

Redis est un composant serveur de cache distribué disponible en open source (BSD-3) que nous retrouvons dans de plus en plus d’architectures. Autrefois très présent dans les architectures PHP (qui ne possède pas de système de cache distribué comme infinispan, ehcache ou hazelcast) il est toutefois sorti de ce milieu et on le retrouve dans des architectures Java/NodeJS. À quoi peut-il bien servir ? Comment en faire bon usage ? Comment le déployer correctement et s’assurer de sa scalabilité et de sa robustesse ? Comment le sécuriser ? Existe-t-il des interfaces graphiques afin de mieux l’exploiter ? Voici les quelques questions auxquelles je me propose de répondre…
Rappel : Qu’est-ce-qu’un cache applicatif ?
Un cache est une couche de stockage de données grande vitesse qui stocke un sous-ensemble d'information, généralement transitoires, de sorte que les demandes futures soient traitées le plus rapidement possible. La mise en cache vous permet de réutiliser efficacement des données précédemment récupérées ou traitées.
Les cas d’usage
Le cache clé-valeur
C’est la fonctionnalité de base de Redis. Redis a d’abord été conçu comme une alternative à memcached. C’est un cache mémoire de type clé valeur, dont la priorité numéro 1 est la rapidité au niveau des temps de réponse. Sur un réseau classique de type Gigabit Redis répond dans l’ordre de la centaine de µs. Redis propose en option de persister ces données sur le disque, mais cette persistance est juste un moyen de récupérer les données en cas de redémarrage ou de crash.
Du côté des valeurs, Redis vous propose de stocker bien plus que des simples chaînes de caractères, il possède en effet les types suivants :
- Strings (GET/SET)
- Listes ordonnées de Strings (LGET/LSET)
- Sets (SADD/SMEMBER) : Collections de chaînes uniques non ordonnées
- Ordered sets (ZADD/ZRANGE) : Collections de chaînes uniques ordonnées
- Hashes (HGET/HSET) : Tableau associatif
Le gros intérêt est qu'on peut modifier un élément de ces collections sans avoir à renvoyer toute la collection! On peut aussi faire des requêtes optimisées pour récupérer une partie seulement de la collection.
Redis possède en outre des fonctionnalités sympathiques permettant d’incrémenter/décrémenter de manière atomique des valeurs.
Évidemment, (comme il s’agit d’un cache) redis implémente en standard un système de TTL (time to live) (commande EXPIRE), qui permet d’invalider les clés automatiquement à partir d’un temps donné.
Broker de message PUB/SUB
https://redis.io/docs/manual/pubsub/
Redis implémente une fonction de messagerie de type « Publish Subscribe » permettant donc de s'abonner à des canaux pour recevoir des informations par leur biais lorsque des messages sont publiés.
Attention, ce mode de fonctionnement ne permet pas de rejouer les messages si le subscriber n’était pas disponible… Aucune conservation des données n’est effectuée. Ainsi si vous voulez un système de message de type queue entre vos micro services, mieux vaut pour vous jeter un œil sur le paragraphe suivant!
Broker de flux (stream)
https://redis.io/docs/data-types/streams/
Cette fonctionnalité est pour moi une grande découverte, car elle offre une alternative à ce qu’on peut mettre en place avec Kafka. C’est une bonne alternative car un cluster Redis est beaucoup moins gourmand en ressources et plus simple à manager qu’un cluster Kafka.
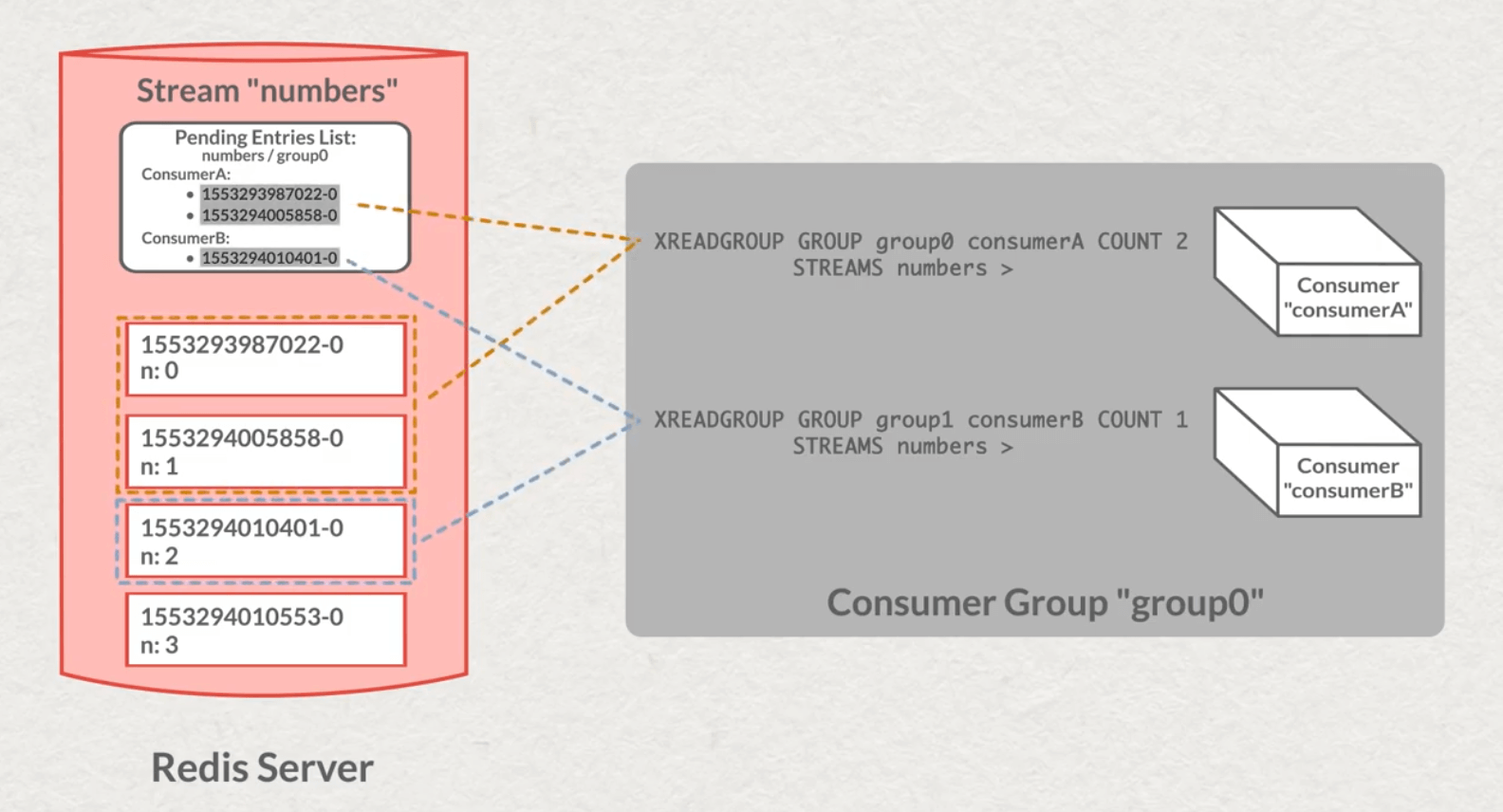
Un stream est une séquence ordonnée d’éléments avec une particularité notable : chaque nouvel élément du stream doit toujours être apposé au bout de la séquence. Il n’est ainsi pas possible d’en ajouter un au début ou au milieu du stream. C’est une structure persistée append-only.
Chaque message dans un stream est un hash de clé valeur. Redis n’effectue aucun traitement sur ces données, vous pouvez y mettre ce que vous voulez (string, json, binaire).
Pour produire des données dans un stream, il suffit d’utiliser la commande XADD. De multiples producteurs peuvent pousser des données dans un même stream.
Pour lire les données en temps réel, Redis possède la notion de groupe de consommateurs. Chaque groupe de consommateurs possède un offset de lecture dans le stream. Ceci est indispensable quand vous avez plusieurs instances du même microservice qui doivent consommer les données.
Les commandes XGROUP CREATECONSUMER et XREADGROUP permettent de créer un consommateur dans un groupe et de lire les données du groupe.

Les contraintes
- La taille des clés ou des valeurs est limitée à 512MB
- Redis est un système “in memory” donc il faut que la RAM du serveur puisse stocker l’intégralité des données. Il faut de ce fait dimensionner les serveurs en conséquence.
- La persistance de Redis est un système de backup qui ne garantit pas la durabilité, ce dernier est basé sur un système de snapshot périodique (RDB) https://redis.io/docs/manual/persistence/ Néanmoins les dernières versions ont mis en place le système AOF (Append Only File) qui est un fichier de log de toutes les opérations reçus par le serveur depuis le début. Meilleur que RDB concernant la perte de donnée en cas d’arrêt brutal, il rend le démarrage de redis assez lent, car ce dernier doit rejouer tout le journal pour reconstituer son état…
Pour avoir le meilleur des deux mondes on peut utiliser RDB et AOF en même temps, ce qui augmente la durabilité sans pour autant sacrifier le temps de démarrage.
- Redis est mono threadé, ce qui lui permet de ne pas avoir à gérer les problèmes de concurrence en écriture, il gère les requêtes les unes après les autres. Chaque requête Redis est atomique et se veut très rapide.
La sécurité
Il faut avouer, pendant longtemps la sécurité ne fut pas la priorité numéro 1 des développeurs Redis…
Comme le dit la documentation : “Redis is designed to be accessed by trusted clients inside trusted environments”. Il n’est donc jamais une bonne idée d’exposer son serveur redis publiquement sur internet! (j’enfonce des portes ouvertes, mais je l’aurais dit!)
Néanmoins, depuis quelque temps, on a du mieux !
- L'authentification n'est pas activée par défaut sur un serveur Redis. On peut l’activer en mettant un password en clair (...) dans le fichier redis.conf (requirepass)), heureusement depuis la version 6, on peut même spécifier des utilisateurs dans un fichier séparé : aclfile et même implémenter des listes de contrôle d’accès (ACL)!
- Le chiffrement des données en transit. C’est aussi une nouveauté de la version 6 (avant ils conseillaient de mettre un stunnel devant…). Les paramètres tls-*-file permettent de mettre en place une clé privée et un certificat afin de chiffrer le protocole Redis via TLS. On peut aussi utiliser l’authentification via certificat client via la propriété tls-auth-clients.
- Le chiffrement des données au repos. Redis peut utiliser le disque pour persister ses données. Pour les chiffrer, Redis se repose sur les fonctionnalités de l’OS (luks) ou du cloud provider.
Déployer Redis ?
Dans quel mode : Standalone / Sentinel / Cluster ?
Par défaut, Redis se déploie en mode instance standalone. Ce mode ne permet ni la haute disponibilité, ni la scalabilité. Il doit être réservé au développement ou à de l’utilisation sur des applications dont la criticité est faible. Dans ce mode, toutes les données sont sur un seul serveur Redis, non répliquées. Redis est alors un SPOF important.

Afin de pouvoir gérer la haute disponibilité (mais pas la scalabilité) Redis propose un mode de déploiement appelé Redis Sentinel. C’est un mode maître/esclave avec bascule automatique en cas de non-disponibilité du maître. Toutes les requêtes lecture / écriture sont faites sur le maître qui réplique les données sur les instances esclaves en temps quasi réel.
Le composant sentinel qui tourne sur tous les nœuds du cluster permet la découverte de service et renvoie au client l’adresse du maître courant.

Il faut au moins 3 nœuds pour un cluster sentinel.
En production, le mode que je vous conseille d’adopter est le mode “Redis Cluster”, il permet à la fois la haute disponibilité et le sharding des données, donc la scalabilité horizontale.

Dans ce mode, chaque nœud master est responsable d’un sous-ensemble des données du cluster et chaque nœud master est répliqué sur son nœud esclave correspondant.
Dans le cas d’ajout d’un nouveau nœud, la redistribution des données dans les nœuds du cluster est une opération transparente.
Il faut néanmoins savoir que ce mode n’est pas transparent pour l’application client. Il faut configurer la bibliothèque cliente pour lui dire qu’on fonctionne dans ce mode. En effet, lorsque lorsqu'on demande un objet à un nœud, celui-ci peut répondre avec la commande MOVED qui lui indique sur quel nœud il doit aller pour faire sa requête. C’est une sorte de redirection côté client.
GET x
-MOVED 3999 127.0.0.1:6381Dans cette configuration, il est nécessaire d’avoir au moins 6 nœuds pour garantir scalabilité et haute disponibilité.
Du côté du théorème du CAP, Redis Cluster se positionne comme un système CP.

Sur mon cloud provider préféré
Redis existe en tant que service managé sur la plupart des cloud providers digne de ce nom :
- Sur AWS : Redis est disponible sous le doux nom de AWS ElastiCache. Vous avez d’ailleurs le choix entre deux moteurs, Redis ou le bon vieux memcache. Il supporte le mode standalone et le mode cluster (pas le mode sentinel) et une scalabilité jusqu’à 500 nœuds.
- Sur Google GCP : Redis se trouve caché sous le service Memorystore, comme pour AWS, on a le choix entre Redis et memcache
- Sur Azure : Azure Cache for Redis
- Et cocorico, même OVH possède une version managée dans son public cloud : Managed Databases for Redis
Et pourquoi pas directement dans mon cluster Kube ?
Si vous désirez déployer Redis en mode “cluster” dans un cluster kubernetes, je ne saurais trop vous recommander l’usage d’un opérateur pour cela. Un cluster Redis est stateful et nécessite des étapes de configuration un peu complexes…
J’ai personnellement testé cet opérateur https://github.com/OT-CONTAINER-KIT/redis-operator

grâce à lui, je déploie un simple manifest :
apiVersion: redis.redis.opstreelabs.in/v1beta1
kind: RedisCluster
metadata:
name: redis-cluster
spec:
clusterSize: 3Et mon cluster est immédiatement opérationnel !
En local sur mon poste de dev
Je ne saurais que vous recommander d’utiliser docker pour cet usage.
docker run -d -p 6379:6379 --name myredis redisComme Redis est une application simple écrite en C, le lancer en local n’ajoutera presque aucune surcharge RAM sur votre poste ! (quelques Mo)! Ajoutez le à votre docker-compose pour le lancer en même temps que votre base de donnée locale.
Sinon, si vous utilisez linux, un simple :
apt-get install redisdevrait suffire.
Interagir avec Redis
Rien ne vous empêche de faire cela à la main sans utiliser de couche et de surcouche, car le protocole Redis est très simple. Il s’agit d’une simple connexion TCP et on envoie les bonnes commandes… On peut donc déboguer un redis avec un simple telnet!
Dans mes applications java
- La bibliothèque la plus complète et la mieux maintenue à mon goût est https://redisson.org/ Pas de soucis pour la connexion en mode cluster et SSL/TLS.
- https://lettuce.io/ : Fonctionne en mode réactif et asynchrone.
- https://github.com/redis/jedis (je n’ai pas trouvé comment se connecter à un cluster en SSL/TLS), pas très vivant et pourtant c’est l’implémentation officielle.
Spring boot data redis https://docs.spring.io/spring-data/data-redis/ utilise redisson ou lettuce comme backend de connexion.
Vous pouvez avec spring cache/redisson utiliser l’annotation @Cacheable avec redis https://redisson.org/glossary/spring-cache.html
Dans mes applications NodeJS
Du côté javascript/typescript https://github.com/redis/node-redis a l’air d’être très vivant et l’implémentation de référence.
Avec ma souris…
Pour ceux qui préfèrent les interfaces graphiques, il existe quelques outils bien faits :
- https://resp.app/
- https://github.com/patrikx3/redis-ui/
- Un plugin IntelliJ (non testé) https://plugins.jetbrains.com/plugin/12820-redis
Avec mes outils de monitoring
Du côté de l’observabilité, je vous conseille de mettre en place redis-exporter pour retrouver toutes les métriques redis dans prometheus.

Pour finir
Redis est un serveur de cache, rapide et très fiable (jamais constaté le moindre plantage). Il peut convenir à de nombreux cas d’usage métier/design patterns (chat en ligne, Event Sourcing, gestion de panier). Disposer d’un système de caching performant et fiable est un grand plus pour nos applications et pour améliorer leur réactivité! Sachons aussi sensibiliser les développeurs à l’utiliser à bon escient surtout quand un architecte solution s’est échiné à le mettre en place!
Néanmoins, sa mise en place en production nécessite de bien connaître à l’avance des éléments de volumétrie pour déployer la bonne architecture (cluster ou sentinel). Concernant une architecture basée sur les événements, pensez à Redis avant de déployer systématiquement un Kafka que vous ne sauriez pas opérer!
Sinon, par pitié, rappelez vous que Redis est d’abord un système de cache (n'en déplaise à son éditeur), donc que ces données viennent d’autres systèmes et doivent pouvoir être facilement reconstituées, ne l’utilisez pas comme base de données principale pour votre projet!
