

En tant que développeur, la première épreuve que nous avons à surmonter au début d’une mission est en général de mettre en place notre environnement de développement, et de parvenir à faire tourner les applications sur notre machine. Si cela peut paraître banal, dans un contexte avec une dizaine d'applications inconnues, on peut y perdre beaucoup de temps.
Simplifier au maximum le lancement des applications nous permet d’optimiser cette tâche pour les nouveaux arrivants, et favorise également la répartition des connaissances au sein d’une équipe : les développeurs seront plus aptes à travailler sur n’importe quelle application de leur périmètre.
Cela permet aussi d'accélérer la résolution d’incidents, parce qu’il est alors plus facile de reproduire l’erreur en local pour l’analyser.
Simple et efficace : commiter le runner IntelliJ
Tout le monde ne le sait pas, mais IntelliJ propose d’enregistrer la configuration de lancement de votre application sous la forme d’un fichier XML dans votre projet. C’est-à-dire qu’une fois votre application bien paramétrée dans “Run -> Edit configurations…”, les paramètres de VM ajoutés, les profils renseignés, il suffit de cocher la case en haut à droite “Store as project file” pour qu’IntelliJ crée un dossier .run à la racine du projet qu’il suffira de commiter pour que tous les autres développeurs y aient accès.
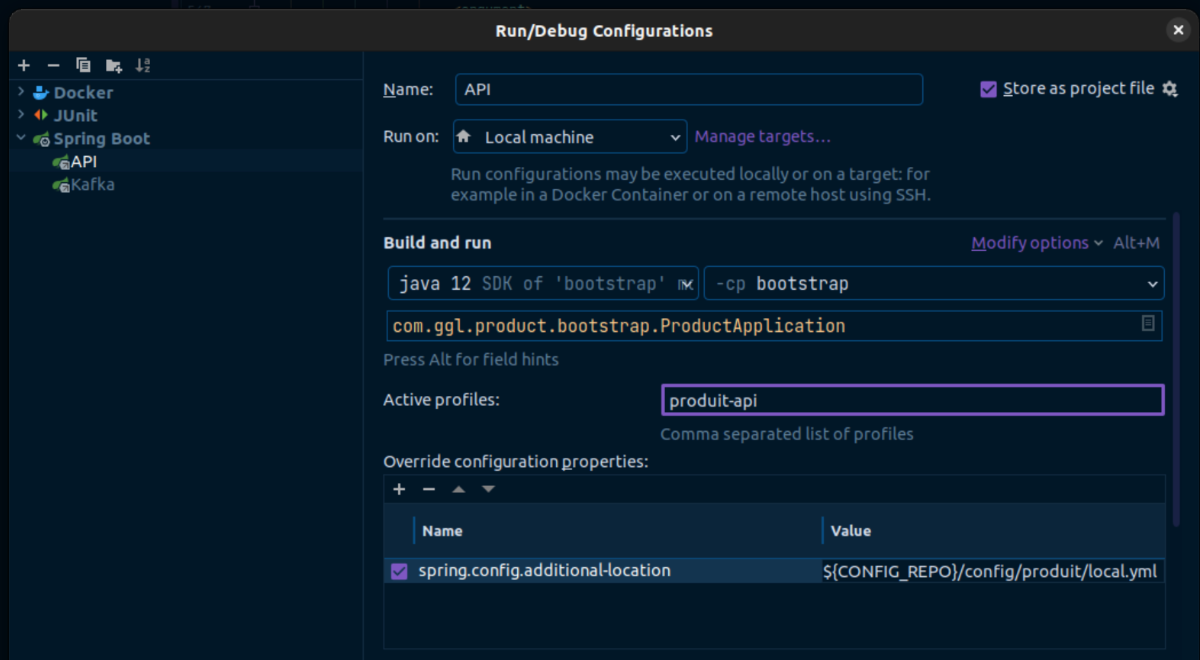
Un développeur de votre équipe n’aura qu’à cloner le projet, et IntelliJ lui générera automatiquement les runners nécessaires à partir des informations stockées dans le dossier .run.
Chaque fichier XML définit un runner, et le dossier .run peut en contenir autant qu’on veut.
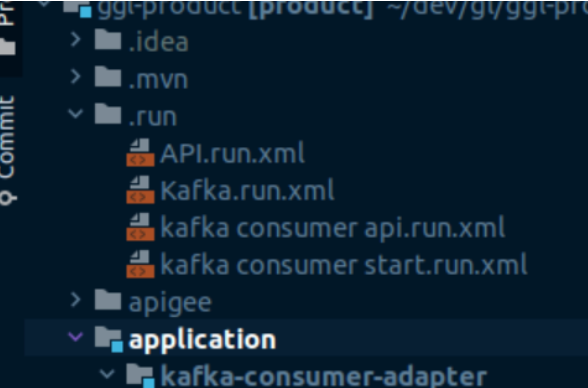
Note : On note l’utilisation d’une variable CONFIG_REPO dans les spring.config.additional-locations, car dans notre cas la configuration est externalisée dans un projet séparé. Il faudra soit mettre manuellement le vrai chemin, soit définir cette variable d’environnement qui pointe vers la config. Si chaque développeur de l’équipe définit la variable CONFIG_REPO préalablement sur son poste, ils pourront directement lancer le runner sans avoir à y toucher.
Par exemple :
CONFIG_REPO=$HOME/dev/mon-entreprise/config/
Avec Maven
Maven nous offre la possibilité de définir des profils, et de les associer à des profils spring boot :
<profiles>
<profile>
<id>api</id>
<activation>
<activeByDefault>true</activeByDefault>
</activation>
<properties>
<spring.profiles.active>produit-api</spring.profiles.active>
</properties>
</profile>
<profile>
<id>kafka</id>
<properties>
<spring.profiles.active>produit-kafka</spring.profiles.active>
</properties>
</profile>
</profiles>
Ici nous avons défini deux profils :
api, qui pointe vers le profil springproduit-apikafka, qui pointe vers le profil springproduit-kafka
J’ai donné des noms différents pour montrer que c’est possible, mais je suggère plutôt de garder le même nom que les profils spring pour ne pas se mélanger, et ne plus savoir quel nom indiquer au lancement de l'application.
Pour simplifier encore, on indique ici le profil à prendre par défaut si aucun n’est renseigné au lancement, avec la balise activeByDefault.
Pour gérer les spring.config.additionnal-location, il est possible d’utiliser le plugin maven spring-boot-maven-plugin.
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<version>${spring-boot-maven-plugin.version}</version>
<configuration>
<skip>true</skip>
<profiles>${spring.profiles.active}</profiles>
<arguments>
<argument>--spring.config.additional-location=${CONFIG_REPO}/config/produit/local.yml
</argument>
</arguments>
</configuration>
</plugin>La commande mvn spring-boot:run lancera l’application en chargeant le profil par défaut, et la configuration externe.
Pour préciser un autre profil :
mvn spring-boot:run -P kafka
Avec Compose pour une application multi-containers
Nous n’avons pour le moment pas pris en compte les applications complexes qui dépendent d’autres services, comme une base de données. Compose (docker-compose) peut s’en charger, à condition d’être à l’aise avec Docker.
Un premier exemple
Compose nous permet de définir et lancer des applications Docker multi-containers.
Imaginons une application “Produit” qui a la responsabilité des données produit de votre entreprise. On peut supposer qu’elle va avoir besoin :
- d’une base de données pour les stocker, PostgreSQL par exemple
- d’un cache Redis pour optimiser les requêtes
- d’un Redis Commander, une UI pour manager le cache Redis
Pour un développeur qui voudrait cloner et démarrer l’application, il ne sera pas simple de la faire tourner, car elle va exiger que tous ces services soient lancés pour démarrer.
À partir d’un Dockerfile, Docker peut nous containeriser un service. Compose nous permet quant à lui de définir plusieurs containers dans un fichier .yml et de les lancer en une seule commande.
Jetons un œil à ce fichier YAML qui liste tous les services à lancer : db, redis, redis-commander.
version: '3'
services:
db:
image: "postgres:11"
container_name: "postgres-produit"
environment:
- POSTGRES_USER=user
- POSTGRES_PASSWORD=password
- POSTGRES_DB=produit
ports:
- "5432:5432"
redis:
image: "redis"
container_name: "redis-produit"
restart: always
ports:
- "6380:6379"
redis-commander:
image: "rediscommander/redis-commander:latest"
container_name: "redis-commander-produit"
restart: always
environment:
- REDIS_HOSTS=local:redis:6380
ports:
- "8009:8081"
produit:
build:
context: .
dockerfile: Dockerfile
volumes: *volumes
ports:
- "8080:8080"
environment:
DB_HOST: postgres-produit
Note : pour le service Produit, le fichier indique à Compose le Dockerfile à aller chercher. On ne va pas aborder Docker et les Dockerfiles dans cet article.
Pour lancer tous les services, il suffit de saisir :
docker-compose -f monfichier.yml up
Le -f sert à préciser le nom du fichier. En nommant le fichier docker-compose.yml, on n’a plus besoin de préciser le nom, ce qui donne alors :
docker-compose upOn peut ajouter -d à la commande pour libérer le terminal.
docker-compose nous répond :
Starting postgres-produit ... done
Starting redis-produit ... done
Starting redis-commander-produit ... done
Starting produit ... done
Le compte est bon, tous les services ont démarré et l’application tourne. Il suffit de commit ce fichier dans le projet, et il suffira à un nouvel arrivant de cloner le projet et de lancer cette commande.
Note : Par défaut, Compose crée tous les conteneurs définis dans un même fichier sur le même network. Ils peuvent donc communiquer entre eux. Si on a plusieurs fichiers .yml, il faudra définir dans chaque fichier le network utilisé pour permettre à vos services d'interagir.
Application multi-profils avec configuration externe
Complexifions le problème, et supposons que notre application Produit contient deux profils Spring qui sont indépendants.
produit-kafkareçoit le flux produit par events dans un topic kafka.produit-apiexpose une API REST qui permet aux autres applications du système de récupérer les informations produit.
La configuration est aussi externalisée dans un autre projet, disons config, cloné également en local. Pour démarrer l’application produit, il faut lui indiquer en paramètre l’endroit où la trouver. Comme noté au début de l’article, on va s’appuyer sur la variable d’environnement CONFIG_REPO.
Concentrons-nous uniquement sur la définition du service produit dans notre fichier docker-compose.yml. Il y en a deux maintenant, un par profil :
produit-api:
build:
context: .
dockerfile: Dockerfile
volumes:
- ${CONFIG_REPO}/produit/local.yml:/deployments/config/produit-config.yml
ports:
- "8080:8080"
environment:
DB_HOST: postgres-produit
spring_profiles_active: produit-api
produit-kafka:
build:
context: .
dockerfile: Dockerfile
volumes:
- ${CONFIG_REPO}/produit/local.yml:/deployments/config/produit-config.yml
ports:
- "8888:8080"
environment:
DB_HOST: postgres-produit
spring_profiles_active: produit-kafkaÇa fonctionne, mais c’est trop redondant. Presque tout est en doublon : build, volumes, environment… Si on avait davantage de profils et une modification à faire dans le fichier, on devrait la faire autant de fois qu’il y a de profils !
Le format YAML nous propose des fonctionnalités qui se rapprochent de l’héritage et de l’extension pour éviter les répétitions. On va définir un service abstrait qui va regrouper la configuration commune, dont nos deux profils hériteront.
& sert à définir une variable réutilisable
* permet d’appeler la variable
<<: permet de l’étendre
application-abstraite:
profiles: [ "donotstart" ]
build: &build
context: .
dockerfile: Dockerfile
environment: &environment
DB_HOST: postgres-produit
volumes: &volumes
- ${CONFIG_REPO}/produit/local.yml:/deployments/config/produit-config.yml
produit-api:
build: *build
volumes: *volumes
ports:
- "8080:8080"
environment:
<<: *environment
spring_profiles_active: produit-api
produit-kafka:
build: *build
volumes: *volumes
ports:
- "8888:8080"
environment:
<<: *environment
spring_profiles_active: produit-kafkaAinsi, pour produit-api et produit-kafka, il suffit de rappeler les valeurs prédéfinies &build, &volumes et &environnement.
Le problème c’est que par défaut, docker-compose up lance tous les services qui sont définis. Il essayera donc de lancer notre application-abstraite, alors qu’elle ne représente pas de service réel, mais n’est là que pour régler notre souci de redondance.
On peut bricoler un peu, et définir un profil Compose. Les profils Compose servent de discriminant pour ne lancer que certains services du fichier.
docker compose --profile monprofil upIci on va s’en servir dans l’autre sens : donner un profil à notre application abstraite pour qu’elle ne soit pas lancée avec le reste des services. Tant que le profil qu’on a défini n’est pas précisé lors du lancement des services, celui-ci ne sera jamais lancé. Ici, j’ai donc attribué le profil donotstart au service abstrait, mais n’importe quel nom fonctionnerait.
docker-compose upEt notre BDD, notre cache, notre cache manager, et les deux profils de notre application Spring Boot sont lancés dans Docker, sur un même network.
Conclusion
Je vous ai présenté 3 solutions pour faciliter l’onboarding d’un développeur sur vos applications, qu’il s’agisse d’un ancien développeur qui n’y a jamais touché ou d’un nouvel arrivant.
Ces solutions peuvent bien entendu s’étendre et s’adapter pour prendre en compte d’autres éléments nécessaires aux applications : gestions de secrets par exemple, avec une variable SECRET_REPO à définir, ou encore gestions des environnements avec un fichier .env à la racine du projet…
Il est aussi possible de combiner ces méthodes. Personnellement, j’ai préféré utiliser Compose pour lancer les bases de données et les caches, et plutôt un Runner IntelliJ pour lancer l’application elle-même pour pouvoir se servir directement des outils de débug proposés par IntelliJ.
A vous de choisir ce qui s'adapte le mieux à votre façon de travailler.
