

S’achève la semaine du “AWS re:Invent 2023”. Comme des milliers de “cloudeurs”, j’ai pu suivre avec beaucoup d'intérêt les conférences mises en ligne régulièrement au fil des jours.
Comme chaque année, le Leader du Cloud Public, AWS, nous a offert de nombreuses annonces. Vous pouvez trouver un résumé dans les articles de mes collègues, AWS re:Invent 2023 - Résumé des 2 premiers jours, et AWS re:Invent 2023 - Résumé des 2 derniers jours.
Dans cet article, je ne vous parlerai pas du service de “GenIA” d’AWS. Avec l’essor de ChatGPT, AWS se devait de répondre officiellement et faire ses annonces dans ce domaine technologique. Je vous invite à suivre sur notre blog notre temps fort “GenIA” et les articles de mes autres collègues qui vous décriront bien mieux que moi les “taux d’hallucinations” et autres “LLM”, tous ces termes qu’on peut trouver barbare quand on ne les manipule pas au quotidien.
Non, aujourd’hui, à travers 2 articles, je voulais vous présenter 3 conférences qui m’ont particulièrement intéressées.
AWS re:Invent 2023 - Building observability to increase resiliency (COP343)
Lien Youtube : ici
Je ne m’étendrai pas sur cette conférence, le temps me manquant. Mais je vous invite fortement à la regarder, si vous êtes un “SRE” (Site Reliability Engineer) comme moi. On y retrouve tous les principes et bonnes pratiques autour de l’observabilité. Mais surtout, avec des exemples concrets, on nous explique comment réagir aux différents problèmes que nous sommes amenés à rencontrer et notamment :
- Les problèmes de dépendance de notre application;
- Les problèmes liés à un composant de l’application;
- Les problèmes liés à une montée de version;
- Les problèmes liés à des montées en charge;
- Et bien d’autres choses encore.
Nous avons déjà tous créé nos dashboards CloudWatch, fouillé dans les dimensions et les métriques disponibles de nos composants d’application, créé nos propres alarmes CloudWatch. Mais, dans cette conférence, vous y retrouverez toutes les astuces pour observer des événements sur des bases “stables” (utilisation des taux d’erreurs, des taux d’erreurs par client). La combinaison des CustomMetrics avec CloudWatch Insights permet d’appréhender plus facilement les difficultés de l’observabilité et réduire les faux-positifs. Finalement, David Yanacek nous donne les clés pour utiliser les bons services et les bonnes métriques dans les bons cas d’utilisation pour une meilleure observabilité des applications que nous opérons.
A voir absolument.
AWS re:Invent 2023 - Introducing Amazon ElastiCache Serverless (DAT342)
Lien Youtube : ici
Actuellement en mission pour un client qui a démarré sa stratégie de “Move To Cloud”, et après avoir réussi haut la main cette transition vers le cloud AWS, nous travaillons actuellement à améliorer et “refactorer” son application afin de bénéficier des nouvelles opportunités que peut lui apporter le Cloud. Et, coïncidence, nous sommes actuellement en cours de mise en œuvre d’une brique de “caching”, basée sur Elasticache. C’est donc tout naturellement que je me suis empressé de voir les nouvelles annonces autour de ce service.
Avant de pouvoir déployer cette brique de cache, je dois faire valider l’aspect “FinOps”. Le “business” me demande : “Ça va me couter combien ?”. Et bien “Il faut déterminer au plus juste la capacité de notre cluster, la taille des instances et le nombre de “read-replicas” ai-je répondu. Et c’est exactement ce par quoi commence cette conférence : les difficultés autour du “capacity planning”. C’est illustré par le graphique suivant :
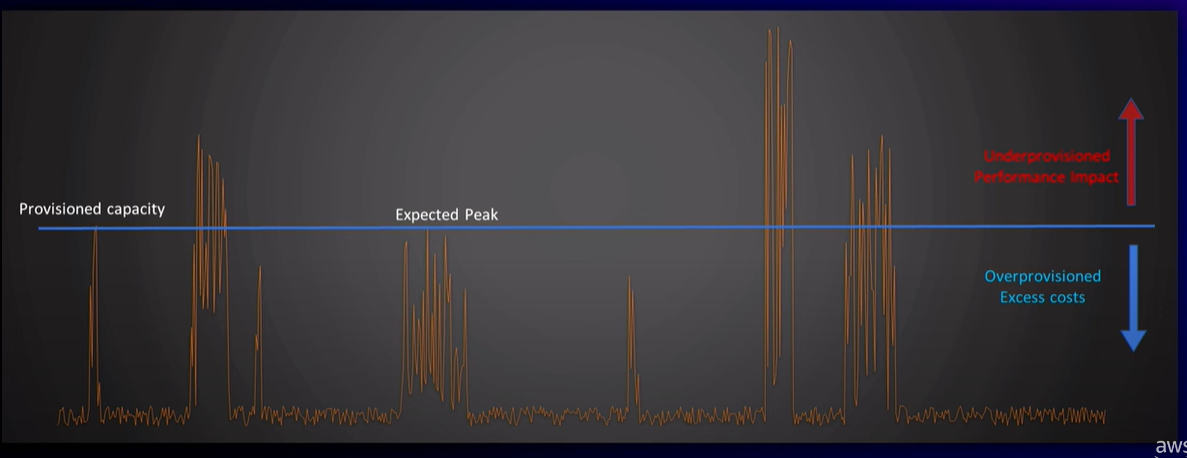
Définir à l’avance nos besoins est un travail difficile, voire impossible. Soit on peut se permettre de tailler large et donc, “payer plus” que nos besoins réels, soit on taille au plus juste, avec le risque d’avoir de la contention lorsque les pics de trafic surviennent. D’autre part, ce qui est vrai à un instant t, peut ne plus l’être à un instant t+1 (pendant un “black friday” ou à Noël par exemple). Alors oui, il est toujours possible de réajuster son cluster mais il faut “suer” pour écrire les runbooks qui nous permettront de faire ces opérations.
Bref, une fois encore, AWS a compris qu’être “Customer Centrics” c’est proposer des solutions qui permettent de répondre au mieux aux difficultés de leurs clients.
Avec “ElastiCache Serverless”, cette problématique de “capacity planning” n’existe simplement plus. Le service se charge de mettre en place tout le monitoring nécessaire pour scaler horizontalement, verticalement, gérer le nombre de shards pour nous, les pannes (et oui ça arrive) et l’indisponibilité des nœuds durant les maintenances. La mise en place d’un cache applicatif devient maintenant vraiment simple : on définit un “nom”, le nombre d’AZ et c’est tout !!
Une fois créé, nous nous retrouvons avec un unique “endpoint” pour interagir avec notre cache. Toute la tuyauterie est gérée de manière transparente par AWS. Notez que ce service est disponible d’une part sur toutes les régions AWS et que d’autre part, il supporte les 2 types de stacks, memcached et redis.
ElastiCache Serverless en 1 minute
Prenons une minute pour regarder les principaux apports de cette solution :

Que dire de plus ? ElastiCache Serverless supporte le chiffrement en transit et au repos.
Pour résumer : le service AWS ElastiCache Serverless s’occupe pour nous de déployer des nœuds d’une certaine taille, de les “scaler” quand c’est nécessaire, de les réduire quand c’est nécessaire, de “rebalancer les données” quand c’est nécessaire (perte d’un nœud, maintenance, etc ...).
Quelles contraintes côté application ?
Finalement très peu. Le cluster ElastiCache est accessible depuis un unique “endpoint”.
L’application n’a aucune connaissance de la topologie du cluster sous-jacent et c’est tant mieux !
Pay-per-use : Le modèle de facturation est basé sur les 2 métriques suivantes :
- Stockage (facturation à l’heure en fonction du nombre de GB utilisé)
- ECPUs : facturation au “ElastiCache Processing Units”. L’utilisation de fonctions d'agrégation (sort, average, etc ..) seront comptabilisées en plus du temps CPU pour récupérer un set de données.
Performance :

Les chiffres parlent d’eux-mêmes !
“AZ Affinity & Read-Replicas” :
De part le fait que nous définissons plusieurs AZs sur lesquelles le cluster AWS ElastiCache Serverless est déployé, pour bénéficier des meilleures performances, il faut mettre en place une sorte d’affinité d’AZ. Si notre conteneur EKS est sur l’AZa, il faut dialoguer par défaut sur cette AZ : meilleure performance, pas de coût issu d’un trafic inter-AZ. Comment faisons-nous cela ? Très simplement : C’est le “endpoint” qui le fait pour nous !
Néanmoins, pour de meilleures performances, il est préférable de faire les lectures sur les read-replicas plutôt que sur les “masters”. Et cela se fait côté client. Cela est illustré par le code suivant :

“Support des versions” :
Le service AWS ElastiCache Serverless est disponible pour
- Redis version 7.1
- Memcached version 1.6.22
Sous le capot
Pour ceux qui sont curieux de savoir ce qu’il se passe sous le capot, je ne peux que vous conseiller de regarder la vidéo elle-même et de vous laisser guider par Yaron Sananes, mais voici les principaux points :
Le système “interne” :
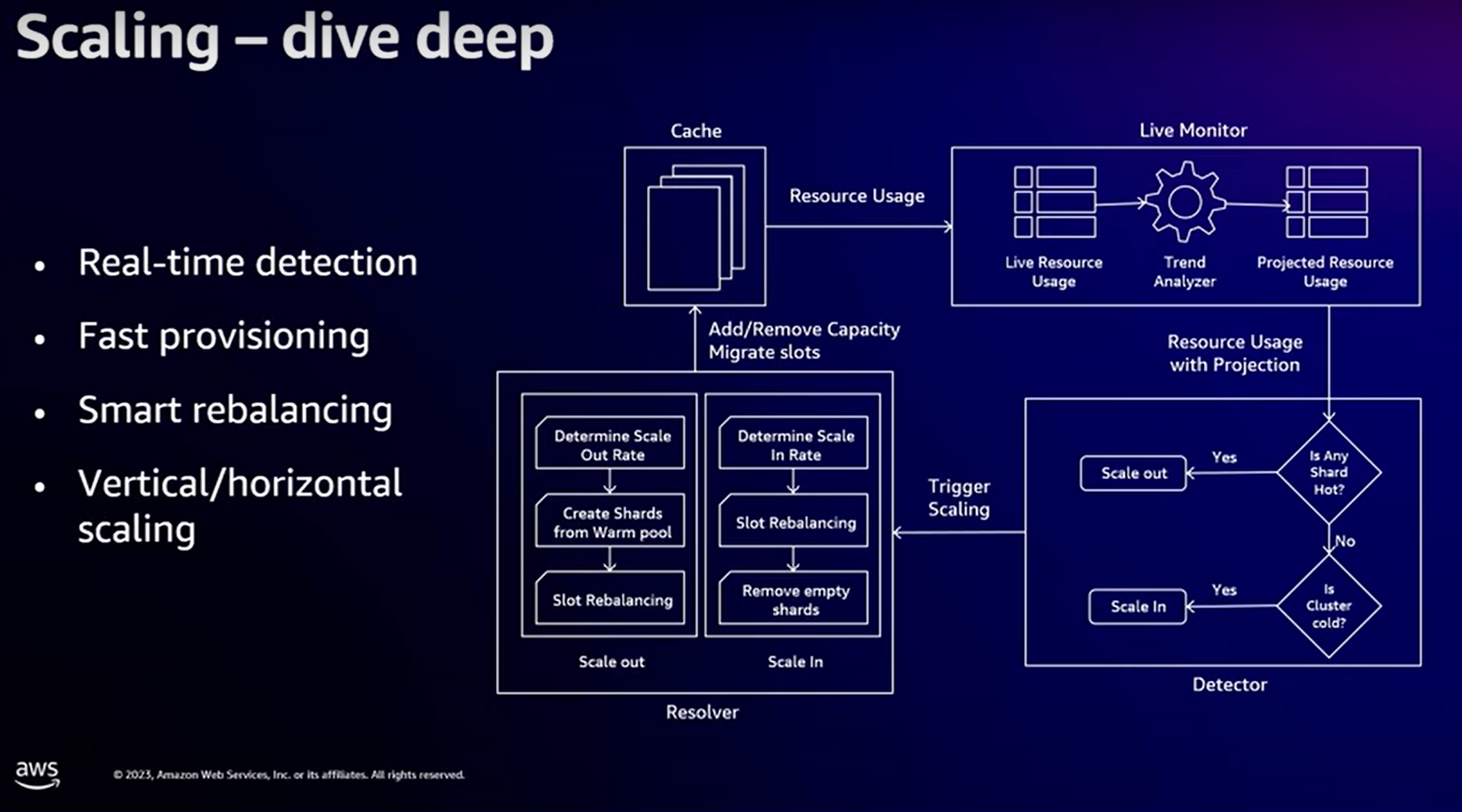
Notez que :
le “Live Monitor” utilise des algorithmes de prédiction. Par conséquent, le “scale-up” se déclenche normalement avant que votre pic de trafic arrive effectivement.
La gestion du “Fast Provisionning” se base sur des fermes de serveurs “Caspian”. C’est une technologie développée en interne par AWS, déjà utilisée dans les stacks “serverless”, permettant de ne plus fixer la taille mémoire & cpu d’un nœud à sa création (!)
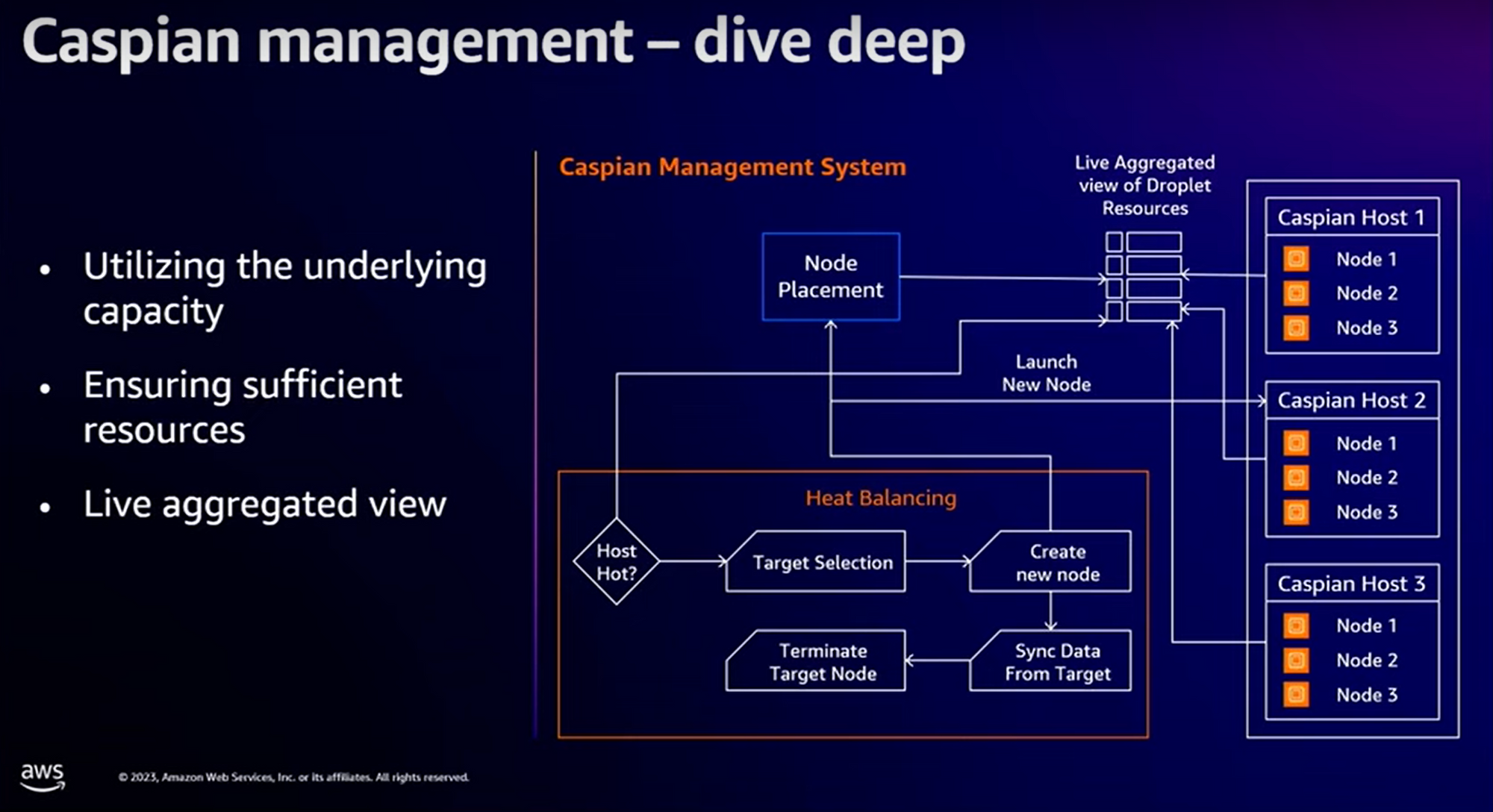
Les nouvelles machines qui doivent intégrer un cluster sont “chauffées”, récupèrent les données depuis un des nœuds du cluster (un algorithme spécifique a été développé pour minimiser la perturbation induit par la synchronisation des données).
Et enfin, le “proxy” qui est le composant exposé à travers le endpoint du cluster ElastiCache Serverless :
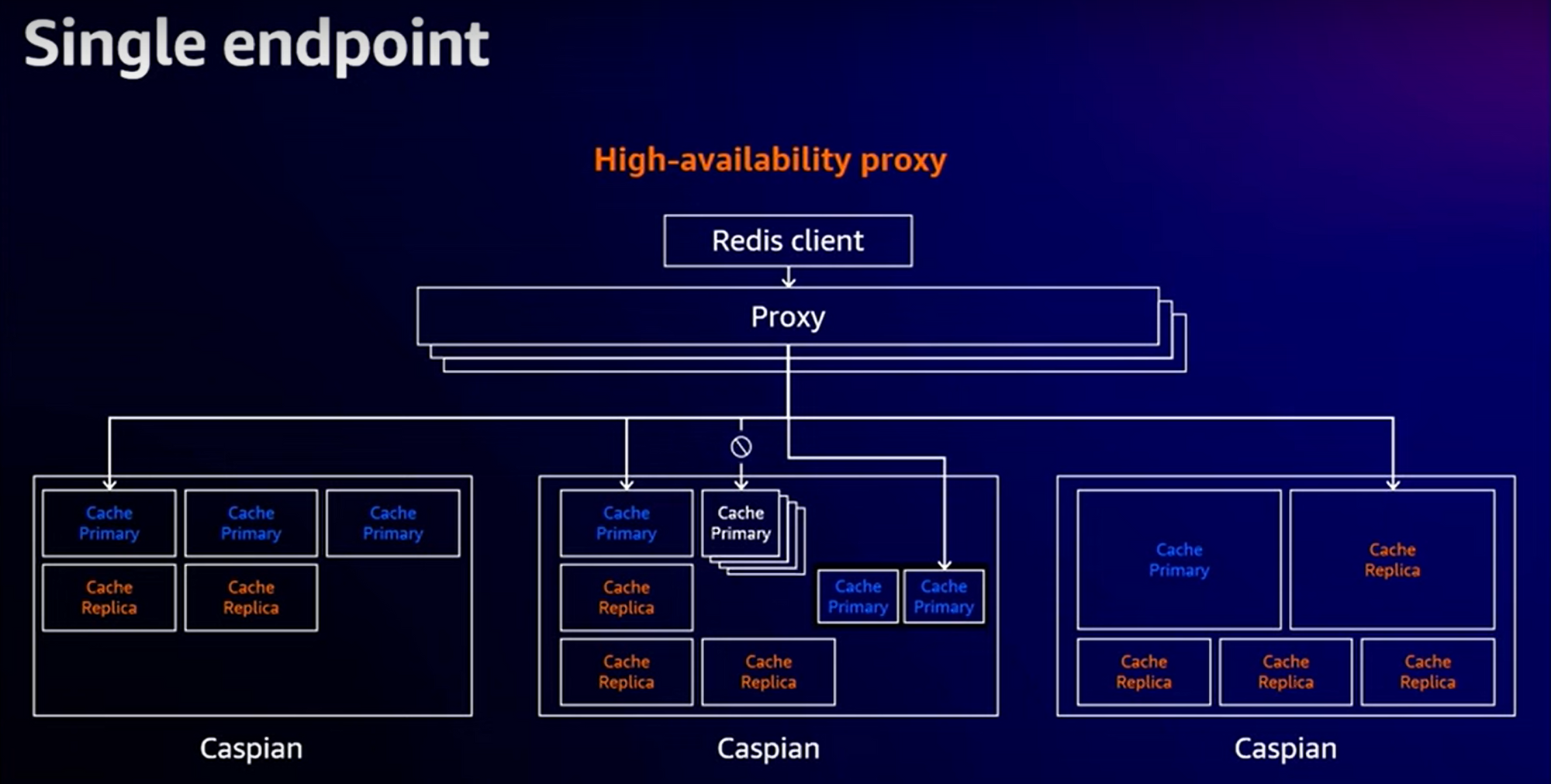
Notez que le proxy utilise une couche de “multiplexage” réseau permettant de réutiliser les connexions réseau et encapsuler plusieurs commandes à l’intérieur. Et enfin, le diagramme général avec la mise en oeuvre de la Haute-Disponibilité et de l’affinité par AZ :
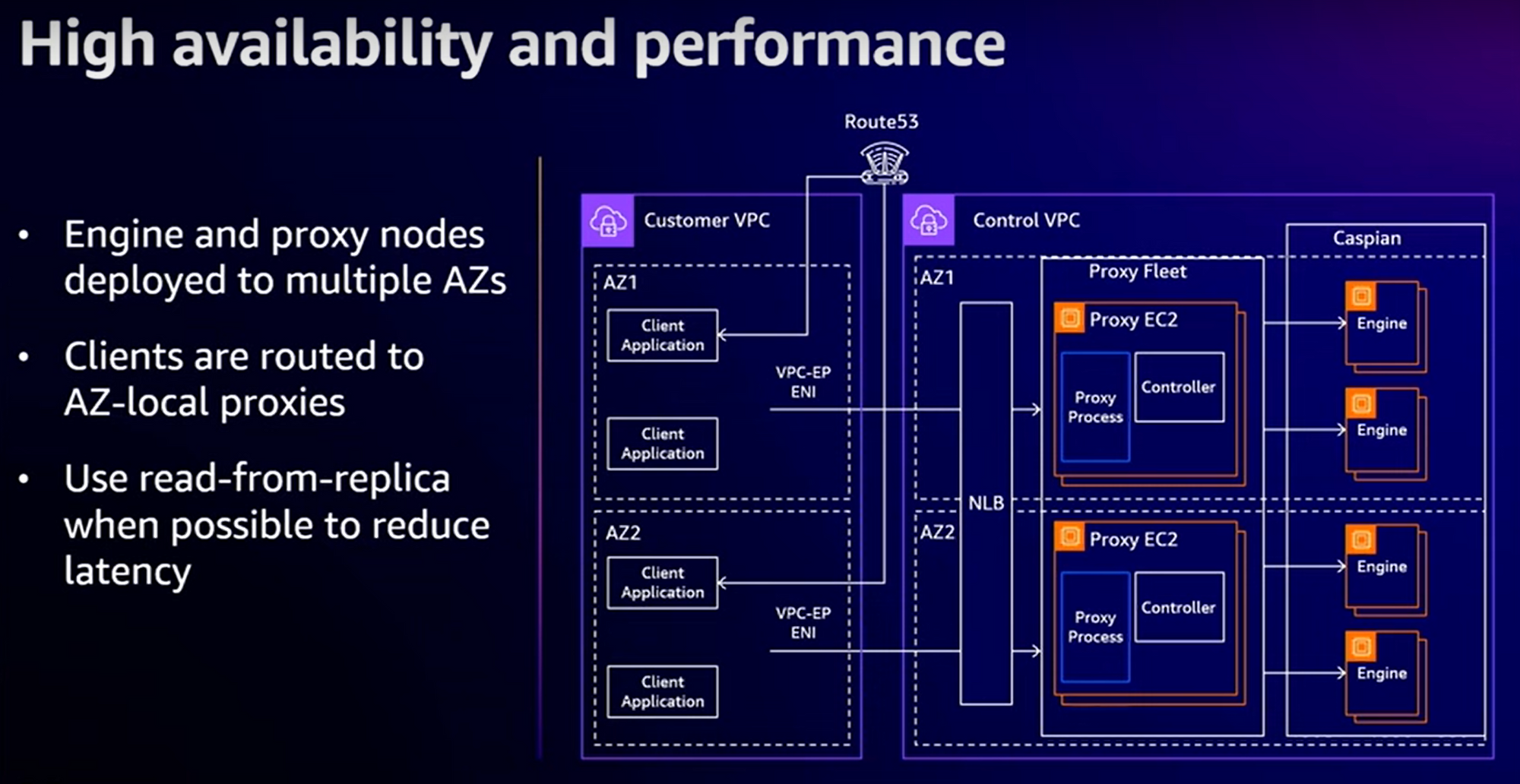
Conclusion
Vous avez compris : je suis emballé par ce nouveau service parce qu’il répond clairement à une problématique assez difficile à adresser : le “capacity planning”.
Si on ne doit retenir qu’une seule chose de ce nouveau service, c’est le fait de ne plus avoir à s’occuper du “capacity planning”. Ce n’est pourtant pas le 1er service à offrir cette possibilité (Redshift Serverless, RDS Aurora Serverless, OpenSearch Serverless). En revanche, de mon expérience personnelle, dans les départements “Operations IT”, on met les moyens techniques et humains sur les entrepôts de données, les bases de données, mais beaucoup moins sur les briques de cache. En utilisant un service tel qu’AWS ElastiCache Serverless, on enlève une pression certaine sur les équipes de run.
Reste néanmoins l'aspect coût : en délégant la partie "capacity planning" aux algorithmes gérant la topologie du cluster, on espère que le coût en "réaction aux pics" sera acceptable en regard d'un sizing plus stable géré par les équipes de Run.
