

Vous avez déjà sûrement entendu parler de Rust, ce langage qui est systématiquement élu langage préféré des utilisateurs de StackOverflow depuis 2016. Peut être que vous l’utilisez déjà et qu’à travers cet article vous souhaitez intégrer cet outil à vos Lambdas. Vous êtes au bon endroit puisque le but de cet article est de vous donner les clés pour la création et le déploiement de fonctions Rust Serverless sur AWS Lambda.
Nous reviendrons d’abord sur chacune des briques nécessaires, que nous intégrerons ensuite à AWS SAM dans le cadre d’un exemple “simple”.
A la fin de cet article vous devriez pouvoir ajouter une Lambda en Rust dans un projet SAM déjà existant, tout en comprenant ce que vous êtes en train de faire !
Pourquoi utiliser Rust ?
C’est une chose d’être le langage préféré des utilisateurs d’un de nos sites préférés, mais pourquoi ? Est-ce qu’à l’instar de Deno ou encore Go, les développeurs en 2022 se ruent sur tout langage ayant une mascotte mignonne ?

|

|

|
| Logo Deno (1) | Mascotte Go (2) | Mascotte Rust (3) |
Alors peut-être en partie, mais là n’est pas la question. L’attrait pour Rust peut être résumé à 3 points clés :
- Sa rapidité
- Son système de gestion de la mémoire
- Son compilateur
Sa gestion de la mémoire
Il n’y a pas besoin d’expliquer en quoi être rapide est un avantage, mais qu’est-ce qui permet à Rust d’être aussi efficace ? On arrive à ce qui fait le cœur du langage, mais également ce qui est le moins intuitif initialement : sa gestion de la mémoire.
Traditionnellement les langages de programmation se reposent sur un garbage collector (GC), comme en Java, ou sur l’expertise du développeur, comme en C, pour s’assurer que la mémoire est gérée correctement. Ces approches s’accompagnent respectivement d’un impact sur la performance (bien que les GC s’en sortent plutôt bien aujourd’hui) et d’une complexité accrue ainsi que de nombreuses fuites mémoire si le développeur n’est pas expert.
Rust lui s’appuie sur une forte distinction entre les variables dont la taille est connue à la compilation (qui seront stockées dans le stack) et celles dont la taille n’est pas connue à la compilation (qui seront stockées dans le heap).
Par exemple pour gérer des chaînes de caractères on a un type statique, le String Literal (&str) qui sera stocké dans le stack et un type String dynamique qui sera stocké dans le heap :
let my_str = "Hello, world!"; // type &str immutable, stocké dans le stack
let mut my_string = String::from("Hello, world!"); // String mutable, stocké dans le heapCette distinction n’est pas la seule particularité de Rust puisqu’on se doit d’aborder les notions d’Ownership et de Borrowing. Dans les grandes lignes, ces notions permettent de limiter la durée de vie d’une variable au scope dans lequel elle est déclarée. Le Borrowing permet “d'emprunter” une variable d’un scope à un autre. A ces notions on peut ajouter la notion de move qui est le déplacement permanent d’une variable d’un scope à un autre. On a donc par exemple :
fn main() {
// Initialisation dans un scope 'a'
let my_string = String::from("Hello World");
println!(" initial string {}", my_string);
{
// Borrowing par référence du scope 'a' vers 'b'
let borrowed_string = &my_string;
println!("borrow :{}", borrowed_string);
} // Fin du scope 'b'
// variable toujours disponible dans le scope 'a'
println!("after borrow :{}", my_string);
{
// Move du scope 'a' vers 'c'
let moved_string = my_string;
println!("move :{}", moved_string);
} // fin du scope 'c'
println!("after move :{}", my_string); // invalide
}
“Attend comment ça invalide ? Je suis complètement perdu” me direz-vous. Et bien oui, la variable a été changée de scope en la réassignant, Rust a donc automatiquement libéré la variable “my_string”. Bref, il est impossible d’apprendre les détails du langage en 2 minutes, mais si vous voulez y consacrer des jours entiers ou si vous avez juste quelques questions, l’excellent Rust Book est à votre disposition !
Son compilateur
Heureusement il n’est pas nécessaire d’avoir absolument tous les concepts en tête lors de l’écriture de votre premier programme. En effet, Rust est doté d’un excellent compilateur basé sur LLVM, un framework de compilateur derrière Clang pour la famille de langage C par exemple. Il bénéficie donc de la rapidité et de la faible utilisation mémoire de ce framework.
Mais ce qui fait vraiment la différence à l’utilisation est le Borrow Checker. C’est lui qui est responsable de vérifier que tout ce que vous faites n’est pas un plat de spaghettis duquel risquent d’émerger des centaines d’insectes. Plus concrètement, il vérifie votre gestion de la mémoire, et si vous faites des erreurs, il vous le dit lors de la compilation !
Et encore, “le dire” n’exprime pas à quel point Rust vous tient la main pendant la compilation avec des messages d’erreurs et des warnings d’une rare qualité.
Par exemple, le code ci-dessus avec une instruction invalide ne compilera pas, car le Borrow Checker aura repéré l’erreur et vous en informera ainsi :

La précision des erreurs vous permettra la plupart du temps de rapidement corriger le problème, ou au moins d’en comprendre l’origine. En bonus, une fois qu’un programme compile correctement, il y a de très fortes chances pour qu’il fonctionne du premier coup , puisque très peu de comportements sont laissés au hasard.
En conclusion, Rust c’est un peu comme un parent un peu strict. Il nous tient la main pour nous aider à faire du code de qualité en nous expliquant quoi faire, mais c’est d’une main de fer qu’il nous interdit la moindre erreur et qu’il nous oblige à replonger notre nez dans le (toujours aussi excellent) Rust Book.
Rust dans vos Lambdas
Sur nos architectures serverless le vieil adage “le temps c’est de l’argent” coule de source. Plus vos Fonctions prennent du temps à s'exécuter, plus elles coûtent cher.
Heureusement la bonne performance de Rust s’applique également à vos Lambdas, comme on peut le voir dans cet article d’Alexander Filichkin : AWS Lambda battle 2021: performance comparison for all languages (cold and warm start).
Maintenant quels outils utiliser pour pouvoir déployer efficacement vos Lambdas en Rust ? La réponse, comme souvent, est que cela dépend de vos besoins, mais laissez moi vous donner quelques éléments qui vous aideront à faire votre choix.
Si vous souhaitez uniquement mettre un place un projet SAM adapté au déploiement des lambdas en Rust, vous pouvez passer directement à la section éponyme
Pré-requis
- SAM
- Rust et Cargo
- Cargo Lambda (et Zig)
- Docker : Docker est utilisé par SAM pour lancer vos Lambdas en local (même si Cargo Lambda reste ce que je préconise de par sa simplicité) ainsi que dans le cas où vous souhaiteriez compiler vos Lambda Rust dans un container dont je vous fournirai le Dockerfile. (Attention, veillez à permettre à un utilisateur non-root d’accéder à Docker pour l’utiliser avec SAM.)
La crate lambda_runtime
AWS Lambda propose plusieurs environnements d’exécutions (runtimes) implémentant des langages différents. Ainsi on retrouve évidemment un environnement Python ou encore JavaScript. Mais aujourd’hui Rust n’est pas supporté nativement. Comment faire ?
AWS implémente avec Lambda un système de Runtime Custom. Très grossièrement cela prend la forme d’un exécutable (un fichier nommé bootstrap) qui fait le lien entre l’environnement de la Lambda et la fonction à exécuter.
Heureusement pour nous il n’est pas obligatoire de s’encombrer des détails techniques, puisqu’AWS nous met à disposition une crate (le nom donné aux packages Rust) qui s’en occupe pour nous, la crate lambda_runtime.
Il nous faut donc créer un projet Rust et ajouter cette crate à notre cargo.toml, qui est un fichier qui décrit notre projet Rust, analogue à un package.json par exemple. On va suivre l’arborescence suivante :
BasicRustFunction
├── Cargo.toml
├── src
│ └── main.rs
On va également rajouter les crates tokio et serde-json qui sont utilisées respectivement pour du calcul asynchrone et la gestion du format JSON.
Soit notre fichier Cargo.toml:
[package]
name = "basic-rust-function"
version = "0.1.0"
edition = "2021"
[dependencies]
lambda_runtime = "0.6.0"
serde_json = "1.0.85"
tokio = "1.21.0"
Attaquons nous maintenant au code en lui même, soit le fichier main.rs.
Concrètement cette crate va nous amener à légèrement changer la structure de notre programme Rust, pour laisser la crate gérer le point d’entrée de notre fonction et transmettre les évènements Lambda à notre code :
use lambda_runtime::{service_fn, Error, LambdaEvent};
use serde_json::{json, Value};
#[tokio::main]
async fn main() -> Result<(), Error> {
let func = service_fn(func);
lambda_runtime::run(func).await?;
Ok(())
}
async fn func(event: LambdaEvent<Value>) -> Result<Value, Error> {
let (event, _context) = event.into_parts();
let first_name = event["firstName"].as_str().unwrap_or("world");
Ok(json!({ "message": format!("Hello, {}!", first_name) }))
}
Source : https://crates.io/crates/lambda_runtime/#example-function
Et… C’est tout, on a déjà une lambda prête à compiler et à déployer. Mais du coup, comment on déploie ? comment on crée notre exécutable, comment on teste que notre code répond correctement aux évènements ? Et bien tout ça c’est le job de Cargo Lambda.
Cargo Lambda
Pour des informations plus détaillées sur les différentes étapes et commandes présentées dans cette partie, n’hésitez pas à vous référer à la documentation de Cargo Lambda.
Cargo est le package manager de Rust. Cargo Lambda est une sous-commande de Cargo.
Il convient donc d’installer l’un puis l’autre :
sudo apt-get -y install cargo
cargo install cargo-lambda
Compilation
Nous pouvons désormais compiler notre projet. Cargo Lambda, par l’intermédiaire de l’utilitaire zig, va compiler pour l’architecture spécifique de nos lambdas.
cargo lambda build -release --target x86_64-unknown-linux-gnu.2.17
Attention : Si Zig n’est pas installé sur votre machine, Cargo Lambda vous proposera de l’installer via Pip3. Si vous n’avez pas Pip3 référez vous à la documentation de Cargo Lambda pour l’installer.
Nous avons désormais généré notre fichier exécutable bootstrap !
BasicRustFunction
└── target
├── lambda
│ └── BasicRustFunction
│ └── bootstrap
Tester sa lambda localement
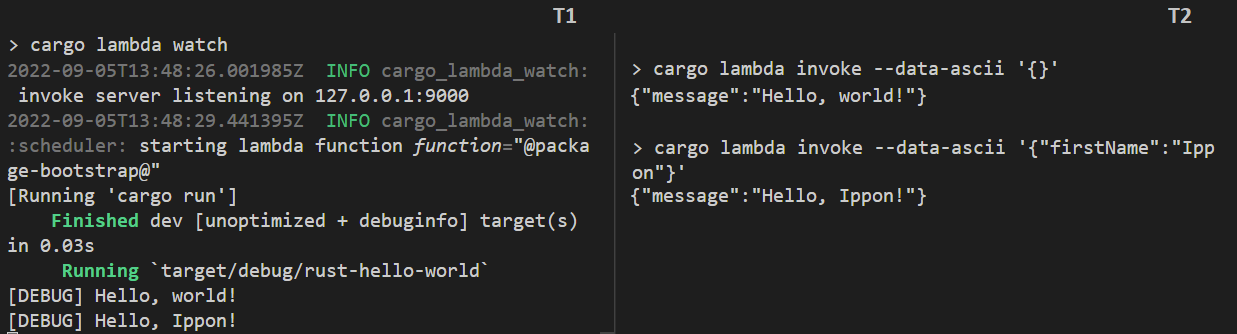
Le gros avantage de Cargo Lambda est d’embarquer un émulateur Lambda très simple d’utilisation, qui permet de tester sa lambda dans des conditions proches du réel (aux permissions près) avec notamment une gestion des évènements. Pour ce faire, j'ai pour habitude d’ouvrir deux terminaux (ci-dessous T1 et T2). Dans le premier nous lançons l’émulateur avec la commande watch:
# T1
cargo lambda watch
En bonus, vous n’aurez pas besoin de lancer cette commande à répétition, puisque toute modification au code sera automatiquement compilée !
Dans le second terminal nous utiliserons la commande invoke pour exécuter notre lambda. Nous devons également lui transmettre un évènement, sous la forme d’une chaîne de caractères avec le flag –data-ascii ou sous la forme d’un fichier json avec –data-file
# T2
cargo lambda invoke --data-ascii <event>
# ou
cargo lambda invoke --data-file <file>
J’apprécie utiliser deux terminaux plutôt que de lancer l’émulateur en arrière plan car le terminal dédié à l’émulateur permet de visualiser la sortie standard de l’environnement de la Lambda, et notamment les fameux println! que vous utiliserez certainement à des fins de debug.
Laissez moi modifier un peu notre fonction en ajoutant une instruction de debug et illustrer un peu mieux ce que je raconte :
async fn func(event: LambdaEvent<Value>) -> Result<Value, Error> {
let (event, _context) = event.into_parts();
let first_name = event["firstName"].as_str().unwrap_or("world");
println!("[DEBUG] Hello, {}!", first_name); // Ajout d'une ligne de debug
Ok(json!({ "message": format!("Hello, {}!", first_name) }))
}
En pratique on a bien nos messages de debug à gauche, et la sortie de la Lambda à droite. On voit également que l'événement transmis est correctement traité:
Déploiement
Nous avons désormais testé notre fonction Lambda, il ne nous reste plus qu’à la déployer sur AWS !
Cargo Lambda s’en occupe également. Malheureusement on se retrouve vite limités, ce qui justifiera la plupart du temps l’utilisation d’un outil un peu plus puissant : SAM. Nous y reviendrons.
Déployer via cargo lambda est relativement simple :
cargo lambda deploy
Un rôle d'exécution par défaut sera créé, cependant dès que votre lambda aura besoin de permissions plus poussées vous devrez créer ce rôle au préalable et l’associer à votre lambda avec le flag –iam-role.
Dans la plupart des cas ce n’est pas optimal, d’autant plus que Cargo Lambda ne peut déployer qu’une fonction Lambda à la fois.
En bref, Cargo Lambda est un outil très simple à utiliser et qui facilite le développement en local et la compilation, mais qui ne suffit pas dès lors que notre projet grandit en taille et en complexité.
AWS SAM
AWS Serverless Application Model, que nous appellerons SAM, est un framework permettant de créer des applications serverless. En quelques mots, ce framework facilite la déclaration de Lambdas et de ressources complémentaires afin de déployer rapidement une stack serverless. Parmi ces ressources on peut notamment citer Layers, APIs ou encore Policies ou Events.
Dans cette partie nous allons utiliser tout ce qui a été détaillé précédemment et plus encore pour mettre en place un projet SAM permettant de déployer une ou plusieurs Lambdas rustiques.
Le code issu de cette partie, ainsi que d’autres exemples et ressources sont disponibles sur ce repo.
(Optionnel) Création d’un container de build
Une fois tous les pré-requis installés, vous devriez pouvoir build en utilisant SAM. Cependant si vous souhaitez disposer d’un environnement “clé en main” pour build vos lambdas en Rust, Un Dockerfile est à votre disposition sur ce repo.
Le build de l’image Docker se résume à cette commande :
docker build -t sam/build-lambda-rust <path_to_dockerfile>
Il faut ensuite indiquer à SAM d’utiliser cette image pour le build. Il est préférable de le faire par l’intermédiaire du fichier samconfig.toml en y rajoutant ces lignes :
[default.build.parameters]
build_image = ["BasicRustFunction=sam/build-rust-lambda"]
mais il est également possible de le faire directement en ligne de commande avec :
sam build --use-container --build-image BasicRustFunction=sam/build-rust-lambda
Ajouter une fonction Rust à son projet SAM
Dans cette partie nous allons ajouter une fonction Rust à votre projet SAM. Plus spécifiquement nous allons intégrer la fonction développée précédemment à un projet SAM.
Dans le cas où vous partiriez de zéro, le code est disponible ici.
Prenons un projet SAM basique. Nous allons voir quelles modifications y apporter afin d’intégrer notre fonction :

La première chose à faire est de déclarer notre nouvelle ressource. Cette déclaration de ressources est au cœur de SAM et s’effectue dans le fichier template.yaml.
Pour l’arborescence décrite ci-dessus, l’ajout de cette ressource peut être aussi simple que de rajouter les lignes suivantes dans la section “Resources” du template.yaml (attention au respect des tabulations):
BasicRustFunction:
Type: AWS::Serverless::Function
Properties:
CodeUri: ./BasicRustFunction
Handler: bootstrap.is.the.handler
Runtime: provided
Metadata:
BuildMethod: makefile
Laissez moi revenir sur ces quelques lignes :
- CodeUri : Cette ligne indique le chemin relatif de la fonction, et plus spécifiquement du Makefile responsable pour le build de cette fonction.
- Handler : Ici cette ligne est rajoutée par souci de lisibilité. En effet on utilise un langage compilé, et nous sommes donc obligés de générer un exécutable, ce qui nous exempte d’handler. La valeur ici n’est pas importante.
- Runtime : Notre Runtime n’est pas directement supportée par Lambda (d’où l’existence de cet article), on utilise donc une runtime custom, d’où la valeur “provided”.
- BuildMethod : Cette ligne est cruciale. Elle indique à SAM que nous utilisons un Makefile pour la génération de notre exécutable.
L’utilisation d’un Makefile pour l’étape de compilation est obligatoire, puisque SAM ne sait pas comment gérer la compilation d’une runtime custom.
Son rôle est simple : compiler vers l’architecture propre aux Lambdas, et mettre tous les artéfacts de compilation à disposition de SAM en préparation de l’étape de déploiement.
Par ailleurs, il faut faire attention à le nommer Makefile.
.PHONY: build
build-BasicRustFunction:
cargo lambda build --release --target x86_64-unknown-linux-gnu.2.17
cp target/lambda/basic-rust-function/bootstrap ${ARTIFACTS_DIR}
A l'exécution de sam build, SAM va chercher dans notre Makefile l’étape build-[nom_de_la_ressource] (le nom précisé dans template.yaml)
Ensuite tout est plutôt logique, on build en utilisant Cargo Lambda puis on copie notre exécutable dans le dossier des artéfacts, qui est par défaut :
SamBasicRustApp
├── .aws-sam
│ ├── build
│ │ ├── BasicRustFunction
Les artéfacts comprennent évidemment l'exécutable, mais dans le cas où votre code utilise des fichiers issus de votre disque dur, il faudra faire attention à ce qu’ils soient accessibles lors du déploiement. Ainsi par exemple si votre code lit le fichier :
├── BasicRustFunction
│ ├── config.json
Il faudra faire attention à rajouter la ligne :
cp ./config.json ${ARTIFACTS_DIR}
(Plus d’informations dans la partie sur la gestion des fichiers partagés)
Félicitations, il vous est désormais possible de compiler votre fonction, puis de la déployer :
sam build
sam deploy --guided
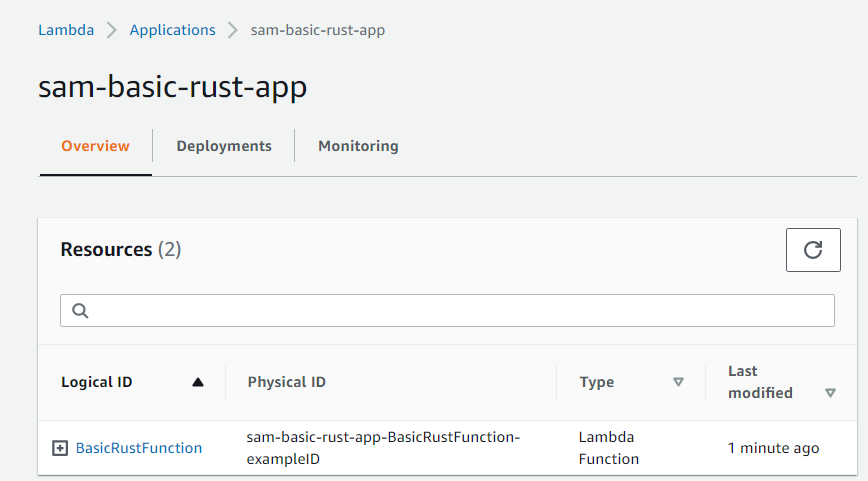
L’argument –guided permet de compléter le fichier samconfig.toml avec des informations relatives à l’application à déployer.
Une fois le déploiement effectué, vous devriez pouvoir retrouver votre application sur AWS.
Pour aller plus loin : la gestion des fichiers partagés
L’organisation présentée ci-dessus fonctionne très bien, mais évidemment elle n’est pas parfaite. Une de ses grosses lacunes est qu’en l'état, elle ne gère pas les fichiers partagés. Que ces fichiers soient des modules Rust custom où de simples fichiers de configuration communs à plusieurs de vos fonctions, l’utilisation du copier coller est un sacrilège pour beaucoup (et à raison) aussi il nous faut un moyen pour éviter la duplication du code et des ressources
SAM offre un support pour les Layers, qui permettent en théorie de faire exactement ce qu’on veut. Malheureusement Rust est compilé, ce qui implique qu’il a besoin de tout avoir à disposition dès la compilation.
Pour nous en sortir, nous allons utiliser la flexibilité permise par l’utilisation de makefiles.
Prenons deux fonctions, NiceRustFunction et AngryRustFunction, qui font toutes les deux appel au module “greetings”. On adapte le projet SAM de la sorte :
SamDryExample
├── srcRust
│ ├── AngryRustFunction
│ │ ├── Makefile
│ │ └── src
│ │ └── main.rs
│ ├── NiceRustFunction
│ ├── Makefile
│ └── src
│ └── main.rs
│ ├── modules
│ │ └── greetings
│ │ ├── Cargo.toml
│ │ └── src
│ └── Makefile
├── samconfig.toml
└── template.yaml
Trois choses sont à noter dans cette nouvelle arborescence :
- Les fonctions Rust sont désormais dans un dossier srcRust/
- Le module greetings est dans srcRust/modules
- Un Makefile est à la racine du dossier srcRust/
L’idée est la suivante : SAM fera appel à srcRust/Makefile pour toute fonction Rust, et c’est ce Makefile qui s’occupera de faire appel aux Makefiles respectifs à chaque fonction. Ainsi dans l’environnement de build le dossier srcRust/ complet sera à disposition, et les chemins relatifs du module greetings ne poseront pas de problème.
En pratique cela se traduit par le template.yaml suivant :
Resources:
AngryRustFunction:
Type: AWS::Serverless::Function
Properties:
CodeUri: ./srcRust/ # On utilise le même dossier pour les deux fonctions
Handler: bootstrap.is.the.handler
Runtime: provided
Metadata:
BuildMethod: makefile
NiceRustFunction:
Type: AWS::Serverless::Function
Properties:
CodeUri: ./srcRust/ # On utilise le même dossier pour les deux fonctions
Handler: bootstrap.is.the.handler
Runtime: provided
Metadata:
BuildMethod: makefile
couplé au fichier srcRust/Makefile suivant :
build-AngryRustFunction:
cd ./AngryRustFunction/ && make build
build-NiceRustFunction:
cd ./NiceRustFunction/ && make build
ensuite le build de chaque fonction est laissé à son Makefile respectif, par exemple pour srcRust/NiceRustFunction/Makefile on a :
.PHONY: build
build:
cargo lambda build --release --target x86_64-unknown-linux-gnu.2.17
cp target/lambda/nice-rust-function/bootstrap ${ARTIFACTS_DIR}
Pour les détails de l’implémentation et des imports j’ai mis le code complet à disposition ici.
Conclusion
Rust est un langage récent. Par conséquent, son support est encore limité. Pour autant il est si prometteur que de nombreux outils sont déjà disponibles pour en faciliter l’utilisation, c’est notamment le cas de la crate lambda_runtime maintenue par AWS et qui nous permet de tirer parti de Rust même dans nos applications serverless. Ce support n’est que le début, et la popularité de Rust est telle que je suppose que mon article sera rapidement obsolète.
En attendant, certains des outils que nous utilisons au quotidien n’ont pas encore sauté le pas, et l’utilisation de Rust dans leur contexte peut être sujette à friction. J’espère avoir réussi dans cet article à réduire cette friction, notamment dans le cas d’AWS SAM.

{kind=link}
{kind=link}
{kind=link}