

Table des matières
Introduction
Keynote d'ouverture
Rendre hautement disponibles des milliers d'ingress sur des clusters kubernetes indépendants
Révolution eBPF : Un noyau Linux dynamique
Et si l’on construisait un cloud open source pour la datascience ?
Sécurisez votre software supply chain avec SLSA, Sigstore et Kyverno
Vers une culture où tout le monde est responsable de l'indisponibilité
OpenTelemetry, JavaScript et tracing distribué : Un jour j'irai vivre en Théorie, car en Théorie tout se passe bien
5 ans avec Kubernetes : retour sur le déploiement des conteneurs chez Pôle Emploi
Performances et scaling pour les événements spéciaux chez eTF1
Comment bien foirer sa certif CK{A,S}
Récapitulatif de la journée
Introduction
Ça y est nous y sommes ! Les Kubernetes Community Days arrivent en France !
Ce mardi 7 mars, la communauté tech dont une délégation de 9 consultants Cloud & DevOps d'Ippon Technologies sur-motivés se sont retrouvés au Centre Pompidou en plein centre de Paris pour assister à de multiples conférences et retours d'expérience autour des technologies Cloud Native et DevOps.
Cette première édition a réuni plus de 800 participant(e)s, une trentaine de partenaires parmi lesquels nous pouvons citer Redhat, OVHcloud ou encore Scaleway, le tout dans une ambiance conviviale et pleine de partage.
Dans cet article, nous proposons de vous partager nos moments forts et les sujets prometteurs à suivre dans l’année 2023.
Keynote d'ouverture
Les Kubernetes Community Days France ont été initiés en 2019 sur Paris, par des bénévoles motivés par l’idée de créer une conférence autour de Kubernetes en France. D’abord freinés par le Covid, les bénévoles ont attendu 2023 pour être certains de faire un salon qui restera dans les mémoires.
Pour cette journée de talks, nous sommes répartis en 3 salles : bleue, blanche et rouge pour un salon aux couleurs de la France.
La keynote d’ouverture c’est la première conférence de la journée, et qui de mieux pour commencer ce Kubernetes Community Day que Solomon Hykes, le créateur de Docker lui-même. “Kubernetes c’est le prolongement de Linux”, c’est avec cette phrase qu’il a entamé son discours. Il a ensuite brièvement parlé du nouvel outil que lui et ses équipes développent : Dagger, un moteur de CICD As Code, qui permet aux développeurs de créer leurs pipelines en utilisant différents langages (Python, Go, Typescript etc).
Différents partenaires du salon ont ensuite pris la parole :
- RedHat, créateur d’Openshift qui est le “Kubernetes avec beaucoup d’amour”
- L’éducation nationale qui a présenté le projet Santorin, un système d’aide de numérisation et de notation de copies d’examens officiels ainsi que Cloé, le Cloud pour l’éducation nationale
- OVH qui agrandit son catalogue d’offres cloud pour se frotter aux concurrents américains
- Scaleway qui nous a fait un tour plein d’humour sur les différentes prononciations de la commande kubectl

Solomon Hykes
Rendre hautement disponibles des milliers d'ingress sur des clusters kubernetes indépendants.
Rédigé par : Gabriel WESTRELIN
Speakers : Solvik Blum & Laurent Marchaud, Numberly
Comment faire en sorte d’avoir du Load Balancer sur des ingress dans des clusters indépendants dans des DataCenter différents ? Le tout en ayant une redondance, permettant une maintenance simplifiée, en augmentant la fiabilité et en ne fédérant pas les clusters (“diviser pour mieux régner”) ?
La réponse qu’ils ont trouvée est d’utiliser Yggdrasil https://github.com/uswitch/yggdrasil . Ce control plane pour multi-cluster scanne tous les ingress des clusters, les agrège et les envoie sur envoy qui se charge de faire le LB. En outre, ce dernier check les endpoints permettant ainsi de suivre leur disponibilité. Ils ont même contribué à ce projet en apportant ce qui lui manquait : une gestion plus affinée des certificats ou encore un système de poids sur les différentes routes.
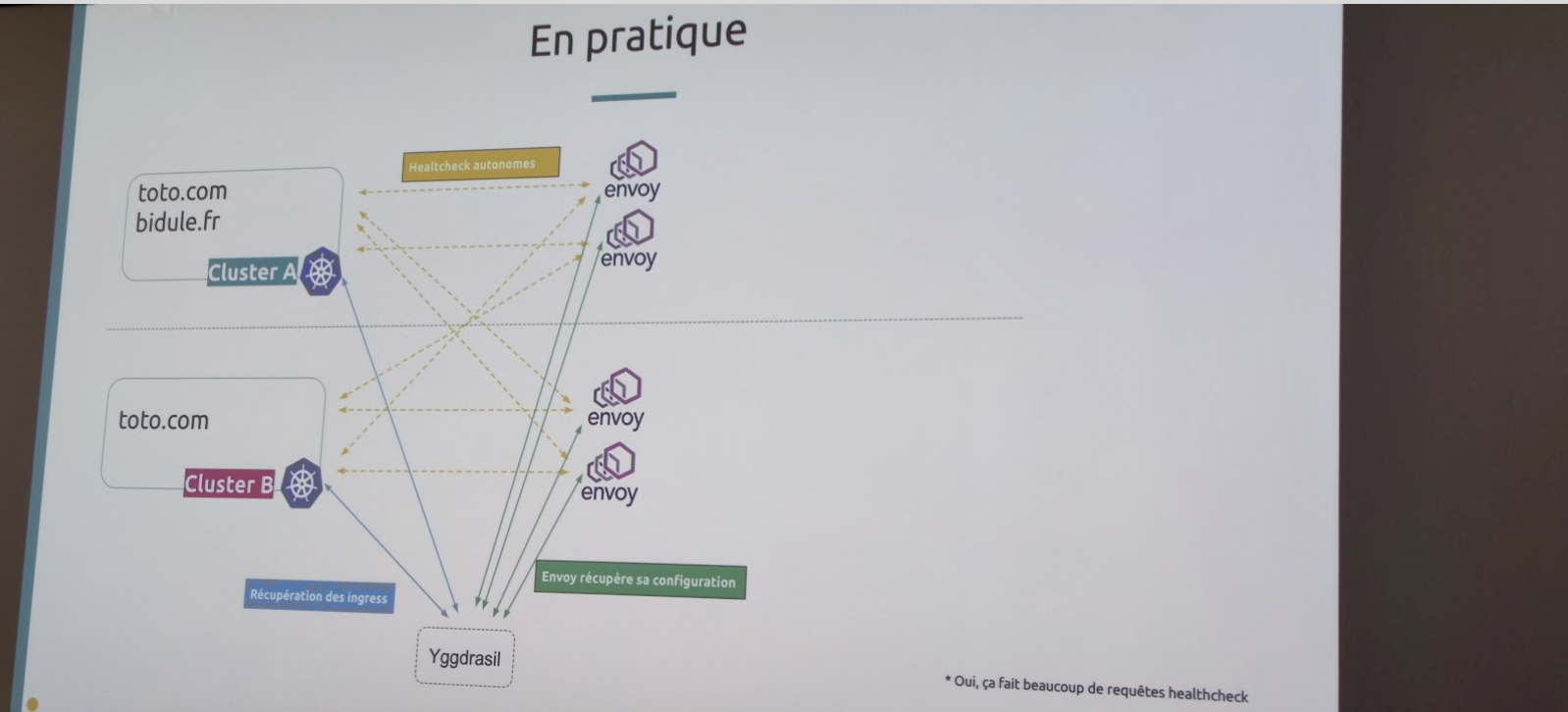
La perspective de pouvoir gérer d’un seul tenant ce type de Load Balancer est plutôt intéressante. Surtout si le nombre de clusters est important. Il faudrait voir maintenant au niveau des performances ce que cela donne par rapport à d’autres solutions (par exemple des solutions matérielles).
Révolution eBPF : Un noyau Linux dynamique
Rédigé par : Damien ROLLET
Speaker : Raphaël Pinson, Isovalent
Isovalent a développé Cilium, un CNI (Container Network Interface) basé sur la technologie eBPF du Kernel Linux. Cilium est disponible en OpenSource et Isovalent fournit également une version entreprise intégrant notamment du support.
La technologie d’eBPF permet d'étendre les fonctionnalités du Kernel Linux en s'interfaçant directement avec lui. Dans le cadre d’un CNI Kubernetes, il permet entre autre d’implémenter des features dans les domaines suivants:
- Observabilité: L’objectif principal est de pouvoir récupérer des métriques directement à bas niveau tout en intégrant les concepts Kubernetes (labels, pods..)
- Gestion du trafic réseau: l’utilisation d’eBPF va permettre à Cilium d’interagir directement avec la carte réseau, d’éviter l’utilisation de règles IPTables
- Sécurité : Cilium peut à la fois permettre d’avoir des informations très précises pour structurer l’information, alimenter un SIEM ou agir directement sur les pods
Voici en exemple de visualisation orientée sécurité :

La conférence de Raphaël permet à la fois de comprendre les principes de fonctionnement d’eBPF et l’intérêt de son utilisation dans le contexte du développement d’un CNI pour Kubernetes.
Cilium peut avoir de vrais intérêts pour vous si vous manquez d’information pour faciliter l’observabilité ou si vous avez des contraintes de performances ou de customisation pour lesquelles eBPF peut être une réponse.
Et si l’on construisait un cloud open source pour la datascience ?
Rédigé par : Pierrick ROBIC-BUTEZ
Speakers : Frédéric Comte & Olivier Levitt, INSEE
Dans le contexte de l’INSEE où les statisticiens sont peu familiers avec les technologies Cloud et Kubernetes, l’institut, en collaboration avec la DINUM a décidé de développer une plateforme open source dédiée à la datascience dans le but d’onboarder les statisticiens sur les pratiques et méthodes du domaine Cloud & DevOps (l’idée étant de profiter de leurs avantages).
Leur principale problématique a été d’établir de manière claire les services relevant de chaque utilisateur unique de la plateforme et les communs à destination de l’ensemble des utilisateurs. Effectivement, s’il paraît logique que tous les projets utilisent le même outil de VCS ou que chaque projet utilise ses propres services applicatifs, des services tels que la gestion des logs ou le monitoring posent question.
Ainsi, le provisionnement de services dans les clusters Kubernetes de la plateforme est simplifié au maximum, avec une interface graphique basée sur la lecture des fichiers de configuration values.spec.yaml de Helm, où les valeurs sont pré-remplies en fonction du contexte de l’utilisateur et des autres services qu’il a déjà déployé en utilisant Helm lookup.
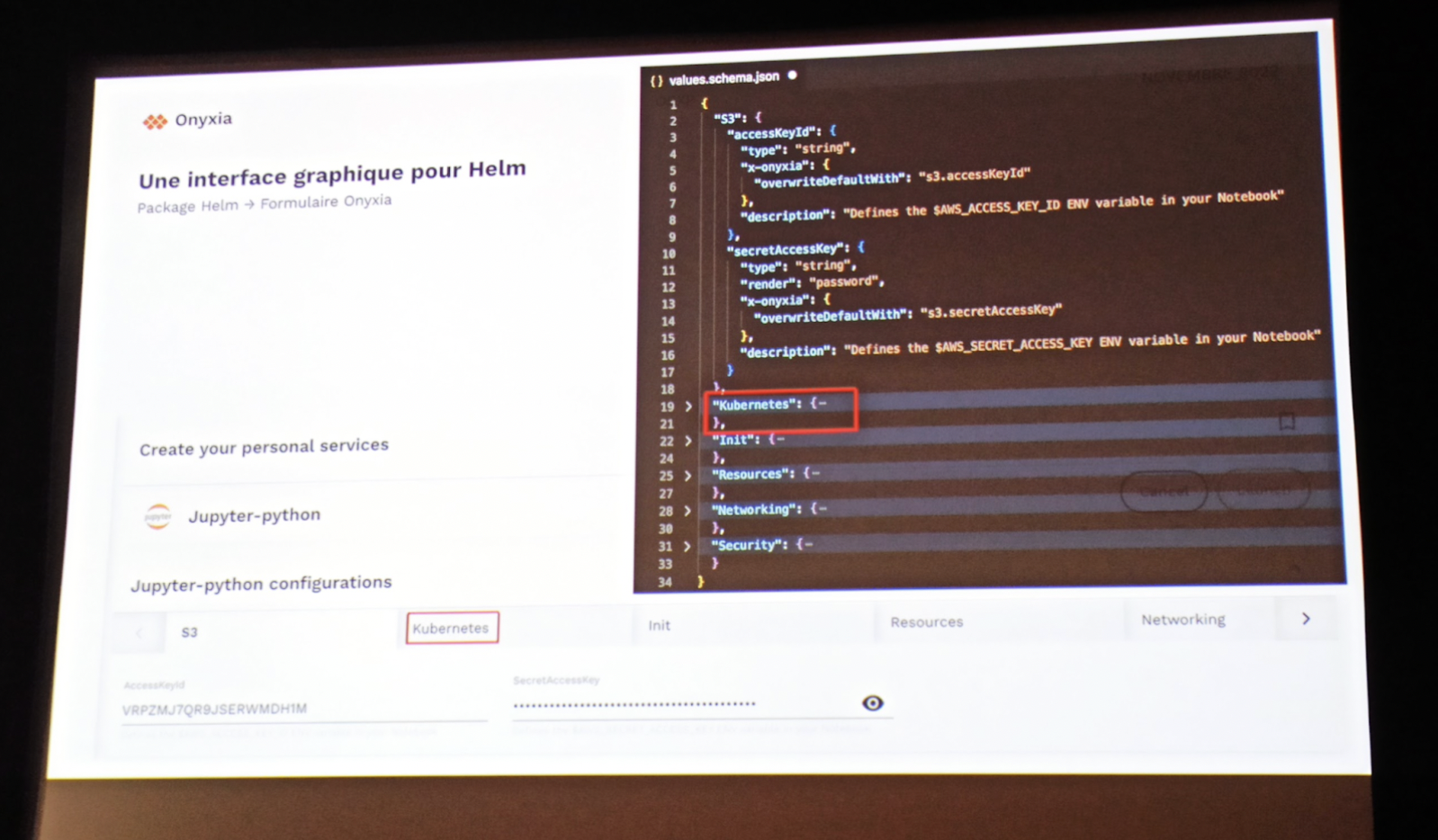
En effet, Helm lookup permet de détecter les ressources déjà déployées dans le namespace de l'utilisateur et de pré-remplir les valeurs des variables d’environnement nécessaires au déploiement de nouveaux services. C’était assez intéressant de voir que dans la salle, très peu étaient familiers avec cette fonctionnalité.
La plateforme open-source, appelée Onyxia et accessible gratuitement pour toutes les administrations publiques. Elle est aussi déployable sur sa propre infrastructure.
Dans ce contexte, la ligne directrice du projet a été de proposer un produit le plus user friendly, le plus simple à utiliser afin de faciliter l’adoption des pratiques amenés par la philosophie DevOps par les métiers liés à la data science.
Sécurisez votre software supply chain avec SLSA, Sigstore et Kyverno
Rédigé par : Florian Patérour
Speaker : Mohamed Abdennebi, SFEIR
Cette présentation est l'œuvre de Mohamed Abdennebi, Cloud Security architect chez SFEIR. Son rôle est de concevoir et de construire des infrastructures cloud sécurisées “by design”.
Ici Mohamed nous présente SLSA (Supply chain Levels for Software Artifacts, prononcez “salsa”), un framework développé par Google et sorti en 2021. Il s’agit d’un ensemble de standards et de contrôles à appliquer dans le but d’assurer l’intégrité de la chaîne de construction et de déploiement de nos artefacts.
SLSA se décline en 4 niveaux, le niveau 4 représentant l’idéal à atteindre. Avant de rentrer plus en détails dans l’explication de ces niveaux, il est important de revenir sur une composante centrale dans SLSA : la provenance.
La provenance est une attestation composée de métadonnées sur l’artefact produit (cf exemple image). Elle décrit notamment le type d’artefact produit, quel type de plateforme l’a produit (ex : GitHub Actions), avec quel script, quel événement a engendré sa production ainsi que le code source et les dépendances utilisées à la base. L’idée étant de pouvoir s’assurer de l’intégrité de l’artefact et de rendre sa production reproductible.
Cette attestation est produite et stockée avec l’artefact de sorte à être facilement vérifiable par les consommateurs de la dépendance.

Exemple de fichier attestant de la provenance d’un artefact, ici une image Docker
Pour atteindre le niveau SLSA 1, il suffit simplement de générer la provenance en plus de l’artefact. A ce niveau, la provenance ne protège pas de l’altération de l’artefact mais permet de l’identifier plus finement et facilite la gestion des vulnérabilités.
Le niveau 2 exige l’utilisation d’un système de build capable de générer une provenance signée. A ce niveau la confiance d’une non altération de l’artefact repose sur la confiance que l’on a dans le système de build.
Au niveau 3, on considèrera la provenance infalsifiable grâce à l'impossibilité d'utiliser des jobs contrôlés par l'utilisateur pour générer et signer la provenance. En pratique, Mohamed nous a donné l'exemple d'une équipe DevSecOps en interne chargée justement de fournir ces jobs utilisables mais non modifiables par les développeurs.
L'atteinte de ce niveau permet de se protéger contre certains types de menaces, comme la contamination cross build.
Lors de la conférence le niveau 4 n'a pas été mentionné mais après quelques recherches il s'avère que celui-ci requiert une review par au moins deux personnes de tous les changements ainsi qu'un mécanisme de build le plus reproductible possible. Ce dernier point est assuré par la nécessité de garantir la provenance de toutes les dépendances de l'artefact produit.
Si vous souhaitez en savoir plus et examiner un exemple de cas pratique avec sigstore comme outil de signature de la provenance, voici le lien du répertoire GitHub utilisé par Mohamed lors de sa démonstration pendant la conférence : https://github.com/albasystems/hello-slsa.
Finalement, pour faire le pont avec l’écosystème Kubernetes, le speaker a présenté un scénario où Kyverno - un outil de gestion de politiques de conformité - est utilisé pour valider le déploiement de vos pods en vérifiant leur provenance en amont. Si la provenance de vos conteneurs ne peut pas être vérifiée, votre déploiement sera rejeté.
En somme, cette conférence nous a donné, à travers l’application de SLSA, un bon aperçu des pratiques possibles pour garantir l’intégrité de sa chaîne de construction logicielle.
Vers une culture où tout le monde est responsable de l'indisponibilité
Rédigé par : Alexis RENARD
Speaker : Emmanuel Bernard, Red Hat
Avant de construire une architecture, Emmanuel nous propose de prendre deux principales problématiques à prendre en compte :
- les limites du système que l’on veut proposer à nos utilisateurs
- les attentes de nos utilisateurs quant à ce système
Riche de son expérience chez Red Hat en tant que head de la section architecture, il s’agit surtout d’un retour d’expérience sur des tips & tricks de gestion d’équipe afin de faciliter la boucle de rétro compatibilité entre les décisions des devs, des ops et des architectes. Un talk assez haut niveau qui nous rappelle l’importance de l’acculturation et du partage de responsabilités dans un contexte DevOps.
Après avoir communiquer sur les limites de notre système et alerter lorsqu’elles vont être atteintes, il peut être intéressant d’envisager de le brider volontairement afin de ne pas atteindre ses limites. Pour illustrer ces propos avec un exemple :
- Notifier que la stack ne fonctionnera jusqu’à 1TB de stockage
- Alerter lorsque 75% de ce stockage est atteint mais empêcher, applicativement, le fait de pouvoir utiliser plus de 990 Gb pour éviter d’atteindre la limite critique de la stack et d’impacter notre SLO/SLA.
OpenTelemetry, JavaScript et tracing distribué : Un jour j'irai vivre en Théorie, car en Théorie tout se passe bien
Rédigé par : Adrien DELCOURT
Speaker : Sonia Seddiki, Pitchy
Le sujet de cette conférence porte sur l'intégration d’OpenTelemetry autour du javascript pour du tracking. Elle prend place dans le cadre d’une application d'édition de clip vidéo éditée par la société Pitchy, tout ceci presenté par Sonia Seddiki.
La présentation montre l'intégration par l'équipe de développeurs et leurs apprentissages pour réussir à obtenir des métriques pertinentes et comprendre les goulets d'étranglement de leurs applications. Le système d’auto instrumentation d’OpenTelemetry est bien, avec deux problèmes principaux : la quantité de mesures remontées et la limitation sur les possibilités de configuration. L'équipe a instrumenté manuellement certaines fonctions et méthodes en tirant parti des annotations rendues possibles par le langage TypeScript.
L’équipe est petite et a rencontré de nombreuses difficultés pour gérer l’infrastructure par manque de spécialisation. Sonia est revenue sur la bonne évolution du projet OpenTelemetry qui a beaucoup changé après deux ans d'expérimentation. OpenTelementry est disponible pour de nombreux langages avec un niveau de support plus ou moins mature.
Le REX a été intéressant pour avoir le point de vue d’une équipe de développement sur la mise en place d’un premier outil de tracing. Le choix d’open telemetry a été fait sur la promesse de ne pas être dépendant d’un produit de tracing.
Un arbitrage fort a été fait sur la qualité des métriques en choisissant les plus pertinentes niveau métier au détriment de la quantité afin de limiter les coûts.
5 ans avec Kubernetes : retour sur le déploiement des conteneurs chez Pôle Emploi
Rédigé par : Florian Patérour
Speaker : Daniel Benisty & Laurent Nocus, Pôle Emploi
Ce talk nous a été présenté par deux speakers de la DSI de Pôle Emploi, Daniel Benisty, DevOps et Laurent Nocus, Product Owner. Pour remettre le talk dans le contexte Pôle Emploi, il est important d’avoir quelques ordres de grandeur en tête. Ainsi, ~3000 (3000 !) personnes travaillent côté DSI pour un total d’environ 50000 agents. Les enjeux sont donc importants et nécessitent des choix réfléchis à l’échelle de l’entreprise.
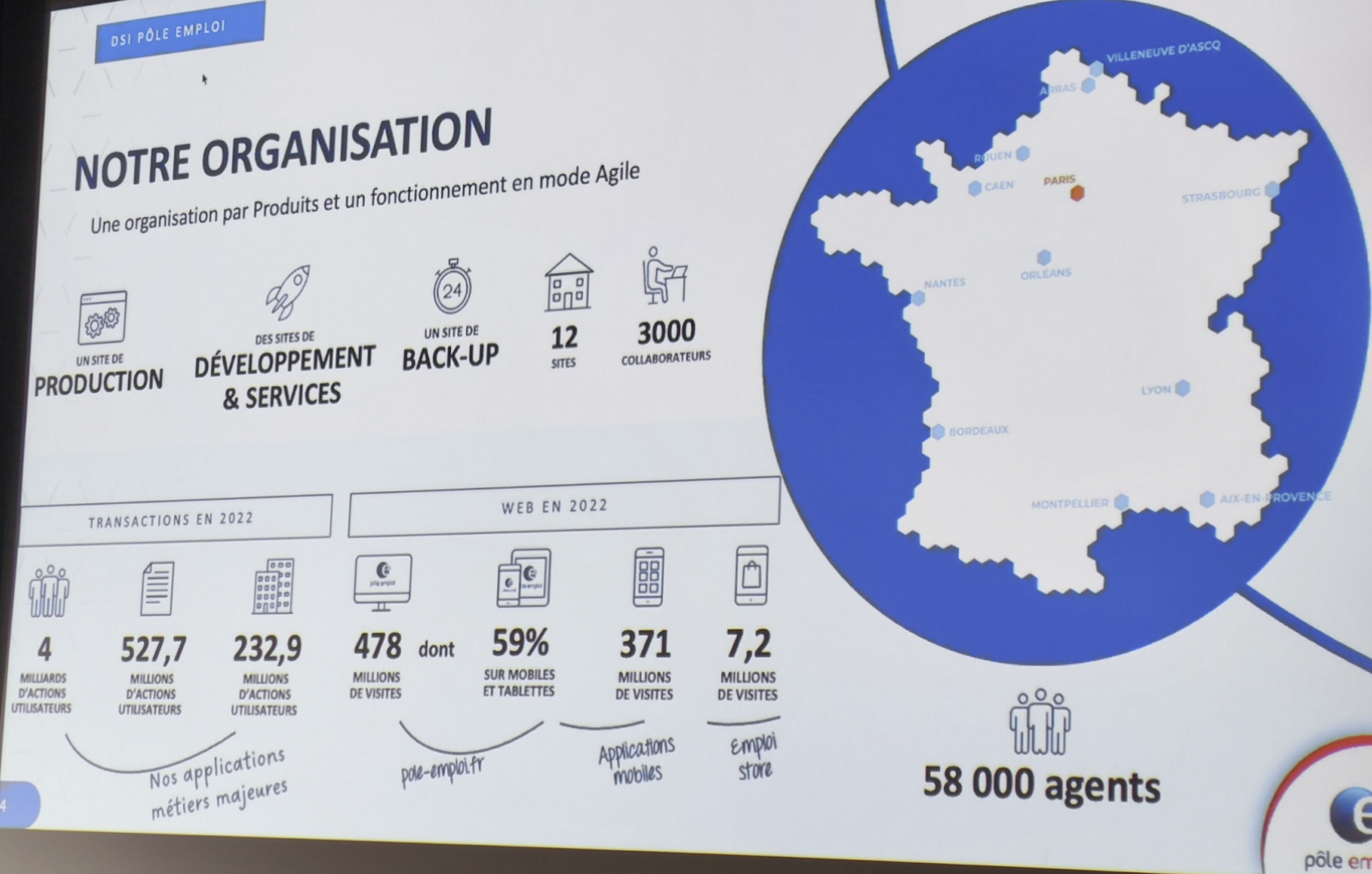
Pôle Emploi en quelques chiffres.
Comme de nombreuses entreprises, la DSI de Pôle Emploi a commencé sur un mainframe et travaille aujourd’hui avec des VM et des conteneurs. Ici on se concentre sur l’évolution côté conteneur avec l’arrivée en 2017 du besoin d’orchestration, besoin couvert dans un premier temps par Docker swarm, très vite remplacé par Kubernetes. Un changement de technologie n’a pas résolu magiquement toutes les problématiques de l’entreprise. Pour preuve, lors de la mise en production de la première grosse application conteneurisée et orchestrée par Kubernetes, rien ne fonctionnait. En cause, le calquage des ressources (RAM, CPU) assignées aux pods sur ce que Pôle Emploi faisait avant : des déploiements sur de grosses machines avec beaucoup de ressources. Problème, ce mode de fonctionnement n’est visiblement pas adapté dans un contexte Kubernetes. Il a donc fallu repenser le découpage de l’application pour réduire les ressources nécessaires pour le bon fonctionnement des différents composants.
En 2020 les speakers et leur équipe mettent à disposition de Pôle Emploi une “plateforme as a product”, un grand succès selon leurs dires. Cette plateforme a pour objectif de provisionner des clusters à la demande avec plein de technos possibles, par exemple une plateforme pour les data scientist de Pôle Emploi.
Le succès de leur plateforme a plusieurs origines, je reviendrai ici sur celles qui m’ont le plus marqué.
Premièrement, pour faciliter l’adoption, ils nous ont raconté avoir donné un accès administrateur à tous les utilisateurs des clusters. Ils l’admettent, ce n’est pas recommandable mais cela a bien aidé et ils ont pu travailler sur la sécurisation de cet aspect dans un deuxième temps.
Un autre point qui m’a paru particulièrement intéressant est le fait d’avoir intégré les équipes de développement de leur “platform as a product” aux équipes amenées à utiliser ce produit et, dans l’autre sens, d’avoir intégré certains utilisateurs à l’équipe de développement.
Dernier point, une communication totalement transparente et accessible à tous les utilisateurs. Ces derniers sont ainsi informés sans langue de bois des raisons qui ont pu pousser aux indisponibilités des clusters déployés et de la façon dont elles ont été résolues.
Ces différents éléments ont participé à l’obtention d’un NPS excellent auprès des utilisateurs.
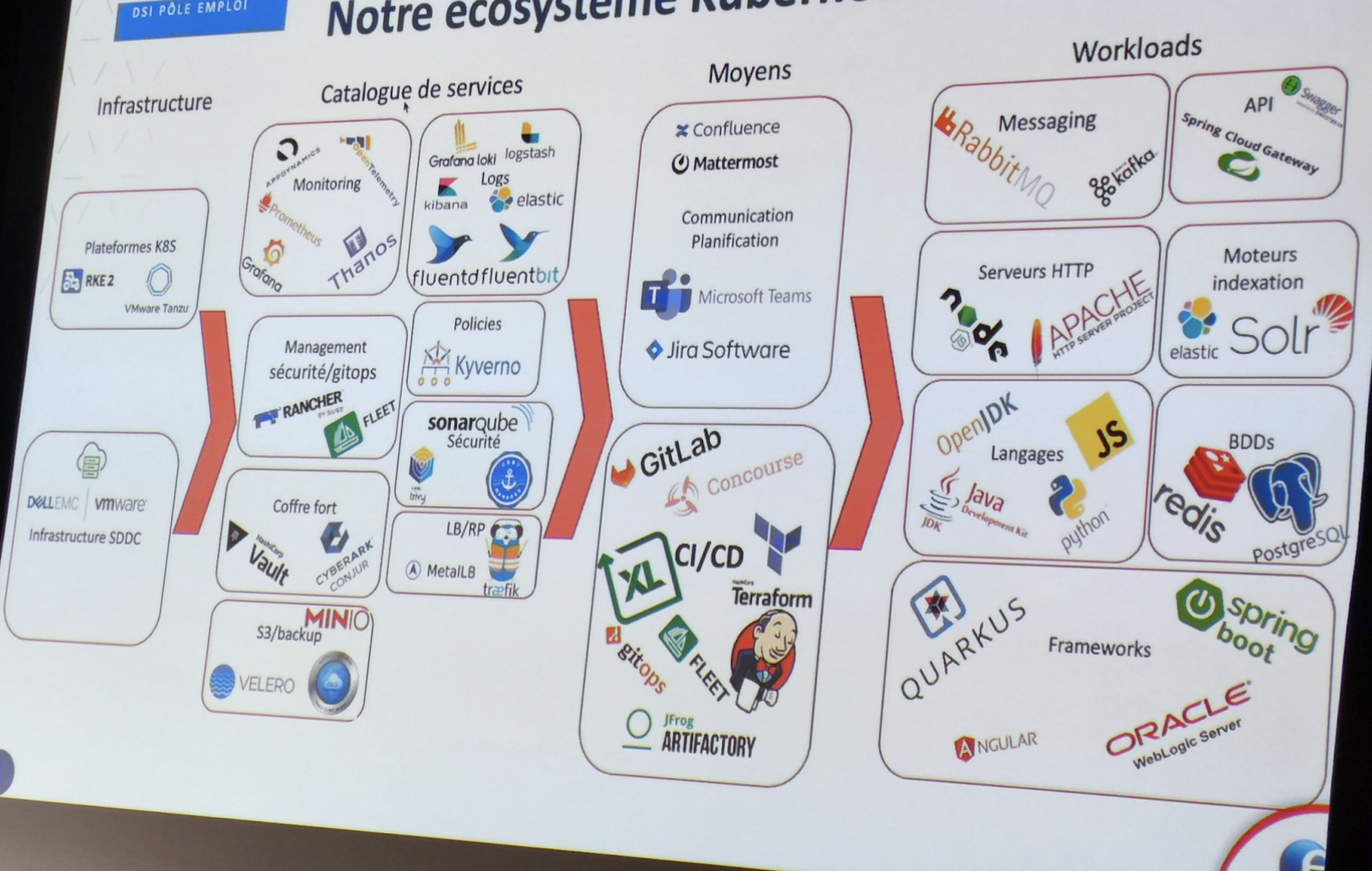
Services rendus par la plateforme Pôle Emploi et outils utilisés par la DSI
Performances et scaling pour les événements spéciaux chez eTF1
Rédigé par : Yoan SIMIAND-COSSIN
Speakers : Laurent Dechoux & Hugo Lebaron, eTF1
Lors de ce retour d’expérience, l’équipe d’eTF1 nous a fait part de leurs problématiques de performance et de mise à l’échelle lors d’événements spéciaux tels que la coupe du monde de football de 2022. De leur stratégie de test en passant par les actions correctives concrètes mises en place ou encore leur vision quant au futur de la plateforme, nous avons pu avoir un bon aperçu du problème et des solutions implémentées pour y répondre.
L’équipe a tout d’abord identifié les différents profils de charge afin de mettre en place des scénarios de tests adaptés. Une fois ces derniers rédigés, ils ont réalisé des tests “grandeur nature” sur une infrastructure répliquée et identique à leur environnement de production, et ce avec une charge au plus proche de la réalité. Ces tests ont permis de mettre en place des correctifs concrets à plusieurs niveaux : amélioration du code côté front et diminution des call flows, ajustement des limites avec leurs prestataires notamment AWS, ajout de micro-caches in-memory, mises à jour de leurs configurations des ressources kubernetes, prescaling (manuel) de leurs clusters Kubernetes, …
Bien que cet événement précis se soit bien passé, l’équipe d’eTF1 ne compte pas s’arrêter là. En effet, ils ont identifié trois principaux axes d’amélioration. Le premier concerne le changement de l’outil utilisé pour la mise à l’échelle de leur cluster, passant du cluster autoscaler d’AWS à Karpenter afin de diminuer la latence de scaling tout en optimisant leurs coûts. Le second axe identifié concerne la mise en place de KEDA, leur permettant de configurer l’Horizontal Pod Autoscaling sur la base de métriques personnalisées telles que le nombre de requêtes par seconde. Enfin, le dernier axe d’amélioration concerne l’industrialisation des tests de charge en les intégrant notamment à leurs pipelines d’intégration continue.
Au-delà des solutions techniques apportées et envisagées, ce retour d’expérience nous a permis de comprendre leur démarche de mise à l’échelle de grande envergure afin de répondre à des problèmes de performance critiques.
Comment bien foirer sa certif CK{A,S}
Rédacteur : Paul BOISSON
Speaker : Rémi Verchère, Accenture
Un Rex sur le ratage de certification est un classique dans les conférences en informatique, mais c’est toujours un moment sympa qui nous pousse à réfléchir sur des mauvaises habitudes que l’on peut avoir sans s’en rendre compte. Rémi Verchère, consultant chez Accenture, nous explique comment bien rater sa certification CKA ou CKS. C’est un expert dans le domaine puisqu’il a raté les deux en 2021, mais a quand même fini par les avoir et les compléter avec deux autres certifications.
Voici ses différents conseils :
Lors de la phase de préparation de l’examen :
1 - Être trop confiant
2 - Ne pas pratiquer
3 - Ne pas apprendre Vim ou l’utilisation de la commande kubectl (l’utilisation de Lens à outrance est un bon moyen de ne pas apprendre kubectl)
4 - Ne pas s’entrainer sur killer.sh qui est une plateforme qui simule des examens des différentes certifications Kubernetes
5 - Ne pas mettre de bookmark sur la documentation de Kubernetes, cela permettrait de trop bien se retrouver.
6 - Lorsque l’on s’inscrit à l’examen, on a deux essais pour réussir l’examen. Utiliser le 1er essai le plus tard possible pour être sûr de ne pas pouvoir se préparer à temps pour le deuxième en cas d’échec.
7 - Oubliez que vous avez souscrit à l’examen
8 - Ne vous mettez pas dans de bonnes conditions. Par exemple, vous pouvez sortir la veille au bar
Lors de l’examen
8bis - Ne vous mettez pas dans de bonnes conditions (webcam 720p, une mauvaise connexion internet, une salle avec plein de monde dedans et du bruit c’est parfait)
9 - Ne lisez pas les questions en entier
10 - N’utilisez pas les contextes Kubernetes, vous risqueriez de gagner du temps lors de vos manipulations
11 - Ne sauvegardez pas votre travail et créez toutes vos ressources à la main
12 - Prenez bien votre temps
13 - Lorsque vous avez terminé, même s'il vous reste du temps, arrêtez tout, tout de suite sans relire.
Bien évidemment, pour passer sa certification, il faut faire tout le contraire.
Ce retour d’expérience est toujours utile pour les personnes qui souhaitent passer leur certification.
Récapitulatif de la journée
Cette première édition des KCD France a été un réel succès en proposant des conférences de qualité et une organisation réussie. C’est en tout cas ce qu’il est ressorti de tous les consultants Ippon qui y ont participé. La présence des nombreux sponsors techniques nous a par ailleurs permis d'approfondir ou de découvrir de nouvelles approches en allant à leur rencontre entre deux conférences.
On ne peut que vous inciter à participer aux prochaines éditions et à visionner les conférences qui ont été filmées lorsqu’elles seront disponibles.








