

Cet article a été co-écrit par plusieurs consultants : Etienne GANDRILLE, Alexis Renard, Julien Sadaoui, David Renouf et Julien Vasdeboncoeur.
La première journée de cette KubeCon+CloudNativeCon 2024 (relatée dans un premier article) s’était ouverte sur une série de présentations centrées sur l’IA (jusqu’à l’excès ?). Cette deuxième journée s’est ouverte en se focalisant en premier lieu sur la communauté ainsi que les promesses d’efficacité, mettant en lumière la nécessité que notre secteur prenne au corps les impacts écologiques qu’il a sur notre monde.
La communauté
Commençons avec tout d’abord quelques statistiques : voici la liste des projets ayant reçu le plus de contributions de la part d’utilisateurs finaux. On retrouve des projets bien connus comme Backstage, Argo, Dragonfly. On trouve également des projets peut-être moins connus comme KCL.
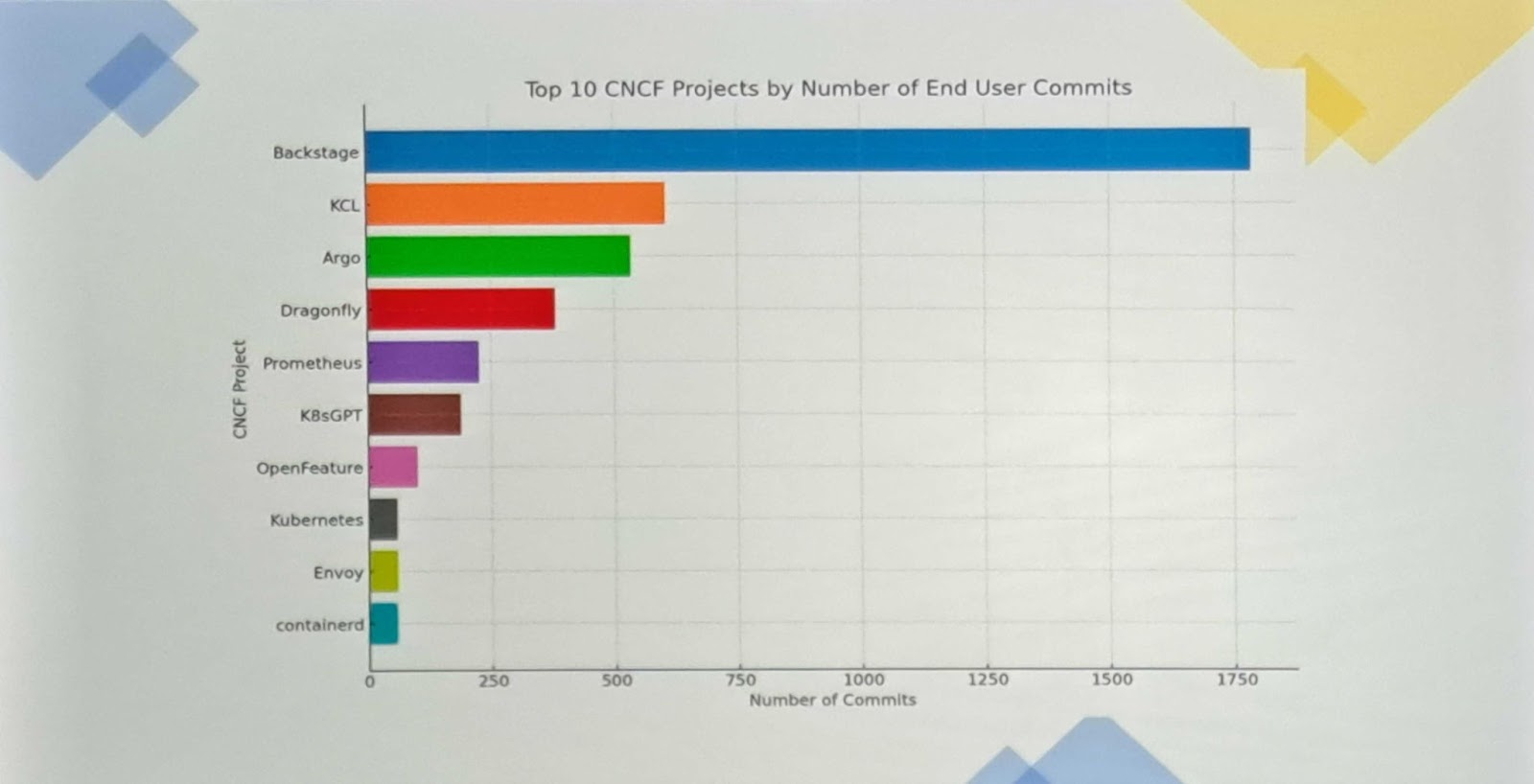
Quoi qu’il en soit, rien ne serait possible sans des contributions de l’ensemble de la communauté. Mais se lancer comme contributeur est parfois difficile. C’est la raison pour laquelle la CNCF a lancé le programme zero to merge pour accompagner ceux qui seraient tentés de contribuer.
Grand contributeur, le CERN remporte le prix de meilleur utilisateur final des solutions CNCF par leur adoption massive des outils, ainsi que leur contribution très active.
Efficacité : Web Assembly & SpinKube
La keynote s’est ensuite orientée vers un autre sujet qui attire de plus en plus de contributions : WebAssembly, plus communément appelé Wasm. Des logiciels populaires tels que Photoshop ont démontré la possibilité et l’opportunité d’utiliser Wasm dans le navigateur, pour exécuter des applications complexes ordinairement exécutées en dehors des navigateurs. Mais Wasm peut également être utilisé côté serveur, offrant ainsi un moyen efficace et sécurisé d’exécuter des workload. C’est là l’objectif de SpinKube, un projet open source nouvellement donné à la CNCF. Son objectif est de prendre en charge l’ensemble du cycle de vie des applications Wasm dans Kubernetes en offrant l’ensemble de l’outillage pour développer, déployer et opérer des Workloads Wasm dans Kubernetes. Sur cette dernière phase, l’exécution, il serait donc nécessaire d’utiliser un runtime Wasm au lieu du container runtime. On mesure dès lors l’impact que cela peut avoir sur les plateformes Kubernetes ! Au-delà de cette annonce, très succincte, c’est très certainement un sujet à suivre si vous croyez en l’avenir (encore incertain ?) de Wasm côté serveur.
Construire et lancer le Green IT : l’exemple de la Deutsche Bahn
La responsabilité du numérique sur le changement climatique a ensuite été mise en avant. Pour cela, Gualter Barbas Baptista, de la Deutsche Bahn (similaire à la SNCF en Allemagne), a offert un retour d’expérience très intéressant sur la manière avec laquelle cette problématique a été prise en compte dans son organisation. La stratégie mise en œuvre était organisée autour de trois axes.
Tout d’abord, la mise en place d’une plateforme centralisée pour maximiser l'utilisation des nœuds sur les clusters Kubernetes. De la même manière que les cloud providers centralisent pour maximiser l’utilisation des ressources, la Deutsche Bahn a fait de même… à son échelle.
Le second axe de la stratégie GreenIT de la Deutsche Bahn est passé par la mise à disposition d’outils aux développeurs en partant du constat suivant : lors des développements, des ressources sont parfois réservées par configuration au-delà du nécessaire pour l’exécution workloads. Si ces réservations permettent d'absorber les pics de charge, elles sont bien souvent disproportionnées le reste du temps. C’est la raison pour laquelle la Deutsche Bahn a poussé l’utilisation de Vertical Pod Autoscaler et de Kube Downscaler pour automatiser la réservation de ressources et l’adapter au besoin réel des applications, permettant ainsi d’augmenter radicalement l’efficacité énergétique des clusters.
Enfin, le dernier axe concerne le monitoring GreenOps des applications basé sur Kepler (Kubernetes-based Efficient Power Level Exporter) pour l’acquisition des données, Prometheus pour la collecte et Grafana pour la visualisation dans un dashboard orienté Green IT.
Pour terminer son intervention, Gualter Barbas Baptista nous a laissé avec ces deux conseils :
- start now : l’important est de démarrer, de mesurer notre imperfection pour avoir une chance de la corriger - et ce même si la mesure n’est pas parfaite dès le début
- empower the people : les développeurs sont source de créativité et d’innovation et sont concrètement ceux qui font bouger les choses sur le terrain. Ne l’oublions pas, et donnons leur des moyens pour atteindre les objectifs de notre stratégie GreenIT.
Contribuer à Kubernetes (durant sa deuxième décennie d'existence
Pour ma part, j’ai été attiré par une conférence que je croyais orientée développeur et qui, je l’espérais, lèverait le voile sur “comment contribue-t-on aujourd’hui à un projet aussi complexe et globalisé que Kubernetes ?”.
Le plan de la présentation était le suivant :
- Une petite intro
- Le concept d’expérience contributeur au sein de la communauté Kubernetes
- L’évolution de la façon de contribuer depuis les débuts
- Comment je démarre en tant que nouveau contributeur
- Et enfin les écueils “classique” que je vais devoir surmonter
Les speakers, composés de membres de VMWare, Suse et Google, faisaient partie du groupe d'intérêt spécialisé (cf la suite de cet article) en charge de l’organisation de la communauté Kube. Leur mission : faire face aux défis que représente la coordination des bonnes volontés de 86000 contributeurs répartis sur tout le globe.

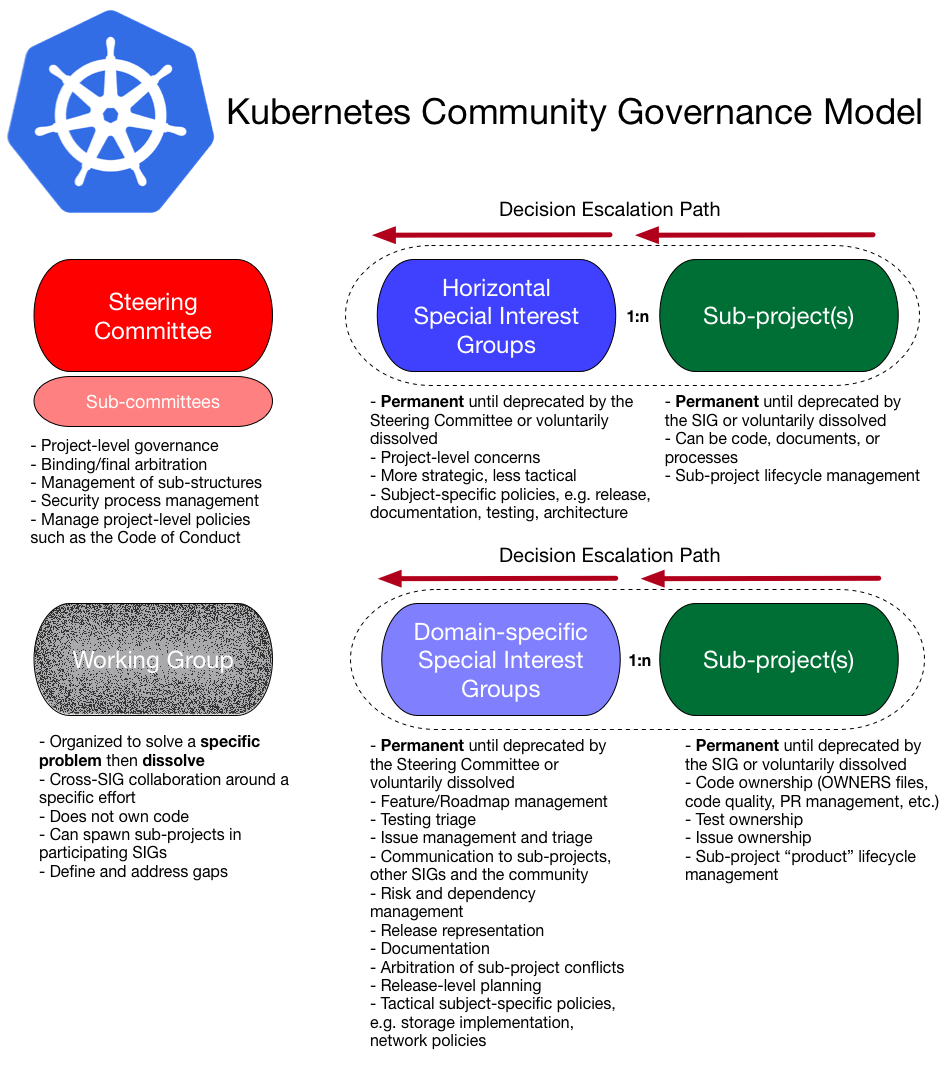
a) Organisation de la communauté
La version simplifiée de la structure de la communauté est bâtie sur :
- 24 groupes d'intérêts spécialisés
- 7 groupes de travail
- 3 comités
Je dis simplifié parce qu’au fur et à mesure de la conférence, j’ai fini par me dire que l’organisation générale était plus dure à appréhender que ce découpage et qu’elle fluctue dans le temps.
Les groupes d'intérêts spécialisés sont la base de la pyramide et s’occupent de la réalisation des fonctionnalités dans les sous-projets, ils sont parfois verticaux parfois horizontaux parfois les 2.
Les groupes de travail sont temporaires (surprenant puisqu’ils adressent des sujets comme : la sécurité, la fiabilité…) tandis que les comités de pilotage, qui ne sont pas techniques, s'occupent de la gouvernance, du code de conduite et de la direction globale du projet.
Puis vint une explication sur la façon dont les décisions de gouvernance étaient prises, cf schéma ci-dessous (officiel mais moyennement compréhensible à mes yeux :)
Ensuite la hiérarchie des contributeurs fut évoquée :
- leurs rôles
- la façon dont ils peuvent gravir les échelons ; par exemple en passant du temps et en gagnant de l’expérience sur les sujets populaires

b) Comment démarrer en tant que contributeur ?
Nabarun Pal (VMWare) a présenté les points d’entrées pour qui souhaite s’impliquer :
- le github de la communauté : kubernetes/community: Kubernetes community content (github.com)
- le slack de la communauté : Join Kubernetes on Slack - Community Inviter, (https://kubernetes.slack.com)
- les google groups des sous projets avec leur propriétaires et les mailing listes associées
ce qui répond aux questions :
- Comment se diriger vers un groupe d'intérêt spécialisé ?
- Quel est son périmètre ?
- Qui le gère ?
- Qui sont les responsables techniques ?
- Quand sont organisées des réunions ?
- Où sont les comptes rendus ?
- Comment obtenir du contexte ?
- Qui contacter ?
- Comment escalader ?
En gros, le guide du nouvel arrivant dans votre société, si votre société est suffisamment grosse pour avoir pris le temps de rédiger un guide de survie (probablement parce que des moussaillons sautent du navire à peine embarqué).
La deuxième partie de la conférence expliquait le rôle du groupe “spécialisé” chargé de l’expérience contributeur.
ContribEx (c’est le nom du groupe) s’occupe de tout ce qui touche de prêt ou de loin à la communauté :
- la documentation destinée à “comment contribuer ?”
- les autorisations des individus sur les groupes, la modération, gestion github
- la communication sur les réseaux, blog, valorisation, les partenariats
- le suivi statistiques des contributions
- “l'organisation bureaucratiques” selon les termes de Kaslin Fields (Google) (écrire les règles, les élections…)
c) Evolution de la communauté Kubernetes
L’intervention de la troisième interlocutrice (Priyanka Saggu) portait sur l'évolution qu’avait connu les processus et les outils de gestion de la communauté Kube :
- Utilisation des Github labels pour automatiser la génération de tableau et nourrir le backlog
- Audit et récupération des statistiques d’utilisation par Github Organisation Membership
- Remplacement de Zapier Zoom par Youtube Automation pour les réunions
- Utilisation de Peribolos pour faciliter l’octroi et la suppression des permissions Github
- Migration des mailing list
- …
J’ai retenu quelques chiffres intéressants pour moi, qui considère qu’un projet avec 15 développeurs en parallèle est un “gros” projet

Notez au passage que Kube n’est pas le projet le plus actif, j’ai trouvé cela un peu ironique, au vu du nombre de projets CNCF basé dessus…
Priyanka explique qu'évidemment avec autant de contributeurs, détecter l’inactivité pour pouvoir expurger les disparus était important pour limiter les coûts.
Les speakers ont profité de l’occasion pour lancer quelques appels :
- “il nous faut plus de Ziggurats relecteurs !”
- “si vous avez des compétences python, venez contribuez à Elekto / Elekto (github.com) (projet CNCF pour lancer des élections sur base d’un repo github)
- “nous souhaitons organiser chaque année, en parallèle de la Kubecon, le Kubernetes Event Summit Events | Kubernetes Contributors, donc si vous avez des compétences dans l’événementiel : venez !
- Le site web kubernetes, contributeur Kubernetes Contributors, aurait besoin de main d’oeuvre qualifiée bash et Golang pour faire évoluer le générateur markdown vers html
- Et on aurait besoin de vous si vous connaissez Golang et l’API Github pour venir corriger un certain nombre de problèmes avec Peribolos (l’outil interne de la communauté Kubernetes mentionné plus haut) (Peribolos | Prow (k8s.io)
d) Éviter les déboires
La dernière partie de la conférence tentait de nous rassurer sur les déceptions qui immanquablement allaient survenir lors de nos premiers pas en tant que contributeur Kubernetes.
J’ai noté :
- toute forme de contribution est la bienvenue :
- à commencer par les relectures
- la documentation
- le support et répondre aux questions slacks
- ne pas rester coincé :
- sur les “bons premiers problèmes à résoudre” pour démarrer, le projet s’occupera de ça
- n'hésitez pas à demander des éléments de contexte
- il est normal de se sentir perdu, frustré, submergé d’informations
- ne pas se décourager devant :
- l’ampleur de la tâche
- la sémantique technique
- le manque de documentation
- être patient vis à vis de la relecture pour ses contributions (2 semaines en moyenne)
- accepter l’entropie : absorber de la connaissance des parties du projet en dehors du périmètre de votre intervention
- il faut du temps pour trouver le sous projet dans lequel se sentir à l’aise
e) Mon bilan
J’avoue que cette conférence m’a un peu laissé sur ma faim. J’aurais bien aimé entrapercevoir un peu plus ce qui se trame derrière le rideau, par exemple :
- la répartition des profils de contributeurs :
- professionnels / bénévoles
- par entreprises qui paient leurs développeurs pour contribuer
- comment se règlent les inévitables conflits d'intérêt pour une plateforme utilisée par les plus grandes sociétés de la planète
Mais surtout, je n’ai pas ressenti l'enthousiasme que j'espérais trouver en y entrant.
Après tout, on venait de m’expliquer que :
- je devais venir pour :
- retirer du code inutile
- relire les pull requests
- m’occuper de la documentation, des habilitations, de l’outillage, de l’organisation, des événements
- que j’allais à coup sûr être paumé, frustré, submergé…
Tout ça est sans doute la pure vérité mais pour me faire rêver, il aurait peut être mieux valu me glisser à l’oreille que mon code pourrait se retrouver un jour dans un des projets les plus utilisés de la planète et que cette perspective valait bien quelques sacrifices, non ?
Innover de manière responsable et durable sur Kubernetes
En continuant sur la lancée du talk précédent, Aparna Subramanian de Shopify souligne que la responsabilité quant à l’impact environnemental de notre secteur et nos métiers est partagée : d’un côté les fournisseurs (providers), et de l’autre les utilisateurs de leurs solutions. Chacun a son impact, chacun a sa part à faire. Nous notons que le concept de partage de responsabilité n’est en rien nouveau à l’ère des services managés et des fournisseurs cloud, mais il est intéressant de voir que la durabilité (ou sustainability) partage désormais la scène aux côtés de la sécurité, de l’efficacité ainsi que de l’innovation.
Pour illustrer ce propos, A. Subramanian invite à ses côtés les deux parties prenantes.
Côté infrastructure cloud, Adrienne Jan de Scaleway note alors qu’un de leurs principaux travaux est l’optimisation du refroidissement des serveurs, responsable d’une bonne partie de leur empreinte carbone.
Du côté “customer”, David Meder-Marouelli de 1&1 Mail et Todd Ekenstam d’Intuit nous montrent la voie pour passer à l’action:
- Auditer pour mesurer (avec fruggr.io en suggestion)
- Planifier une stratégie pas à pas avec des objectifs concrets, ainsi que de favoriser l’utilisation d’outils pour mettre à l'échelle au plus proche (“right sizing”) plutôt que de se retrancher derrière l’approche non durable du “better safe than sorry”. Celle-ci nous pousse à surestimer nos besoins et consommer d’autant plus.
- Réduire l’impact de notre compute, quitte à transférer nos workloads sur ARM (moins gourmand en énergie) ou à investir dans des solutions AI maison pour construire des dashboards Green (initiative poussée en interne chez Intuit)
Confidential Container support in CRI-O
Speaker : Julien Ropé & Sohan Kunkerkar
Bien que le chiffrement soit disponible pour sécuriser les données lorsqu’elles sont stockées et transférées, elles sont toujours déchiffrées et chargées en mémoire lors de l'exécution sur le conteneur, les exposant potentiellement à une extraction involontaire ou intentionnelle. Des données sensibles telles que les mots de passe, les clés privées ou des données très confidentielles pourraient être accessibles par des entités non autorisées avec des risques de sécurité ou de perte de propriété intellectuelle offrant à d’autres organisations un avantage concurrentiel.
C’est là qu’intervient le Confidential Computing, ou informatique confidentielle. Cette technologie chiffre la mémoire afin de protéger les données pendant leur traitement. Confidential Containers (CoCo) est un projet de la CNCF qui vise à apporter l’informatique confidentielle à Kubernetes. Le but de ce projet est de déployer des conteneurs confidentiels à l’aide des outils standards sans connaissances approfondies des technologies sous-jacentes.
Les conteneurs confidentiels offrent un ensemble de fonctionnalités et de capacités pour sécuriser davantage vos conteneurs afin d’atteindre des objectifs plus élevés en matière de sécurité des données, de confidentialité des données et d’intégrité du code d’exécution. Ces conteneurs démarrent sur du matériel tirant parti des environnements d’exécution de confiance (TEE ou Trusted Execution Environment) pour protéger les données et les conteneurs.
Le support des conteneurs confidentiels a été intégré au runtime CRI-O, une implémentation de l’interface d’environnement d’exécution de conteneurs (Container Runtime Interface) pour Kubernetes. Le runtime exécute les conteneurs dans une machine virtuelle, en utilisant kata-containers, qui démarre dans un hyperviseur avec la capacité de chiffrer la mémoire quand elle est utilisée. Le but est d’empêcher même un administrateur de la machine de copier la mémoire, cette technologie offre un haut niveau de sécurité et de confidentialité.
API Gateway
Quand on dispose d’un cluster Kubernetes sur lequel des workloads sont exécutés, les workloads sont à l’intérieur… et les utilisateurs à l'extérieur. C’est la raison pour laquelle on utilise un ingress controller comme porte d’entrée dans notre cluster.
Cependant, une ressource de type ingress présente de nombreuses limitations :
- son aspect monolithique avec une seule ressource pour configurer l’ensemble de l’ingress implique une collaboration entre équipe autour d’une unique ressource ;
- son faible périmètre fonctionnel a conduit à la création d’un écosystème un peu “sauvage” pour étendre son comportement
- pas de mécanisme standard d’extensibilité
Le lancement des réflexions autour de l’API Gateway remonte à la KubeCon de San Diego il y a quatre ans. L’objectif affiché était de concevoir la prochaine génération d'API Ingress en prenant en charge le routage L4 et L7 dans Kubernetes. A présent, son ambition affichée est de prendre en charge et standardiser les fonctionnalités de l’Ingress, du Load Balancing et du Service Mesh tout en offrant un mécanisme standard d’extension.
Dès le départ, API Gateway a été pensé pour offrir une séparation des préoccupations et faciliter la collaboration entre les différents acteurs de la gestion d’un cluster, comme le montre le schéma suivant (que l’on retrouve à chaque présentation de l’API gateway !).
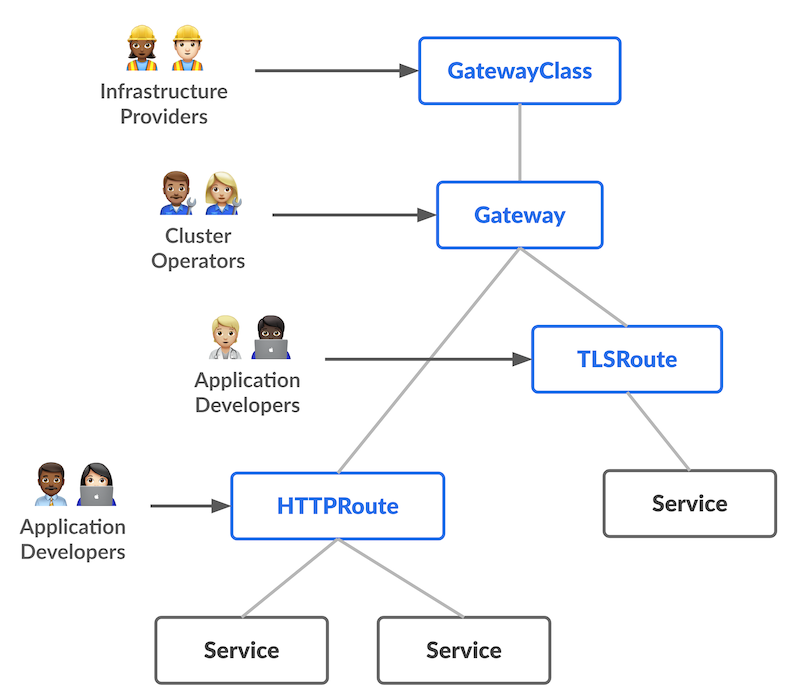
La configuration du routage est extrêmement aisée, comme le montre l’exemple suivant :
---
apiVersion: gateway.networking.k8s.io/v1
kind: HTTPRoute
metadata:
name: faces-gui-route
namespace: faces
spec:
parentRefs:
- name: ingress
namespace: default
rules:
- matches:
- path:
type: PathPrefix
value: /gui/
backendRefs:
- name: faces-gui
port: 80
filters:
- type: URLRewrite
urlRewrite:
path:
type: ReplaceFullPath
replaceFullPath: /
L’API Gateway peut également être configurée très facilement pour faire du trafic slipping, que ce soit du canary deployment (redirection d’un pourcentage du trafic) ou de l’A/B testing (redirection basée par sur des headers de la requête). L’API Gateway offre aussi la gestion des timeouts.
Même si ce projet a déjà publié sa version 1.0, il est peut être encore un peu tôt pour le mettre en production. Cependant, il s’agit très certainement d’un projet à suivre qui pourrait apporter très prochainement de la valeur en simplifiant une partie de la configuration de nos clusters.
Pour en savoir plus n'hésitez pas à consulter le site du projet ou ce tutoriel.
Talks GreenIT & Sustainability
Il faut le dire, cette deuxième journée de conférences grand public nous aura surpris – dans le bon sens – par les multiples conférences orientées GreenIT et Sustainability. Les angles approchés pendant les keynotes et les différents talks de la journée auront pris des directions aussi bien différentes que complémentaires.
Pour les devs comme les DSI, le message de cette journée est clair : nous sommes à la fois acteurs et responsables de l’impact de notre secteur. C’est une bonne nouvelle, ça veut dire que l’on peut agir et faire mieux ! Notre première mission étant de mesurer. Sans cela, impossible de prendre des décisions éclairées pour le numérique de demain.
Ce que l’on en retient “côté tech”
Notre petite sélection d’outils mis en avant durant les principales conférences traitant de la thématique :
- eBPF : par ses capacités de monitoring bas niveau l’outil a été mis en avant plusieurs fois comme un allié à la mesure de l’empreinte électrique (et donc carbone) de nos clusters.
- kepler : incontournable durant cet événement (malgré que ce soit encore une jeune techno), il se base sur eBPF pour capturer des métriques de l’impact énergétique de nos clusters, et de les exporter vers Prometheus. Ensuite, toutes sortes de dashboards orientés pilotage GreenIT sont imaginables.
- kube-green : un outil pratique de shutdown automatique des pods non utilisées (comme on le fait déjà pour nos VMs sur le cloud public)
Ce que l’on en retient “côté organisationnel”
- La mise en avant du TAG Environmental Sustainability : ses victoires, la richesse de sa communauté, et ses nombreux projets à venir. Nous sentons que c’est le début d’une histoire qui se crée dans ce groupe de la CNCF, et ça donne envie d’en faire partie.
- green-reviews-tooling un outil tout récent qui a pour objectif de mesurer l’impact des projets CNCF eux même lors de leur développement. “Eat your own dog food” comme on dit.
- fruggr.io qui a vocation d’aider à auditer nos plateformes kub dans une optique de durabilité.
Avant de terminer cette section, nous voulions mettre en lumiète projet qui touche aussi bien le côté tech qu’organisationnel – c’est celui porté par Deep Green et Civo. L’idée est intrigante et maline: créer une multitude de datacenters décentralisés, au plus près des endroits qu’il faut chauffer : des piscines municipales jusqu’aux bâtiments des collectivités. L’idée est de capturer la chaleur créée par les serveurs pour fonctionner, et de la réinjecter directement là où elle est nécessaire. La puissance de ces datacenters est exploitée par Civo, se chargeant de piloter, de mesurer l’impact et de décomplexifier l’arrivée sur le cloud de ses clients. Les objectifs – et les résultats – sont sociaux, écologiques et économiques. Sans davantage entrer dans les détails, si cela vous intéresse le talk est disponible ici.
“Brilliant”, comme disent les anglais.
Dernière note : en France, ils nous ont conseillé d’aller voir ce que font Qarnot.
Conclusion
Loin de dire que cela sera suffisant pour amortir l’impact que nos workloads ont sur l’environnement dès demain (surtout avec l’avènement de l’IA), il a été rafraîchissant de voir que ce sujet fasse partie intégrante d’un événement de cette envergure. Un message important à recevoir lorsque l’on voit le contraste entre les objectifs fixés pour limiter l’empreinte carbone vs les estimations à venir de notre secteur.
Si ce ne sont pas encore des résultats tangibles en termes de réduction d'empreinte carbone qui ont été présentés cette année, c’est au moins une graine plantée dans nos esprits, prête à germer.
A nous de l’arroser et de voir ce que l’on récoltera l’année prochaine.
Restaurer des pods après la terminaison d’une instance spot
@The Party Must Go on - Resume Pods After Spot Instance Shut Down - Muvaffak Onuş - KubeCon Europe 2024
Ce talk a montré comment reprendre l'exécution d’un pod s'exécutant dans un cluster Kubernetes sur des instances spots après qu’une de ces instances spot soit forcée de s’éteindre.
Dans un premier temps, il est utile de rappeler que les instances spots permettent une économie importante, ici entre “40-60% de réduction sur GCP”. Cependant les instances spot sont aussi des instances pouvant être réclamée par le cloud provider à n’importe quelle moment et provoquant l’arrêt de tous les processus qui s'exécutent. Le conférencier partage le chiffre “5%” qui correspond au nombre de tests qui échouent sur des millions faits chaque mois. Ce pourcentage est d’autant plus important quand on sait que les tests doivent ensuite être relancés après un échec.
La solution qui est mise en avant ici est l’utilisation de “Checkpoint/Restore In Userspace (CRIU)” pour créer un checkpoint du processus qui servira à l'exécuter ailleurs par la suite.
Fonctionnement de criu
criu permet donc de récupérer un checkpoint d’un pod quand un signal de terminaison est reçu par ce dernier.
Actuellement voici les postulats qu’utilise criu:
- runc peut créer un checkpoint et le restaurer
- containerd and cri-o peuvent créer un checkpoint et le restaurer
- l’API kubelet supporte les checkpoints mais pas encore les restores
- Les checkpoint sont stockées dans le système de fichier local de kubelet
Basiquement lors de l'exécution d’un processus. La commande “criu dump” va stopper le processus et créer un checkpoint du processus en incluant tous les fichiers nécessaires à sa restauration.
Puis “criu restore” va permettre de continuer l'exécution du processus à partir du checkpoint.
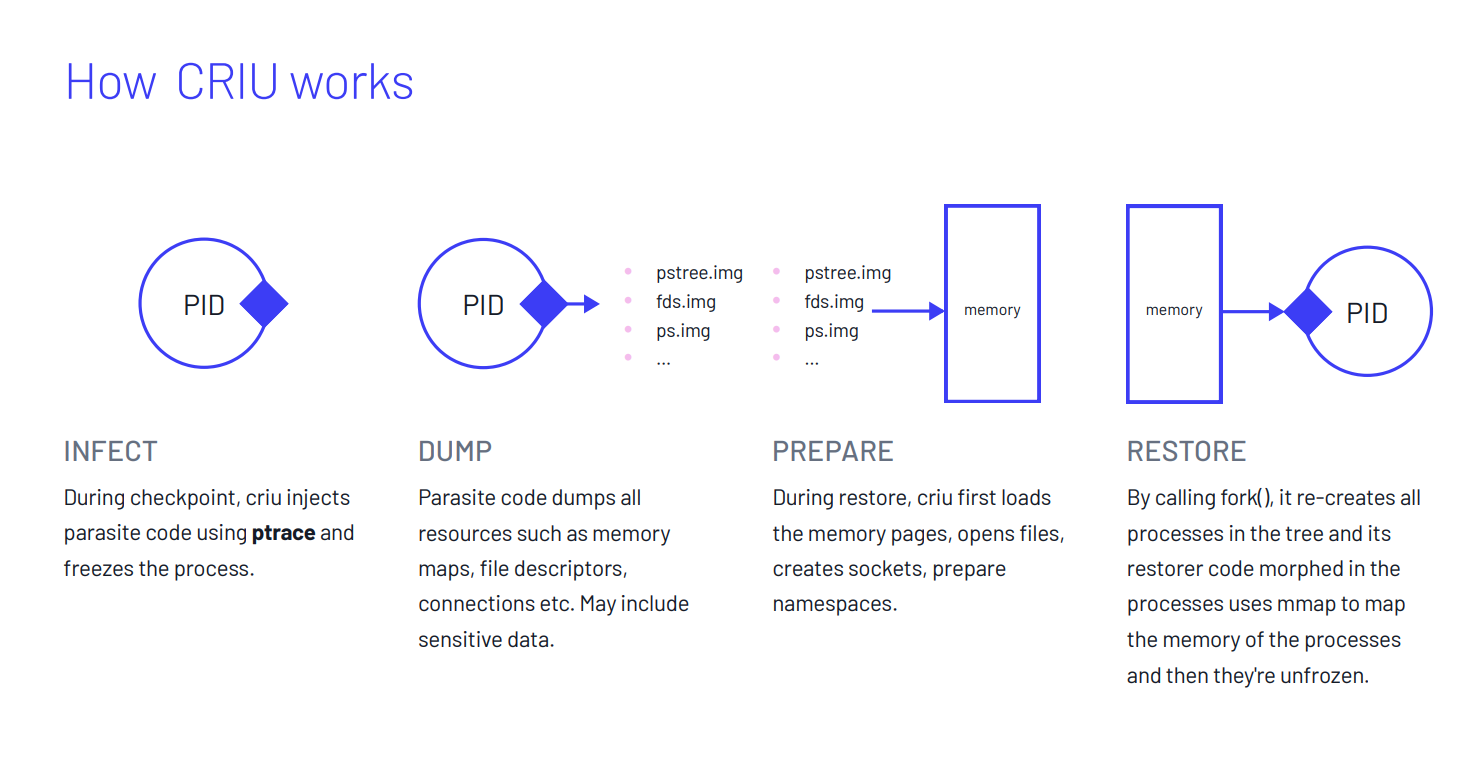
Dans un conteneur, il faut prendre en compte plusieurs aspects. D’une part, le processus qui s'exécute a toujours le PID 1. Or criu ne pourra pas le restaurer sur ce même PID dans un nouveau conteneur qu’il exécutera car ce PID sera déjà occupé par lui-même. De même, toutes les communications initiées aux travers des TTYs possèdent des IDs uniques liés aux communications.
Pour palier ce problème, le wrapper de commande crik peut être utilisé. Crik est un wrappeur de commande open source utilisé pour orchestrer des pods sur Kubernetes.
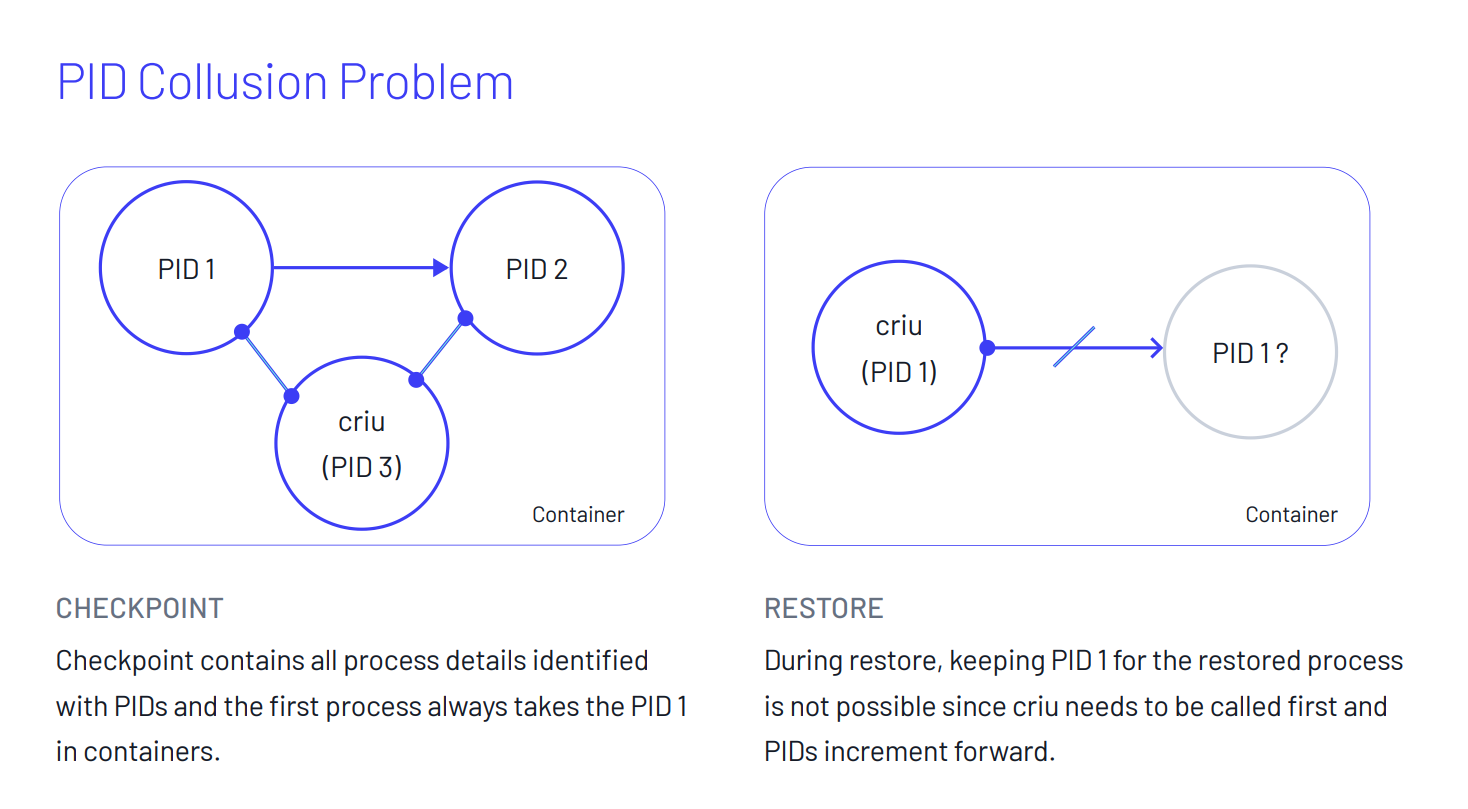
Il résout les problèmes cités en allouant des PIDs définis en amont aux processus qui sont destinés à être utilisés pour les actions de dump/restore. Il enregistre aussi les ID des pipes de communications pour conserver cette unicité lors de la restauration du processus.
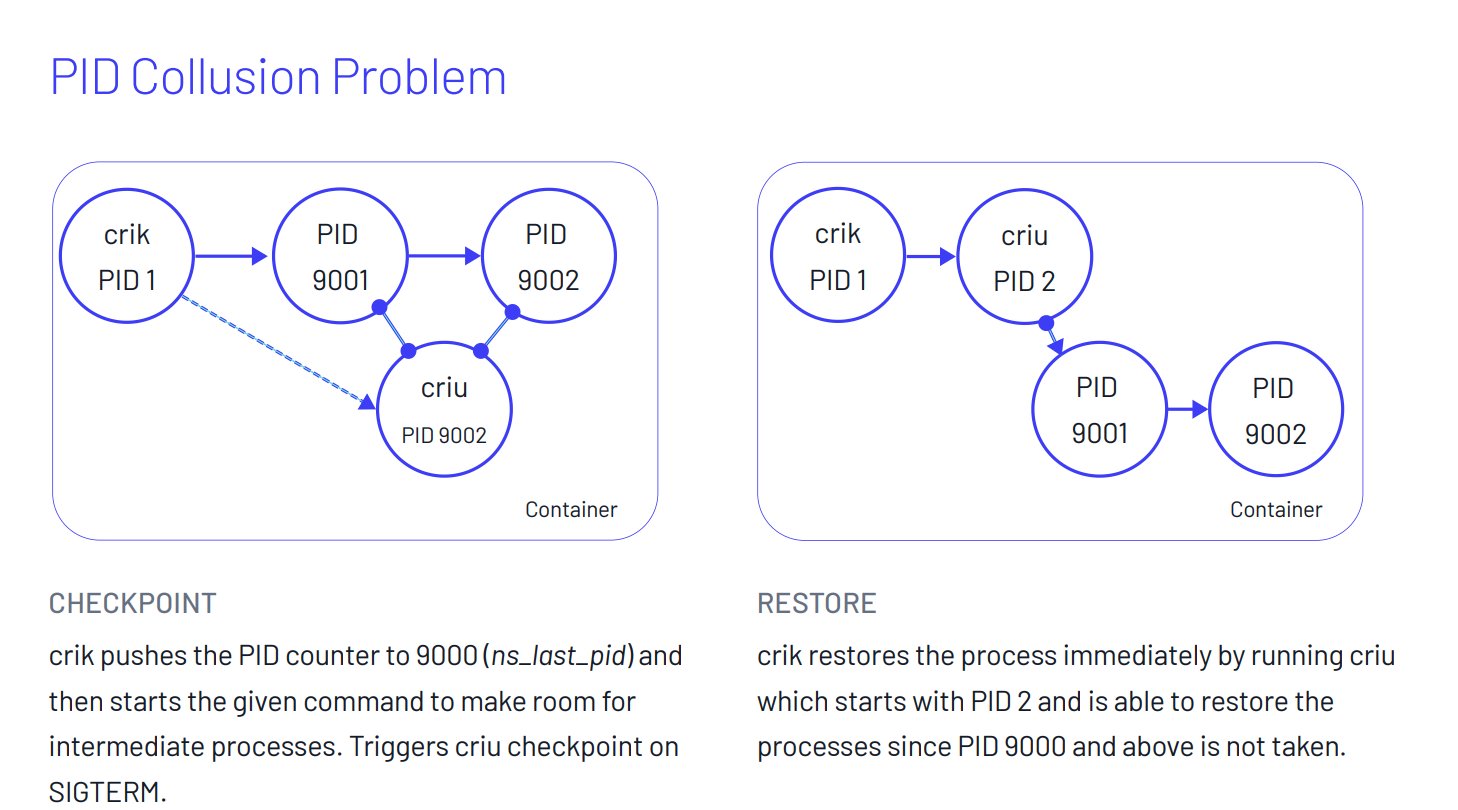
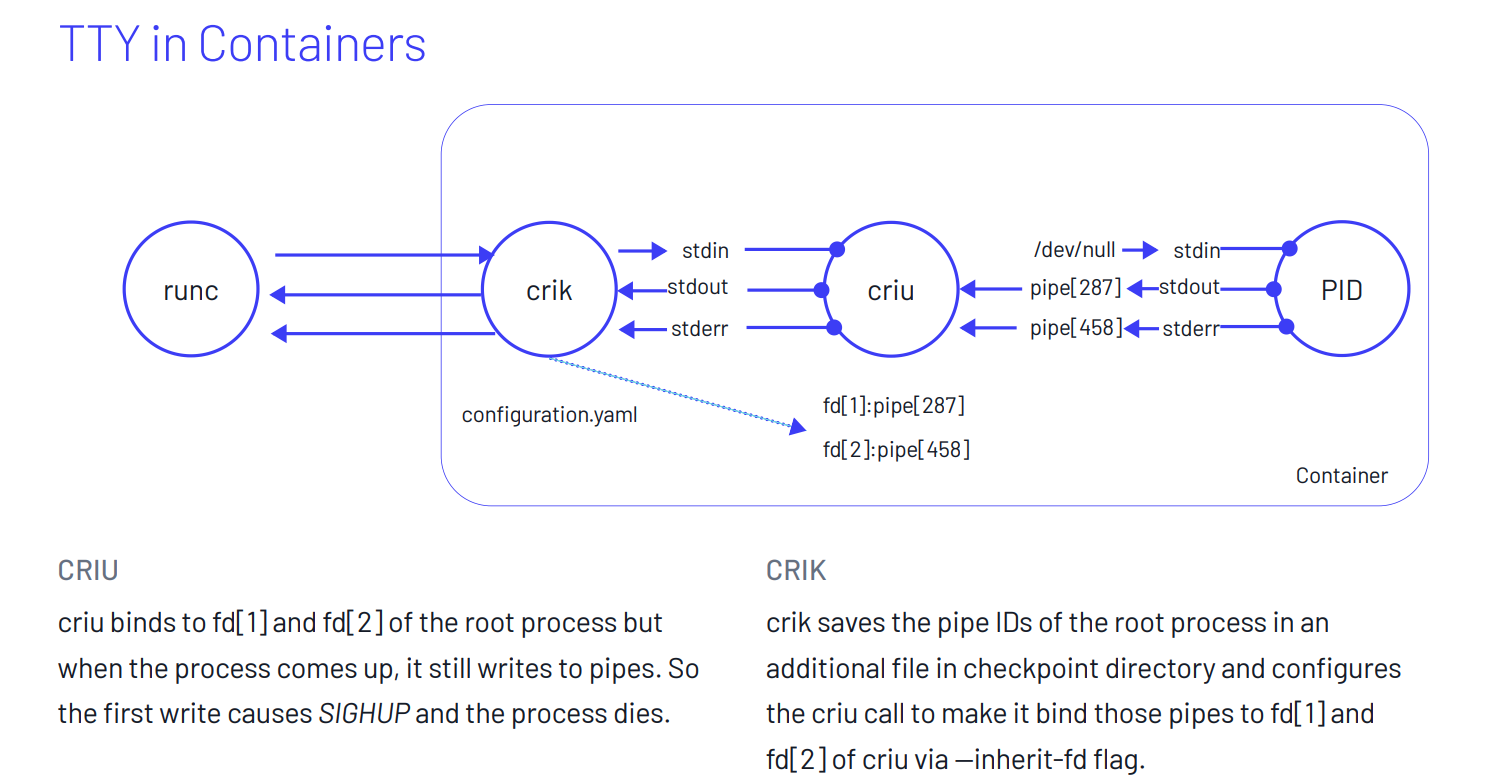
Utilisé dans un conteneur, crik permet alors d’attendre l'arrivée d’un SIGTERM pour créer un checkpoint du pod et ensuite reprendre son exécution dans un autre contexte tout en conservant les spécificités liées à son exécution.


