

Introduction
Si comme moi, vous êtes intéressés par les questions liées à la qualité des données, vous avez probablement entendu parler de la DRE Con. Cependant, si contrairement à moi, vous aviez des choses à faire le 19 avril au soir, vous n’avez probablement pas pu voir les conférences proposées lors de cette édition 2023. Je vous rassure tout de suite, j’ai deux excellentes nouvelles pour vous :
- la première, c’est que cet article est là pour vous résumer rapidement cette édition de la DRE Con ;
- la seconde, c'est que les talks devraient être disponibles dans quelque temps sur la chaîne Youtube de Bigeye.
En attendant que tout cela soit disponible, je vous laisse avec ce résumé de mes talks préférés de la soirée, en espérant que celui-ci attirera votre curiosité et vous poussera à lire d’autres articles sur le sujet, voire à attendre les vidéos.
Kickoff: Welcome to Data Reliability Engineering - Egor Gryaznov et Kyle Kirwan
Un très bon ami musicien me disait une fois que l’important pour que les gens apprécient une musique, c’est le début et la fin de celle-ci. Et bien, il semblerait que la DRE Con ait suivi ce conseil car l’introduction et la conclusion (les transitions aussi soit dit en passant) ont été gérées d’une main de maître par Egor Gryaznov, Kyle Kirwan (les hôtes de cette conférence et fondateurs de Bigeye) et Demetrios Brinkman.
En effet, ce premier talk définissait le DRE et surtout présentait selon les organisateurs, l’état actuel du mouvement. Selon eux, le DRE est simplement l’adaptation du SRE à la data, qui suit la même trajectoire d’évolution que l’ingénierie logicielle : tout d’abord, on a observé l’arrivée de l’infra as code avec les cloud providers puis avec des frameworks comme Gradle ou Selenium et enfin avec de l’observabilité, par exemple avec des outils comme Datadog. De la même manière, en data, nous avons vu arriver la possibilité de mettre notre infrastructure dans le cloud via des Data Warehouse comme Bigquery ou Redshift, puis des frameworks comme Dagster, Airflow ou dbt, et désormais, nous voyons arriver des solutions d’observabilité via Bigeye, Monte Carlo ou Great Expectations.
Par la suite, ils nous présentent l’état actuel du DRE et son futur. Selon eux, aujourd’hui l’infrastructure dans les équipes data est globalement bien mise en place via de l’infra as code, la partie machine learning et analytics est elle aussi mature, mais la partie opérationnelle des équipes data manque quant à elle de maturité dans la plupart des cas. Cette partie opérationnelle inclut selon eux la discovery, le modeling, la reliability, le lineage et l’access control. Ils se concentrent par la suite sur une sous partie de cette couche d’opérations, l’observability (cf schéma ci-dessous).
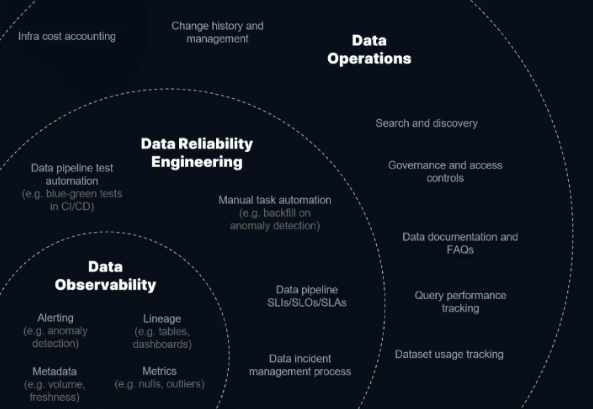
Selon eux, actuellement, la data observability commence à être maîtrisée, les équipes data mettent souvent en place des metadata et des métriques, mais peinent encore quelque peu sur l’alerting et le lineage.
Sur le plan du DRE, ils observent que leurs clients commencent à implémenter l’automatisation des tests de leurs data pipelines et commencent à automatiser les tâches manuelles, mais le reste appartient au futur du DRE.
Chad Sanderson, founder, Data Quality Camp – Data contracts: accountable data quality
Dans la continuité de cette introduction, nous avons eu droit à une première prise de parole particulièrement intéressante sur les data contracts. Ce talk est introduit en statuant que la qualité de données est la fondation pour créer des modèles de machine learning.
Ensuite, il a présenté les trois principales causes à l’origine d’une mauvaise qualité de données :
- Visibility : manque de visibilité et de compréhension.
- Change management : les changements demandés par les métiers et sur les bases opérationnelles sans communication, ni partage sur le pourquoi des changements apportés.
- Lack of Ownership : les producteurs ne sont pas propriétaires de la donnée émise
L’idée est assez simple, s’inspirer des contrats utilisés pour les micro services : définir un contrat sur la donnée que l’on exploite avec les producteurs de cette donnée. L’objectif est triple :
- faire que les producteurs sachent que leur donnée est utilisée par la suite et pour quoi faire ;
- faire que les consommateurs aient une idée de pourquoi/comment la donnée a été générée ;
- faire en sorte que les data engineers ne soient plus un goulot d’étranglement dans la communication producteur/consommateur de la donnée.
Pour accomplir cela, ils ont mis en place ce qu’ils ont appelé des data contracts qui consistent à définir des API qui valident le schéma, la sémantique et la distribution de la donnée pour les producteurs pour rassurer les consommateurs.
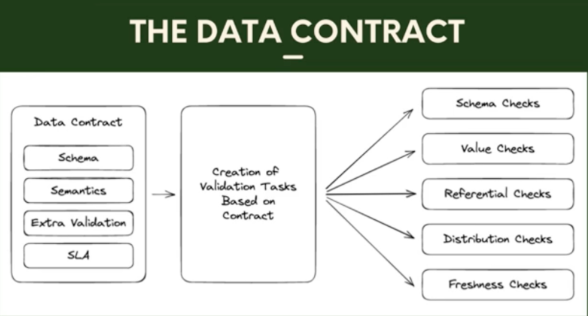
Concernant le schéma, il s’agit simplement de stabiliser le nom et le type des colonnes. Pour ce qui est de la sémantique, par exemple, si une colonne s’appelle « vitesse_en_kph », on ne veut pas qu’elle représente la vitesse en nœuds ou en mètre par seconde. Enfin, la distribution des valeurs vise à s’assurer que la donnée n’est pas biaisée, par exemple, si on a la taille d’une population, on s’attend à ce que cette donnée suive une loi normale, et on va lancer une alerte si la donnée suit une distribution uniforme. On notera que l’on peut ajouter à cela d’autres caractéristiques définies par le métier.
Attention, ce genre de contrat n’est pas destiné à être appliqué à toutes les sources de données de l’entreprise car ils complexifient l’évolution de cette donnée. Seules les données sensibles/importantes doivent y être soumises pour éviter d’avoir à mettre en place des vérifications du respect du contrat ni forcer les équipes productrices à respecter des contrats qui ne sont pas si importants.
Adi Polak, VP of DevEx, Treeverse – Open-source tools for data reliability engineering
Il est vrai que lorsque l’on pense au DRE, on peut vite penser que la plupart des outils sont payants (Bigeye, Monte Carlo, Snowflake, etc), mais ce talk vient nous démontrer le contraire.
Adi Polak nous présente ici l’évolution de la data depuis très longtemps : elle part du document papier pour aller jusqu’au futur de la data et nous présente les outils open source et les paradigmes qui nous permetteront d’implémenter ce futur. Globalement, il faudra implémenter des solutions de data discovery pour faire évoluer les équipes et faire en sorte que les gens puissent comprendre leur data (nous reviendrons sur ce qu’est la data discovery dans le dernier talk). Malgré tout, vous pourrez voir ci-dessous les features qu’Adi Polak pense qu’il faut implémenter dans ces solutions.
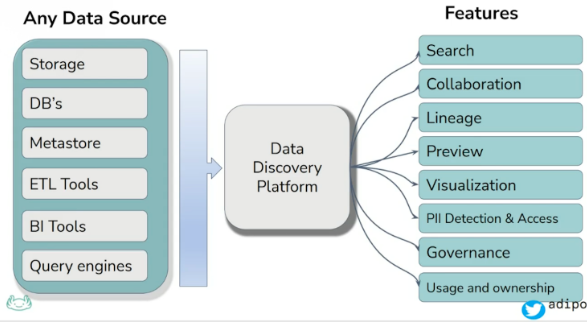
Voici l’ensemble des solutions open source qui peuvent vous permettre d’en arriver là :


Joe Reis, CEO, Ternary Data – A few ways to miserably fail with data
L’objectif de ce talk est très bien résumé par son auteur : il y a beaucoup d’articles sur comment réussir avec la data observability, beaucoup de façons d’y arriver, donc ça ne sert à rien d’aller sur ce terrain et de toutes façons, on ne pourrait pas être exhaustif. De plus, les gens sont bien plus à même de se remémorer des accidents incroyables que des histoires de réussites.
Mais alors, comment fait-on pour ne rien tirer de sa stack de data observability ?
Le premier conseil est de ne pas travailler ni d'implémenter tous les bons outils, mais plutôt de ne rien en faire. En plus de cela, il faut surtout ne pas développer de rapport sur les problèmes que l’on a eus avec la qualité de données. Si jamais on développait malencontreusement un rapport, surtout, n’envoyez simplement que des alertes vagues, voire inutiles, et quoi qu’il arrive, dire aux gens que tout va toujours bien.
Le deuxième conseil est de ne jamais résoudre les problèmes à la racine, toujours faire le moins de travail possible quand on a un problème à résoudre, surtout si on a une solution au problème qui ne sera pas pérenne. Au cas où un problème arriverait en boucle, la bonne technique consiste à inventer un coupable imaginaire dans un service, de sorte que la personne soit introuvable.
Le troisième conseil est de construire des silos et de s’isoler dans le sien. On doit tout faire par soi-même, ne jamais demander d’aide ou de promoteur. Quand on a des problèmes, on peut revenir au conseil précédent et inventer un coupable. En bref, on veut être aussi isolé que possible du monde.
Le dernier conseil, brûler son capital sympathie vis-à-vis des autres équipes. Pour cela, vous pouvez par exemple envoyer les alertes jusqu’au PDG de l’entreprise, et surtout, n’oubliez pas de renvoyer la responsabilité des problèmes aux autres. Et n'oubliez pas, au pire, que vous vous ferez virer, et vous pourrez changer d’emploi pour mieux recommencer ailleurs.
Ellora Praharaj, Director of reliability engineering, Stack Overflow – What do gas stations and DRE have in common
L’avant-dernier talk de cette DRE Con 2023, et j’avoue avoir un petit problème avec, je pense qu’il aurait dû arriver bien plus tôt dans cette conférence car il s’agit plus ou moins d’une définition du DRE, qui plus est d’excellente qualité.
Ellora Praharaj nous présente le DRE via une image en le comparant à une station essence via différentes questions :
- quel type d'essence mettre ?
- quelle quantité ?
- comment ne pas prendre feu ?
- comment faire si la pompe est vide ?
Les parallèles ne sont certes pas forcément évidents, mais au final, ils sont assez clairs.
La quantité d’essence peut être comparée à la taille d’instance, les performances voulues et l’observabilité : dans les deux cas, il faut doser entre prix et qualité de service en fonction de ses besoins.
Sur « comment ne pas prendre feu ? », c’est un focus sur l’automatisation, utiliser la CI/CD, mettre en place les bonnes sécurités pour éviter un incident.
Concernant la question « s’il n’y a plus d’essence ? » c’est qu’il faut mettre en place des SLO et SLA, car il y a parfois des problèmes externes.
Naturellement, le talk va bien plus loin et pose bien d’autres questions et amène bien d’autres bonnes pratiques. En bref, c’est une excellente introduction au DRE, mais si ce talk vous tente, j’en connais un meilleur, et dans la langue de Molière disponible juste ici. Plus sérieusement, le talk est tout de même très bon et aborde des points que le mien n’aborde pas, donc allez le regarder, mais après le mien tout de même.
Shinji Kim, CEO, Select Star – Data discovery vs. data observability: Understanding the differences for better dataOps
On observe aujourd’hui une décentralisation de l’appartenance de la donnée et une silotisation de celle-ci : la quantité et la diversité des données fait que l’on peut facilement s’y perdre. Les gens se demandent d’où viennent les données, comment et pourquoi elles ont été produites, etc. Il faut donc mettre en place de la data discovery. Très bien. Mais qu’est-ce qui se cache derrière ce terme, et quels sont les points communs et différences avec la data observability?
Globalement, on pourrait le résumer ainsi : la data observability cherche à savoir si la donnée suit bien les bonnes distributions, respecte le bon schéma, et a une volumétrie cohérente, etc. La data discovery, quant à elle, cherche à donner un sens à cette donnée en nous renseignant sur la façon dont elle a été produite par exemple.
Si on rentre un peu plus dans le détail, en arrive à cette comparaison en termes d’objectifs entre les deux types de solutions :
Conclusion
Pour finir, je pense que nous avons eu le droit à une bonne édition de la DRE Con, certes un peu moins riche que les précédentes car il y avait moins de speaker (habituellement, la conférence dure à peu près aussi longtemps mais les talks sont faits deux par deux en parallèle). Le changement de format s’est aussi un peu fait ressentir, les talks faisant 25 minutes désormais, ils sont plus simples et agréables à suivre, même si certains laissent un arrière-goût de trop peu. Nous avons tout de même eu le droit à un joli line up qui avait tout pour inciter à la curiosité et se plonger dans l’univers DRE, et qui ne nous a pas déçu.
Je vous conseille sincèrement de regarder les talks que j’ai résumé s’ils vous ont intéressé pour que vous puissiez découvrir les sujets plus en détail. Comme dit dans l’introduction, ils devraient rapidement arriver sur la chaîne Youtube de Bigeye, qui contient d’ailleurs beaucoup d’autres talks passionnants sur le sujet de la qualité de données.
De mon côté, je vous dis rendez-vous probablement l’année prochaine pour un nouvel article sur la DRE Con et peut-être d’autres articles sur la qualité de donnée d’ici là.
