
C’est quoi une architecture event driven et pourquoi stocker les événements ?
Afin de ne pas réécrire une énième définition de ce type d’architecture, je vous laisse avec celle d’AWS : “une architecture guidée par les événements s'appuie sur des événements pour déclencher la communication entre des services découplés. Ce type d'architecture est courant dans les applications modernes reposant sur des microservices. Un événement est un changement d'état ou une mise à jour, comme l'ajout d'un article au panier sur un site d'e-commerce. Les événements peuvent désigner un état (article acheté, prix modifié et adresse de livraison saisie), ou constituer en des identificateurs (notification d'expédition d'une commande).
Les architectures guidées par des événements comportent trois éléments clés :
- les producteurs d'événements,
- les routeurs d'événements
- les consommateurs d'événements.
Un producteur envoie un événement au routeur, qui filtre les événements et les transmet à son tour aux consommateurs. Les services des producteurs et des consommateurs sont découplés, ce qui leur permet d'être mis à l'échelle, actualisés et déployés de manière indépendante.” (https://aws.amazon.com/fr/event-driven-architecture/)
Maintenant que vous êtes à l’aise avec ce type d’architecture (en tout cas, vous avez compris le principe), il faut comprendre que les événements deviennent le cœur de notre application. Sans eux, l’application n’a plus aucun sens, elle ne fonctionne plus d’ailleurs car plus alimentée. On se rend donc très vite compte que stocker ces événements est essentiel. La partie marketing aimerait savoir combien de produits se sont vendus ces dernières heures, jours, mois et années. D’un autre côté, les architectes aimeraient faire émerger un nouveau service qui viendrait consommer un ou des événements déjà existants. Ils aimeraient donc connaître le nombre d'événements produits en x temps.
Si maintenant, vous êtes vous aussi persuadés que stocker et analyser ces événements est essentiel, vous avez de la chance, vous êtes tombés sur l’article qu’il vous fallait.
L’intégralité du code présenté dans cette article est disponible ici (prêt à être deployé) : https://gitlab.com/bootstrap-stack/serverless-analytics
La production d'événements sur AWS
Le service central de notre architecture est AWS EventBridge, le service de bus d'événements sorti par AWS en juillet 2019. Ce service est beaucoup utilisé directement par d’autres services d’AWS. Les configs rules, par exemple, sont déclenchées par des événements passant par des bus d'événements d’AWS. Chaque service possède ses propres événements qui sont émis dans EventBridge (du succès/échec d’une lambda à un scale up ou down dans un auto scaling group), énormément d’informations transitent dans ces bus. (exemple pour les evenements d’auto scaling : https://docs.aws.amazon.com/autoscaling/ec2/userguide/automating-ec2-auto-scaling-with-eventbridge.html )
Mais du coup, comment on s’y prend pour créer notre propre bus de données dans EventBridge et ensuite envoyer des événements dedans ? Rien de plus simple, vous pouvez le faire directement dans la console ou alors à l’aide de votre outil d’infrastructure-as-code favori. Au cours de cet article, je vais utiliser AWS Cloud Development Kit (CDK) pour déployer mon infrastructure (les quelques bouts de code utilisés seront en Typescript).
const businessEventsBus = new EventBus(app, ‘IpponBlogDemo’)
Maintenant que l’on a créé notre bus, il faut que je vous parle du formalisme à utiliser pour envoyer des événements dans EventBridge. Un événement est constitué de 5 champs :
- **time : ** le temps et l’heure de notre événement que l’on produit.
- **source : **la source correspond au domaine depuis lequel votre événement a été envoyé (domaine vente par exemple)
- **detailType : ** définit l’action de l'événement, si on reste dans l’optique d’une boutique e-commerce, on pourrait avoir item.sold par exemple dans ce champ.
- **detail : **le contenu de l'évènement, c’est ici que l’on mettra les champs spécifiques (le nom du produit, son prix, …).
- **event bus name : **le nom du bus dans lequel on souhaite envoyer l’événement.
Tous ces champs sont encapsulés dans un objet JSON et dans notre cas, envoyé via une classe Typescript qui utilise le sdk d’AWS pour appeler l’api d’EventBridge.
import { EventBridgeClient, PutEventsCommand } from '/opt/nodejs/node_modules/@aws-sdk/client-eventbridge'
export default class EventSenderEventBridge {
private client = new EventBridgeClient({})
private busName = ‘myBusName’
send = async () => {
const query = new PutEventsCommand({
Entries: [{
EventBusName: this.busName,
Source: “sales”,
DetailType:”item.sold”,
Detail: {“name”: “toothbrush”, “price”: 9.99, “quantity”: 1},
}],
})
await this.client.send(query)
}
}
Comment s’y prendre pour stocker nos données ?
Etant un grand fan du monde du serverless et des services managés (et oui, ça rend quand même la vie tellement plus facile), ayant un porte-monnaie pas très rempli en plus, je me suis tourné vers une stack flexible.
Nous allons utiliser S3 pour stocker nos données. Ce support est parfait pour notre cas d’utilisation. Pas cher, ultra flexible et 100% managé par AWS.
On a le support pour nos données, on sait comment produire des événements facilement. Maintenant, il nous manque cette petite colle entre notre réceptacle et les événements.
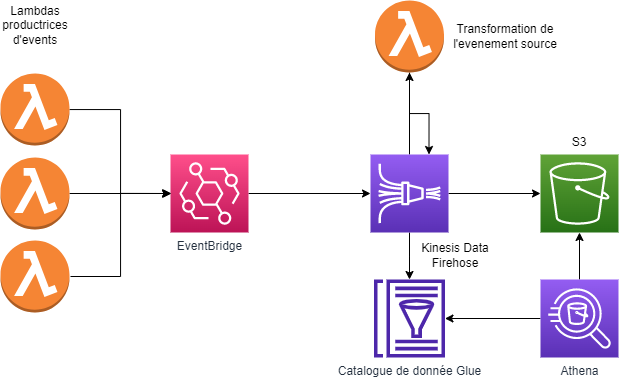
Cette colle va se faire grâce au service Kinesis et notamment Kinesis Data Firehose. En effet, il y a une intégration déjà existante entre le service Kinesis Data Firehose et EventBridge avec comme destination… un bucket S3 !
Dans un premier temps, vous ne connaissez peut-être pas le service Kinesis Data Firehose voici la définition du service d’après AWS : Amazon Kinesis Data Firehose est un service Extraction, transformation et chargement (ETL) qui capture, transforme et fournit de manière fiable des données en streaming aux lacs de données, entrepôts de données et services analytiques. (https://aws.amazon.com/fr/kinesis/data-firehose/)
Ce n’est peut-être pas encore très clair, voici un schéma illustrant le fonctionnement du service :
On remarque à gauche, le “20+ AWS Services” qui contient le service EventBridge, nos événements seront donc transmis à KDF (Kinesis Data Firehose) on pourra ensuite les transformer facilement à l’aide d’une lambda ou grâce aux outils fournis par AWS. Le résultat sera finalement transmis à la destination, dans notre cas, un bucket S3.
Comment créer et paramétrer un stream Kinesis Data FireHose
Passons maintenant à la création avec CDK de notre infrastructure, je vais essayer de détailler les différents champs demandés lors de la création de notre stream.
Il vous faudra tout d’abord créer un rôle IAM avec certaines permissions. Pour ne pas écrire trop de code, je vais seulement créer le rôle et ajouter une police IAM dedans pour vous montrer comment faire :
const deliveryStreamRole = new Role(
construct, props.eventTypeUppercased + 'DeliveryStreamRole', {
assumedBy: new ServicePrincipal('firehose.amazonaws.com'),
},
)
deliveryStreamRole.addToPolicy(new PolicyStatement({
resources: ['*'],
actions: [
'logs:CreateLogGroup',
'logs:PutLogEvents',
'logs:CreateLogStream',
],
}))
Maintenant, il vous manquera à ajouter certaines polices IAM (en fonction de vos besoins) :
- pour le service S3 : AbortMultipartUpload, GetBucketLocation, GetObject, ListBucket, ListBucketMultipartUploads, PutObject
- pour le service **Lambda **(si vous souhaitez transformer vos objets en entrée vers un format différent de celui d’EventBridge) : InvokeFunction, GetFunctionConfiguration
- pour le service **Glue (nous verrons l’utilité de ce service par la suite) *: GetDatabase, GetTable, GetPartition, GetTableVersions
C’est normalement tout bon côté permission, il est désormais temps de créer notre bucket S3 pour pouvoir stocker nos données :
const destinationBucket = new Bucket(
construct,
‘BlogIpponDemoBucket’,
{ bucketName: ‘blog-ippon-destination-repository’ }
Passons désormais à la grosse partie, la création de notre stream Kinesis Data FireHose (KDF). Je vais décomposer la création de celui-ci en plusieurs étapes pour pouvoir expliquer à quoi elles correspondent respectivement.
Tout d’abord, dans le document du CDK concernant le service KDF, il nous faut choisir une “destination configuration” à passer en objet dans le constructeur. Voici un lien vers la documentation : https://docs.aws.amazon.com/cdk/api/v2/docs/aws-cdk-lib.aws_kinesisfirehose.CfnDeliveryStream.html#construct-props
On peut y retrouver différentes destinations, mais celle qui nous intéresse est S3, qui plus est, l’objet extendedS3DestinationConfiguration. Le code qui suit sera donc la configuration de cet objet.
Pour des soucis de lisibilité, nous allons rajouter des variables intermédiaires pour certaines parties. Deux variables seront nécessaires, la première concerne le champ **processingConfiguration **et la seconde le champ dataFormatConversionConfiguration.
const processingConfiguration = {
enabled: true,
processors: [
{
type: 'Lambda',
parameters: [
{
parameterName: 'LambdaArn',
parameterValue: ‘BlogIpponDemoLambdaTransformationArn’,
},
],
},
{
type: 'AppendDelimiterToRecord',
parameters: [
{
parameterName: 'Delimiter',
parameterValue: '\\n',
},
],
}
],
}
Nous voici dans la partie processingConfiguration. Cette partie intervient une fois que la donnée a passé le buffer (ce que je vais expliquer par la suite). Soit on ne fait rien, dans ce cas, la donnée part directement vers notre destination, soit on décide de la transformer avant de la stocker. Dans notre cas, notre donnée source est un événement EventBridge.
On aimerait bien pouvoir transformer l'événement source en quelque chose de plus métier, quelque chose qui aura du sens quand on viendra l’analyser. Dans ce cas, on va faire intervenir une petite lambda que nous aurons construite. C’est une lambda très basique, elle prend un JSON en entrée pour le transformer en un autre JSON en sortie (notre événement métier).
De ce fait, nous avons épuré la donnée source de ses champs inutiles. Le second processeur est juste là pour rajouter un délimiteur entre chacun de nos records. La donnée est désormais prête à partir vers notre bucket S3.
const dataFormatConversionConfiguration = {
enabled: true,
inputFormatConfiguration: { deserializer: { openXJsonSerDe: {} } },
outputFormatConfiguration: { serializer: { parquetSerDe: {} } },
schemaConfiguration: {
catalogId: props.glueDatabase.catalogId,
roleArn: deliveryStreamRole.roleArn,
databaseName: props.glueDatabaseName,
tableName: props.glueTableName,
},
}
Notre deuxième variable est **dataFormatConversionConfiguration. **Elle va nous permettre de configurer la partie format de la conversion des données (en entrée et en sortie) ainsi que de définir un schéma pour nos données (c’est ici que va intervenir Glue).
Ici, nos événements en entrée utilisent le serializer **openXJsonSerDe **et pour la sortie, histoire de ne pas stocker les données telles quelles, nous allons les stocker au format Apache Parquet qui est un format sous forme de colonne (ce qui va réduire les coûts). Nous utiliserons alors le deserializer **parquetSerDe. **
Il est temps désormais de définir un schéma pour nos données. Ce schéma est contenu dans une table Glue, lui-même contenu dans une base de données. Ici on renseigne seulement où est stocké notre schéma (partie schemaConfiguration).
Il est désormais temps d’assembler le tout dans notre objet de configuration en y ajoutant les autres champs
const deliveryStream = new CfnDeliveryStream(construct, props.eventTypeUppercased + 'DeliveryStream', {
extendedS3DestinationConfiguration: {
bucketArn: props.destinationBucket.bucketArn,
roleArn: deliveryStreamRole.roleArn,
bufferingHints: {
intervalInSeconds: 60,
},
cloudWatchLoggingOptions: {
enabled: true,
logGroupName: 'kinesis-log-group',
logStreamName: 'kinesis-logs',
},
prefix: 'year=!{timestamp:yyyy}/month=!{timestamp:MM}/day=!{timestamp:dd}custom_partition=!{partitionKeyFromLambda:custom_partition}/',
errorOutputPrefix: 'errors/!{firehose:error-output-type}/',
processingConfiguration: processingConfiguration,
dataFormatConversionConfiguration: dataFormatConversionConfiguration,
dynamicPartitioningConfiguration: { enabled: true, retryOptions: { durationInSeconds: 10 } },
},
}
)
Les deux premiers champs correspondent à l’ARN du bucket S3 de destination ainsi que de l’ARN du rôle IAM à utiliser.
Le champ **bufferingHints **quant à lui est intéressant, il nous permet de configurer la gestion du buffer de notre stream. Le buffer correspond correspond soit au temps de rétention de la donnée, soit au volume minimal de données à envoyer.
Deux champs sont disponibles, **intervalInSeconds **qui correspond à la partie temporelle (combien de temps attendre). La valeur de ce champ peut aller de 60s à 900s et par défaut est à 300s (on attend au minimum 1 minute entre chaque envoi et au maximum 15 minutes). On a ensuite le champ sizeInMBs, correspondant à la quantité de données qu’on doit attendre avant d’envoyer. Cette quantité varie entre 1 et 128 avec par défaut une valeur à 5.
On s’attaque désormais à la partie concernant les logs, ici on a un objet cloudWatchLoggingOptions qui nous permet d’activer les logs dans cloudwatch en y paramétrant le nom du Group et du Stream CloudWatch.
Il nous reste dorénavant l’une des parties cruciales pour définir notre stream, le préfixe à utiliser (prefix) pour savoir où envoyer nos données dans notre bucket S3 (et surtout, à l’aide de quelles partitions). Ici, j’ai voulu avoir une séparation par datetime avec un compartiment par année/mois/jours et ensuite par une partition custom que nous verrons plus tard. On utilise un mode de partitionnement basé sur du Hive pour pouvoir tirer parti du partitionnement dynamique. Il faut juste savoir que nous avons besoin de définir nos clés de partitions avec ce formalisme “cle_de_partition=!{On Récupère La Clé Ici}“. On fait de même pour la sortie des erreurs de traitement ou d’envoi avec le mot clé errorOutputPrefix. Le fait d’avoir les erreurs directement envoyées dans le bucket S3 est super pratique au passage, on peut très facilement voir si l’on a des erreurs. On peut aussi automatiser la détection de ces erreurs en construisant une lambda qui sera déclenchée à l’ajout d’un fichier dans ce compartiment d’erreur.
Pour en finir avec la création de notre stream, nous allons activer et configurer le partitionnement dynamique à l’aide du mot clé dynamicPartitioningConfiguration. Le partitionnement dynamique est récent et propose beaucoup d'avantages. Le premier étant de pouvoir requêter nos données en fonction de clés que nous définissons nous-même. Ces clés vont permettre de construire les requêtes SQL avec des clauses WHERE. Cela permettra à Athena (le service que l’on va utiliser par la suite pour requêter) de piocher seulement dans les données qui nous intéressent vraiment (et donc, ne pas scanner des données inutilement). On aura donc une amélioration des performances, des coûts et du nombre de données scannées. La contrepartie est que cette option est récente et pas forcément bien documentée pour le moment.
https://docs.aws.amazon.com/firehose/latest/dev/dynamic-partitioning.html
Comment créer et paramétrer une table Glue pour l’utiliser avec KDF
Ici, l’utilisation de Glue que nous faisons est basée sur la définition d’un schéma de données dans une base de données. Il faut savoir que Glue est un service d'intégration de données serverless qui permet aux utilisateurs faisant de l’analytics de découvrir, préparer, déplacer et intégrer facilement des données provenant de plusieurs sources. Il est donc beaucoup plus complet et complexe que l’utilisation que l’on en fait ici.
Nous y sommes presque, plus que deux étapes et nous pourrons enfin requêter nos événements métier issus d’EventBridge. Passons désormais à la création d’une base de données et d’une table Glue :
const glueDatabase = new CfnDatabase(scope, 'glue-database', {
catalogId: ‘IpponBlogDemoAwsAccountId’,
databaseInput: {
name: ’IpponBlogDemoGlueDatabase’,
},
}
)
Pas besoin d’expliquer ce passage, je pense que le code est assez basique avec ce que vous avez pu voir dans l’article désormais.
Pour la création de la table, la configuration intéressante se situera dans l’objet tableInput.
Cet objet étant assez gros, on va devoir faire intervenir quelques variables intermédiaires. Ces variables seront : **partitionKeys **et columns.
const partitionKeys = [
{
'name': 'year',
'type': 'string',
},
{
'name': 'month',
'type': 'string',
},
{
'name': 'day',
'type': 'string',
},
{
‘name’ : ‘custom_partition’,
‘type’: ‘string’,
}
]
Ce premier objet nous permet de définir les clefs de partitions. Ces clefs correspondent à ce qu’on a mis dans la partie préfixe lors de la configuration de notre stream auparavant. Le champ “custom_partition” ici est juste pour rappeler la partition que l’on a ajouté grâce à la lambda de transformation.
const columns = [
{
‘name’: ‘name’,
‘comment’: 'Name of the item’,
‘type’: 'string'
},
{
‘name’: ‘price’,
‘comment’: 'Price of the item’,
‘type’: 'string'
},
{
‘name’: ’quantity’,
‘comment’: ’Quantity of item’,
‘type’: 'string'
},
]
Ce champ-ci va nous permettre de définir le schéma qu’auront les données dans notre bucket S3. Ici on aura donc un nom, un prix et une quantité pour chaque item.
On peut désormais assembler l’ensemble dans notre objet CDK.
const glueTable = new CfnTable(scope, 'glue-table-for-athena', {
databaseName: ’IpponBlogDemoGlueDatabase’’,
catalogId: ‘IpponBlogDemoAwsAccountId’,
tableInput: {
name: ‘IpponBlogDemoGlueTable’,
tableType: 'EXTERNAL_TABLE',
partitionKeys: partitionsKeys,
storageDescriptor: {
compressed: true,
inputFormat: 'org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat',
outputFormat: 'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat',
serdeInfo: {
serializationLibrary: 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe',
},
columns: columns,
location: ‘IpponBlogDemoS3BucketUrl’,
},
},
})
Le champ storageDescriptor va nous permettre de décrire comment seront stockées les données. Ici on va lui dire que nos données seront compressées, notre format en entrée sera du type Apache Parquet et en sortie, la même chose. N’étant pas forcément expert en la matière, je ne vais pas rentrer dans les détails de cette configuration, elle a le mérite de fonctionner. Il n’y aura plus qu’à définir la localisation de nos données (où sont-elles stockées) grâce au mot clé location (on passe ici l’url de notre bucket S3).
Il ne reste plus qu’à décrire à Glue à quoi correspondent les fameuses clés de partitions (i.e. le type associé, les valeurs possibles et le nombre de chiffres possibles par exemple. Pour ce faire, on va utiliser la fonction addPropertyOverride() sur notre table précédemment créée
glueTable.addPropertyOverride('TableInput.Parameters.projection\\.enabled', true)
glueTable.addPropertyOverride('TableInput.Parameters.projection\\.year\\.type', 'integer')
glueTable.addPropertyOverride('TableInput.Parameters.projection\\.year\\.range', '2022,2050')
glueTable.addPropertyOverride('TableInput.Parameters.projection\\.year\\.digits', '4')
glueTable.addPropertyOverride('TableInput.Parameters.projection\\.month\\.type', 'integer')
glueTable.addPropertyOverride('TableInput.Parameters.projection\\.month\\.range', '1,12')
glueTable.addPropertyOverride('TableInput.Parameters.projection\\.month\\.digits', '2')
glueTable.addPropertyOverride('TableInput.Parameters.projection\\.day\\.type', 'integer')
glueTable.addPropertyOverride('TableInput.Parameters.projection\\.day\\.range', '1,31')
glueTable.addPropertyOverride('TableInput.Parameters.projection\\.day\\.digits', '2')
glueTable.addPropertyOverride('TableInput.Parameters.projection\\.custom_partition\\.type', 'injected')
glueTable.addPropertyOverride('TableInput.Parameters.storage\\.location\\.template', 's3://ippon-blog-demo-analytics-repository/year=${year}/month=${month}/day=${day}/custom_partition=${custom_partition}')
Dans notre cas, on vient dire que la partition **year **est un entier composé de 4 chiffres et entre 2022 et 2050. On répète le processus pour les mois et les jours et on laisse Glue définir lui-même le type de notre partition custom grâce au mot clé injected. Il est très pratique mais possède un gros desavantage, on ne peut faire que des égalités par la suite dans les requêtes SQL sur ce champ (ce qui peut être embêtant quand on souhaite récupérer les infos sur une période précise et pas une date fixe par exemple).
Et voilà, le tour est joué.
Comment requêter les données dans S3 ?
Nous avons désormais une stack fonctionnelle qui permet de récupérer les événements envoyés dans EventBridge, les transformer vers un format orienté métier et les envoyer dans un bucket S3 avec de belles partitions. Il ne nous reste plus qu’à requêter toutes ces données. Quand on parle d’analytics et de S3, on pense souvent au service AWS Athena. En effet, Athena est un service qui permet de requêter très facilement un bucket S3 (et bien d’autres sources de données), utilisant le langage SQL et Apache Spark sous le capot. En plus de ça, Athena est un service complètement managé par AWS, pas de gestion de l’infrastructure et ça, c’est génial.
Le plus beau dans l’histoire ? Vous n’avez besoin de rien faire : il vous suffit, une fois arrivé sur la console d'Athéna, de choisir votre base de données Glue, choisir la table en question, configurer la destination des résultats des requêtes et vous serez prêt à requêter vos données.
Ce qui est magique, c’est que grâce au stockage de nos données au format parquet couplé avec le partitionnement dynamique de données, toute cette stack va vous coûter que très peu d’argent. À moins évidemment de produire énormément d'événements (car oui, Athéna peut coûter cher). Et quand je dis énormément, c’est vraiment beaucoup. Sur un projet personnel, je suis à environ 100.000 événements par jours et la stack ne me coûte pas un centime avec le plan gratuit de AWS. La requête sur 10 jours, soit ~1 m d'événements, représente 80 Mo de données scannées. Sachant que le prix d'Athéna est de 5€/To de données scannées, cette requête représente un peu moins de 0,0005 centimes. Tout dépend bien sûr de la taille de vos événements.
Pour conclure cet article, il y a moyen d’optimiser les performances au moment de la requête que l’on fait avec Athena. En effet, moins on a de fichiers dans notre bucket S3 de destination, plus Athena sera rapide à l'exécution de la requête. Il est donc possible à l’aide d’un job EMR (Elastic MapReduce) de joindre les fichiers ensemble pour avoir moins de fichier, mais des fichiers plus gros.
Au niveau des coûts, il faut faire attention au bucket de résultat des requêtes d’Athéna aussi, ne pas hésiter à mettre des configurations de cycle de vie (lifecycle configuration) sur les buckets pour faire expirer les objets dont vous n’avez plus besoin (on arrive vite à des requêtes qui ont des Go de résultat). Il faut également bien penser à ce qu’on veut stocker, stocker pour stocker n’est pas très intéressant (que ce soit pour le métier comme pour le porte-monnaie). Ne stockez que ce qui peut ajouter de la valeur aux requêtes que vous allez faire, le reste n’est certainement pas utile dans le cas d’analytics.
