

Ce 8 novembre 2022 a eu lieu, à la Maison de la Mutualité, l’étape parisienne du Data + AI World Tour de Databricks. Au programme, une quinzaine de conférences sur la thématique du Lakehouse, un concept apporté par Databricks sur l’architecture de données. Databricks étant l’un des partenaires majeurs d’Ippon, la Practice Data était présente afin d’échanger avec les participants. Nous, Sofian Gaide et Romain Le Goas, avons assisté à plusieurs conférences autour du Lakehouse, et vous proposons dans cet article un résumé des différentes connaissances que nous avons pu acquérir au cours de cet événement.
Pour commencer, il nous semble important de rappeler, selon Databricks, la définition du concept de Lakehouse.
« La solution Lakehouse de Databricks combine les transactions ACID et la gouvernance des données des Data Warehouses avec la flexibilité et la rentabilité des Datalakes pour permettre la Business Intelligence (BI) et le Machine Learning (ML) sur toutes les données. Le Lakehouse conserve vos données dans votre stockage Cloud scalable, dans des normes de données open source, ce qui vous permet d'utiliser les données comme et où vous le souhaitez. »
Data Warehouse and analytics on the Lakehouse
Durant ce premier atelier, il nous a été présenté les avantages d’utiliser le Lakehouse comme Data Warehouse.
Selon Databricks, le Lakehouse permet d’unifier les données, l’IA et les workloads analytiques à un seul endroit. L’exemple utilisé était Databricks SQL, le service de Data Warehouse serverless basé sur la plateforme Lakehouse.
Cet outil sert notamment pour l’ingestion, la transformation et le requêtage de données, étapes qui sont simplifiées grâce à l’intégration de différents partenaires au sein de l’écosystème Databricks. Par exemple, l’ingestion des données de l’entreprise peut s’effectuer avec Fivetran, la transformation avec dbt et le requêtage avec des outils de visualisation comme Tableau ou Power BI, pour consommer et interroger la donnée.
Cet atelier était l’occasion pour Databricks de présenter les dernières fonctionnalités incorporées dans Databricks SQL :
-
Python UDF : l’incorporation des User-Defined Functions Python à Databricks SQL rend possible l’exécution de code Python au sein d’une fonction SQL. Ces UDFs sont définies et gérées au sein du Unity Catalog. Il est ainsi possible de gérer leurs permissions d’accès et d’utilisation grâce aux instructions GRANT ou REVOKE. Pour créer une UDF Python, les utilisateurs ont besoin des autorisations USAGE et CREATE sur le schéma et USAGE sur le catalogue. La permission EXECUTE est nécessaire afin de lancer un UDF. Pour éviter tout problème d’exécution de code Python malveillant, l’exécution est réalisée dans un environnement isolé ;
-
Geospatial Analytics : fonctionnalité qui permet un stockage efficace de données spatiales de petite et grande taille ;
-
Query Federation : Databricks SQL étant basé sur le Lakehouse, de nombreuses sources de données peuvent être facilement connectées et ainsi simplifier le requêtage de sources cloisonnées, sans avoir à migrer les données vers un système unifié. Cela permet donc de requêter une base de données distante sans se soucier de l’ingestion de données.
À date, il est possible de configurer des connexions en lecture seule sur les moteurs PostgreSQL, MySQL, Snowflake, AWS Redshift, Azure Synapse et SQL Server. Il est également possible de combiner les bases avec Delta Lake, grâce au protocole open source Delta Sharing pour le partage des tables Delta. Une autre fonctionnalité de Query Federation est l’optimisation automatique et intelligente des pushdowns, procédé qui permet de réduire considérablement le temps de traitement des requêtes via un filtrage des données à la source lorsque le processus de traitement débute ; -
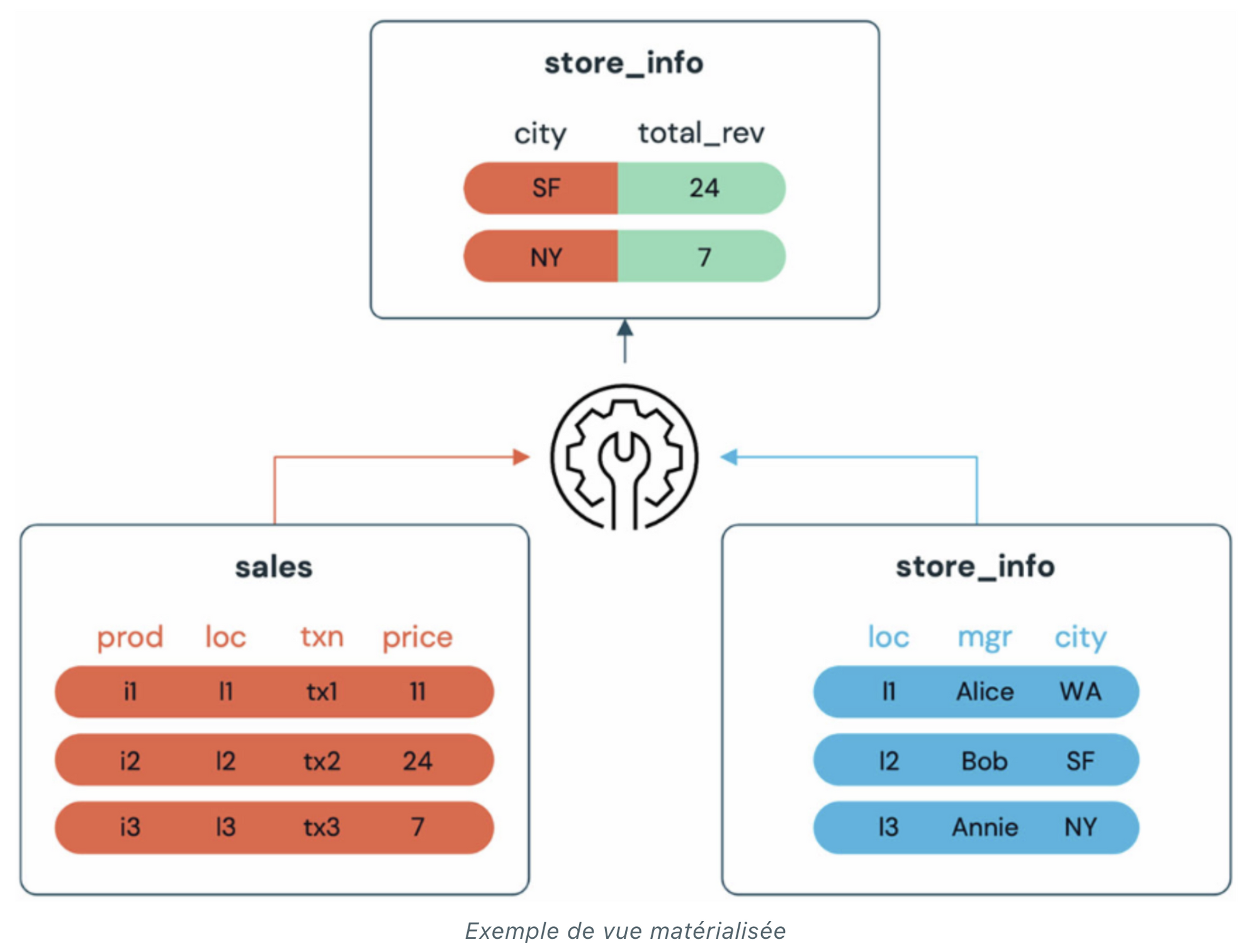
Materialized Views : les vues matérialisées sont construites sur la base des Delta Live Tables (définies dans la suite de l’article) et réduisent la latence des requêtes en pré-calculant les requêtes lentes et les calculs fréquemment utilisés. Par rapport à une vue classique où la requête est exécutée à chaque appel de la vue, la vue matérialisée va persister le résultat de sa définition dans un storage lors de son premier appel, et c’est depuis celui-ci qu’elle sera récupérée lors du deuxième appel. Cela permet donc de diminuer les coûts d’infrastructure.
L’utilisation des vues peut aussi simplifier la production de reportings en nettoyant, enrichissant et dénormalisant les tables.
Enfin, il est possible, avec les vues matérialisées, de contrôler l’accès à la donnée et le partage de celle-ci aux utilisateurs internes, externes ou à des organisations ;
- Data Modeling with Constraints : grâce à cette feature, il est plus simple de modéliser des schémas sur le Lakehouse. Elle propose :
- les contraintes Primary & Foreign Key pour permettre aux utilisateurs finaux de comprendre les relations entre les tables ;
- les colonnes IDENTITY qui génèrent des valeurs entières et uniques lorsque de nouvelles lignes sont ajoutées ;
- les contraintes CHECK renforcées pour éviter les problèmes de qualité ou d’exactitude des données.
- Information Schema : basé sur la norme SQL, il offre un accès unifié et rapide aux informations sur les catalogues, tables, colonnes et permissions associées, via des requêtes SQL. Le schéma est présent dans tous les catalogues qui diffèrent du HIVE_METASTORE. Le HIVE_METASTORE est un metastore Hive accessible par les clusters Databricks, qui sert à conserver les métadonnées des tables.

Databricks cherche à avoir un Data Warehouse toujours plus économique et rapide en termes de requêtes. Pour cela, il utilise le moteur Photon ou encore des fonctionnalités Predictive IO que nous évoquerons dans la suite de l’article.
Lors de la conférence, Databricks a également présenté les progrès effectués sur le temps de warm-up de la première requête dans Databricks SQL. En novembre 2021, cela prenait entre 40 et 50 secondes, contre une dizaine de secondes aujourd’hui. Cela est rendu possible grâce à l’utilisation de caches de warm-up et grâce à la connexion aux metastores. Databricks fait la promesse que, d’ici quelques mois, le temps de préchauffe ne prendra plus que moins de trois secondes, grâce au pré-warm-up des exécuteurs.
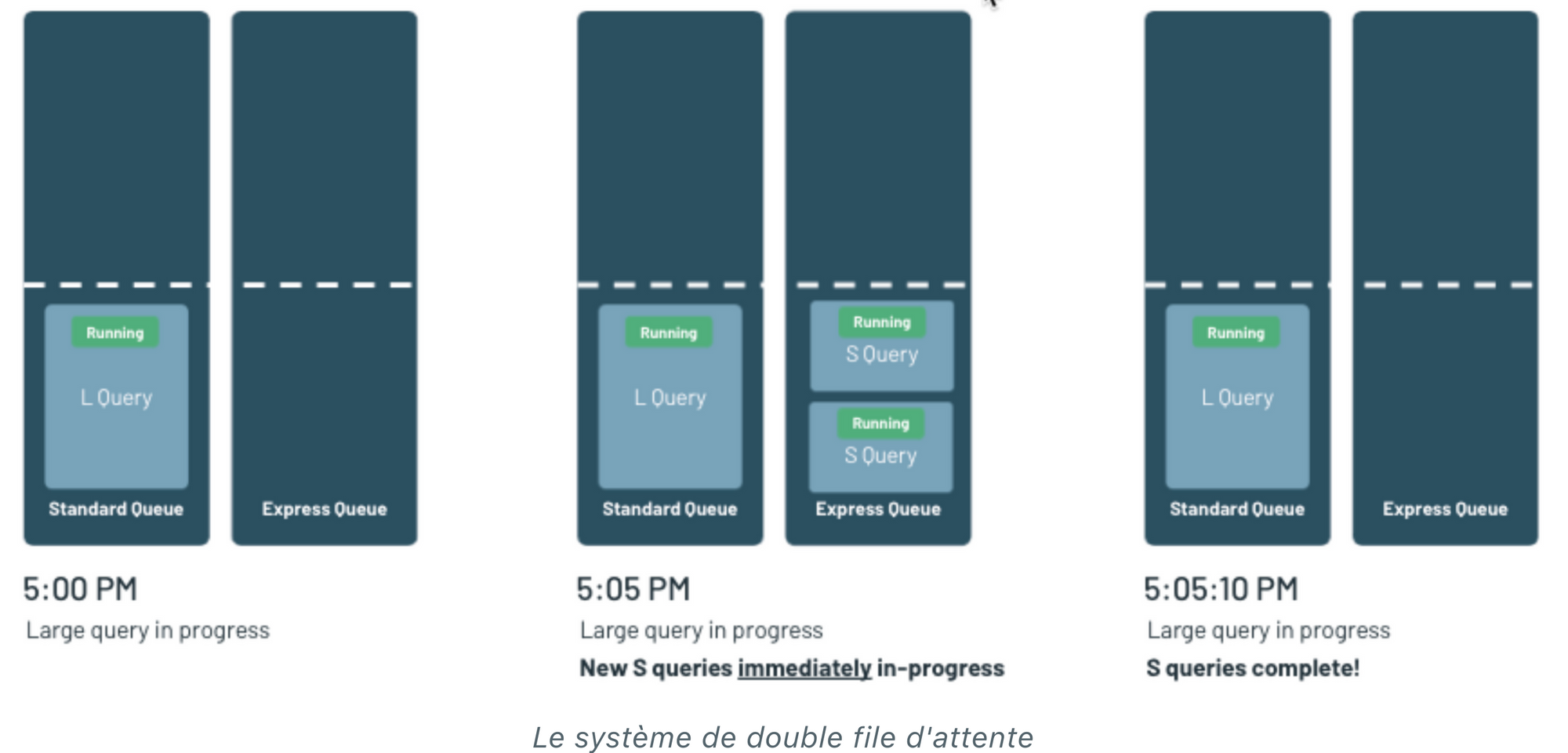
Une autre solution apportée au Lakehouse pour améliorer les performances est la mise en place d’une double file d’attente afin d’éviter que les requêtes chronophages ne bloquent celles exécutables plus rapidement. Ainsi, via un système d’analyse, s’il y a une “grosse” requête en cours d’exécution dans la file Standard et qu’une “petite” requête arrive, le moteur Databricks SQL va pouvoir la rediriger dans la file d’attente Express pour qu’elle soit exécutée prioritairement.
Radical speed on the Lakehouse: Photon under the hood
Dans ce deuxième atelier, il nous a été présenté le Photon Engine, le Predictive IO ainsi que les Deletion Vectors.
Qu’est-ce que Photon ?
« Le Photon correspond à du Spark réécrit en C++ pour profiter des dernières instructions vectorisées du CPU. »
Conçu dès le départ pour offrir les performances les plus rapides à moindre coût, Photon permet de réaliser jusqu'à 80% d'économies sur le coût total, tout en diminuant la latence. Photon est très utile sur les requêtes chronophages, qui peuvent s’exécuter pendant plusieurs heures. Sur des requêtes plus rapides, les gains de performances sont moindres. Pour que Photon soit rentable, il est nécessaire que le temps d’exécution soit divisé par deux au minimum, étant donné que ce moteur est deux fois plus cher qu’un cluster classique. Cela apporte une vitesse d’exécution des workloads analytiques douze fois plus rapide, selon Databricks.
Photon est le premier moteur qui permet aux équipes data de standardiser un ensemble d'APIs pour toutes les charges de travail - ETL, analyses et data science - en mode batch ou streaming.
Photon est un moteur conforme à la norme ANSI SQL, conçu pour être compatible avec les APIs d’Apache Spark, et fonctionne simplement avec le code existant. Pour les langages SQL, Python, R, Scala et Java, aucune réécriture n'est nécessaire. Photon est disponible à partir du Runtime 9.1 LTS, mais il est recommandé d’utiliser le Runtime 11.2, à partir duquel Photon est rendu Generally Available, avec une forte amélioration des performances et une augmentation des fonctions Spark supportées.
Quelques chiffres sur Photon :
- Croissance de 10x au cours des six derniers mois ;
- 7 000 clients l'utilisent ;
- Des milliards de requêtes ;
- Exaoctets de données traitées.
Quel est l’impact de Photon au sein d’un ETL ?
Pour répondre à cette question, a été mis en avant un cas d’usage de l’entreprise Dupont avec une architecture comprenant Azure Data Factory, Databricks, et PowerBI.
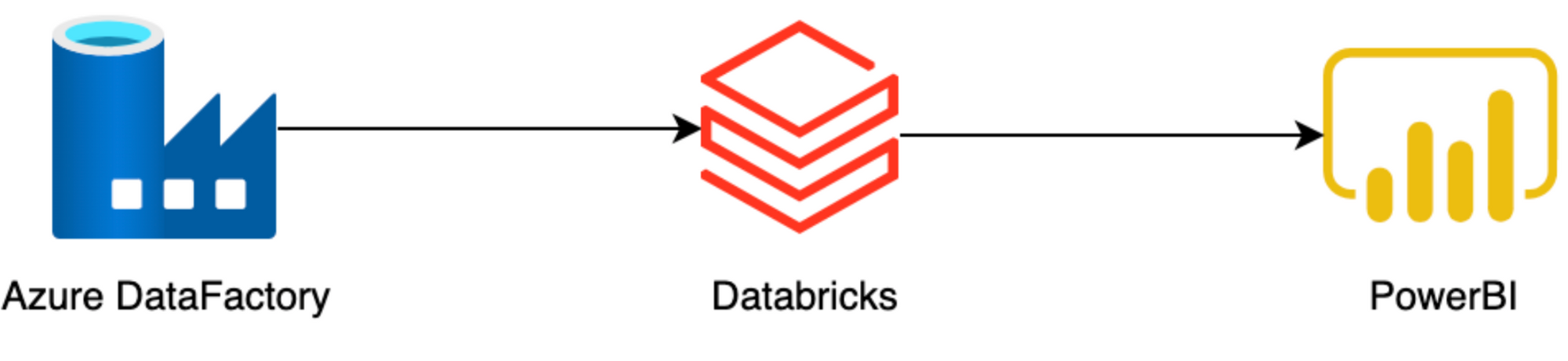
L'entreprise voulait des données plus fiables et plus fraîches provenant de sites de production situés dans le monde entier, ce qui rendait l’architecture compliquée avec près de 120 tables dans le workflow.
Avec Photon, Dupont a obtenu 4 fois moins de latence et une réduction des coûts du même ordre. Le résultat est le suivant : une réduction du coût total de 75% et une amélioration de la latence de 11%.
Quel est l’impact de Photon pour une ingestion en streaming ?
Contexte : Un analyste marketing doit générer des rapports à partir de données de parcours fournies par des partenaires. L'ETL comprend 700Go de fichiers CSV, une transformation légère et l'écriture dans une table Delta. L’utilisation de Photon a permis une réduction du coût total de 19% et une amélioration de la latence.
Voici les différentes compatibilités de Photon avec le RunTime 11.3 :

Quels sont les prochains objectifs de Photon ?
Photon nous réserve une amélioration future de l’analytics avec une diminution de la latence sur les parties BI ainsi que l’ajout des UDFs Python et pandas.
De plus, le coût et les performances devraient s’améliorer avec notamment des exécutions compressées grâce à l’utilisation de dictionnaires.
Qu’est-ce que Predictive IO ?
Predictive IO est une nouvelle suite de fonctionnalités qui optimise la partie analyse, filtrage d'une requête, ou encore la construction de modèles IA/ML, afin que le Lakehouse se comporte comme un Data Warehouse intelligent.
Lors d’une requête, l’utilisation du deep learning permet de déterminer le plan d'exécution le plus efficace pour lire et scanner uniquement les données nécessaires et ainsi supprimer les colonnes et les lignes qui ne le sont pas. De plus, cela permet de calculer les probabilités des critères de recherche dans les requêtes sélectives correspondant à une ligne. Au fur et à mesure que les requêtes s'exécutent, ces probabilités sont utilisées pour anticiper l'emplacement de la prochaine ligne correspondante.
A savoir que les Predictive IO sont prises en charge par les DataWarehouses SQL serverless, ainsi que par les clusters Photon.
Qu’est-ce que les Deletion Vectors ?
Les Deletion Vectors permettent d'améliorer jusqu'à 10 fois les performances des opérations DELETE, MERGE et UPDATE avec le moteur Photon.
Ces opérations sont plus efficaces en réduisant la quantité de données qui doivent être écrites sur le stockage Cloud.
Data Streaming on the Lakehouse
Dans cet atelier sur le streaming, Databricks nous présente les différents cas d’usages du streaming dans le Lakehouse ainsi que ses avantages. Pour cela, nous allons aborder les concepts de Delta Live Tables ainsi que SQL pour l’ingestion streaming.
Commençons par lister les principaux avantages du streaming dans le Lakehouse qui sont :
- Donnez l'accès à toutes vos équipes Data : les Data Engineers, Data Scientists et Data Analysts peuvent facilement construire des pipelines de données en continu avec les langages et outils qu'ils connaissent déjà ;
- Simplifiez le développement et les opérations : réduisez la complexité en automatisant de nombreux aspects de la production associés à la création et à la maintenance des flux de données en temps réel ;
- Une plateforme unique pour les données et les flux streaming : éliminez les silos de données, centralisez les modèles de sécurité et de gouvernance et offrez une prise en charge complète de tous vos cas d'utilisation en temps réel.
De plus, il est facile d'intégrer les outils Databricks en fonctions des différents cas d’usages streaming :
- Real-Time Analytics : Delta Live Tables & Workflows + Databricks SQL
- Real-Time Machine Learning : Delta Live Tables & Workflows + ML Platform
- Real-Time Applications : Spark Structured Streaming
Qu’est-ce que Delta Live Tables ?
« Delta Live Tables (DLT) facilite la création et la gestion de pipelines fiables fournissant des données de haute qualité sur Delta Lake. DLT aide les équipes de data engineering à simplifier le développement et la gestion ETL avec le développement de pipelines déclaratifs, des tests de données automatiques et une visibilité approfondie pour le monitoring et la restauration. »
Delta Live Tables est le moyen le plus simple de faire du streaming dans le Lakehouse:
- Accélérez le développement ETL : déclarez du SQL ou du Python et Delta Live Tables gère automatiquement l’orchestration des DAG, les tentatives suite à un échec ainsi que les changements de données.
- Gérez automatiquement votre infrastructure : automatisez les activités complexes comme la récupération, l'auto-scaling et l'optimisation des performances.
- Assurez la qualité des données : fournissez des données fiables grâce aux contrôles de qualité, aux tests et au monitoring.
- Unifiez le batch et le streaming : bénéficiez de la simplicité de SQL et de la rapidité du streaming grâce à une API unifiée.
Comment cela fonctionne-t-il ?
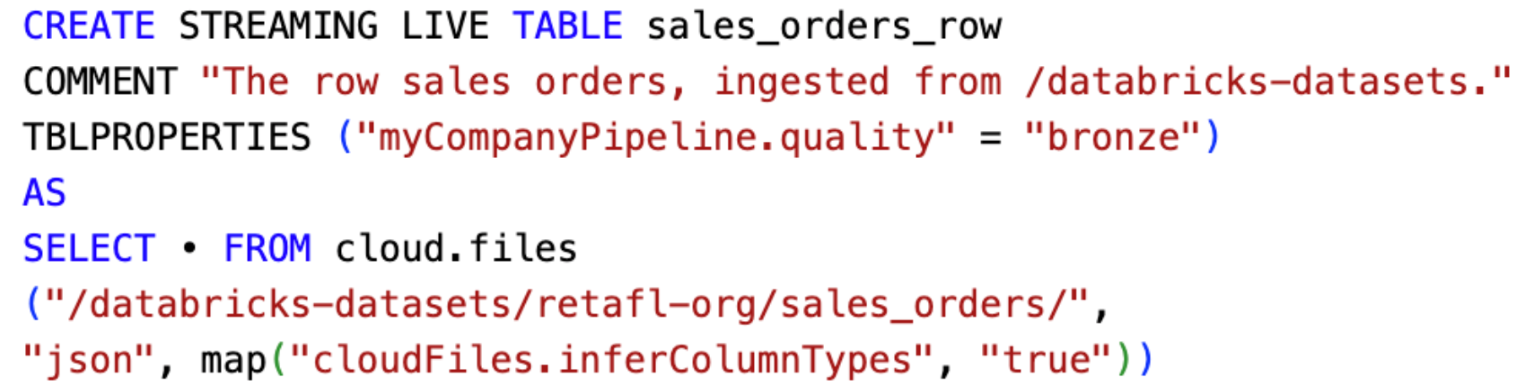
Voici un exemple d’ingestion d’une table Bronze, à partir d’une source de données contenant des fichiers au format JSON :

De plus, il est possible de créer une pipeline d’ingestion streaming :
Cela permet de traiter efficacement et de manière incrémentielle les nouvelles données à mesure qu'elles arrivent et d'interpréter automatiquement le schéma des fichiers entrants (uniquement les fichiers de type CSV, JSON, AVRO, PARQUET). On obtient donc une évolution automatique des schémas, ce qui permet d’éviter toute perte de données.
L’un des plus grands avantages de DLT est l’utilisation des expectations. Ces derniers permettent de définir des contraintes de qualité et ainsi stocker ou supprimer les données qui ne les respectent pas. Vous pouvez définir des expectations avec une ou plusieurs contraintes de qualité dans les pipelines Python en utilisant @expect_all, @expect_all_or_drop et @expect_all_or_fail. Par exemple, pour conserver une donnée invalide :
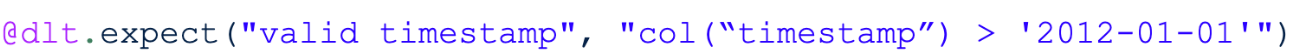
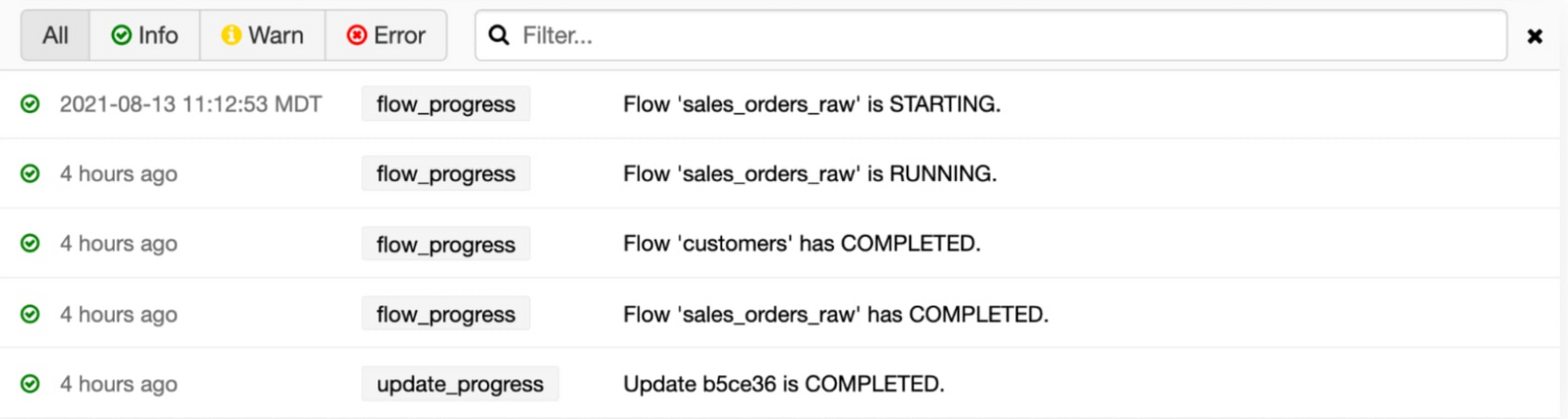
Grâce à cela, il est possible de créer des dashboards afin d’avoir un suivi de qualité des données au sein du pipeline DLT. Les sources de streaming autorisées dans ce processus sont Kafka, Amazon Kinesis, Azure Events Hubs, Google Cloud Pub/Sub. De plus, grâce aux différents logs de pipeline, il nous est possible de suivre son évolution :
Journey to unified governance for your Data and AI assets on Lakehouse
La dernière conférence de la journée à laquelle nous avons assisté était consacrée à l’outil de gouvernance de Databricks, Unity Catalog.
Le Unity Catalog est utilisé pour gérer les utilisateurs et les métadonnées dans un endroit centralisé, mais aussi pour le contrôle centralisé de l’accès aux données. Il permet également l’accès à la lignée de la donnée pour une meilleure traçabilité des traitements appliqués. Avec le Unity Catalog, il est possible de parcourir et d’interroger la donnée de manière sécurisée, en respectant les permissions d’accès des utilisateurs. Au niveau des logs, le Unity Catalog enregistre tous les accès effectués sur la donnée et les différentes actions réalisées. La fonctionnalité Delta Sharing, intégrée nativement au Unity Catalog, permet un partage sécurisé de la donnée.
Il y a trois niveaux de namespace dans le Unity Catalog, en plus du Metastore :
- le catalogue,
- le schéma (base de données),
- la table (externe, managée ou vue).
Hive Metastore est intégré dans Unity Catalog, ainsi un espace de travail Databricks a un Metastore du Unity Catalog qui lui est assigné et est associé à un Metastore Hive. Le Hive Metastore est local à l’espace de travail associé, on ne peut pas y accéder depuis un autre espace de travail. Le Unity Catalog est lui partagé par tous les espaces de travail auxquels il est associé.
Le fonctionnement du Unity Catalog dans le cadre d’une requête utilisateur nous a été détaillé à l’aide d’un exemple sur AWS. Au préalable, il faut qu’un administrateur ait créé le rôle IAM, les identifiants d’accès au service de stockage et défini les permissions d’accès dans le Unity Catalog. Voici les étapes de la vie d’une requête :
- L’utilisateur envoie une requête (SQL, Python, R, Scala) au cluster ou à l’endpoint SQL,
- Le cluster vérifie le namespace, les métadonnées et les permissions avec le Unity Catalog,
- Ce dernier assume un rôle IAM pour le stockage Cloud (par exemple S3),
- Il renvoie une liste de chemins, ou de fichier de données et un token temporaire au cluster,
- Le cluster ingère ou requête la donnée dans les chemins/fichiers de données, grâce au token temporaire
- Le stockage Cloud renvoie les données au cluster
- Le cluster envoie le résultat de la requête à l’utilisateur
Le Unity Catalog peut, dans le même temps, écrire les logs d’audit.
Databricks nous a également présenté les prochaines fonctionnalités qui seront ajoutées au Unity Catalog :
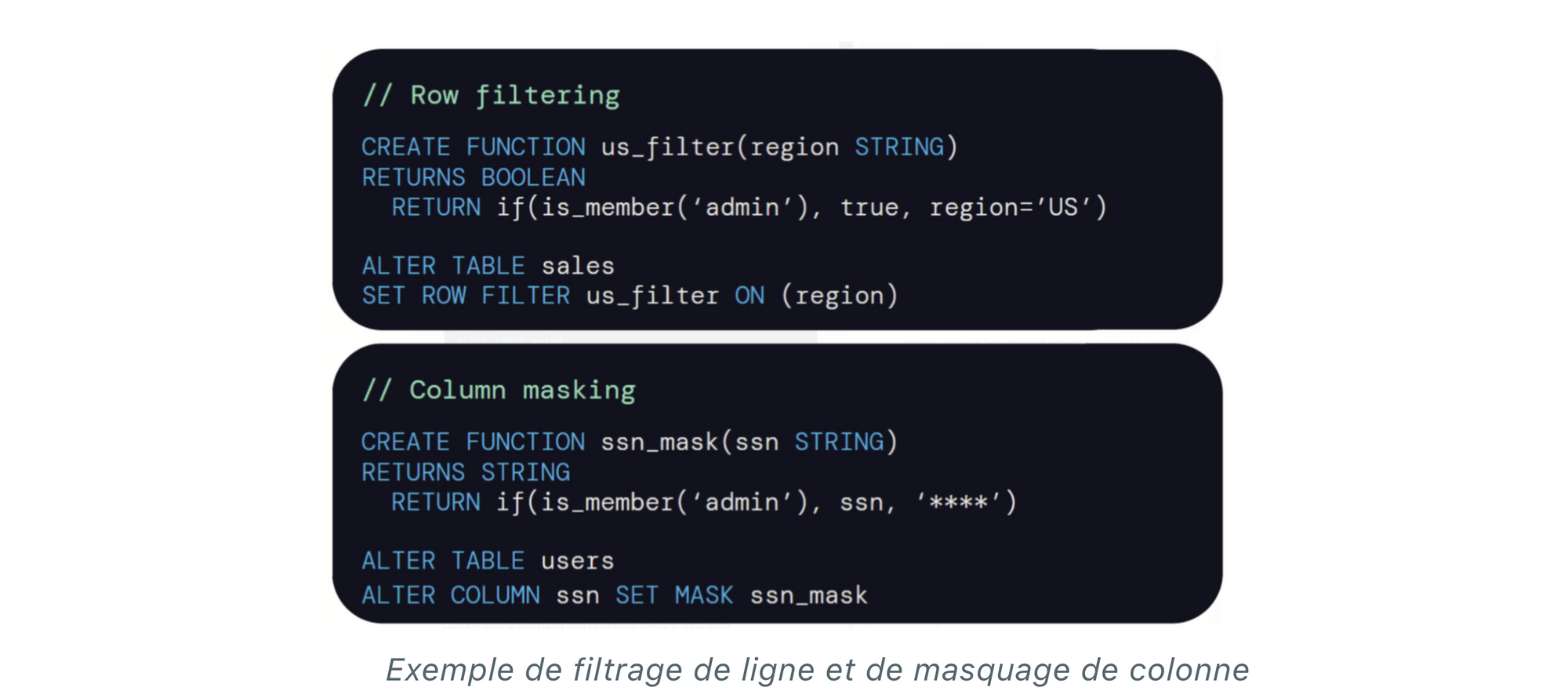
- le contrôle d’accès aux données basé sur des tags
- le filtrage de ligne et le masquage de colonne
- le catalogage et la gouvernance des modèles de Machine Learning
- le partage de données via des marketplace ou des clean room (environnement sécurisé qui permet un accès externe aux données, entre au moins deux entreprises, avec la possibilité de choisir le niveau de visibilité de celles-ci)
Conclusion
Ces conférences nous ont permis d’en apprendre plus sur le concept de Lakehouse et les différents outils développés par Databricks, notamment le moteur Photon et le Unity Catalog. Databricks investit massivement dans ces technologies, il est intéressant de continuer à suivre les diverses évolutions et innovations apportées.
Références
https://www.databricks.com/blog/2022/07/20/databricks-sql-highlights-from-data-ai-summit.html
https://docs.databricks.com/sql/language-manual/sql-ref-information-schema.html
https://www.databricks.com/blog/2021/09/08/new-performance-improvements-in-databricks-sql.html
https://www.databricks.com/discover/pages/getting-started-with-delta-live-tables
https://docs.databricks.com/workflows/delta-live-tables/delta-live-tables-expectations.html
https://docs.databricks.com/workflows/delta-live-tables/delta-live-tables-event-log.html#data-quality
https://www.databricks.com/product/unity-catalog

