

Introduction
Dans le monde Kubernetes, nous avons le besoin de mettre à l’échelle nos applications, en utilisant par exemple la ressource HorizontalPodAutoscaler, mais nous avons aussi besoin de mettre à l’échelle nos clusters en y ajoutant ou retirant des serveurs.
Pour cela, la solution habituelle pour mettre à l’échelle de manière automatique un cluster Kubernetes est le cluster autoscaler.
Karpenter vient challenger cette approche en apportant davantage de réactivité et de souplesse en gérant un pool hétérogène de nœuds.
Dans cet article, nous allons détailler cette nouvelle solution et montrer sa mise en place ainsi que ses avantages avec un pool qui mettra à disposition des nœuds pour exécuter des runners GitLab.
Karpenter étant actuellement seulement disponible pour des clusters EKS gérés par AWS, cet article traitera principalement de ce type de clusters Kubernetes.
État de l’art - Cluster autoscaler
Avant l’arrivée de Karpenter, la solution recommandée pour mettre à l’échelle de manière automatique un cluster EKS était le cluster autoscaler.
Cette solution permet d’ajuster le nombre de nœuds d’un groupe de nœuds gérés (managed node group) en fonction de la charge requise (containers requests) par les applications déployées dans le cluster.
Cependant, cette solution a un problème majeur : sa flexibilité. En effet, les nouveaux nœuds ont exactement la même configuration que les autres nœuds d’un même groupe de nœuds gérés, et nous n’avons pas le contrôle sur la taille de l’instance, le type de capacité (à la demande, spot, etc), ou encore la zone de disponibilité dans laquelle elle est créée. Ainsi, nous pouvons nous retrouver avec un nœud d’une taille considérable pour faire tourner une seule application qui ne pourrait pas être placée sur les autres nœuds par manque de place, et donc avec des instances potentiellement sous utilisées.
Une solution serait alors d’utiliser plusieurs groupes de nœuds gérés, mais nous allons voir que nous pouvons faire bien mieux…
Une nouvelle solution - Karpenter
Pour pallier les limitations du cluster autoscaler, AWS a développé Karpenter, disponible sous licence open source Apache License 2.0 : https://github.com/aws/karpenter.
Concepts
Avant de découvrir les avantages de cette solution, il est important d’en comprendre les concepts.
Karpenter vient avec la notion de NodePools, qui permettent de définir des contraintes sur les nœuds que peut créer Karpenter. Il est ainsi possible de définir des labels, des annotations, des taints, les types d’instances souhaités (type de capacité, famille, taille, etc), la configuration de Kubelet sur les nœuds qui vont être créés, ou encore le délai avant expiration du nœud.
De plus, il est important de noter que les NodePools ont une notion de poids. Ainsi, si un pod nouvellement créé correspond à plusieurs NodePools, celui ayant le poids le plus élevé est sélectionné.
Karpenter propose également des NodeClasses, qui permettent de configurer les instances qui vont être créées (sous réseau, groupe de sécurité, AMI, tags, etc). Cette notion peut être comparée aux modèles de lancement (launch templates) d’AWS. Dans notre exemple, nous utiliserons des NodeClasses de type EC2NodeClass.
Avantages
Maintenant que nous avons vu les principaux concepts de Karpenter, nous allons voir les nombreux avantages qu’il propose.
Tout d’abord, Karpenter adapte le type d’instances en fonction de la charge des applications. Par exemple, si nous souhaitons déployer une application ne nécessitant pas beaucoup de ressources, Karpenter va choisir une instance de petite taille, et inversement. Mais il ne s’arrête pas là ! Il adapte les types d’instances en continu, permettant de toujours avoir une configuration adéquate avec la charge requise (containers requests), tout en minimisant le prix : il va toujours préférer la configuration la moins coûteuse.
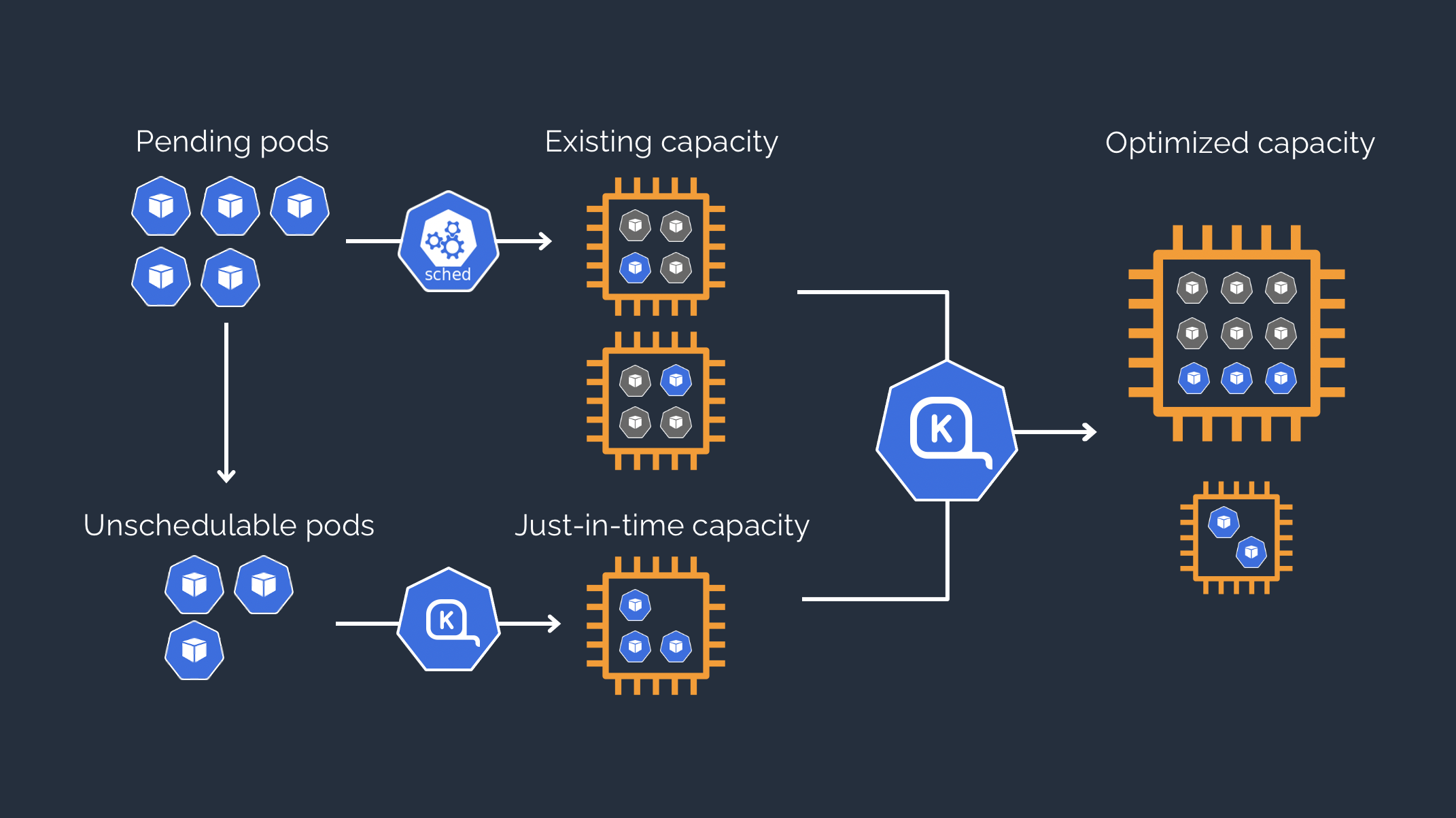
Karpenter est par ailleurs très flexible, pouvant gérer plusieurs NodePools. Il permet notamment de sélectionner précisément le type d’instance, par exemple une instance spot de petite taille dans la zone de disponibilité A et ayant une architecture ARM, et ce grâce aux labels connus. Cela permet de choisir finement le type de nœud et d’instance souhaités, et ce même si on ne dispose que d’un seul NodePool.
Enfin, un avantage considérable de Karpenter est sa rapidité, autant à la création qu’à la suppression de nœuds. En effet, il ne passe pas par des groupes de nœuds gérés, mais il instancie directement des EC2 via l’API d’AWS. Aussi, il est capable d’associer des pods à des nœuds en cours de création, lui permettant d’anticiper la charge requise et d’instancier de nouveaux nœuds si nécessaire, sans avoir à attendre qu’un nœud soit prêt avant d’en instancier un autre. En ce qui concerne la suppression de nœuds, ces derniers seront automatiquement supprimés au maximum 30 secondes après avoir été considérés comme étant vide ou sous utilisés. Il est également possible de personnaliser ce délai dans la définition du NodePool utilisé.
Inconvénients
Bien que Karpenter possède de nombreux avantages, il possède également quelques inconvénients qu’il est important de noter.
En premier lieu, cette solution n’est actuellement disponible que pour des clusters EKS sur AWS. Karpenter est conçu pour supporter plusieurs types de cluster Kubernetes et notamment plusieurs fournisseurs de services cloud, mais ce n’est pas encore le cas.
Par ailleurs, vos applications doivent être cloud native, c’est-à-dire avoir un cold start relativement faible et supporter les arrêts et redémarrages fréquents. En effet, comme nous l’avons vu, Karpenter est très réactif et ajuste en continu les nœuds en fonction de la charge, ce qui peut avoir pour effet l’extinction et la création de nœuds de manière répétée et fréquente, et ainsi la suppression et création des pods se trouvant sur ces nœuds.
Il est fortement recommandé d’avoir au minimum 2 réplicas sur vos Deployments, et d’utiliser des Pod Disruption Budget afin d’éviter toute coupure de service pour vos utilisateurs. En effet, Karpenter prend en compte et respecte les Pod Disruption Budget.
Mettre en place Karpenter dans son cluster EKS
Maintenant que vous en savez plus, nous allons passer à la pratique en mettant en place Karpenter dans un cluster EKS.
Prérequis
Vous devez disposer d’un cluster EKS avec un groupe de nœuds gérés afin de pouvoir déployer les pods du contrôleur de Karpenter (le programme qui est responsable de la mise à l’échelle du cluster).
Créer un rôle IAM pour Karpenter
Afin de pouvoir créer des instances, nous devons tout d’abord créer un rôle IAM qui sera assumé par le service account associé aux pods de Karpenter. Il s’agit ici de la mécanique de IAM Roles for Service Accounts (IRSA), décrite dans cet article de Timothée AUFORT.
Pour ce faire, nous devons disposer d’un OpenID Connect Provider associé à notre cluster EKS, et qui peut être déployé avec le code Terraform suivant :
data "tls_certificate" "eks_cluster_certificate" {
url = aws_eks_cluster.eks_cluster.identity[0].oidc[0].issuer
}
resource "aws_iam_openid_connect_provider" "eks_cluster_openid_connect_provider" {
client_id_list = ["sts.amazonaws.com"]
thumbprint_list = [data.tls_certificate.eks_cluster_certificate.certificates[0].sha1_fingerprint]
url = aws_eks_cluster.eks_cluster.identity[0].oidc[0].issuer
}
Ensuite, nous pouvons créer un rôle IAM qui sera assumable par le service account karpenter dans le namespace Kubernetes karpenter :
data "aws_iam_policy_document" "karpenter_controller_assume_role_policy" {
statement {
actions = ["sts:AssumeRoleWithWebIdentity"]
effect = "Allow"
condition {
test = "StringEquals"
variable = "${replace(var.eks_cluster_openid_connect_provider_url, "https://", "")}:sub"
values = ["system:serviceaccount:karpenter:karpenter"]
}
principals {
identifiers = [var.eks_cluster_openid_connect_provider_arn]
type = "Federated"
}
}
}
resource "aws_iam_role" "karpenter_controller_iam_role" {
name = lower("${var.tf_stack}-${var.environment}-karpenter-controller")
assume_role_policy = data.aws_iam_policy_document.karpenter_controller_assume_role_policy.json
tags = {
Name = lower("${var.tf_stack}-${var.environment}-karpenter-controller")
}
}
Enfin, nous associons à ce rôle IAM la politique IAM suivante, recommandée dans la documentation de Karpenter :
resource "aws_iam_policy" "karpenter_controller_iam_policy" {
name = lower("${var.tf_stack}-${var.environment}-karpenter-controller")
policy = jsonencode({
"Version" : "2012-10-17",
"Statement" : [
{
"Effect" : "Allow",
"Action" : [
"ssm:GetParameter",
"ec2:DescribeImages",
"ec2:RunInstances",
"ec2:DescribeSubnets",
"ec2:DescribeSecurityGroups",
"ec2:DescribeLaunchTemplates",
"ec2:DescribeInstances",
"ec2:DescribeInstanceTypes",
"ec2:DescribeInstanceTypeOfferings",
"ec2:DescribeAvailabilityZones",
"ec2:DeleteLaunchTemplate",
"ec2:CreateTags",
"ec2:CreateLaunchTemplate",
"ec2:CreateFleet",
"ec2:DescribeSpotPriceHistory",
"iam:CreateInstanceProfile",
"iam:TagInstanceProfile",
"iam:AddRoleToInstanceProfile",
"iam:GetInstanceProfile",
"iam:DeleteInstanceProfile",
"pricing:GetProducts"
],
"Resource" : "*"
},
{
"Effect" : "Allow",
"Condition" : {
"StringLike" : {
"ec2:ResourceTag/karpenter.sh/nodepool" : "*"
}
},
"Action" : "ec2:TerminateInstances",
"Resource" : "*"
},
{
"Effect" : "Allow",
"Action" : "iam:PassRole",
"Resource" : "${var.nodes_iam_role_arn}"
},
{
"Effect" : "Allow",
"Action" : "eks:DescribeCluster",
"Resource" : "${var.eks_cluster_arn}"
}
]
})
tags = {
Name = lower("${var.tf_stack}-${var.environment}-karpenter-controller")
}
}
Ici, la variable nodes_iam_role_arn fait référence à l’ARN du rôle IAM attribué au groupe de nœuds gérés, créé en même temps que le cluster EKS et qui possède les politiques IAM suivantes :
- arn:aws:iam::aws:policy/AmazonEKSWorkerNodePolicy
- arn:aws:iam::aws:policy/AmazonEKS_CNI_Policy
- arn:aws:iam::aws:policy/AmazonEC2ContainerRegistryReadOnly
Installer Karpenter
Nous pouvons à présent installer Karpenter dans notre cluster EKS à l’aide du chart Helm officiel et de la commande suivante :
helm install karpenter oci://public.ecr.aws/karpenter/karpenter \
--namespace karpenter \
--create-namespace \
--set serviceAccount.annotations.eks\.amazonaws\.com/role-arn=${KARPENTER_IAM_ROLE_ARN} \
--set settings.clusterName=${CLUSTER_NAME} \
--set settings.clusterEndpoint=${CLUSTER_ENDPOINT}
Créer notre premier NodePool et notre première EC2NodeClass
Afin que Karpenter soit en mesure de créer de nouveaux nœuds, nous avons besoin d’au moins un NodePool ainsi que son EC2NodeClass associée.
Nous pouvons donc créer le NodePool par défaut suivant :
apiVersion: karpenter.sh/v1beta1
kind: NodePool
metadata:
name: default
spec:
template:
metadata:
labels:
role: general
spec:
nodeClassRef:
apiVersion: karpenter.k8s.aws/v1beta1
kind: EC2NodeClass
name: default
startupTaints:
- key: node.cilium.io/agent-not-ready
value: "true"
effect: NoExecute
requirements:
- key: "karpenter.sh/capacity-type"
operator: In
values: ["on-demand"]
- key: karpenter.k8s.aws/instance-family
operator: In
values: ["m6g"]
- key: karpenter.k8s.aws/instance-size
operator: In
values: ["medium", "large", "xlarge"]
- key: "kubernetes.io/arch"
operator: In
values: ["arm64"]
limits:
cpu: "50"
memory: 200Gi
disruption:
consolidationPolicy: WhenUnderutilized
expireAfter: 168h # 24 * 7
Ici, nous associons à ce NodePool l’EC2NodeClass “default” (que nous créons juste après) grâce à la clé nodeClassRef.
Nous définissons également le label role=general qui sera attribué aux noeuds créés par ce NodePool, ainsi que des contraintes sur les types d’instances à utiliser. Les contraintes spécifiées seront également présentes sous forme de labels sur les nœuds créés par ce NodePool, afin de pouvoir sélectionner finement les types d’instances souhaités en utilisant les notions de NodeSelector et NodeAffinity au niveau des pods (nous verrons cela plus en détail dans la suite de cet article). Si nous ne mettons pas de NodeSelector ou de NodeAffinity sur nos pods afin de préciser le type de capacité souhaité, Karpenter choisira toujours la configuration la moins coûteuse.
Nous définissons aussi des limites générales afin de limiter le nombre de nœuds créés par ce NodePool.
Enfin, nous utilisons la politique de consolidation WhenUnderutilized afin que Karpenter optimise le nombre et le type des instances en fonction de la charge, et supprime tout nœud vide ou sous utilisé en 30 secondes maximum.
Nous pouvons ensuite créer l’EC2NodeClass “default” :
apiVersion: karpenter.k8s.aws/v1beta1
kind: EC2NodeClass
metadata:
name: default
spec:
amiFamily: AL2
role: karpenter-test-demo-nodes
subnetSelectorTerms:
- tags:
kubernetes.io/cluster/karpenter-test-demo: owned
kubernetes.io/role/internal-elb: "1"
securityGroupSelectorTerms:
- tags:
kubernetes.io/cluster/karpenter-test-demo: owned
tags:
Name: karpenter-test-demo-default-node
blockDeviceMappings:
- deviceName: /dev/xvda
ebs:
volumeSize: 30Gi
volumeType: gp3
encrypted: true
deleteOnTermination: true
Ici, nous sélectionnons la famille d’AMI AL2 pour Amazon Linux 2, et précisons le rôle IAM à associer aux EC2. Par ailleurs, nous utilisons des tags associés aux sous-réseaux privés utilisés par le cluster EKS afin que les instances y soient créées. Nous sélectionnons également le groupe de sécurité créé par défaut lors de la création du cluster, et précisons le type d’EBS à associer aux EC2.
Voilà ! Vous avez à présent la configuration minimale afin de mettre à l’échelle votre cluster EKS avec Karpenter.
Mettre en place plusieurs NodePools
L’intérêt de Karpenter étant la possibilité d’utiliser plusieurs NodePools, nous allons en créer un second avec un cas concret : le besoin d’exécuter des jobs GitLab avec les GitLab runners et l’executor kubernetes.
apiVersion: karpenter.sh/v1beta1
kind: NodePool
metadata:
name: gitlab-runner-ci
spec:
template:
metadata:
labels:
role: gitlab-runner-ci
spec:
nodeClassRef:
apiVersion: karpenter.k8s.aws/v1beta1
kind: EC2NodeClass
name: gitlab-runner-ci
startupTaints:
- key: node.cilium.io/agent-not-ready
value: "true"
effect: NoExecute
taints:
- key: gitlab-runner-ci
value: "true"
effect: NoSchedule
requirements:
- key: "karpenter.sh/capacity-type"
operator: In
values: ["spot"]
- key: karpenter.k8s.aws/instance-family
operator: In
values: ["m6g", "m6i"]
- key: karpenter.k8s.aws/instance-size
operator: In
values: ["large", "xlarge"]
- key: "kubernetes.io/arch"
operator: In
values: ["arm64", "amd64"]
limits:
cpu: "50"
memory: 200Gi
disruption:
consolidationPolicy: WhenEmpty
consolidateAfter: 30m
expireAfter: 1h
Ici, nous associons ce NodePool avec une EC2NodeClass différente de celle par défaut : gitlab-runner-ci. Il s’agit de la même EC2NodeClass que celle par défaut et créée précédemment, à la différence du tags.Name qui nous permet de différencier les EC2 des différents NodePools dans la console AWS : “karpenter-test-demo-gitlab-runner-ci-node” et “karpenter-test-demo-default-node”.
Nous utilisons également un label role différent, à savoir gitlab-runner-ci, ainsi qu’un taint, afin de sélectionner les pods pouvant être placés sur ce type de nœuds.
Aussi, nous utilisons seulement le type de capacité “spot”, et autorisons des instances ARM64 et AMD64, pouvant être utiles lors de builds Docker multi architectures par exemple.
Enfin, au lieu d’utiliser la politique de consolidation WhenUnderutilized, nous utilisons la politique WhenEmpty avec un consolidateAfter à 30 minutes afin que les nœuds ne soient pas supprimés 30 secondes après être vides ou sous utilisés, dans le but d’optimiser le temps d’attente des jobs GitLab (encore une fois, ce n’est qu’un exemple de ce qu’il est possible de faire).
Et voilà ! Nous pouvons désormais utiliser ce NodePool pour nos pods de gitlab-runner pour différents cas d’usages. Par exemple, nous pouvons déployer deux gitlab-runner, un utilisant l’architecture ARM64, et l’autre utilisant l’architecture AMD64.
Pour ce faire, il suffit d’utiliser respectivement les configurations suivantes dans les values du chart gitlab-runner :
[[runners]]
[runners.kubernetes]
[runners.kubernetes.node_selector]
"role" = "gitlab-runner-ci"
"kubernetes.io/arch" = "arm64"
[runners.kubernetes.node_tolerations]
"gitlab-runner-ci=true" = "NoSchedule"
et
[[runners]]
[runners.kubernetes]
[runners.kubernetes.node_selector]
"role" = "gitlab-runner-ci"
"kubernetes.io/arch" = "amd64"
[runners.kubernetes.node_tolerations]
"gitlab-runner-ci=true" = "NoSchedule"
Comme vous pouvez le constater, Karpenter va utiliser les labels présents dans le nodeSelector des pods afin de déterminer quel NodePool utiliser, mais aussi quel type d’instance utiliser parmi ceux listés dans sa configuration.
Conclusion
Nous avons vu dans cet article les différences entre le cluster autoscaler et Karpenter lorsqu’il s’agit de mettre à l’échelle des clusters EKS. Comme vous pouvez le constater, Karpenter s’avère être beaucoup plus flexible, tout en apportant une certaine rapidité et efficacité, qu’il s’agisse de scale out ou de scale in. De plus, de part sa flexibilité avec les types d'instances et son fonctionnement qui optimise en continu le cluster en fonction de la charge, Karpenter permet de faire des économies en évitant de sous utiliser des instances, et ça, c’est bon pour le portefeuille mais aussi et surtout pour la planète !
J’espère donc vous avoir donné une bonne première vision de cet outil très prometteur, et vous encourage vivement à le mettre en place sur vos clusters EKS !
