes ou l'utilisation de nouvelles techniques d'entraînement, garantissant leur efficacité et leur applicabilité dans la durée.
- Monitoring continu (CM) : Cette approche se concentre sur le suivi et l'évaluation permanents des données en production ainsi que des performances opérationnelles des modèles, facilitant la détection rapide des baisses de performance ou des nécessités de modification.
La distinction entre CI/CD en DevOps et en ML Ops découle des caractéristiques propres et des besoins spécifiques des workflows de ML par rapport aux méthodes de développement logiciel classiques. Dans le cadre du ML Ops, les principes de CI/CD sont essentiels mais leur application est élargie pour englober non seulement le code source, mais également les données, les modèles de machine learning, ainsi que les processus d'entraînement et de déploiement de ces modèles.
Même si les objectifs d'automatisation et d'amélioration de l'efficacité sont communs au CI/CD dans les domaines du DevOps et du ML Ops, le ML Ops couvre un champ d'action plus étendu en intégrant la gestion spécifique des données, des modèles et de leurs performances, en plus de la gestion du code source.
Versionning
L'objectif du versionnement est de traiter les scripts d'entraînement, les modèles de machine learning et les jeux de données comme des éléments clés des pratiques ML Ops. Cela se réalise par l'emploi de systèmes de gestion de versions, qui permettent de consigner et de suivre les modifications apportées aux modèles et aux données au cours du temps.
Cette pratique permet aux équipes de revenir à des versions antérieures, de suivre les modifications apportées au fil du temps, et de garantir la cohérence entre les équipes de développement et de production.
Les modifications des modèles et des données de ML peuvent survenir pour plusieurs raisons, notamment :
- Les modèles peuvent être réentraînés avec de nouvelles données.
- Les performances des modèles peuvent se dégrader avec le temps.
- Les modèles peuvent nécessiter des révisions en cas d'attaque.
- La possibilité de revenir rapidement à une version antérieure.
- Les exigences de conformité peuvent imposer la réalisation d'audits ou d'enquêtes sur les modèles et les données, ce qui requiert la disponibilité de toutes les versions des modèles de ML utilisées en production.
Conformément aux pratiques établies dans le développement de logiciels, chaque spécification de modèle de machine learning (autrement dit, le code utilisé pour élaborer un modèle ML) doit être soumise à une révision de code. En outre, il est impératif de consigner chaque spécification dans un système de gestion de versions pour assurer que l'entraînement des modèles ML puisse être vérifié et reproduit.
Testing
Les tests dans le cadre du ML Ops sont cruciaux pour assurer la fiabilité, l'efficacité et la conformité des systèmes d'apprentissage automatique (ML). Ils se divisent en plusieurs catégories principales, à savoir les tests sur les données, la fiabilité des modèles, et l'infrastructure ML, chacun visant à valider différents aspects du processus de développement de ML.
- Tests sur les données : ils s'assurent de la qualité et de la pertinence des données utilisées, incluant la validation des schémas des données, l'évaluation de l'importance des features et la conformité réglementaire des pipelines de données.
- Tests pour la fiabilité : ces tests des modèles visent à identifier les modèles obsolètes, à évaluer la performance des modèles à l'aide de jeux de tests distincts, et à tester la fairness, le biais et l'inclusion pour garantir que les modèles traitent toutes les données de manière équitable. (La fairness assure que les algorithmes traitent équitablement tous les groupes, le biais se réfère aux distorsions dans les prédictions, et l’inclusion vise à garantir que les solutions sont conçues pour bénéficier à toute la diversité des utilisateurs.)
- Tests d'infrastructure ML : se concentrent sur la reproductibilité des modèles, en s'assurant que l'entraînement produit des résultats cohérents, et sur le bon fonctionnement de l'API ML, notamment via des tests de stress.
Ces tests sont essentiels non seulement pour la phase de développement mais aussi pour l'intégration et le déploiement des modèles ML. Ils contribuent à améliorer le versioning en validant les modifications du code, à renforcer l'automatisation en s'intégrant aux pipelines d'automatisation, à optimiser la surveillance en détectant les problèmes potentiels et à garantir la reproductibilité des modèles au fil du temps. En résumé, les tests sont une composante indispensable du ML Ops, permettant de s'assurer que les systèmes ML sont performants, conformes et prêts pour la production.
Monitoring
Une fois un modèle de ML déployé, le suivi rigoureux du projet ML Ops est primordial pour garantir la performance, la stabilité et la fiabilité du modèle en production. Le monitoring englobe l'observation continue de la qualité, de la consistance et de la pertinence des données d'entrée, ainsi que le suivi de la performance du modèle ML lui-même, incluant sa stabilité numérique, son vieillissement et sa performance computationnelle. Si une anomalie est détectée, il est crucial de signaler ces changements et d'alerter les développeurs concernés, garantissant ainsi une intervention rapide pour maintenir l'efficacité du système.
Le monitoring du code joue également un rôle clé dans l'assurance de la qualité et de l'intégrité du code du projet ML, incluant la surveillance des changements dans le système source, des mises à jour des dépendances et de la qualité prédictive de l'application sur les données servies. En parallèle, le suivi des processus de génération des caractéristiques est essentiel, car ils ont un impact significatif sur la performance du modèle. Ce suivi permet de réitérer la génération des caractéristiques de manière régulière pour prévenir toute dégradation de la qualité prédictive due à des changements dans les données ou des divergences dans les chemins de code.
Finalement, le monitoring et le suivi contribuent à la reproductibilité en enregistrant les entrées, sorties et l'exécution du code, des workflows et des modèles. Le suivi des tests permet également de détecter des anomalies dans le comportement et la performance du modèle. Ainsi, la surveillance continue du modèle en production est essentielle, utilisant des indicateurs comme la précision, le rappel et le score F1 pour déclencher un réentraînement du modèle si nécessaire, menant à la récupération du modèle et à la préservation de son efficacité à long terme.
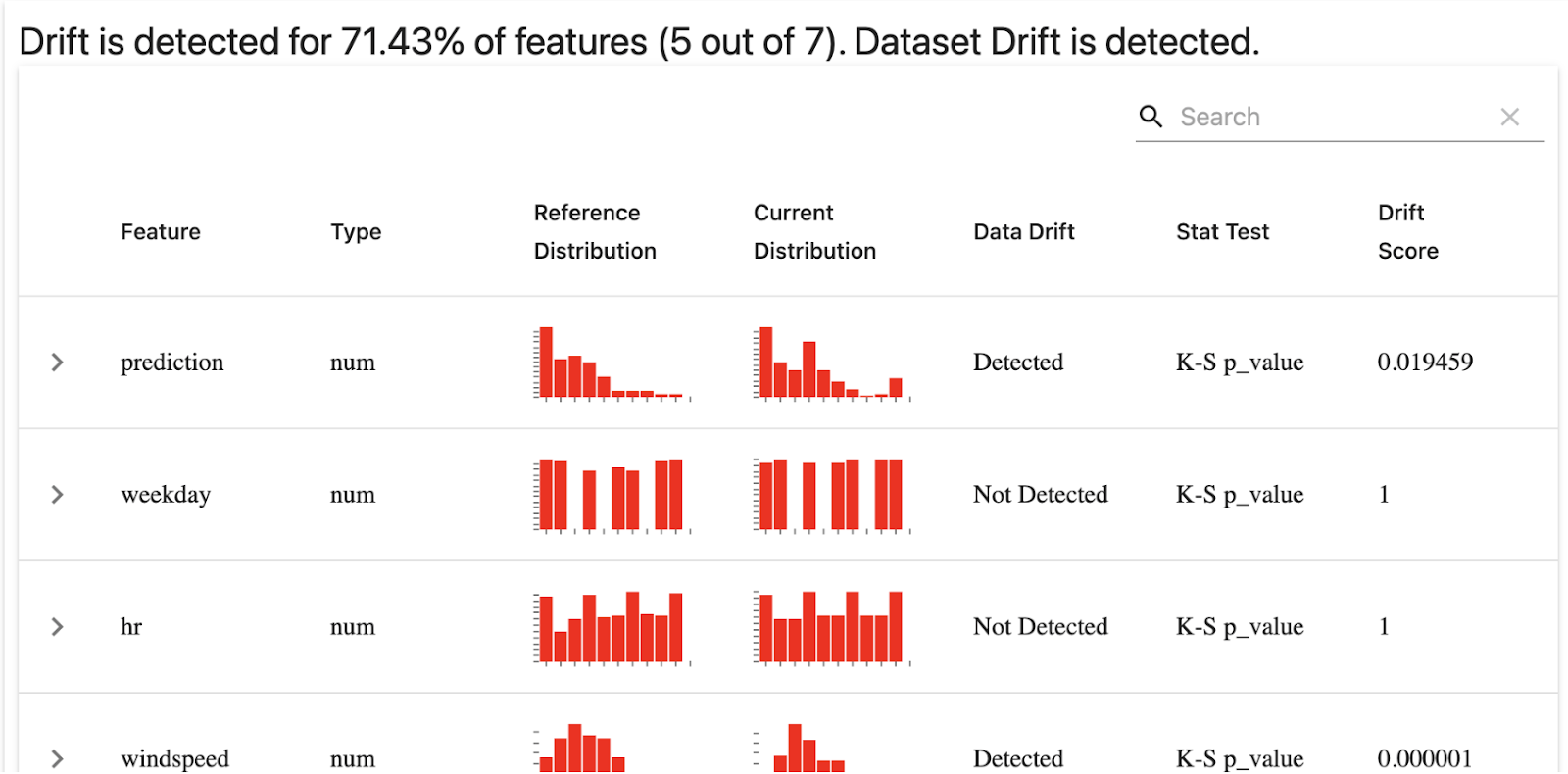
source: https://www.evidentlyai.com/blog/ml-model-monitoring-dashboard-tutorial
Reproductibilité
La reproductibilité est cruciale dans la construction des workflows de ML. Elle permet de générer des résultats identiques avec les mêmes entrées, peu importe le lieu d'exécution. Pour garantir des résultats identiques, l'ensemble du workflow ML Ops doit être reproductible.
La reproductibilité des données implique la capture et la conservation de toutes les informations et processus nécessaires à la collecte, au prétraitement et à la transformation des données, permettant ainsi à d'autres de retrouver le même ensemble de données pour l'analyse ou l'entraînement de modèles. Cela comprend la création de sauvegardes pour les données, le versionnement des données, ainsi que la création et la sauvegarde des métadonnées (paramètres d'entraînement, les versions des modèles, les performances des modèles sur des ensembles de données de test, les graines aléatoires entre autres) et de la documentation.
La reproductibilité du code permet de recréer et d'obtenir les mêmes résultats à partir du code utilisé pour développer les modèles de ML. Elle garantit que les versions des dépendances et la pile technologique sont identiques pour tous les environnements. Cela est généralement assuré en fournissant des images de conteneurs ou des machines virtuelles.
Globalement, la reproductibilité est atteinte grâce à d'autres principes : le versionnement, les tests, l'automatisation et le suivi travaillent de concert pour capturer et maintenir les informations nécessaires, exécuter les processus de manière cohérente, vérifier la justesse des résultats et identifier tout facteur pouvant affecter la reproductibilité des modèles et des workflows.
Conclusion
En conclusion, le ML Ops représente une avancée significative dans la manière dont les entreprises déploient et gèrent les modèles de ML dans des environnements de production. En intégrant des principes tels que le versionning, l'automatisation, la reproductibilité, le testing, l'intégration continue, et le monitoring en temps réel, le ML Ops facilite non seulement le déploiement rapide et sécurisé de modèles ML, mais assure également leur performance et leur fiabilité sur le long terme. Cette approche méthodique favorise une collaboration efficace entre les data scientists, les ingénieurs ML et les équipes opérationnelles, accélérant l'innovation et renforçant l'alignement avec les objectifs commerciaux.
À mesure que le domaine de l'intelligence artificielle continue d'évoluer, l'adoption du ML Ops deviendra incontournable pour les organisations qui souhaitent rester compétitives et tirer pleinement parti des technologies de machine learning. En somme, le ML Ops est non seulement essentiel pour la stratégie de transformation digitale des entreprises, mais il s'impose également comme un pilier central pour la mise en œuvre réussie et durable des solutions de machine learning.