

Foundry est bien plus qu'une simple plateforme d'analyse de données. C'est une solution complète de bout en bout qui facilite la gestion, la transformation, l'analyse et la visualisation des données. Sa conception modulaire permet aux utilisateurs de s'adapter aux besoins spécifiques de leurs projets. Le tout en leur permettant de collaborer sur une plateforme cloud.
L’outil est développé par Palantir, une entreprise américaine éditant des solutions de stockage, de gestion et d’analyse de données. Ces logiciels sont utilisés à travers le monde et dans de nombreux secteurs d’activité (comme les services de renseignement aux Etats-Unis ou l’aviation en France).
Dans cet article, je vous présente quelques points importants à connaître avant de vous lancer dans vos premiers développements sur Foundry.
1. La transformation : le concept clé
La transformation est au cœur de l’outil pour l’ingénieur data puisqu’elle permet de traduire les besoins métiers en algorithme. Ce processus est défini par la transformation d'un ou plusieurs inputs, qui sont ensuite mappés vers un ou plusieurs outputs.
La plateforme offre la possibilité d’utiliser plusieurs langages de programmation, notamment Java, Python, Scala, R et SQL. La documentation est particulièrement détaillée pour Java et Python, ce qui permet de mieux appréhender leur utilisation avec les APIs de la plateforme et de trouver des exemples détaillant des cas d’utilisation.
Foundry étant dimensionnée pour traiter de gros volumes de données, les transformations utilisent le framework Spark afin de paralléliser les tâches.
Le fonctionnement
Par défaut, une transformation sera du type SNAPSHOT. L'outil lit intégralement les inputs, procède à la transformation des données et effectue un nettoyage de l'output avant d'écrire le résultat final.
Bien que ce mode soit efficace lorsque la lecture intégrale de l'input est souhaitée, il présente certaines limites. En particulier si de nouvelles données sont ajoutées à l'input. Le traitement ultérieur devra relire l’intégralité de l’input, imposant ainsi la nécessité de retraiter toutes les données. Cette approche devient peu optimale, surtout avec d'importants volumes de données.
La transformation INCREMENTAL permet de s'adapter à davantage de cas d’usages et donne la possibilité d'interpréter les entrants de façon plus détaillée.
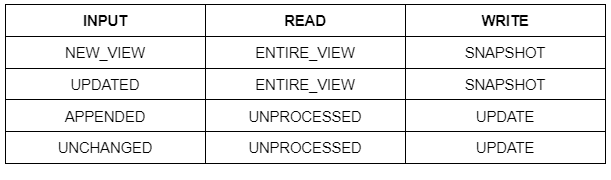
À l'exécution du programme, quand l'input sera lu, un statut sur son état sera remonté. Il peut prendre quatre valeurs différentes:
- NEW_VIEW : aucun des fichiers entrants n’a été traité par la transformation.
- UPDATED : les fichiers entrants ont été traités mais ils ont été modifiés.
- APPENDED : certains fichiers entrants ont été traités, d’autres non.
- UNCHANGED : aucun changement n’a eu lieu depuis la dernière transformation.
Grâce à ces types de modification, on peut définir une certaine stratégie de lecture et d’écriture.
Pour la lecture :
- ENTIRE_VIEW : le ou les entrants sont lus en intégralité.
- UNPROCESSED : seulement les fichiers non traités sont lus.
- PROCESSED : on ne lit que les fichiers qui ont déjà été traités.
Pour l’écriture :
- SNAPSHOT : l’output est vidé avant d’écrire le résultat de la transformation.
- INCREMENTAL : le résultat de la transformation est ajouté à ce qui est déjà présent dans l’output.
Pour illustrer ces différents types de modification, prenons le cas d’un supermarché. Tous les soirs, toutes les données créées dans la journée (achats, nouveaux clients, …) sont transformées et chargées dans la plateforme.
La transformation est configurée ainsi :
Le cas d’usage “classique” (si ce n’est pas le premier run ou bien que l’historique des fichiers n’a pas été modifié) sera qu’à chaque traitement, de nouveaux fichiers seront détectés (APPENDED). La plateforme lira ces nouveaux fichiers seulement (UNPROCESSED) et écrira le résultat de la transformation sans écraser l’existant (UPDATE).
Voici un exemple de code en Java avec un dataset “markets” en input.
Transformation SNAPSHOT
@Compute
public void compute(
@Input("path_to_input_dataset/markets")FoundryInput input,
@Output("path_to_output_dataset/hypermakets") FoundryOutput output) {
Dataset<Row> hypermarkets = input.asDataFrame().read().filter(col("supermaket_type").eq("hyper"));
output.getDataFrameWriter(hypermarkets).write();
}
Transformation INCREMENTAL
@Compute
public void compute(
@Input("path_to_input_dataset/markets")FoundryInput input,
@Output("path_to_output_dataset/hypermakets") FoundryOutput output) {
Dataset<Row> hypermarkets = input.asDataFrame().readForRange(getReadRange(input)).filter(col("supermaket_type").eq("hyper"));
output.getDataFrameWriter(hypermarkets).write(getWriteMode(input));
}
//Définition de la stratégie de lecture
private ReadRange getReadRange(FoundryInput input) {
switch (input.asDataFrame().modificationType()) {
case UNCHANGED:
return ReadRange.UNPROCESSED;
case APPENDED:
return ReadRange.UNPROCESSED;
case UPDATED:
return ReadRange.ENTIRE_VIEW;
case NEW_VIEW:
return ReadRange.ENTIRE_VIEW;
default:
throw new IllegalArgumentException("Unknown ModificationType for input dataset");
}
}
//Définition de la stratégie d'écriture
private WriteMode getWriteMode(FoundryInput input) {
switch (input.asDataFrame().modificationType()) {
case UNCHANGED:
return WriteMode.UPDATE;
case APPENDED:
return WriteMode.UPDATE;
case UPDATED:
return WriteMode.SNAPSHOT;
case NEW_VIEW:
return WriteMode.SNAPSHOT;
default:
throw new IllegalArgumentException("Unknown ModificationType for input dataset");
}
}
Note: cette partie s’applique pour les transformations en Java. Pour Python, la logique et les termes sont différents. Je vous invite à consulter la documentation.
2. Des outils qui simplifient la vie
Nous venons de voir comment transformer la donnée grâce à du code Java (et Python, si vous avez suivi le lien vers la documentation).
La plateforme met également à disposition de nombreux outils pour traiter et interagir avec les données.
Voici une liste non exhaustive des outils qui me semblait intéressant de partager :
- Code Workbook : pour créer des transformations rapidement sans avoir besoin de créer un répertoire de code Java ou Python.
- Contour : outil no/low code pour filtrer, analyser et visualiser des datasets.
- Quiver : outil d’analyse et de visualisation de données adapté pour les time series.
- Monocle : outil de data lineage qui permet également d’accéder aux options de scheduling.
- Notepad : bloc note dans lequel on peut intégrer des visuels Contour ou Quiver qui s’actualisent en temps réel.
- Workshop : pour créer des applications rapidement et facilement.
3. Mes conseils
Comme nous venons de le voir, la plateforme propose de nombreux outils clés en main et accessibles. Il pourrait être tentant de se lancer sans forcément prêter attention à leur fonctionnement. Toutefois, afin de les utiliser au mieux et de créer des traitements optimisés (je rappelle que l’on travaille avec de gros volumes de données), il reste important de faire attention à certains points. Voici donc mes derniers conseils :
- Les transformations étant basées sur le framework Spark, il est important de connaître son fonctionnement et avoir quelques notions sur son utilisation.
- Aussi, il est important de créer des transformations optimisées en termes d’utilisation des ressources et en temps de traitement. C’est pour cela qu’il est important d’avoir connaissance des techniques d’optimisation de Spark sur la plateforme. (voir Foundry usage optimization best practices).
- Vous avez peut-être remarqué que j’ai fait de nombreuses références à la documentation fournie par Palantir pour illustrer mes propos. C’est parce je la trouve bien faite et plutôt complète. Mon dernier conseil est donc de vous diriger vers celle-ci si vous souhaitez approfondir le sujet.
Dans cet article, je vous ai brièvement présenté Foundry, la plateforme data by Palantir.
L'utilisation de Spark offre la possibilité de traiter des volumes de données importants. Les deux modes de transformation (snapshot et incremental) permettent d'adapter le développement à une multitude de cas d’usages. Les outils intégrés tels que le Code Workbook, Notepad, Monocle ou Contour simplifient les opérations de visualisation, d'analyse ou de présentation des données.
Malgré ces fonctionnalités et outils clé en main, il est tout de même nécessaire d'apporter une certaine vigilance aux bonnes pratiques (notamment d'optimisation puisque l'objectif est de travailler avec de gros volumes de données).
Pour aller plus loin, je vous conseille le blog Palantir. J’ai particulièrement aimé les articles sur la gestion des ressources de la plateforme (Introducing Rubix: Kubernetes at Palantir, Spark Scheduling in Kubernetes, The Benefits of Running Kubernetes on Ephemeral Compute).
