

Le 3 Avril 2024 avait lieu le traditionnel Summit d’AWS, au Palais des Congrès, le salon organisé chaque année à Paris par le leader mondial du Cloud. Cette année, comme dans beaucoup d’autres conférences, l’IA était à l’honneur. Après des exemples de sociétés françaises qui ont pleinement adoptées le Cloud avec AWS (FFT, Ubisoft ou encore Betclic) plusieurs annonces ont été faites par Julien Groues, Directeur Général d’AWS France et Mai-Lan Tomsen Bukovec, vice Présidente d’AWS :
- AWS Bedrock est disponible dans la région Paris
- Le modèle Mistral AI Large est dorénavant disponible sur Bedrock, ce qui nous a valu la présence d’Arthur Mensh, cofondateur de Mistral AI
- AWS et Nvidia travaillent conjointement sur le projet Ceiba, un projet pour créer de nouveaux serveurs pour calcul haute performance dédiés à l’IA.
S’en sont suivies des présentations de différents partenaires d’AWS, en voici certaines :
- Hugging Face est un HUB dédié au partage de modèles d’IA Opensources et de dataset. Le projet, présenté par son cofondateur Thomas Wolf, utilise AWS depuis ses débuts et aujourd’hui la plateforme contient plus de 500 000 modèles.
- Raphaëlle Deflesselle, CTO chez TF1, nous a présenté certains projets du groupe et a abordé notamment la nouvelle plateforme TF1+ qui se veut être la première plateforme de streaming gratuite qui repose sur AWS.
Un élément important transparaît aussi lors de cette keynote, c’est la volonté d’AWS de former de plus en plus de futurs utilisateurs, ils promettent d'offrir plus de 29 millions de formations gratuites d’ici 2025, de quoi leur assurer une bonne avance en nombre de compétences sur le marché.
Réduisez en toute simplicité le coût de vos environnement AWS en planifiant le démarrage et l'extinction de vos ressources
Speakers: Pereg Hergoualc'h, Cloud Architect - Devoteam
Cette conférence a tout de suite attiré mon attention parmi celles présentes sur le calendrier de la journée, tout d’abord parce que comme l’a bien dit Pereg “nous aimons l’argent” et aimons en faire économiser à nos clients mais surtout parce que la promesse est proche d’un outil qui a fait l’objet d’un précédent article, Cloud Custodian. Notre confrère de chez Devoteam a d’abord présenté le contexte dans lequel il a commencé à développer AWS Service Scheduler un outil permettant d’allumer et d’éteindre ses services AWS de façon programmée:
- Éteindre et allumer des instances EC2 à certains moments de la semaine et de la journée
- Certains environnements doivent être allumés à la demande
- DocumentDB doit faire partie des services compatibles (excluant AWS Instance Scheduler des outils répondant à ses besoins car ne permettait de gérer que des instances EC2 et RDS)
- Il faut que l’outil soit simple à mettre en place et à utiliser au quotidien (que ce ne soit pas des fonctions lambda à gérer)
- Qu’il puisse être mis en place via Terraform
La solution qu’il a choisie est de développer un module Terraform basé sur des Step Functions, Event Bridge, des Lambdas et SSM Automation pour démarrer à la demande des scripts d’extinction de ressources. Il se peut que, comme chez certains de nos clients, vous ayez été amené à créer ce type d’infrastructure à la main en fonction de vos besoins. L’idée derrière ce projet est d’avoir un module avec suffisamment de fonctionnalités pour répondre au besoin de tous.
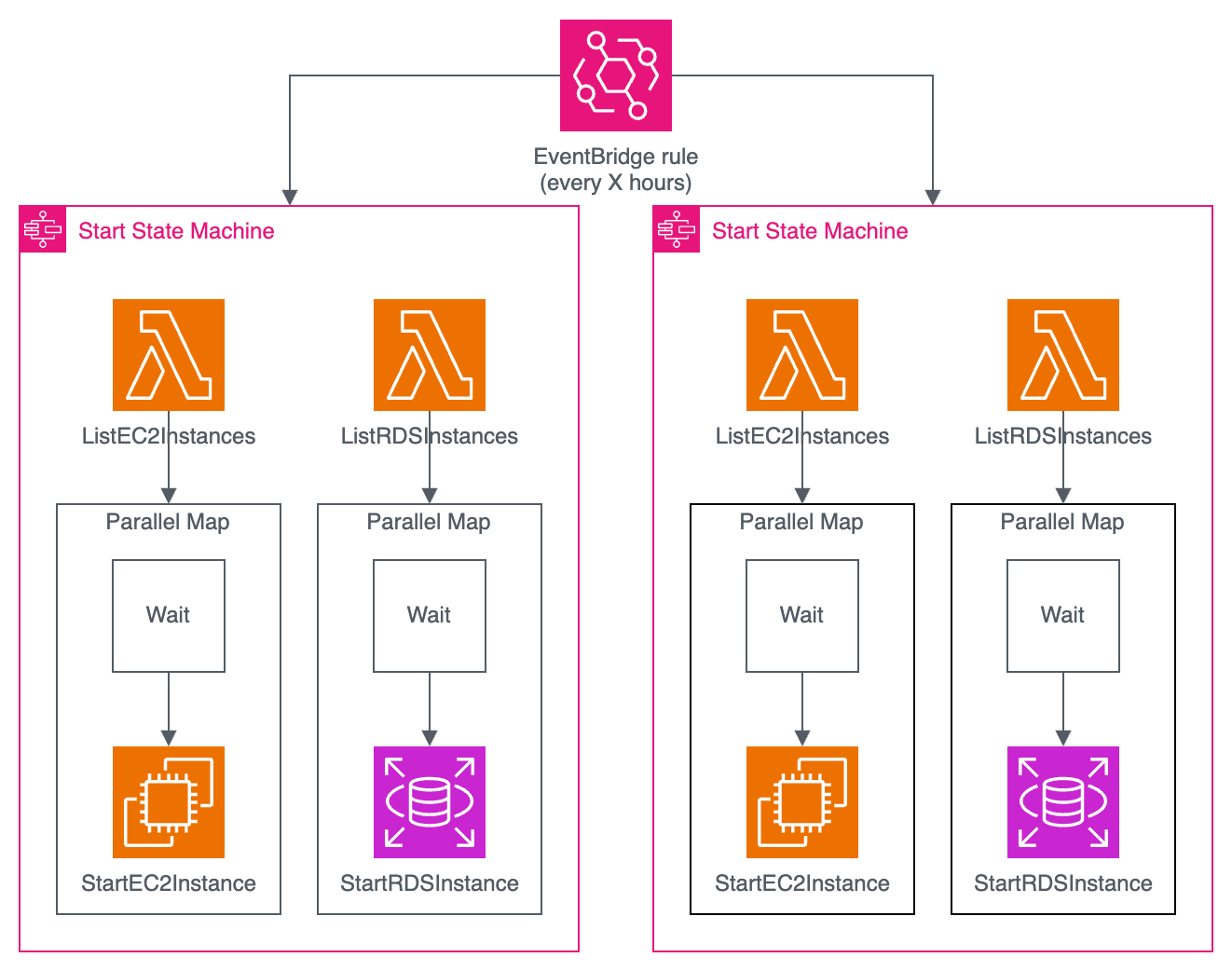
Pour utiliser le module c’est très simple, il suffit d’avoir le code suivant dans son projet et de l’adapter au besoin :
module "service_scheduler" {
source = "phergoualch/service-scheduler/aws"
version = ">= 2.0.0"
enabled_services = ["ec2", "asg", "ecs", "rds", "documentdb", "lambda", "apprunner", "aurora"]
default_timezone = "Europe/Paris"
app_name = "service-scheduler"
execution_interval = 6
}
Le principal avantage de ce module par rapport à l’utilisation de Cloud Custodian par exemple, est qu’il est utilisable dans notre code Terraform à côté de la déclaration de nos ressources.
Pour le moment, les services EC2, ASG, RDS, Aurora, ECS, DocumentDB, Lambda et AppRunner sont supportés. Pereg nous a ensuite partagé sa vision pour l’avenir de ce module et souhaite l’ouvrir à la communauté pour ajouter de nouvelles fonctionnalités, de nouveaux services compatibles, et de le rendre utilisable via CloudFormation.
C’est un très beau projet qui pourra servir à tous.
Protégez vos données à l’échelle avec les contrôles data perimeter
Speakers : Claude Ampigny, Achraf Moussadek Kabdani et Al'hossein Laaguel
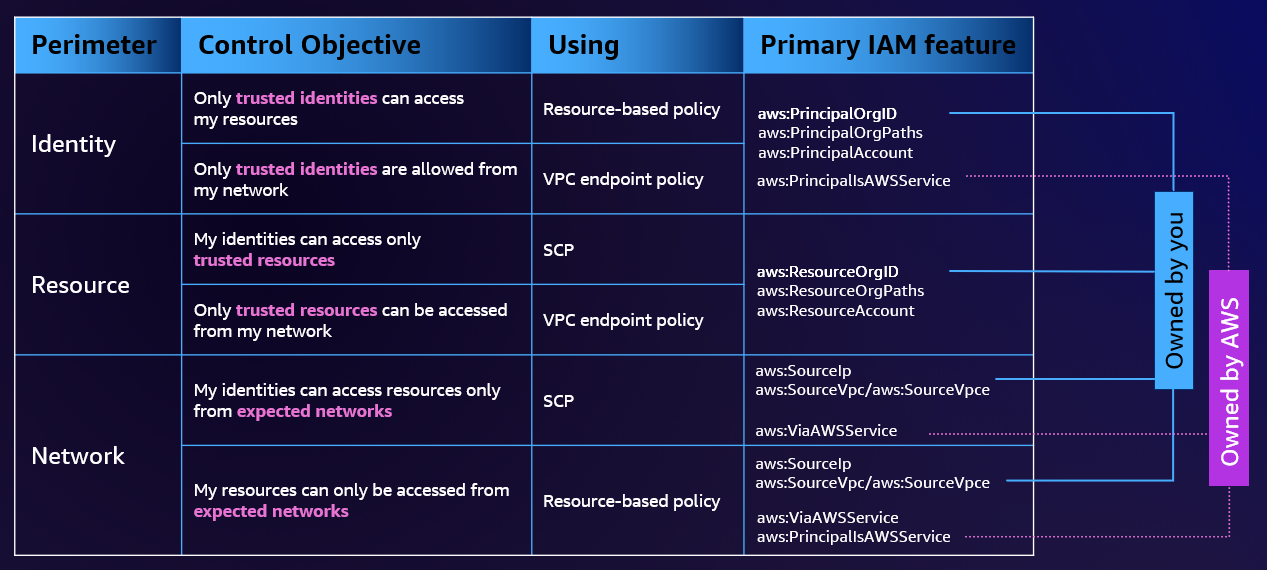
Quand on a une organisation dotée de nombreuses identités AWS, avec des données sensibles, on a envie d’avoir un niveau de sécurité élevé. Pour éviter des accès illégitimes ainsi que des fuites de ses données, AWS permet de renforcer la sécurité à l’aide d’un ensemble de SCPs, resource-based policies et de VPC endpoint policies: un data perimeter.
Le data perimeter agi sur trois dimensions :
- Les identités, rôle IAM ou utilisateurs appartenant à votre organisation
- Les ressources appartenant à vos comptes AWS, ou les services AWS eux-mêmes
- Les réseaux, que ce soient vos réseaux on-premise, vos VPCs ou des réseaux de services AWS
Pour le mettre en place, il faut suivre plusieurs étapes :
- Examiner les objectifs de sécurité : quels sont les services AWS les plus utilisés, où se situent les données les plus sensibles, …
- Adapter le data perimeter à son contexte, en hiérarchisant les besoins les plus nécessaires
- Concevoir les contrôles du data perimeter à l’aide des templates proposés par AWS sur leur dépôt github
- Anticiper les effets de bords de ces contrôles à l’aide du data perimeter helper
- Mettre en place les contrôles
- Monitorer et faire évoluer les contrôles
Il est important de noter plusieurs informations. Premièrement le data perimeter ne remplace pas les mesures de sécurité déjà mises en place, ce n’est qu’une couche supplémentaire.
Deuxièmement, pour utiliser le data perimeter helper, les événements des services touchés par les contrôles doivent être remontés dans AWS Cloudtrail, et il ne permettra d’éviter que les principaux effets de bords, par exemple un oubli de whitelist d’une API externe pouvant impacter une, ou plusieurs, de vos applications.
Et finalement, tout au long de ce processus de mise en place de ce data perimeter, il est important de garder en tête la matrice de celui-ci, se trouvant ci-dessous.
Développement cloud en local avec AWS CDK et local stack
Speakers: Max Thomas, AWS | Jean-Baptiste Guillois, AWS
Cette conférence (qui n’est pas sponsorisée par l’entreprise du même nom) a été, pour AWS, l’occasion de vanter les mérites du projet Local Stack, un outil permettant d’émuler un environnement complet sur son ordinateur. Il repose sur des conteneurs Docker qui sont lancés à chaque fois qu’un nouveau service est ajouté à une stack CDK. Les speakers ont utilisé l’exemple des fonctions lambda qu’il faut déployer sur AWS avant de pouvoir les tester. Avec un tel outil, un environnement complet sous AWS peut être testé en local sans générer le moindre coût. Le seul inconvénient avec cet outil est qu’il n’y a pas d’interface utilisateur et c’est un peu plus compliqué pour retrouver les logs.
Code de la demo : https://github.com/aws-samples/localstack-aws-cdk-example
Chez Ippon nous avions écrit un article sur LocalStack en 2019, n'hésitez pas à le relire.
Opérationnalisation de la GenAI : du concept à l'industrialisation
Speakers: Julien Kopp, Deloitte | Karl-Eduard Berger, Deloitte | Tony Baudot, Deloitte | Cristbel Gonzalez Rojas, Deloitte
Dans un premier temps, la conférence commence sur des questions d’ordre éthique et légales. L'adoption de l'IA dans nos systèmes pose des questions de taille, surtout quand il s'agit de garder nos données en sécurité et de rester conforme aux règles. Imaginez que quelqu'un "empoisonne" l'IA avec de mauvaises données dès le départ - comment réguler ce type de déviance à l'échelle mondiale ?
Ensuite arrive la comparaison entre les pratiques d'IA traditionnelles (MLOPS) et la gestion des nouveaux géants de l'IA (LLMOPS), surtout en termes de sécurité et d'éthique. Ce n'est pas juste une question de technologie ; dès le début, il faut penser à ce qui est juste et légal.
Prenons les hallucinations de l'IA. Comment faire pour le détecter avant de mettre notre système en ligne, sans utiliser de données réelles? Un autre enjeu est la détection de réponses discriminatoires ou le respect de la propriété intellectuelle. Tous ces défis nous rappellent que derrière les lignes de code, il y a des responsabilités légales et éthiques.
Airbus : utiliser la GenAI pour optimiser la gestion du cycle de vie
Speakers: Cassy Deplace, DataScientist @Capgemini | Alexandra Amiens, DataScientist @Capgemini
Le projet Lifecycle met en lumière une problématique cruciale de l'industrie aéronautique : bien que la majorité des composants d'un avion, plus de 90%, pourraient être réutilisés après son démantèlement, seulement 30% bénéficient d'une seconde vie. Cette sous-utilisation s'explique principalement par une gestion inefficace de l'historique des maintenances et réparations. Chaque intervention sur une pièce est consignée sur un document spécifiant les modifications apportées, engendrant ainsi des doutes quant à la fiabilité de la traçabilité de ces opérations. Ajoutant à cette complexité, bien que toutes les compagnies aériennes soient tenues de documenter les mêmes types d'informations, le format de ces enregistrements varie d'une compagnie à l'autre, rendant la standardisation et le suivi encore plus ardu. Enfin, la rédaction manuelle de ces documents engendre un risque d'incohérence dans la saisie.
Pour régler ces différentes problématiques, le choix de la GenAI s’est peu à peu imposé par rapport à l’utilisation de modèles de NLP plus classiques (Natural Language Processing, Traitement automatique de la langue naturelle).
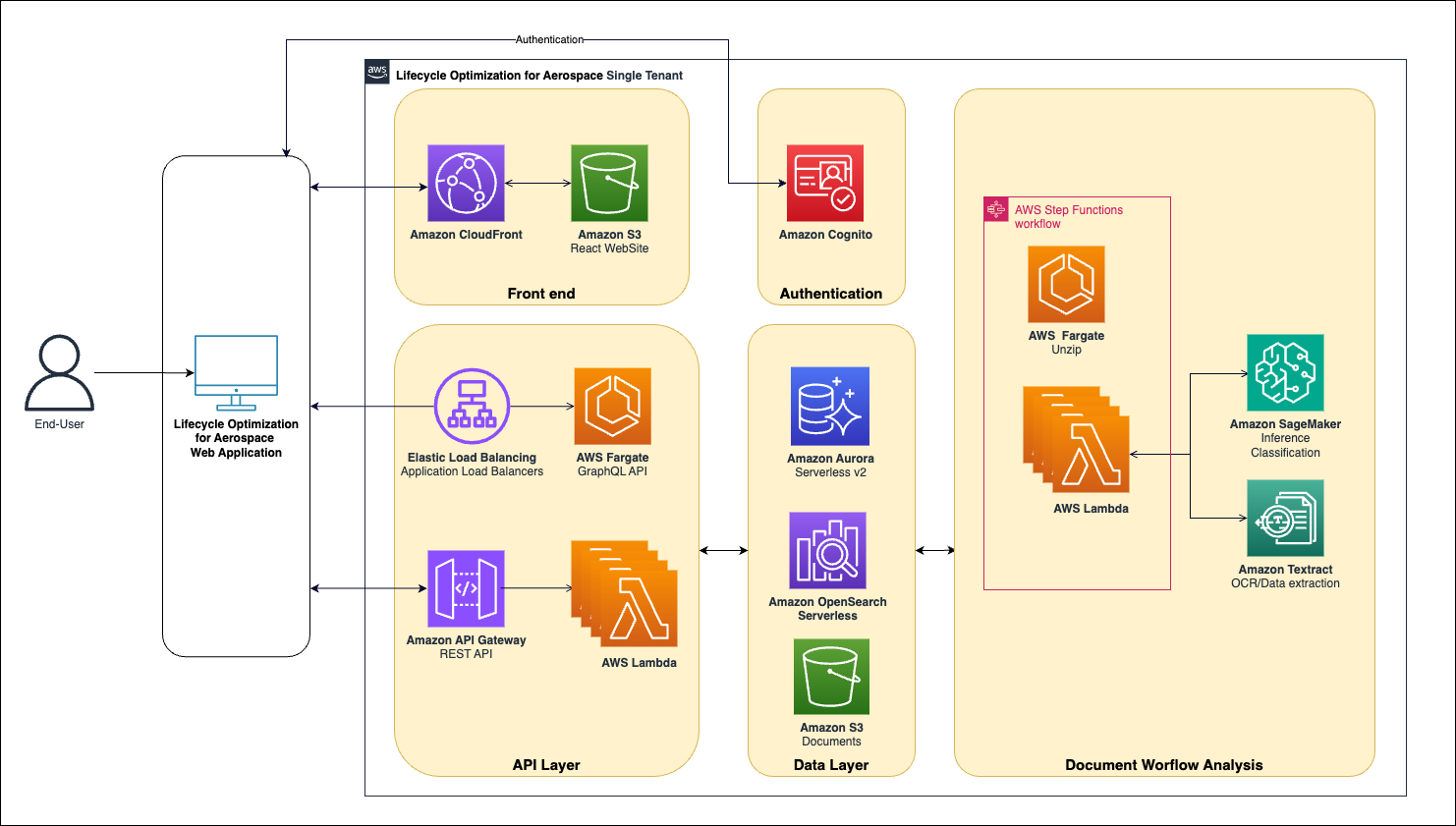
Le workflow d’ingestion se fait de manière classique :
- Un ensemble de documents compressés en format zip est transféré dans un bucket S3.
- Amazon Textract réalise l’OCR (Reconnaissance de caractères), et un modèle custom de Machine Learning est utilisé pour classifier les informations
- Un vectorstore est constitué sur Amazon OpenSearch
Ensuite, l’utilisation de ces documents se fait autour de trois cas d’usage spécifiques.
Premièrement, le projet appelé “Gen AI for unmissable controls”.
Lors d’un changement sur un avion, l’organisme local de sécurité doit l’approuver afin de délivrer un nouveau release certificate à l'avion l’autorisant à repartir en vol. L'organisme chargé de ces régulations en Europe est l'EASA (European Union Aviation Safety Agency), tandis qu'aux États-Unis, c'est la FAA (Federal Aviation Administration), parmi d'autres.
En utilisant le vectorstore constitué précédemment ainsi que Bedrock et le modèle Claude v2, on cherche à trouver des incohérences dans les documents de réparation. Par exemple, sur ces documents une section 'Remarques' peut mentionner un organisme externe, et une case dédiée doit être cochée pour valider la réparation auprès de cet autre organisme. Un document est considéré comme correct si ces deux critères sont remplis ou si aucun n'est applicable. En revanche, une incohérence est signalée si seulement l'un des deux critères est respecté. Ces incohérences sont ensuite remontées à l’application Web et le client est capable de voir d’un coup d'œil les erreurs à vérifier sur les documents d’un avion.
Vient ensuite le projet “Smart Retrieval for Automated AD Verification of Aerospace Components”.
Les documents AD (Airworthiness Directive) sont émis par un organisme de régulation et précisent les modifications à effectuer sur un avion pour complaire aux exigences de sécurité en vigueur. Dans ce cas d’usage, il est demandé au modèle Claude v2, à partir des documents AD d’un avion, de résumer les modifications à effectuer.
Enfin, le projet moins concluant mais tout aussi intéressant nommé “Integrating SDR and SRM for effective repair verification”.
Les documents SDR (Service Difficulty Report) sont des documents rédigés par les exploitants d’avions (compagnies aériennes en général) et qui précisent les problèmes rencontrés sur un avion ainsi que les réparations effectuées. Quant à eux, les documents SRM (Structural Repair Manual) sont fournis par les constructeurs et contiennent les consignes et recommandations de réparations à effectuer en fonction des pannes rencontrées. Ce projet consiste, en utilisant la GenIA, à vérifier si les réparations effectuées suivent ces recommandations. Il n’est cependant pas encore abouti, entre autres dû au fait que certaines réparations recommandées par le constructeur n’existent que sous forme de schémas et sont beaucoup plus difficilement exploitables.
L’exploitation de ces différents cas, permettant d’améliorer la traçabilité des différentes pièces, a d’ores et déjà permis aux clients concernés de réduire de 50% les coûts d’inspection, ainsi que d’augmenter de 20 à 25% le nombre de pièces ré-utilisées.
Cette conférence, à la fois dense et fascinante, a mis en lumière les applications innovantes de l'IA générative dans l'aéronautique, offrant un aperçu de ce que la puissance de cette technologie nous réserve pour l'avenir.

