

Il y a fort longtemps, la donnée était une ressource rare, convoitée par toute personne avide de savoir.
Aujourd’hui, grâce au développement du numérique, et la démocratisation d’Internet, les temps se sont apaisés, la donnée est maintenant abondante et riche, connectée, et organisée.
C’était du moins le rêve des inventeurs du Web Sémantique, cependant l’histoire a choisi une autre voie, la réalité de là où nous en sommes aujourd’hui est bien décevante.
Bien que l’acceptation d’Internet par les foules a réussi à rendre la donnée omniprésente, nous avons échoué à la rendre accessible de manière simple et structurée.
De précieuses données sont ainsi étouffées dans une multitude de formats et de sources hétérogènes, perdues sur des articles de blog, égarées sur divers sites web.
C’est à ce moment qu’est née la quête du Scraping, créer des programmes afin de pouvoir redonner du sens à ces données.
Avec le temps, bien des méthodes se sont développées, et c’est l’objectif de cet article que de vous les présenter, afin de vous aider à faire les bon choix lorsque l’heure s’y prêtera.
Qu’est ce que le scraping ?
Le Scraping est un procédé permettant d’accumuler et de structurer les données d’un site web.
Cela consiste en une série d’opérations effectuées sur un site web pour en extraire des données.
Nous allons voir dans cet article, le fonctionnement de base du Scraping, les alternatives, ainsi que des techniques pour vous permettre de résoudre les problèmes sur lesquels vous pourriez tomber.
Préparation
Cet article contient des exemples de code en Python, populaire pour le scraping.
Il existe également des équivalents à chacune de ces bibliothèques en JS, langage aussi très utilisé pour le Scraping.
- Requests - Permet d’effectuer des requêtes HTTP
- Beautiful Soup - Permet de parser simplement des documents XML et HTML par extension
- lxml - Autre parser pour document XML
- websocket-client - Bibliothèque pour lire les websockets
- Sélénium - Permet de contrôler un navigateur avec du code
- Insomnia - Permet de facilement travailler avec des requêtes
Choses à savoir
Dans cet article nous parlons et effectuons des requêtes HTTP(S), il paraît important de faire un rappel sur leur fonctionnement.
Une requête est constituée d’un URL, d’une entête, de paramètres divers, ainsi que d’une méthode (GET, POST, PUT, ...)
Une fois la requête effectuée, le serveur va renvoyer une réponse qui va dépendre de la route et des paramètres précisés.
Un outil basique pour effectuer une requête est cURL
Ici on utilise httpbin.org qui permet de faire des tests pour l’envoi des paramètres.

Il existe des outils graphiques permettant de faire la même chose, comme Insomnia, Postman, Hoppscotch et autres.
Ils permettent notamment de générer du code dans un langage choisi à partir d’une requête. (Le site https://curlconverter.com/ fait la même chose si vous préférez ne pas installer un nouvel outil)
Avant de commencer
Avant toute chose, il est important de se poser les bonnes questions.
En effet, le scraping est souvent une tâche fastidieuse et longue à mettre en place pour des projets complexes.
Il existe dans la plupart des cas une solution alternative plus efficace et qui vous fera gagner du temps.
“L’art du scrap, c’est de réussir sans combattre.”
Sun Tzu, possiblement
Je vais détailler ici ces différentes solutions (accompagnées d’un ou plusieurs exemples), leurs avantages, ainsi que leurs inconvénients.
Les solutions sont présentées dans l'ordre de priorités dans lequel elles doivent être, selon moi, étudiées.
Cet article a un Notebook compagnon pour vous permettre d'exécuter le code et d'expérimenter vous même directement depuis votre navigateur.
Lien du notebook :
Pour l’utiliser de votre côté, faites Fichier > Enregistrer une Copie sur Drive
Méthode 1 - La route dorée
De nos jours, énormément de sites internet, surtout les plus gros, disposent d'API publiques permettant d'accéder directement aux données voulues via une simple requête HTTP(S).
Si l'information que vous recherchez est disponible via cet API c'est la solution la plus rapide à implémenter, notamment à l’aide d’une documentation complète sur les routes et les paramètres.
De plus cette implémentation sera en général plus durable dans le temps, les routes ayant peu de chance de changer.
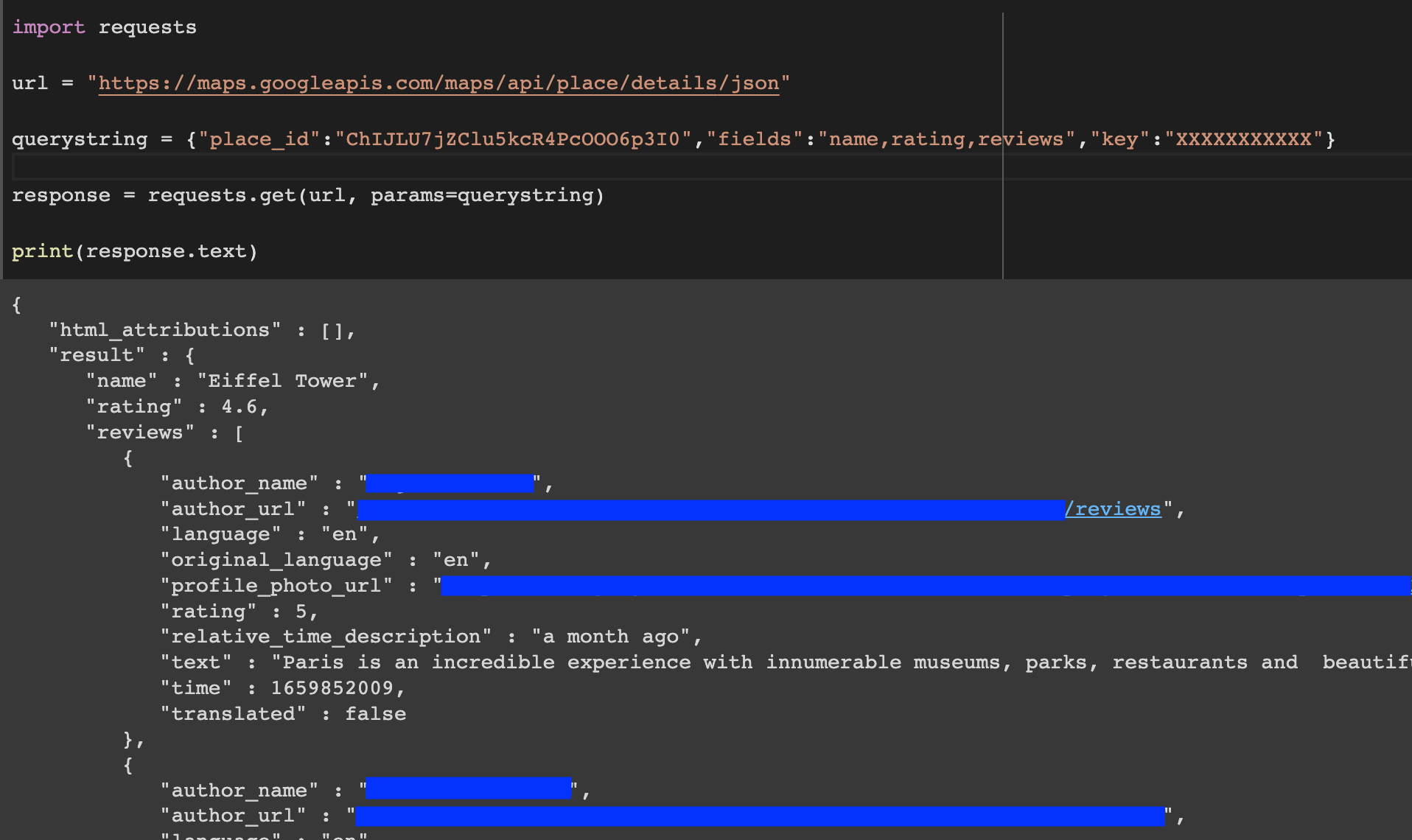
Prenons l'API de Google Maps par exemple :
Supposons que nous voulions récupérer les reviews sur la Tour Eiffel
(Son identifiant Google Maps est: ChIJLU7jZClu5kcR4PcOOO6p3I0)
Il y a une documentation qui nous indique la route et les paramètres à utiliser :
https://developers.google.com/maps/documentation/places/web-service/details
La route est donc celle ci :
https://maps.googleapis.com/maps/api/place/details/json
On peut préciser des paramètres tels que “fields” qui indiquent les champs que l’on veut récupérer.
Sur l’image ci-dessous les paramètres sont dans la variable “querystring”.
En plus de ces champs on doit s’identifier avec une clé API que l’on obtient depuis Google Cloud Platform (GCP) dans notre cas.
Pour en savoir plus sur comment créer une clé dans GCP :
https://developers.google.com/maps/documentation/android-sdk/get-api-key?hl=fr
En seulement quelques lignes et le lancement de notre requête, les informations nous sont disponibles et présentées dans un format JSON.
L'inconvénient évident de ces API est qu'elle demandent quasiment toujours une authentification, cette authentification va donc enregistrer l'utilisation de l'API et en fonction des sites webs, des quotas peuvent exister.
Aussi certains sites font payer l'accès à leur API, ce qui peut engendrer des coûts plus ou moins lourds en fonction de votre utilisation.
Cout:
Simplicité:
Pérennité:
Cette méthode est à prioriser lorsqu'elle est possible.
Dans le cas où le site Web ne propose pas d'API, d'autres méthodes sont à essayer.
Méthode 2 - La route argentée
Le site dont vous voulez extraire les données ne propose pas d’API ?
Il y a peut être encore une solution pour vous simplifier la tâche.
“Connais ton ennemi et connais-toi toi-même eussiez-vous cent guerres à soutenir, cent fois vous serez victorieux”
Sun Tzu
C’est pourquoi une analyse du site web va être nécessaire.
Les données affichées viennent forcément de quelque part, et pour beaucoup de sites internet modernes elles viennent de requêtes faites au backend.
Plus précisément il va falloir analyser les requêtes XHR/Ajax effectuées par le site internet.
Pour cela, nous devons ouvrir les outils développeur,
Il existe plusieurs méthodes pour ouvrir ce menu en fonction du navigateur ou de l’OS, la méthode que je préfère est simplement un clic droit n’importe où sur la page, et cliquer sur “inspecter”.
Aller ensuite dans l’onglet Network/Réseau.
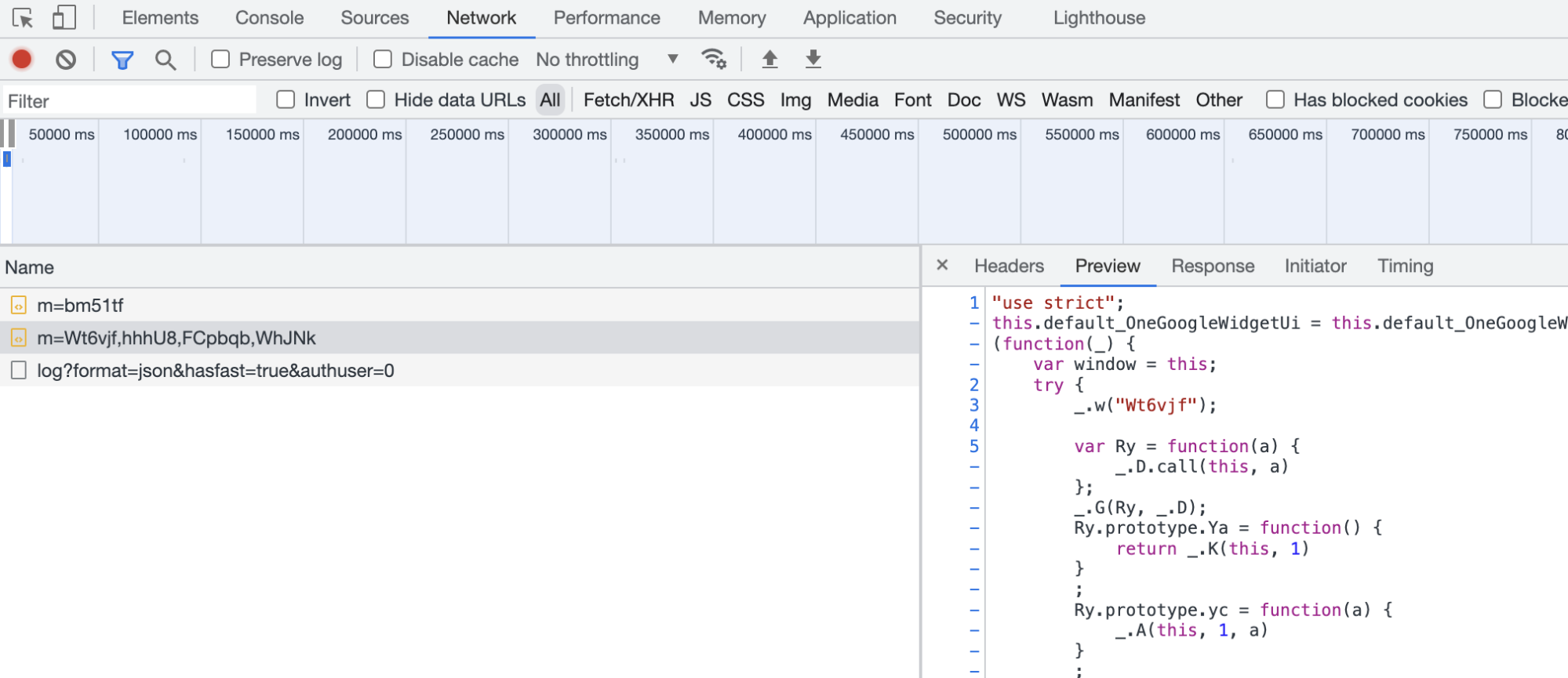
Dans la partie gauche se trouve la liste des requêtes effectuées par le site web (fichiers JS, images, etc..)
En cliquant sur une de ces requêtes, on peut observer le détail de celle-ci à droite, notamment la réponse dans l’onglet “Réponse/Response” (Je préfères utiliser l’onglet Preview qui affiche une version plus lisible des réponses, notamment des JSON)
En faisant clic droit, copier en tant que cURL on peut copier l'entièreté de la requête afin de la rejouer ailleurs.
Grâce à Insomnia, un simple copier-coller dans la barre d’url va automatiquement convertir la requête cURL et remplir les bons champs.
Pour exécuter la requête il faut ensuite cliquer sur le bouton “Send”

Évidemment ici, il n’y a aucune information intéressante, il s’agit uniquement d’un exemple.
Si jamais l’outil est rempli de requêtes diverses, il peut être intéressant de cliquer sur l'icône poubelle/clear en haut à gauche de l’outil développeur pour y voir plus clair.
Nous allons donc entrer les informations normalement dans le site internet et ensuite lancer la recherche, ce qui va avoir pour effet d’effectuer une requête sur le backend.
Plus généralement, il faut activer la fonctionnalité qui va récupérer les résultats souhaités (Par exemple, cliquer sur le bouton suivant s'il s’agit d’une page ecommerce)
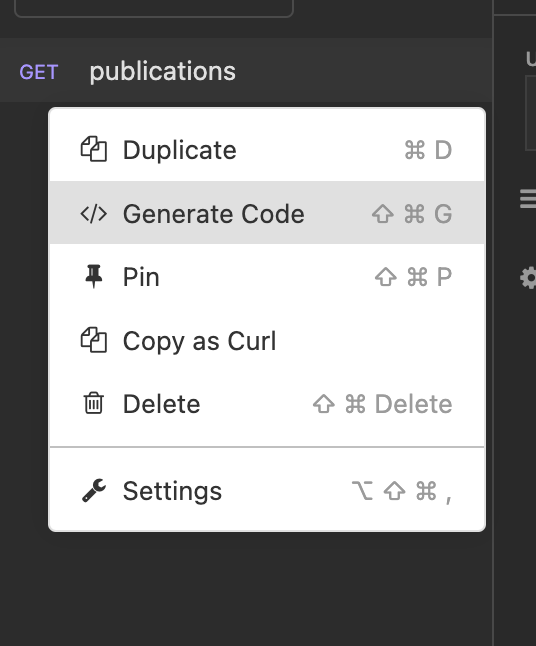
Dans notre cas, nous allons récupérer les publications sur le site d’Ippon.
On va rapidement voir énormément de requêtes s’effectuer dans l’onglet Network/Réseau.

C’est ici qu'une analyse de ces requêtes est primordiale, pour faciliter cette tâche il est possible de filtrer les requêtes par XHR(XMLHttpRequest), ce qui rend cela beaucoup plus lisible.
L’idée est de cliquer sur les différentes requêtes affichées et essayer si la réponse contient les informations recherchées.
Dans notre cas beaucoup de requêtes s’effectuent, en regardant dans l’onglet réponse on va pouvoir voir quelles informations sont récupérées par cette requête.
Il va falloir trouver celle qui contient les informations que nous cherchons, parfois cela est assez simple, parfois il va falloir y passer un peu plus de temps.

Une fois la bonne requête trouvée, il suffit de faire un clic droit sur la requête et de copier en tant que cURL, pour être utilisé par la suite.
(Cela peut varier en fonction du navigateur utilisé, sous Firefox par exemple il faut faire "Copier la valeur" > "Copier comme cURL")

Une fois copiée, on peut la coller dans Insomnia pour tester que tout fonctionne correctement (Coller la requête dans la barre URL d’Insomnia, et appuyer sur SEND)
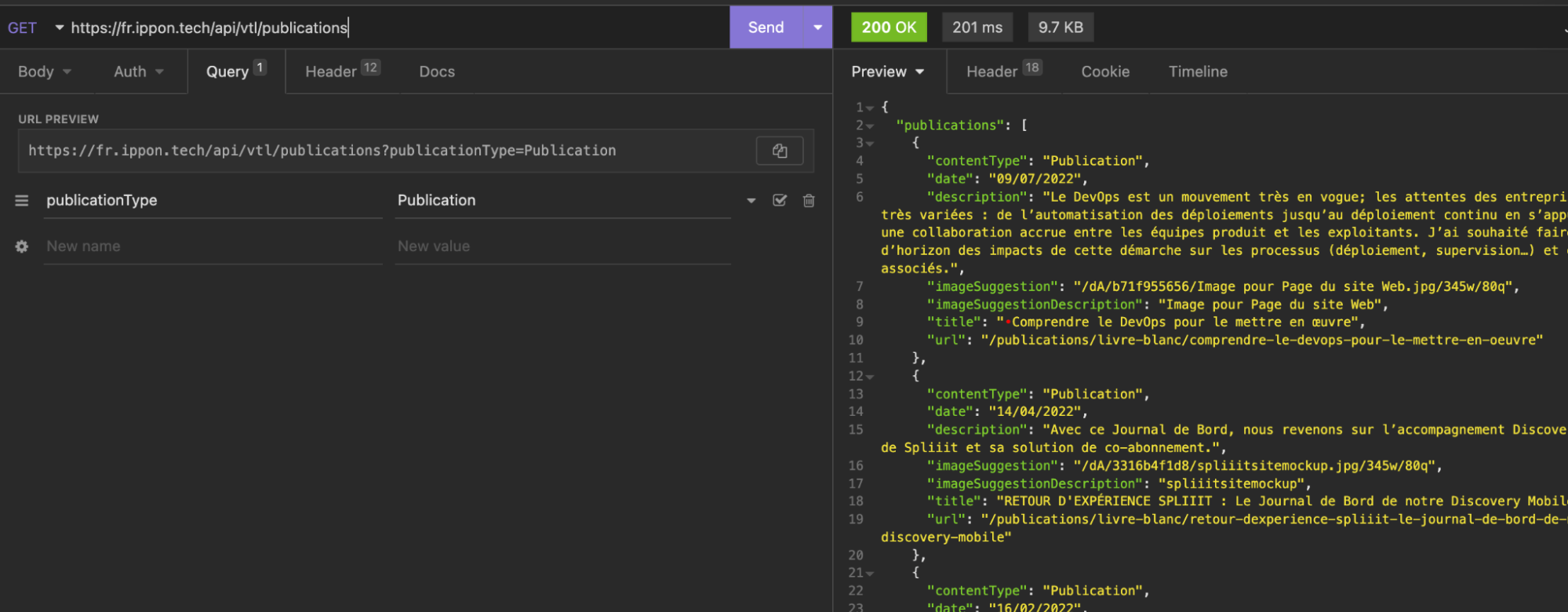
On peut maintenant exporter cette requête dans notre langage de programmation de destination.
Dans le cadre de cet article ce sera Python avec Requests :
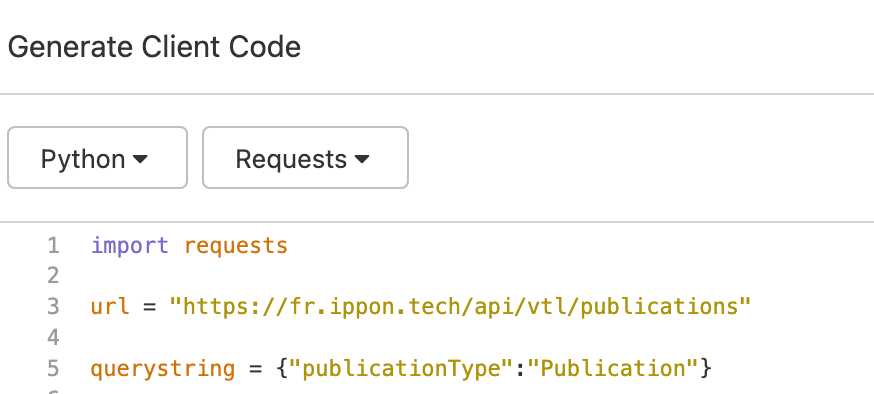
Dans notre cas le code généré ressemble plus ou moins à ça :
(J’ai enlevé les cookies et autres headers pour rendre la lecture plus facile.De plus, la bibliothèque json a été ajoutée pour convertir la réponse en un format json utilisable facilement)

On entre maintenant dans la partie de découverte de l’API, contrairement à la première méthode il n’y a pas de documentation, ce qui laisse place à l’expérimentation.
Dans notre cas cet API est très simple, avec un seul paramètre: “PublicationType”
Après expérimentation,le résultat change si on change la valeur de “Publications” à “Articles”

Souvent, les paramètres auront des noms assez simples à déterminer, si ce n’est pas le cas, il est important d’essayer de relier les données dans la requête à celle que nous avons fourni au formulaire auparavant.
Un cas souvent présent sur beaucoup de sites web est la pagination.
Elle peut être simplement basée sur un numéro avec un paramètre indiquant “page”:”1” par exemple, ou bien avec un token dans le json indiquant “next”:“......”, qui demandera un code adapté.
C’est pourquoi je conseille toujours d’encapsuler les requêtes dans des fonctions une fois que les paramètres ont été compris.

Cette méthode est quasiment équivalente à la méthode 1, à la seule différence près qu’il faut trouver et comprendre soit même les différents API.
Il est à noter que parfois un token ou un cookie sont nécessaires pour faire ces requêtes, sans quoi vous serez bloqués, c’est pourquoi cette méthode peut être utilisée en combinaison avec d’autres méthodes que l’on verra par la suite qui vont nous permettre de récupérer un cookie ou token valide.
Cout:
Simplicité:
Pérennité:
Méthode 3 - La route de bronze
La route de bronze est une des routes les plus étranges, l’idée ici est d’utiliser des sources de données parfois oubliées telles que les flux RSS, ou encore des méthodes peu classiques telles que les websockets.
Cette méthode touche beaucoup moins de sites, mais peut faire gagner un temps précieux quand ces sources de données sont disponibles.
Les flux RSS
Si les données que vous tentez de récupérer sont “de surfaces”, c’est à dire par exemple de simples titres, ou descriptions, ou encore des liens, les flux RSS peuvent être une des solutions les plus simple, même plus simple que la méthode 1 ou 2 dans certains cas.
Les flux RSS ont tendance à être très utiles pour tout ce qui ressemble de près ou de loin à un blog.
Attention: Les données des feeds RSS ne sont (en général) pas un historique complet de tous les “articles” du site en question, le nombre de données affichées va dépendre du site, cela reste cependant un moyen tous les x jours par exemple de regarder si un nouvel élément est présent et si c’est le cas l’enregistrer de notre côté pour construire nous même l’historique.
Supposons que nous devions récupérer une liste des vidéos de la chaîne Youtube Ippon: https://www.youtube.com/c/ippontechtv/videos
Si on ouvre le code source de la page, et que l’on cherche “rss”, on se retrouve ici :

https://www.youtube.com/feeds/videos.xml?channel_id=UCXvQBjBXq4geZbyXVtZvQYg
Les flux RSS étant des fichiers au format XML, un exemple très simple de lecture de ce flux est celui ci :

Les Websockets
Il peut arriver que vous deviez récupérer des données en temps réel sur certains sites internet, il est fort probable que ce genre de données soit transféré par des WebSockets, et il est possible de directement interagir avec celles-ci.
Prenons l’exemple de Binance, un site internet qui propose des services liés aux crypto-monnaies.
Sur cette page : www.binance.com/fr/trade/ETH_EUR
On peut voir l’évolution de l’ETH (Ethereum) en EUR(Euro), ces données de par leur valeur monétaire se doivent d’être le plus à jour possible et utilisent donc les WebSockets.
Toujours dans l’onglet “Network” (en s’aidant du filtre WS, pour n’afficher que les Websockets) on peut observer leur contenu.
(Un rechargement de la page une fois l’onglet network ouvert est nécessaire)

Ici j’ai rajouté un filtre “etheur”, car la websocket transmet aussi d’autres informations non essentielle pour nous, je limite donc ici les messages à ceux en rapport au ratio ETH-EUR
Pour récupérer ces données via du code, il va falloir récupérer l’endpoint en faisant clic droit et en copiant l’adresse du lien.
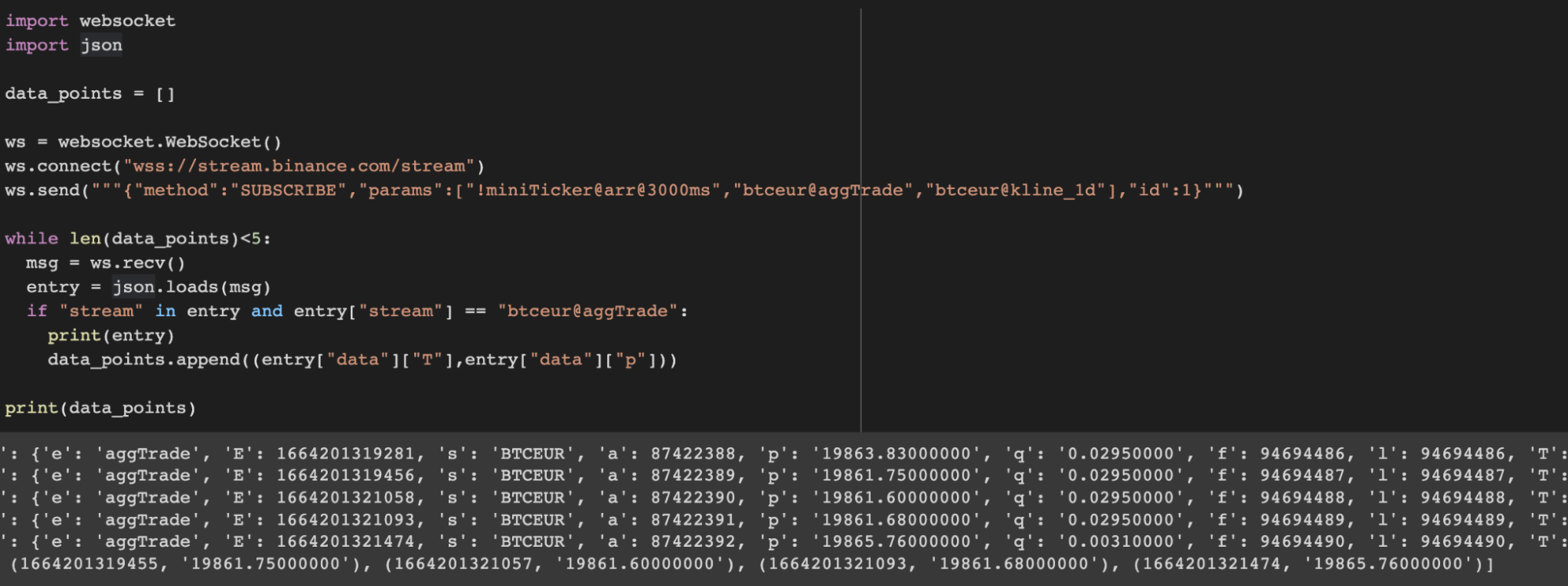
La websocket ici est : wss://stream.binance.com/stream
La bibliothèque que l’on va utiliser ici est :
https://pypi.org/project/websocket-client/ (pip install websocket-client)
Ici l’idée est que l’on doit commencer l’échange en envoyant un message, il suffit pour ça de copier le message envoyé que l’on voit sur l’image précédente.
Une fois le message envoyé, on pourra récupérer les informations.
Et voici un exemple qui va lire 5 data points :
La méthode 3 couvre quelques exemples de sources de données alternatives qui peuvent exister en plus (ou seules) des sources classiques de type XHR.
(Si jamais l'API de Binance vous intéresse, il y a une documentation complète sur celle-ci ici)
Ces sources ne sont évidemment pas limitées à celles présentées ici, l’idée est de vérifier si les informations recherchées ne sont pas accessibles d’une autre manière et d’explorer les possibilités. Par exemple dans certains cas, une simple sitemap peut contenir les informations recherchées.
Cout:
Simplicité:
Pérennité:
Méthode 4 - La route cuivrée
La route en cuivre traite du scraping dit 'classique', qui consiste globalement à récupérer le contenu d'une page au format HTML et extraire des informations ciblées à l'aide de sélecteurs (CSS, Xpath, ou bien via du code avec un parser)
Pour beaucoup c'est la première méthode qu'ils appliquent et pourtant il s'agit d'une des méthode les moins efficaces.
Un des plus gros défauts de cette méthode est que le code ne fonctionnera que tant que la structure de la page restera inchangée.
Cette méthode est aussi beaucoup plus lourde car elle charge des données qui ne nous servent pas, ce qui a aussi pour effet de ralentir le processus de scraping.
Pour notre exemple, nous allons simplement récupérer les titres et le temps de lecture des articles data sur le blog Ippon. (https://blog.ippon.fr/tag/data/)
En l'occurrence la page est générée côté serveur, donc pas besoin d'exécuter du JavaScript.
On peut regarder avec l'inspecteur d’élément l’élément HTML qui contient les informations que nous cherchons.

Chaque article est représenté par un div de classe “table-card”
Ensuite, on peut récupérer la balise h1 de classe “card-title” pour le titre, et la balise p de classe “eta” pour le temps de lecture.
Je présente ici deux manières de parser du HTML, une avec BeautifulSoup, et l’autre à l’aide de XPath, pour la simplicité de lecture je ne peux que recommander BeautifulSoup.
XPath a cependant une plus grande expressivité et peut être extrêmement pratique pour des tâches complexes.
Si ces deux façons vous ennuient et que vous souhaitez rajouter du piment à votre vie, il est possible de parser de l’HTML à la Cthulhu avec des expressions régulières:
https://blog.codinghorror.com/parsing-html-the-cthulhu-way/
(Evidemment il s’agit bien d’humour, comme l’indique l’article, sauf dans des cas extrêmement précis, il est en général une mauvaise idée de parser un document HTML avec des expressions régulières)
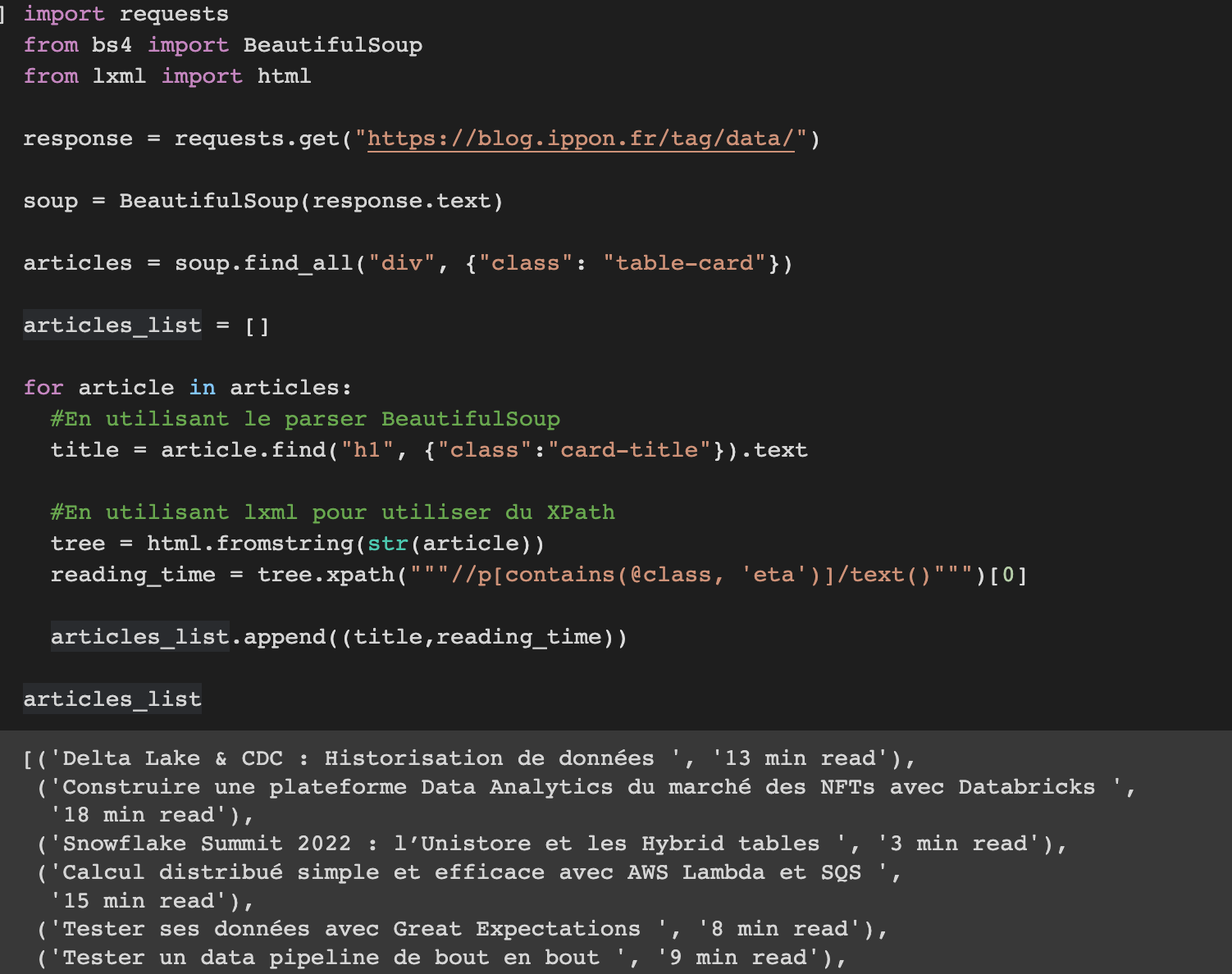
Dans cet exemple l’analyse est faite directement après la récupération de la page HTML, sur un projet plus conséquent il est presque vital de découpler le scraping du parsing.
Pour cela on va simplement sauvegarder la page HTML dans un fichier pour être traité plus tard. Cela évite de requêter à chaque fois que l’on modifie le parsing.
On économise donc du temps en ne faisant pas de requêtes inutiles et on évite en même temps de surcharger le site web pour du contenu que nous avons déjà.
Le scraping classique est assez simple dans son concept, et très facile à réaliser.
À cela on peut ajouter que cette méthode ne fonctionne que si le contenu que l'on cherche à extraire est généré côté serveur (à la PHP), ce qui a tendance à de moins en moins marcher car les sites internet de nos jours fonctionnent pour la plupart via des requêtes XHR,et le contenu est requêté et créé à la volée sur la page.
A noter : requests_html permet dans une certaine mesure d'exécuter du JavaScript, ce qui pourrait être plus simple à intégrer que Selenium ou autre navigateur headless
https://requests.readthedocs.io/projects/requests-html/en/latest/#javascript-support
Si jamais le contenu est généré par du JavaScript il est nécessaire d'utiliser un outil permettant d'exécuter ce JavaScript.
Cet outil n'est d'autre qu'un navigateur, plus précisément un 'Headless browser'.
L’idée est simple, utiliser un navigateur classique mais en arrière plan, et à ça il faut rajouter la possibilité de contrôler le navigateur avec du code.
Selenium est un outil permettant de faire exactement cela, on peut également choisir son driver (Chrome, Chromium, Firefox, etc).
Pour l’installer : https://selenium-python.readthedocs.io/installation.html
Des outils similaires existent également (tq.: Puppeteer ou Playwright, ou même Helium qui tend à rendre l’utilisation de Sélénium plus simple)
Dans cet article nous parlerons principalement de Sélénium de part son ancienneté et sa communauté.
Évidemment cette méthode est beaucoup plus lourde que toutes les autres que nous voyons ici.
Mais la méthodologie finale est la même, on va charger la page web et ensuite la parser, la différence ici est que le JavaScript aura pu s'exécuter.
Pour comparaison ici on va récupérer la liste des offres d’emploi sur la page https://fr.ippon.tech/carrieres/
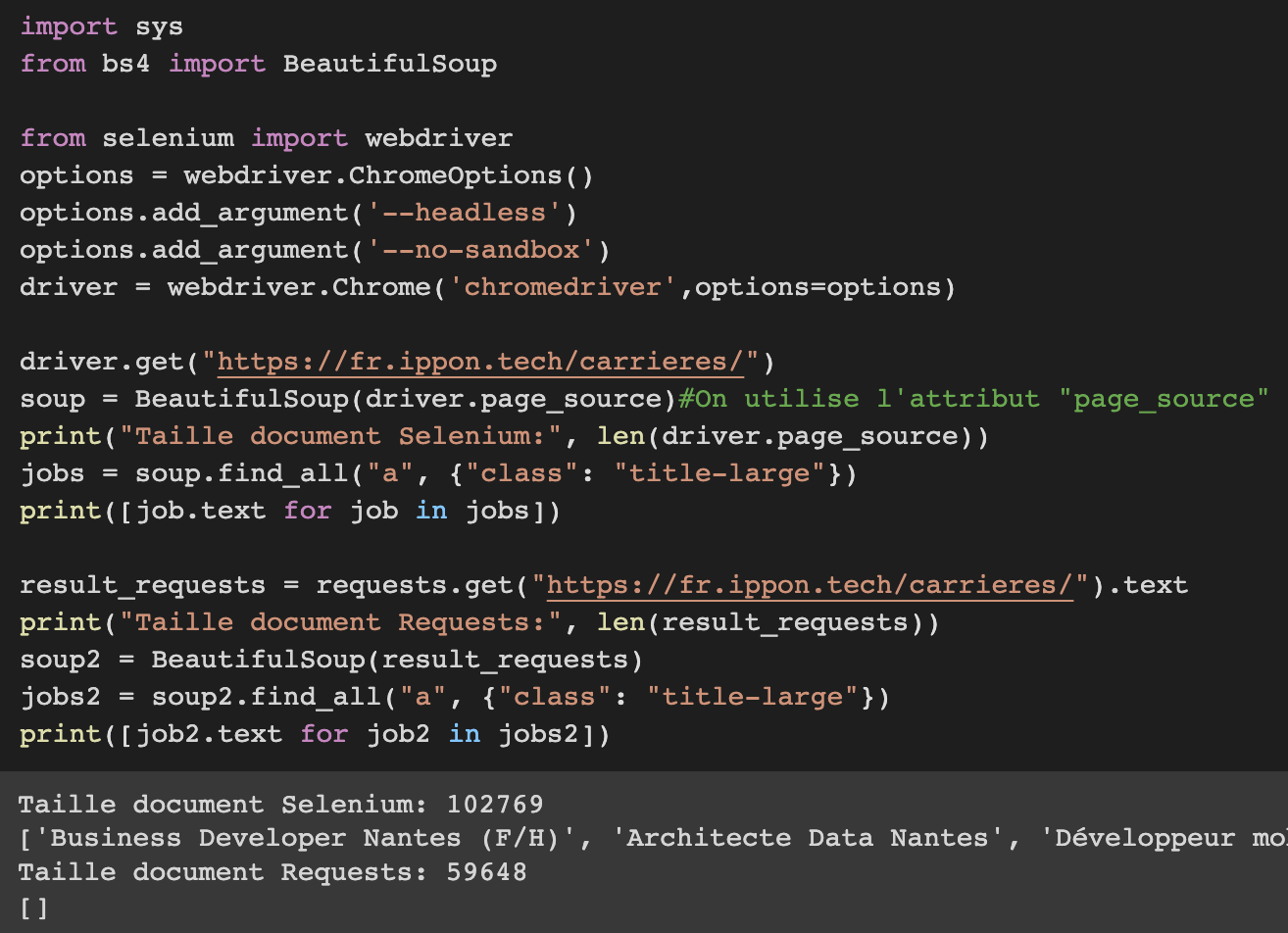
(Les titres des offres sont des balises “a” avec classe “title-large”)
L’HTML pour les offres est généré à la volée via des requêtes XHR, il est donc impossible pour requests de les voir vu qu’aucun JS n’est appelé, mais cela ne pose pas de problème pour Sélénium.
Il existe des frameworks comme Scrapy pour faciliter ce type de scraping grâce au concept de Spiders. J’ai fais le choix de ne pas en parler dans cet article pour ne pas compliquer les choses, mais vous pouvez en lire plus ici : https://blog.ippon.fr/2019/06/17/extraire-la-data-des-reseaux-sociaux/
Cout:
Simplicité:
Pérennité:
Points importants
Vous avez maintenant les clés en main pour extraire les données dans cette caverne qu’est Internet, cependant les exemples partagés dans cet article ne reflètent pas la réalité qui est souvent bien plus cruelle.
Cette partie de l’article a pour objectif de vous fournir les outils nécessaires pour comprendre rapidement vos problèmes et pouvoir agir. Nous discuterons également d’autres points importants dans le scraping en général.
L’éthique du scraping
Une partie qu’il semble important d’aborder en premier lieu est celle de l’éthique du scaping.
L’idée est de sensibiliser à pratiquer du scraping responsable.
Certains articles dédiés à ça l’exprimeront sans doute mieux que moi, mais il est toujours de bon augure de respecter quelques règles lors d’une séance de scraping.
- Ne récupérer que des informations disponibles publiquement et ne pas les revendre/publier directement (ce qui est d’ailleurs quasiment toujours illégal).
- Même si les données sont publiques, ne pas scraper de données personnelles
(https://www.cnil.fr/fr/la-reutilisation-des-donnees-publiquement-accessibles-en-ligne-des-fins-de-demarchage-commercial) - Respecter le site en question, d’autant plus s’il s’agit d’un site ayant une petite infrastructure, si vous effectuez des requêtes trop rapidement, vous pouvez causer des problèmes au site, voire même causer un déni de service involontaire.
Les User-Agents
Vous venez de trouver une API sur un site internet et souhaitez l’utiliser dans du code, tout a l’air similaire mais quand vous exécutez votre requête vous obtenez une erreur.
Dans 90% du temps (évidemment, ce n'est pas une vraie statistique, je n’ai pas les chiffres), il s’agit d’un problème de User-Agent (UA).
Un User-Agent est simplement un morceau de texte qui ressemble à ça :
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36
Il sert à indiquer l’OS, le navigateur et sa version, surtout à des fins de compatibilité et est envoyé au serveur lors d’une requête HTTP.
Cela permet notamment de déterminer si l’utilisateur est sur un mobile ou non (bien que d’autres méthodes existent).
Le souci est que lorsque nous effectuons des requêtes via du code, bien souvent l’utilitaire (curl ou requests, par exemple) va avoir son propre user agent.
On peut s’en rendre compte en utilisant le site https://httpbin.org/user-agent
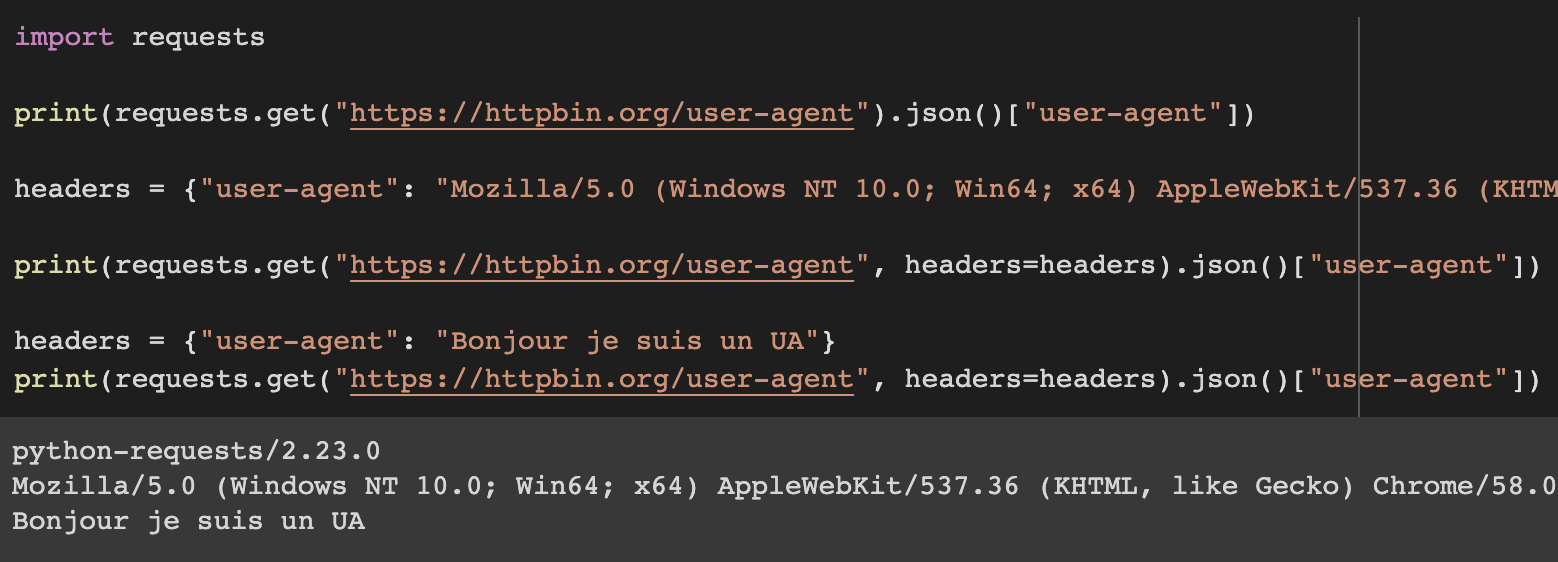
Comme on peut le voir, la valeur de l’user-agent peut littéralement être ce que l’on veut, il est intéressant pour nous d’apparaître comme un navigateur classique pour éviter les blocages.
Sur un gros projet il peut même être intéressant, voire obligatoire à un certain point de changer par rotation son user agent.
Voici une liste des user agent les plus commun que vous pouvez utiliser :
https://www.networkinghowtos.com/howto/common-user-agent-list/
(Les contenu des User Agents n’ont pas vraiment beaucoup de sens aujourd’hui, je laisse le lien vers un article qui en détaille l’histoire pour les intéressés, cela dépasse évidemment le cadre de l’article: https://webaim.org/blog/user-agent-string-history/)
Attention aux pièges
Certaines ressources en ligne préconisent d’utiliser le User-Agent du crawler de google (GoogleBot) ou d’autres moteurs de recherche, ce qui paraît être une bonne idée, mais cela est très facile à identifier, un site internet peut vérifier si votre IP appartient à la liste des IP de GoogleBot via un Reverse DNS, et si ce n’est pas le cas directement vous marquer comme suspicieux ou directement vous bloquer.
https://developers.google.com/search/docs/advanced/crawling/verifying-googlebot?hl=fr
Un User-Agent classique sera beaucoup mieux dans la plupart des cas, ou même utiliser un UA d’appareil mobile, qui pour certains sites peut complètement changer leur fonctionnement et peut être donner accès à plus d’informations.
Les proxies
Lorsque vous scrapez comme s' il n’y avait pas de lendemain, et que vous effectuez beaucoup de requêtes à la suite provenant de la même IP, vous risquez de rapidement vous faire bloquer.
C’est pourquoi il est important d’utiliser un bon nombre d’IP différentes, ce qui est fait en faisant une rotation de proxy.
Bien qu’il existe des proxies gratuits disponibles sur Internet, il est mieux d’éviter de les utiliser, ceux ci ayant déjà été utilisés par beaucoup d’autres personnes souvent à des fins peu scrupuleuses, sont bloqués par bon nombres de sites.
Par exemple ScraperAPI propose une méthode simple pour utiliser ses proxies :
https://www.scraperapi.com/
Il y a également https://rayobyte.com/
Si vous êtes sur un petit projet, il est possible d’utiliser ces services comme proxy :
Google Cache est un outil de Google qui garde une version en cache d’un site web, pour l’utiliser il suffit de remplacer <URL> par le lien que vous souhaitez scraper, vous n’ interagissez pas directement avec le site, mais bien avec Google cache.
⚠️ Attention, si vous chargez des ressources externes sur le cache (comme les images), ces ressources ne passent pas par le cache mais bien par vous ⚠️
https://webcache.googleusercontent.com/search?ie=UTF-8&q=cache:<URL>
Google Translate permet de traduire une page d’une langue à une autre, celle-ci agit de la même façon que Google cache.
https://translate.google.com/translate?hl=en&sl=auto&tl=en&u=<URL>
Le fingerprinting
Dans la plupart des cas la combinaison UA+Proxy fonctionnera sans soucis, mais il est quand même important de noter que des méthodes plus avancées existent pour détecter l’unicité d’un utilisateur de site web, une de ces méthodes étant le fingerprinting.
Le fingerprinting s’applique également à n’importe quel utilisateur qui utilise le web, l’idée est de rassembler toutes les informations qu’un utilisateur transmet via son navigateur (Système d’exploitation, version du navigateur, heure locale, et bien d’autres) et la combinaison de toutes ces informations va donner une empreinte, à priori suffisamment unique pour traquer un utilisateur d’un site à l’autre.
Ce site web vous permet de voir si votre empreinte est plus ou moins commune :
https://amiunique.org/fr/fingerprint
Chose intéressante à remarquer: une information qui est donnée au site internet est la liste de vos polices d’écritures installés, et c’est bien souvent un des facteur les plus discriminant dans cette liste.
Un autre site du même genre pour les intéressés : https://abrahamjuliot.github.io/creepjs/
Lorsque vous utilisez un Headless Browser comme vu dans la section précédente il est possible de choisir les valeurs à envoyer à un site internet, mais cela reste une tâche fastidieuse et complexe.
Certains projets comme selenium-stealth (https://github.com/diprajpatra/selenium-stealth)
existent et ont comme objectif de faire fondre Sélénium dans la masse, mais n’ayant pas eu besoin de le tester moi même je ne peux pas affirmer ou infirmer son efficacité. Toujours est-il que l’option existe et cette piste est peut être à creuser.
Conclusion
Dans cet article nous avons pu passer en revue différents aspects important du scraping, et selon moi la partie la plus importante étant celle des différentes méthodes, le scraping via parsing d’HTML est souvent trop rapidement la solution numéro 1 de beaucoup de personnes. Bien qu’elle comporte certains avantages, envisager d’autres solutions ne peut être que bénéfique.
Malheureusement il n’est pas possible de parler de tous les sujets intéressants liés de près ou de loin au scraping dans un seul article, mais j’espère que j’ai su éveiller votre intérêt sur les différents sujets abordés ici.
Liens utiles et sujets avancés :
