

C’est une fin de journée. Et quelle - troisième - journée ! Pas mal d’annonces ont été communiquées à la keynote du matin. Des sessions se sont ouvertes en conséquence et nous nous sommes permis d’aller y faire un tour, histoire de voir ce qu’il en retourne, en plus de ce que nous voulions voir à la base. Mamamia comme on dit au Venetian ! (en vrai, personne ne dit ça là-bas).
Keynote DATA
Écrit par Timothée Aufort, Rémy Olivet et Thomas Thiriet
Présenté par Swami Sivasubramanian, Vice President of AWS Data and Machine Learning
Que de nouveautés encore à cette 3ème Keynote du AWS re:Invent 2022. Nous avons de nouveau sélectionné quelques annonces pour condenser les 2h de conférence auxquelles nous avons assisté :
- Amazon Athena for Apache Spark est GA. Nous pouvons désormais exécuter des workloads Spark en utilisant Jupyter Notebook comme interface pour effectuer le traitement des données sur Athena. Grosse annonce ! Obtenez une session Spark quasi-instantanément , aucune infrastructure à gérer, aucune JVM à démarrer et à attendre, auto-scaling automatique, … Il suffit d’exécuter votre code Spark;

- Amazon DocumentDB Elastic Clusters est GA. Ce service va permettre de faire évoluer de manière élastique une BDD DocumentDB ;
- Amazon SageMaker supporte désormais le ML géospatial. Cette fonctionnalité peut être utilisée pour utiliser les données géospatiales pour, par exemple, gérer les catastrophes naturelles et organiser les secours sur le terrain, l'aménagement urbain, l'agriculture…
- Amazon Redshift Multi-AZ est disponible en preview. Cette fonctionnalité de haute disponibilité repose sur un stream Kinesis qui ingère toutes les requêtes de modification et qui utilise Route 53 pour envoyer les utilisateurs de RedShift vers la base saine la plus proche ;

- Trusted Language Extensions for PostgreSQL est GA. Avec
pg_lte, un SDK open source, les développeurs vont pouvoir développer des extensions avec des langages comme JavaScript, Perl et PL/pgSQL ; - Amazon GuardDuty for RDS est disponible en preview. GuardDuty peut maintenant détecter des connexions suspectes sur une BDD. On devrait, je l’espère, pouvoir envoyer agréger ces résultats dans Security Hub. Il reste encore à voir le pricing ;

- AWS Glue Data Quality est disponible en preview. Cette fonctionnalité permet la génération de règles de qualité de la donnée de façon automatique dans le but de prendre de meilleures décisions business. Ce qu’il fait est explicite - vous définissez des règles sur ce à quoi votre jeu de données doit ressembler (« pas de valeurs nulles », « valeurs entre 0 et 10 », « std inférieur à 3 », ...) et il exécute un job qui le vérifie. DeeQu finalement offert sur un plateau aux clients AWS ? Stay tuned ! ;
- Centralized Access Controls for Redshift Data Sharing est disponible en preview. Cette fonctionnalité va permettre la gestion centralisée des accès à la donnée en utilisant Lake Formation. Le but est d’améliorer la sécurité du partage de données avec des permissions niveau ligne ou colonne ;
- Amazon SageMaker ML governance est une nouvelle fonctionnalité qui permet de gouverner et d’auditer le développement ML end-to-end ;
- Amazon Redshift auto-copy from S3 permet l’ingestion de données de façon continue et automatisée depuis S3 quand de nouveaux fichiers apparaissent sur des buckets. Cette annonce renforce l’adhérence entre S3 et Redshift et c’est bien ! Ce re:Invent, c’est un peu noël pour les utilisateurs de Redshift ;
- Amazon AppFlow supporte plus de 50 nouveaux connecteurs : DataDog, Slack, Jira, S3…
- ...
Voilà encore beaucoup de nouvelles solutions à évaluer, tester, benchmarker pour savoir si elles sont pertinentes chez nos clients.
Amazon GuardDuty RDS Protection
Écrit par Timothée Aufort
Que faire pour protéger une BDD AWS ? Idéalement, il faut éviter d’exposer une instance RDS au monde extérieur. Une instance devrait être exposée seulement en interne d’un VPC (i.e dans des subnets privés) . Il y a de nombreuses autres bonnes pratiques : utiliser des credentials uniques pour chaque serveur applicatif, faire une rotation des credentials régulièrement, …
Que va apporter GuardDuty pour RDS ? GuardDuty pour RDS sera d’abord disponible pour Aurora seulement (et pas pour Aurora Serverless pour le moment). Aurora fournit déjà plusieurs moyens de sécuriser une instance : SSL/TLS, logs d’audit, gestion du cycle de vie des credentials, authentification IAM (n’hésitez pas à consulter l’article d’un ancien collègue qui en parle ici)… GuardDuty va ajouter des moyens d’identifier les tentatives de login suspectes pour mitiger les menaces avant qu’elles n’aboutissent ou ne prennent plus d’ampleur. Il permettra de surveiller ces menaces sur l’ensemble des instances Aurora d’une organisation AWS.

Une nouvelle source de données est ainsi disponible dans GuardDuty : les événements de login Aurora. De nouvelles techniques de ML qui modélisent l’activité des logins RDS a été créée pour détecter des menaces. Les résultats GuardDuty sont enrichis avec du contexte pour répondre plus rapidement à des questions comme : quelle BDD a été accédée ? D’où a-t-elle été accédée ? L’utilisateur a-t-il déjà eu accès à cette BDD ?
De quoi GuardDuty pour RDS va-t-il nous protéger ? Il pourra détecter les tentatives de brute force de passwords, des credentials utilisés différemment de situations habituelles (depuis un PgAdmin par exemple) et des tentatives de scanning de credentials.
Que retenir ? GuardDuty pour RDS ajoute un nouveau type de protection qui sera facile à activer et qui s’intégrera parfaitement avec les autres outils de sécurité d’AWS. Comme il est disponible en preview, il faudra attendre un peu pour avoir des informations sur le pricing de cette nouvelle fonctionnalité. On regrettera que GuardDuty pour RDS ne puisse “que” détecter des menaces de type login, il aurait été intéressant qu’il soit en mesure de détecter des modifications malveillantes de données dans la BDD ou encore des requêtes SQL inhabituelles.
Democratize data with governance: Bring together people, data and tools
Écrit par Rémy Olivet
Data, governance, people, … C’était forcément une conférence qui allait me parler.
Sous ce titre de conférence un peu générique nous avons, forcément, retrouvé le service annoncé hier : Amazon DataZone !
Les principaux challenges rencontrés par nos clients sont assurément l'accessibilité et le partage des données. C’est grâce à une gouvernance bien outillée que ces entreprises arrivent à les résoudre.
DataZone est un service qui permet de partager, découvrir et chercher de la donnée partagée dans une organisation. Il est composé :
- d’une brique “Business catalog“ qui est votre catalogue de données ;
- d’une brique “Data projects” permettant de collaborer autour d’un domaine ;
- d’une brique “Governance and access control” définissant le workflow permettant aux producers de partager leurs données aux consommateurs ;
- d’une brique “Data portal” qui est l’UI permettant à n’importe quel utilisateur (autorisé) à se loger, chercher, accéder aux données
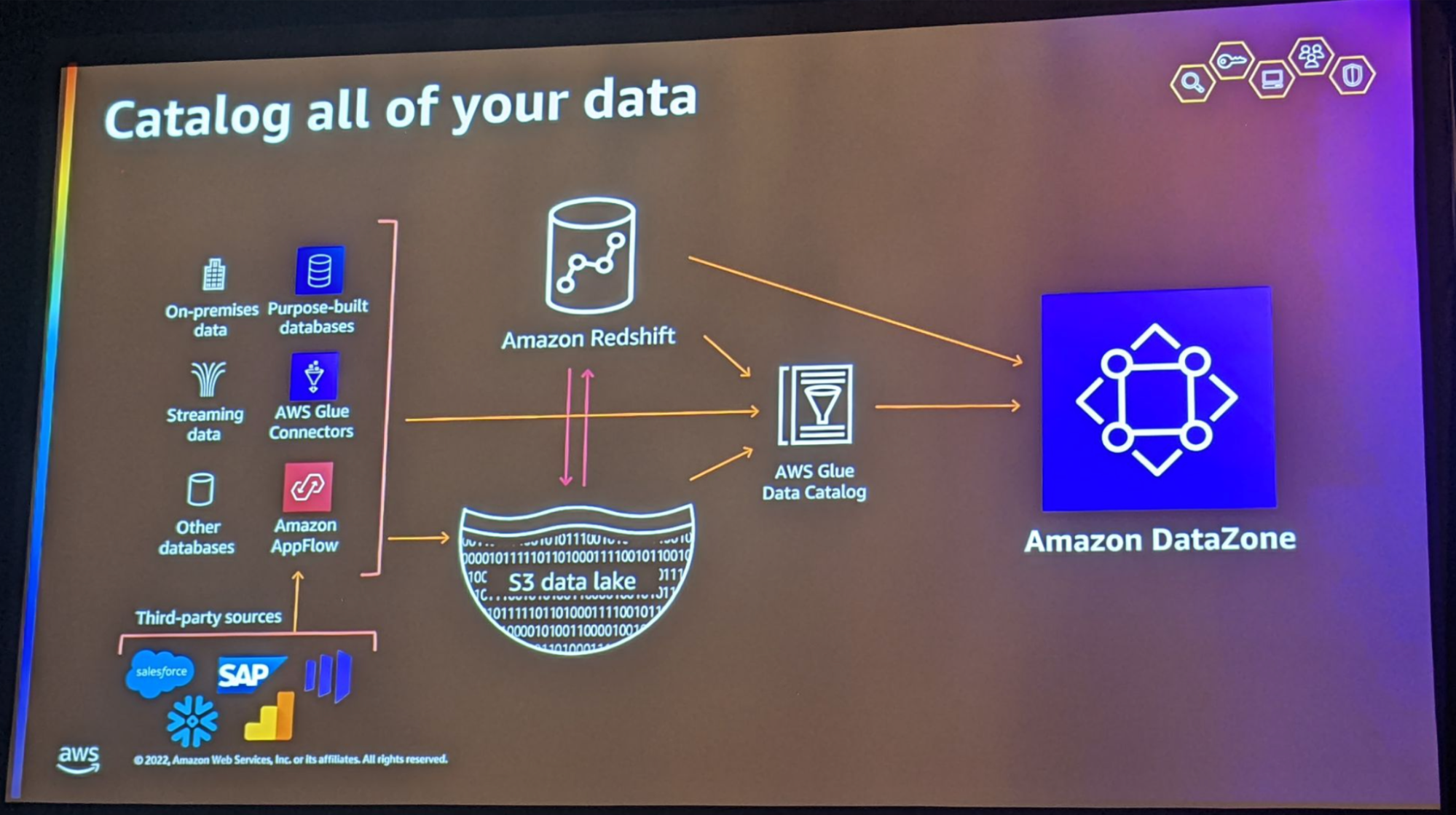
Ce service permet de cataloguer n’importe quelle donnée, puisque les connecteurs AWS Glue et Amazon AppFlow sont de plus en plus nombreux, à condition de la stocker dans Amazon Redshift ou Amazon LakeFormation. En effet, les Redshift tables et LakeFormation tables sont les seules sources de données pouvant être cataloguées pour l’instant. On comprend bien que les usages de cette solution sont uniquement analytiques !
Une fois cataloguées et partagées au sein d’un Data Project, au travers du Data Portal, n’importe quel consommateur autorisé peut requêter les données, via des deep links, par le biais des query editors d’Amazon Redshift ou Amazon Athena. L'utilisateur est fédéré dans le groupe de travail Athena ou le cluster Redshift assignés lors de la création du projet.
Les producteurs de données et les consommateurs de données peuvent être sur différents comptes AWS ou différents warehouses dans un même compte AWS. Amazon Datazone est une réelle plateforme d’échange entre clients Amazon.
Je vous ai glissé le mot “domain” tout à l’heure et ça vous a potentiellement fait réagir … DataZone se positionne comme un véritable facilitateur pour les clients souhaitant s’orienter vers une organisation “data mesh” !
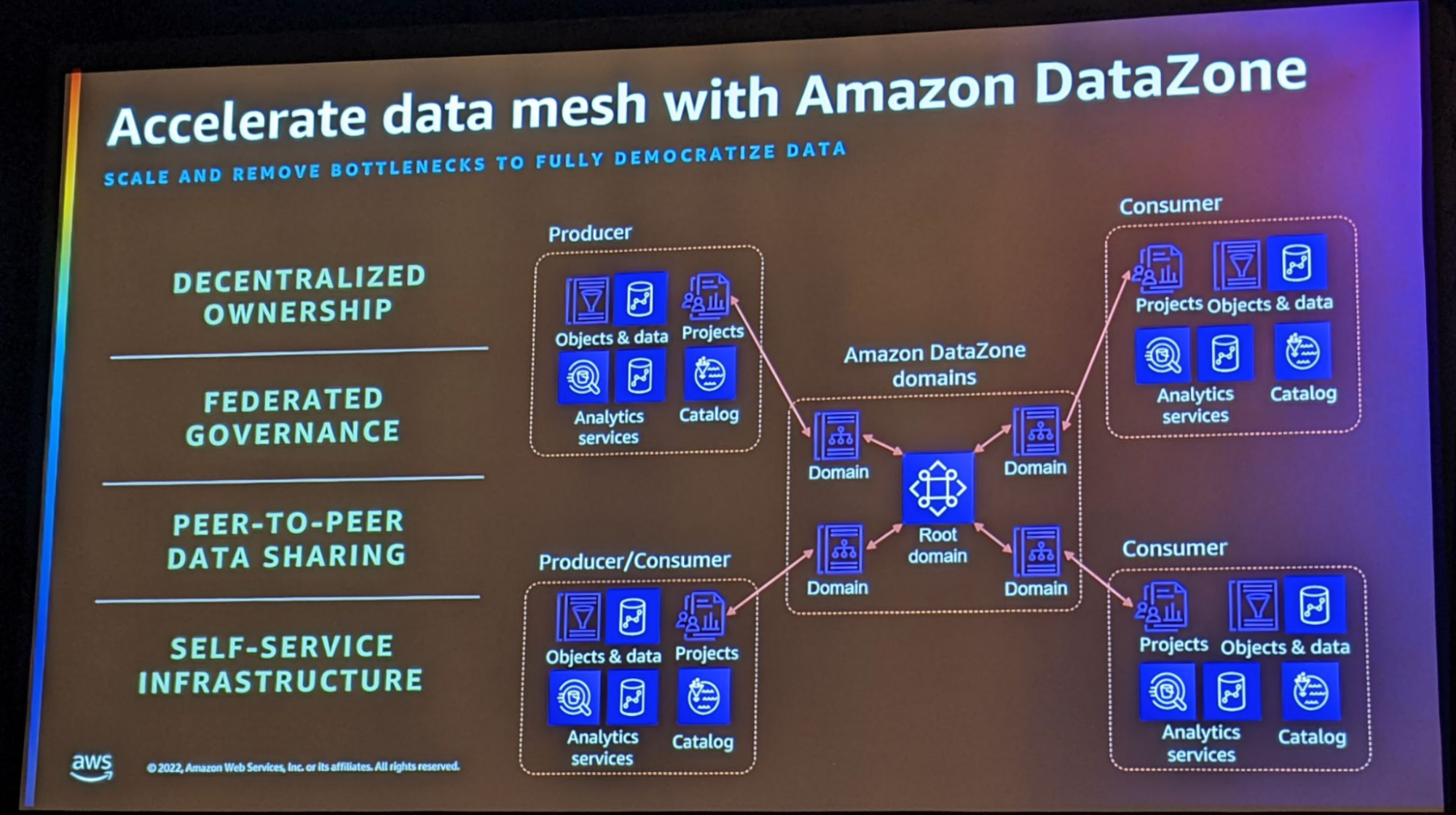
Au sein de DataZone, chaque domaine représente un Data Project. Au niveau projet, chaque domaine contrôle sa donnée, peut la partager à d’autres domaines, peut auditer l’accès à ses données partagées, …
La session Q&A qui a suivi cette conférence à surtout montré que nous en étions qu’à la preview et que la roadmap sur ce service est monstrueuse (on y retrouve : la prise en charge du row level security, unstructured data cataloging, intégration à SageMaker, lineage, data usage tracking pour les datasets partagés, …)
Hâte de commencer à l’utiliser chez nos clients qui ont déjà choisi Redshift comme entrepôt de données ! Mais pour celà, nous attendrons la GA et surtout l’ajout de quelques features supplémentaires qui rendra le projet vraiment mature pour les entreprises (APIs et IaC entre autres).
Building a serverless Apache Kafka data pipeline
Écrit par David DALLAGO
Animé par
- Banjo Obayomi - Senior Developer Advocate at AWS
- Zaiba Jamadar - Solutions Architect at AWS
Troisième jour ici au re:Invent, ça y est, je me repère dans le labyrinthe des casinos, et trouve rapidement les conférences et workshops ! Ce matin, c’est le workshop “Building a serverless Apache Kafka Data pipeline” auquel je participe.
Nous mettons en place l’architecture suivante:
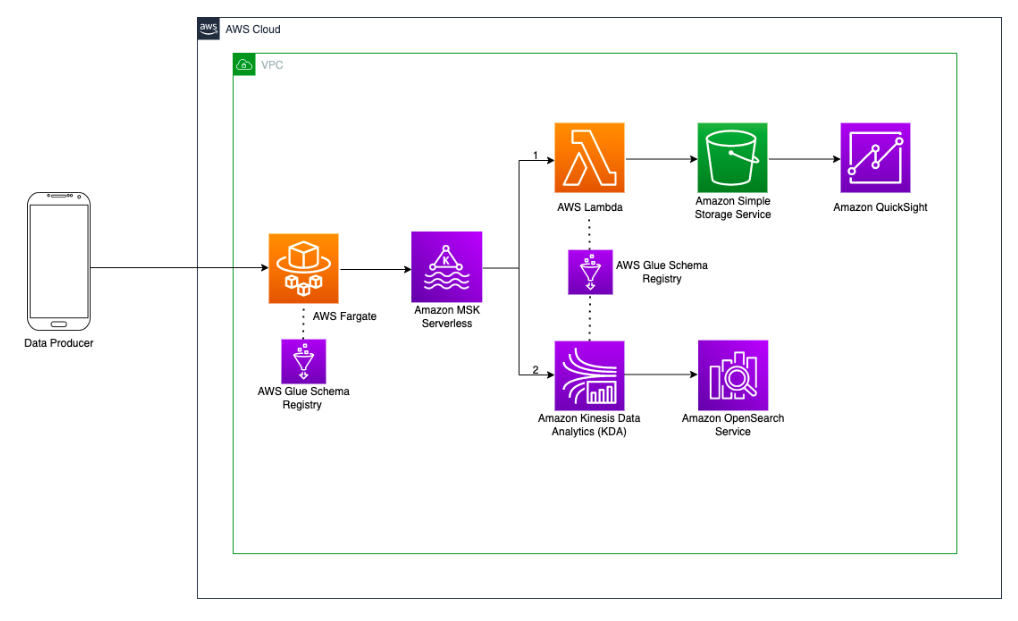
Les services en jeu:
- AWS MSK Serverless: le cluster kafka managé serverless
- AWS EC2 sur Fargate auquel je me connecte pour créer les topics suivants
- Clickstream
- Departments_Agg
- ClickEvents_UserId_Agg_Result
- User_Sessions_Aggregates_With_Order_Checkout
- AWS Lambda : la lambda préparée pour le workshop va consommer le topic clickstream via la définition d’un trigger et pousser les données vers un bucket S3
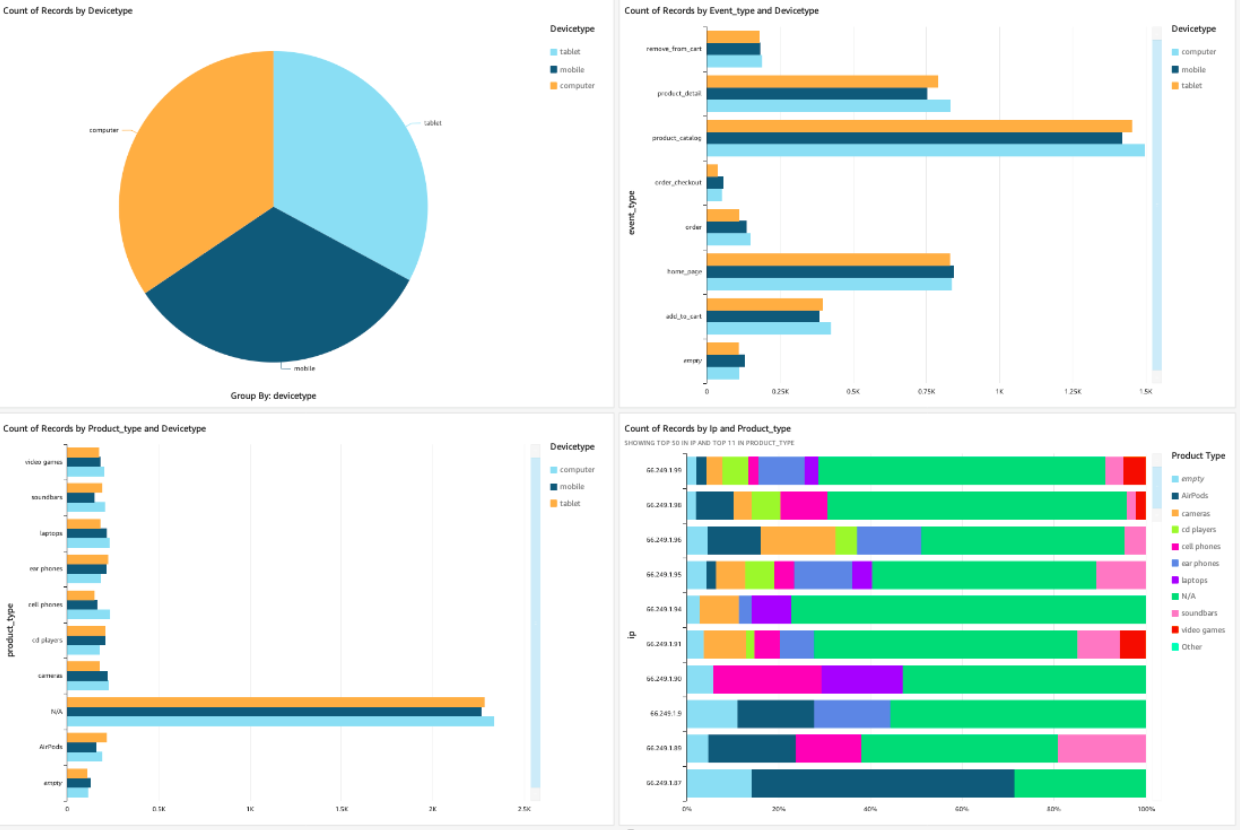
- Amazon QuickSight : on va pouvoir analyser les données et créer le dashboard simple ci-dessous. C’est un service qui peut être utilisé typiquement pour du reporting récurrent sur la semaine, le mois, etc. Je met en place rapidement ce dashboard grâce à ce que j’ai déjà vu hier sur le workshop finops :
- Amazon Kinesis Data Analytics : Ce service va agréger les données du MSK sur une time window et alimenter OpenSearch
- Amazon OpenSearch Service : va nous permettre également d’avoir des dashboards, cette fois-ci, en temps réel
Nous n’arrivons pas à la fin du workshop. En effet, la salle a attendu sans succès la finalisation de la création des applications KDA. J’ai apprécié ce workshop rapide et la mise en œuvre simple et efficace d’un pipeline sur les données kafka que je pourrai conseiller chez nos clients.
Amazon Quicksight: Quelles sont les nouveautés?
Écrit par Imane BENOMAR
AWS a annoncé deux nouveautés sur Amazon Quicksight, le “Forecast” et “Why” dans Quicksight Q ainsi que l'option “Assets as code”.
QuickSight Q: “Forecast” et “Why”
Amazon Quicksight dispose d’un service QuickSight Q qui utilise le machine learning pour permettre aux utilisateurs de faire des analyses de données en posant des questions en langage naturel (NLQ: Natural Language Query). L’utilisateur n’a pas besoin d'être un data analyste ou développeur BI pour utiliser le service, il peut tout simplement poser ses questions dans la barre de recherche Q afin d’obtenir des réponses en visuels :
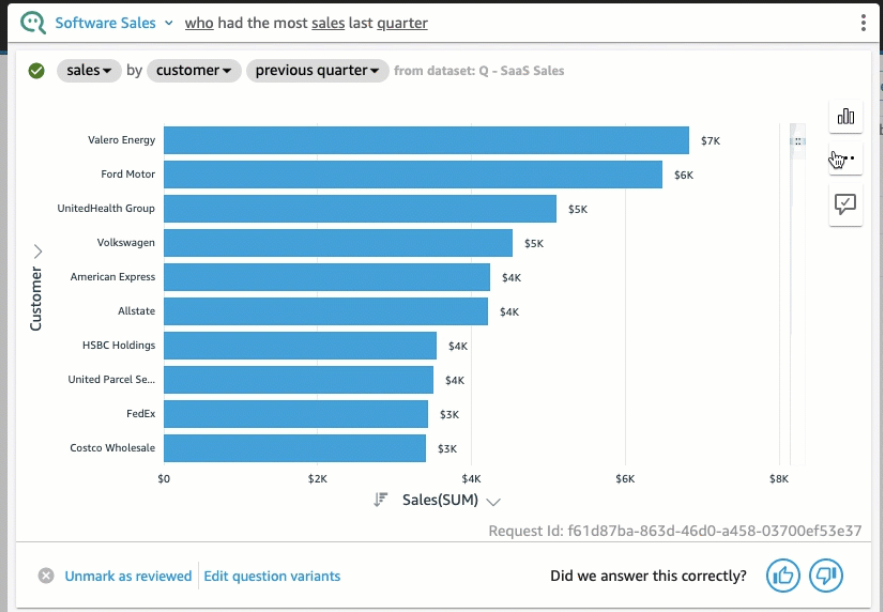
Forecast (Prédiction)
L’une des utilisations phare de l’analyse de données est d'offrir aux décideurs la possibilité d'estimer avec précision ce qui est susceptible de se produire dans une situation donnée, d’anticiper les problèmes et d’optimiser les performances. La possibilité de le faire simplement avec une commande_ forcast ou "show me_ a forecast" constitue une réelle avancée pour ce service.
Exemple: Show me a forecast of sales for EMEA region.
Why (Pourquoi)
Comprendre le “Pourquoi” dans l’analyse de données est très important, pour le faire il faut creuser un peu plus dans son analyse et explorer plusieurs pistes afin de trouver la bonne réponse, Quicksight Q permet maintenant de le faire avec une requête NLQ simple contenant une mesure numérique et une mesure temporelle
Exemple : Why sales drop in 2020.
Assets as code
Quicksight permet désormais de créer et gérer les datasets et les dashboards par code en ajoutant un nouvel ensemble d’APIs Describe:
- DescribeAnalysisDefinition, pour gérer les analyses_
- DescribeTemplateDefinition pour gérer les modèles_
- DescribeDashboardDefinition pour gérer les tableaux de bord._
Les ressources sont définies par des objets Json entièrement modélisés à l’aide de l’AWS SDK:
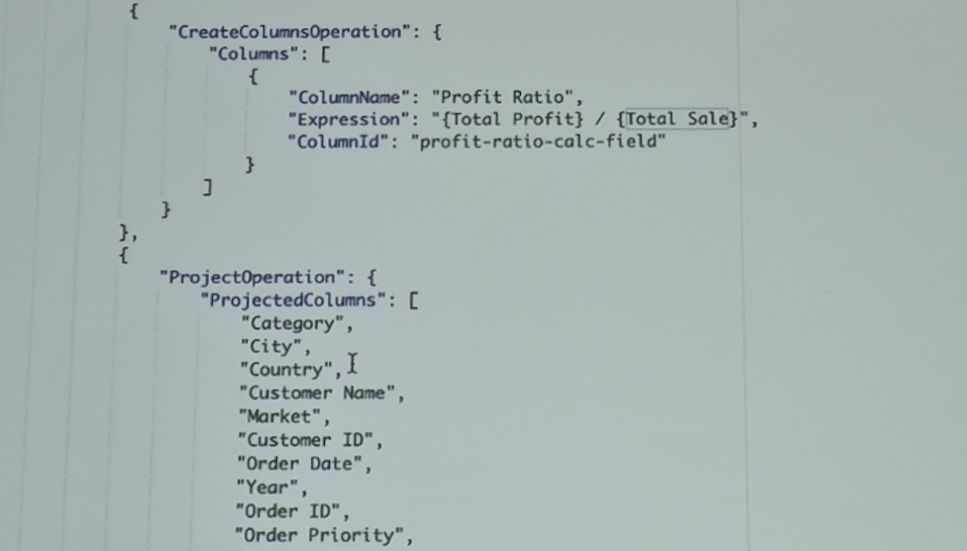
Et pour lancer la création ou modification d’une ressource, il suffit d’exécuter la création avec l’AWS CLI:
aws quicksight create-analysis --generate-cli-skeleton > create-analyse.json
Quicksight évolue dans un bon sens en proposant ces nouvelles fonctionnalités sachant qu'il a déjà des points forts que la majorité de ses concurrents n'ont pas, il est cloud natif, serverless et scale automatiquement.
Monitor and manage data quality in your data lake with AWS Glue
Écrit par Thomas Thiriet
Présenté par Brian Ross (Senior Software Development Manager AWS), Shiv Narayanan (Product Manager AWS) et Sudeep Joseph (VP, Chief Data & Information Architect Travelers)
Après l’avoir annoncé à la keynote, j’ai suivi une conférence plus approfondie sur la nouvelle fonctionnalité d’AWS Glue concernant la “Data Quality”. C’est une conférence sur laquelle j’avais beaucoup d’attentes tellement le sujet est important ! Comme l’ont dit nos speakers : “The quality of your analytics is only as good as the quality of your data”. Autrement dit vos requêtes SQL peuvent être parfaites, si les données sont fausses, les résultats le seront aussi.
Pourtant de nombreuses décisions sont prises, basées sur nos dashboards Analytics.
Quels sont les défis des outils de vérification de la qualité des données ?
- beaucoup de configurations
- open source ou avec des coûts de licences importants
- des process manuels, exemple : recenser toutes les règles métiers autours de la data
- la scalabilité et la performance
- le support de multiples personas
C’est sur ces points qu’a beaucoup travaillé AWS pour proposer la fonctionnalité Data Quality.
Les principales informations sont donc les suivantes, AWS Glue Data Quality :
- est capable d’analyser les données et de faire des recommandations sur les règles que celles-ci doivent respecter. Il s’agit d’une bonne base de travail afin de ne pas avoir à tout écrire manuellement
- est serverless, scalable, performant avec des coûts liés aux temps d'exécution.
- permet de vérifier la qualité des données dans Glue Data Catalog et vos pipelines de données (ETL Glue)
- est entièrement managé par AWS et fonctionne sur la librairie open source DeeQu développée et beaucoup utilisée en interne par Amazon
- possède son propre langage : Data Quality Definition Langage (vous avez un exemple avec l’image ci-dessous)
- permet de créer des règles qui répondent à la grande majorité des besoins : Consistency, Accuracy, Completeness, Integrity
- Et enfin permet d’envoyer des metrics sur S3 et cloudwatch, donnant la possibilité de faire des dashboards ou de créer des alarmes
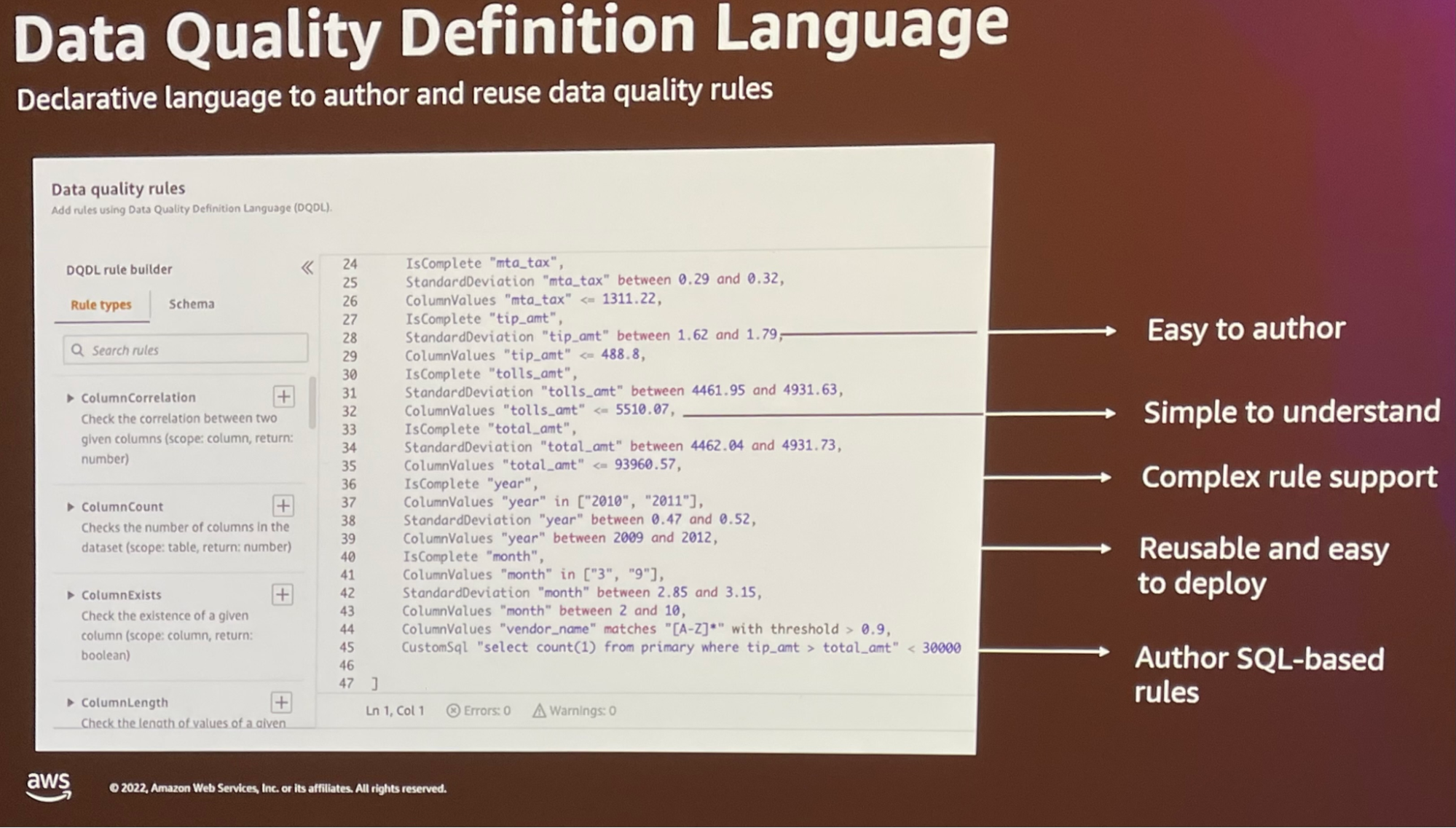
Le pricing :
| AWS Glue Data Catalog | AWS Glue ETL | |
| Get data quality recommendations | $0.44 per DPU Hour | - |
| Evaluate Data Quality | $0.44 per DPU Hour | $0.44 per DPU Hour
$0.29 per FLEX DPU Hour |
Pour conclure, je pense que c’est une solution qui manquait vraiment sur AWS et que nous serons amenés à utiliser pour nos clients afin d’améliorer la qualité de leurs données et de leur Data Lake. De plus, je fus agréablement surpris de voir la bonne intégration de la fonctionnalité dans Glue, celle-ci s’ajoute naturellement dans l’interface et répond à nos attentes en termes d’observabilité avec Cloud Watch. Hâte de tester plus en profondeur, je me pose, en effet, encore pas mal de questions. Est-ce que la solution peut analyser les données de manière incrémentale ? Et est-ce qu’elle peut extraire les données qui ne sont pas correctes ?
A demain pour le dernier numéro de cette belle aventure !
