

Si vous avez correctement suivi le walkthrough Delta Lake & CDC, vous pouvez désormais reconstituer dans votre lakehouse l’état courant d’une table grâce aux événements Change Data Capture (CDC) qu’elle a générés et à la fonction merge de Delta Table. Mais cette approche permet aussi d’historiser entièrement la table source, à condition d’être rigoureux dans la manière de faire son merge.
CDC & historisation : théorie
On aura donc à nouveau besoin de la puissance de Delta Lake et de sa fonction merge pour consolider les événements CDC dans notre future table historisée. En l’occurrence, on doit pouvoir garder l’information de la validité de chaque ligne dans le temps. Pour illustrer cela, prenons l’exemple d’une table très simple contenant deux colonnes, un id et une valeur métier :
Un changement dans cette table va émettre un événement CDC qu’on peut représenter comme ceci :
__time- date de l’opération à l’origine de l’event__type- type de modification (INSERT,UPDATEouDELETE)id- identifiant unique de la donnée modifiéevalue- la valeur métier
Je préfixe ici par “__” les colonnes techniques propres au CDC alors que le nom des colonnes métiers sources reste inchangé. La colonne __time est un Integer et non un Timestamp, par souci de simplicité.
Voyons ce que ça donne si on insère deux lignes dans notre exemple :
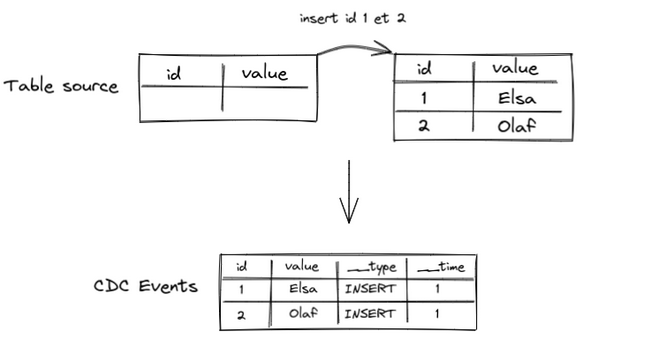
On voit que deux événements CDC de type INSERT sont générés à l’instant __time = 1.
Ensuite, on modifie une ligne existante dans la table source. Nous allons générer un autre événement CDC, de type UPDATE cette fois :
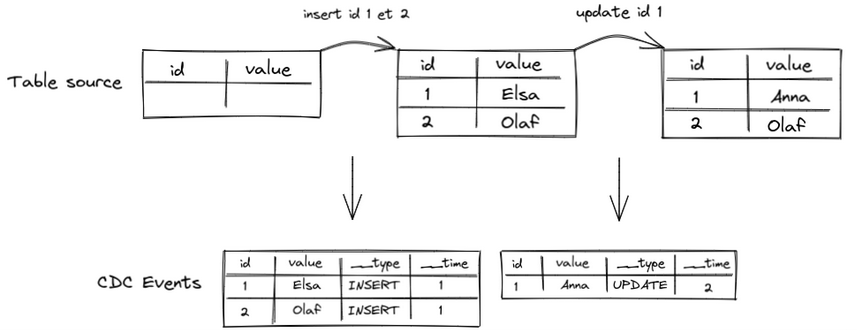
Enfin, si nous avons une dernière transaction qui supprime une ligne, nous arrivons au résultat suivant :
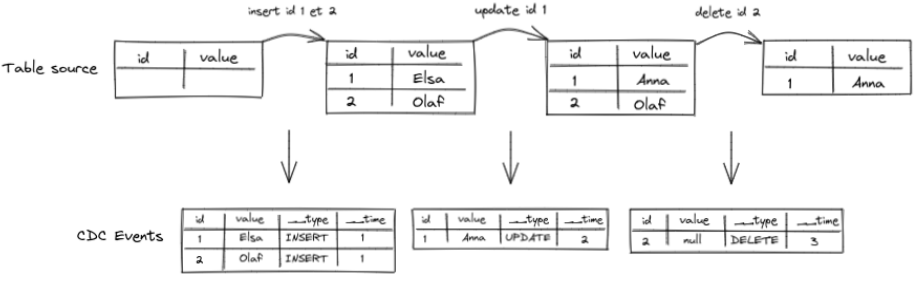
A noter que dans le cadre d’une data platform classique avec trois niveaux de données bronze / silver / gold, on se situe pour l’instant au niveau de la couche bronze. En effet ce type d’événement constitue la donnée brute extraite d’un outil de CDC (Debezium par exemple).
Pour passer au niveau silver, l’enjeu va être de consolider ces événements dans une table Delta cible et pour cela plusieurs stratégies sont possibles.
Consolidation en mode “snapshot”
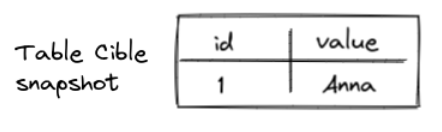
Cette consolidation représente l’état courant de la table source. C’est l’implémentation décrite dans le walkthrough Delta Lake & CDC, donc je ne reviendrai pas dessus plus en détail.
Voici toutefois l’état attendu de la table cible après les opérations de merge :
Consolidation en mode historisé
Ce mode conserve l’ensemble de l’historique des données. Nous aurons besoin d’ajouter des colonnes techniques afin de connaître la période de validité de chaque valeur et pouvoir ainsi retrouver l’état de la table à une date précise dans le passé :
__start_time- début de validité de la donnée__end_time- fin de validité de la donnée__is_current- est-ce la version actuelle de la donnée ?__is_deleted- la donnée existe-elle encore dans la version actuelle ?id- identifiant unique de la donnée modifiéevalue- la valeur métier
Les colonnes __is_current et __is_deleted sont optionnelles mais permettent de requêter plus facilement la table. Par exemple, en sélectionnant uniquement les lignes avec la valeur __is_current = true, on doit retrouver le snapshot de la table.
Voici la table historisée attendue :

Désormais, il est possible de connaître l’état de notre table source à l’instant t dans le passé avec une simple requête sur la table historisée :
SELECT * FROM table_history
WHERE __start_time =< t
AND (__end_time > t OR __is_current)
Cette requête peut être encore plus simple si dans la colonne __end_time des lignes à l’état actuel on insère la valeur maximale possible :
SELECT * FROM table_history
WHERE __start_time =< t AND __end_time > t
Maintenant que nous avons posé ces bases théoriques, place à la pratique !
Setup
La seule chose dont vous avez besoin pour exécuter le code des exemples est une installation de Spark 3.1 sur votre poste.
Dans cette démonstration, on va utiliser spark-shell, l'interpréteur de commandes Spark en Scala. Les résultats de nos opérations, c'est-à-dire le contenu de la table Delta Lake, seront affichés à l'écran. Le style du code a été adapté pour spark-shell qui l'exécute à la volée, ligne par ligne.
Bien évidemment, pour le code destiné à la production, la logique implémentée devra être validée par des tests automatisés. Pour les projets Spark en Scala, je vous conseille vivement d’utiliser la bibliothèque ScalaTest.
Après avoir téléchargé et décompressé Spark 3.1.x, vous pouvez lancer spark-shell avec la commande suivante :
./bin/spark-shell \
--packages io.delta:delta-core_2.12:1.0.0 \
--conf spark.sql.extensions=io.delta.sql.DeltaSparkSessionExtension \
--conf spark.sql.catalog.spark_catalog=org.apache.spark.sql.delta.catalog.DeltaCatalog
Comme vous pouvez le voir, on inclut la bibliothèque Delta Lake et on définit deux paramètres de configuration. Ces deux paramètres ne sont pas indispensables pour l’utilisation de Delta Lake mais permettent d’utiliser plus de fonctionnalités de l’API, notamment la possibilité d’exécuter la commande delete sur la table.
Commençons par ajouter les imports nécessaires et créer quelques fonctions utilitaires que nous allons utiliser dans les exemples :
import io.delta.tables.DeltaTable
import org.apache.spark.sql.Row
import org.apache.spark.sql.DataFrame
import org.apache.spark.sql.expressions.Window
import org.apache.spark.sql.types._
import org.apache.spark.sql.functions._
import spark.implicits._
val tablePath = "/tmp/delta/my_table"
val initEmptyTable = (schema: StructType) => {
spark
.createDataFrame(spark.sparkContext.emptyRDD[Row], schema)
.write
.format("delta")
.mode("overwrite")
.option("overwriteSchema", "true")
.save(tablePath)
}
val deleteTable = () => DeltaTable.forPath(tablePath).delete
val showTable = () => DeltaTable.forPath(tablePath).toDF.show
Pour vérifier nos implémentations, utilisons la méthode test qui :
- supprime le contenu de la table,
- appelle la fonction
mergesur chaque batch en leur appliquant la fonctiontransformpréalablement, - affiche le contenu de la table.
def test(merge: DataFrame => Unit, transform: DataFrame => DataFrame = x => x)(batches: DataFrame*): Unit = {
deleteTable()
batches.foreach{events => merge(transform(events))}
showTable()
}
Représentons maintenant les trois batchs d’événements CDC décrits au début de cet article :
val eventColumns = List("__time", "__type", "id", "value")
val events1 = List(
(1, "INSERT", 1, "Elsa"),
(1, "INSERT", 2, "Olaf")
).toDF(eventColumns: _*)
val events2 = List(
(2, "UPDATE", 1, "Anna"),
).toDF(eventColumns: _*)
val events3 = List(
(3, "DELETE", 2, null),
).toDF(eventColumns: _*)
Ainsi que le schéma de la future table dans laquelle ces événements seront consolidés :
val tableSchema = StructType.fromDDL("id STRING, value STRING, __start_time INT, __end_time INT, __is_current BOOLEAN, __is_deleted BOOLEAN")
Let’s merge !
Lors du merge, si l’id de l’event n’existe pas encore dans la table cible, l’opération est très simple :
val merge = (events: DataFrame) => {
DeltaTable
.forPath(tablePath)
.as("table")
.merge(events.as("event"), "table.id = event.id")
.whenNotMatched("event.__type = 'INSERT'")
.insert(Map(
"id" -> $"event.id",
"value" -> $"event.value",
"__start_time" -> $"event.__time",
"__is_current" -> lit(true),
"__is_deleted" -> lit(false)
))
.execute
}
Testons la bonne exécution de ce merge sur notre table :
initEmptyTable(tableSchema)
test(merge)(events1, events2, events3)
Après quelques secondes, spark-shell devrait vous afficher le résultat suivant :
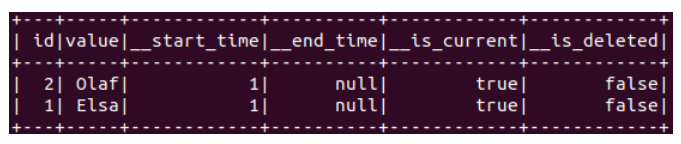
Notre implémentation insère tout simplement les événements de type INSERT (via le filtre event.__type = ‘INSERT’) dont l’id n’existe pas encore dans notre table cible (la condition de merge table.id = event.id est fausse).
On peut de la même manière ajouter le cas où l’id existe et que l’opération à appliquer est un DELETE. Dans ce cas, nous allons mettre à jour la ligne courante de cet id, récupérée avec le filtre __is_current = true :
val merge = (events: DataFrame) => {
DeltaTable
.forPath(tablePath)
.as("table")
.merge(events.as("event"), "table.id = event.id")
.whenNotMatched("event.__type = 'INSERT'")
.insert(Map(
"id" -> $"event.id",
"value" -> $"event.value",
"__start_time" -> $"event.__time",
"__is_current" -> lit(true),
"__is_deleted" -> lit(false)
))
.whenMatched("event.__type = 'DELETE' AND table.__start_time < event.__time AND table.__is_current = true")
.update(Map(
"__is_current" -> lit(false),
"__is_deleted" -> lit(true),
"__end_time" -> $"event.__time"
))
.execute
}
Cela se complique lorsque l’id est déjà connu et qu’on reçoit un event de type UPDATE car on veut faire deux actions dans ce cas :
- mettre à jour la ligne existante dans la table avec
__end_date = event.__time, - ajouter une nouvelle ligne avec
__start_date = event_timequi contient la nouvelle valeur pour cet id.
Cela correspond à écrire quelque chose de ce type :
val merge = (events: DataFrame) => {
DeltaTable
.forPath(tablePath)
.as("table")
.merge(events.as("event"), "table.id = event.id")
.whenNotMatched("event.__type = 'INSERT'")
.insert(Map(
"id" -> $"event.id",
"value" -> $"event.value",
"__start_time" -> $"event.__time",
"__is_current" -> lit(true),
"__is_deleted" -> lit(false)
))
.whenMatched("event.__type = 'DELETE' AND table.__start_time < event.__time AND table.__is_current = true")
.update(Map(
"__is_current" -> lit(false),
"__is_deleted" -> lit(true),
"__end_ts" -> $"event.__time"
))
.whenMatched("event.type = 'UPDATE' AND table.__start_time < event.__time" AND table.__is_current = true")
.update(Map(
"__end_time" -> $"event.__time",
"__is_current" -> lit(false),
))
.insert(Map(
"id" -> $"event.id",
"value" -> $"event.value",
"__start_time" -> $"event.__time",
"__is_current" -> lit(true),
"__is_deleted" -> lit(false)
))
.execute
}
Mais si vous lancez le test, spark-shell devrait rapidement vous remonter cette erreur :
error: value insert is not a member of io.delta.tables.DeltaMergeBuilder
En effet, le snippet précédent n’est pas compilable pour deux raisons :
- on ne peut utiliser la méthode
insert()sur la conditionwhenMatched(), - on ne peut définir deux actions consécutives sur une même condition
whenMatched().
La solution est en fait de merger en deux étapes : une première étape qui va mettre à jour ou supprimer les lignes existantes pour les events de type UPDATE et DELETE, puis une deuxième étape qui va insérer les nouvelles lignes des events de type UPDATE et INSERT.
val merge = (events: DataFrame) => {
DeltaTable
.forPath(tablePath)
.as("table")
.merge(events.as("event"), "table.id = event.id")
.whenMatched("event.__type = 'DELETE' AND table.__start_time < event.__time AND table.__is_current = true")
.update(Map(
"__is_current" -> lit(false),
"__is_deleted" -> lit(true),
"__end_time" -> $"event.__time"
))
.whenMatched("event.__type = 'UPDATE' AND table.__start_time < event.__time AND table.__is_current = true")
.update(Map(
"__is_current" -> lit(false),
"__end_time" -> $"event.__time"
))
.execute
DeltaTable
.forPath(tablePath)
.as("table")
.merge(events.where($"__type" =!= "DELETE").as("event"), "table.id = event.id AND table.__start_time = event.__time")
.whenNotMatched
.insert(Map(
"id" -> $"event.id",
"value" -> $"event.value",
"__start_time" -> $"event.__time",
"__is_current" -> lit(true),
"__is_deleted" -> lit(false)
))
.execute
}
Exécutons notre méthode de test avec cette dernière fonction merge et les trois batchs d’événements CDC :
test(merge)(events1, events2, events3)
Spark-shell devrait vous afficher le résultat suivant :
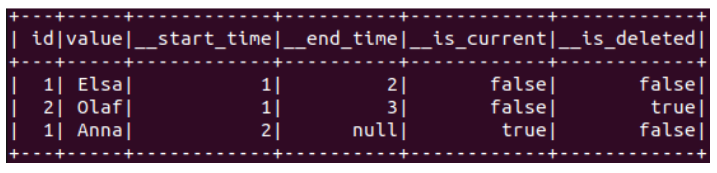
Victoire ! On retrouve bien le résultat attendu qui permet de garder l’historique entier de la table source.
Et comme prévu, si on sélectionne uniquement les lignes avec __is_current = true, on retrouve l’état courant de la table source :
DeltaTable.forPath(tablePath).toDF.where(col("__is_current")).show

Le monde réel est bien plus cruel
L’implémentation de la fonction merge donnée ci-dessus est déjà bien complexe : 30 lignes de code, un merge en deux étapes, plusieurs conditions de matching, etc.
Et pourtant on est encore loin de pouvoir gérer tous les cas à la marge qui peuvent survenir en production :
- duplication d’événements,
- multiples événements pour le même id dans un batch,
- ordre des événements non garanti au sein d’un batch,
- ordre des batchs non garanti,
- …
Pour pallier ces points, on peut envisager de pré-traiter notre DataFrame d’événements avant la fonction merge. Construisons pas à pas une méthode transform pour gérer chacun de ces points.
Duplication d’événements
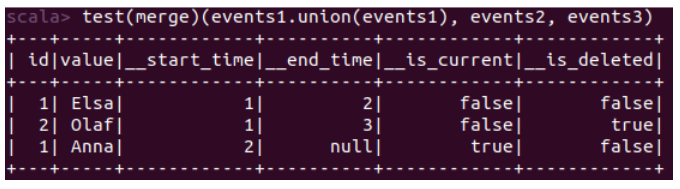
Simuler une duplication d’événements est très simple :
test(merge)(events1.union(events1), events2, events3)
Avec notre implémentation actuelle, le résultat suivant est renvoyé :
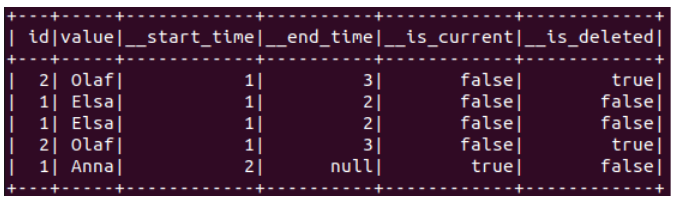
Pour retrouver un résultat correct, voici la manière la plus simple de dédupliquer nos événements dans la méthode transform :
def transform(events: DataFrame): DataFrame = {
events.dropDuplicates()
}
Modifions aussi notre merge pour qu’il appelle la méthode transform :
val merge = (events: DataFrame) => {
val transformedEvents = transform(events)
DeltaTable
.forPath(tablePath)
.as("table")
.merge(transformedEvents.as("event"), "table.id = event.id")
.whenMatched("event.__type = 'DELETE' AND table.__start_time < event.__time AND table.__is_current = true")
.update(Map(
"__is_current" -> lit(false),
"__is_deleted" -> lit(true),
"__end_time" -> $"event.__time"
))
.whenMatched("event.__type = 'UPDATE' AND table.__start_time < event.__time AND table.__is_current = true")
.update(Map(
"__is_current" -> lit(false),
"__end_time" -> $"event.__time"
))
.execute
DeltaTable
.forPath(tablePath)
.as("table")
.merge(transformedEvents.where($"__type" =!= "DELETE").as("event"), "table.id = event.id AND table.__start_time = event.__time")
.whenNotMatched
.insert(Map(
"id" -> $"event.id",
"value" -> $"event.value",
"__start_time" -> $"event.__time",
"__is_current" -> lit(true),
"__is_deleted" -> lit(false)
))
.execute
}
Si vous exécutez à nouveau le test précédent, vous arriverez à ce résultat correct :
Multiples événements pour le même id dans un batch
Il se peut aussi qu’un batch d’événements à traiter contiennent plusieurs événements pour le même id. Pour simuler ce cas, voici le test à exécuter :
test(merge)(events1.union(events2), events3)
Nos deux opérations sur l’id 1 (INSERT et UPDATE) qui se trouvaient initialement dans le premier et dans le deuxième batch, se retrouvent maintenant dans un seul et même batch.
On peut voir que notre transformation actuelle n’est pas suffisante :
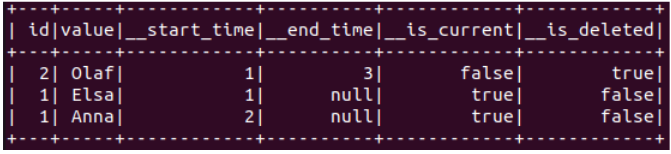
Ici, la valeur “Elsa” ne devrait pas être marquée comme courante pour l’id 1.
Le pré-traitement à réaliser est le suivant :
- nous allons utiliser une première window function afin d’ordonner chronologiquement les événements pour chaque id. Cette colonne,
__row_number, nous sera utile afin d’identifier l’élément le plus ancien plus tard dans notre merge. - une deuxième window function nous permet de récupérer le prochain événement pour un même id dans la colonne
__next_event. On peut alors renseigner le__end_timede la ligne dans le cas où un événement plus récent existe, mais aussi la marquer comme__is_deletedsi cet événement plus récent est de typeDELETE. Enfin, on peut flagger__is_currentsur la ligne la plus récente.
def transform(events: DataFrame): DataFrame = {
val earliest = Window.partitionBy($"id").orderBy($"__time")
val latest = Window.partitionBy($"id").orderBy($"__time".desc)
events
.dropDuplicates()
.withColumn("__row_number_desc", row_number over latest)
.withColumn("__row_number", row_number over earliest)
.withColumn("__next_event", lead(struct($"__type", $"__time"), 1, null) over earliest)
.withColumn("__end_time", $"__next_event.__time")
.withColumn("__is_current", $"__row_number_desc" === 1)
.withColumn("__is_deleted", when($"__next_event.__type" === "DELETE", lit(true)).otherwise(lit(false)))
}
Il faut légèrement adapter le merge pour qu’il prenne en compte nos colonnes de pré-traitement :
- La première partie du merge concerne uniquement l’événement le plus ancien pour un même id (identifié via le filtre
$"__row_number" === 1). - Dans la méthode insert du deuxième merge on ne fixe plus les colonnes
__is_currentet__is_deletedà “false” et “true” respectivement, mais on utilise les valeurs précalculées dans notre méthode transform.
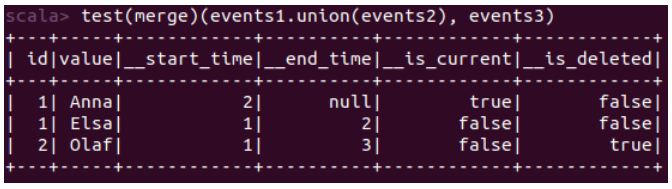
Voici l’implémentation finale du merge :
val merge = (events: DataFrame) => {
val transformedEvents = transform(events)
DeltaTable
.forPath(tablePath)
.as("table")
.merge(transformedEvents.where($"__row_number" === 1).as("event"), "table.id = event.id")
.whenMatched("event.__type = 'DELETE' AND table.__start_time < event.__time AND table.__is_current = true")
.update(Map(
"__is_current" -> lit(false),
"__is_deleted" -> lit(true),
"__end_time" -> $"event.__time"
))
.whenMatched("event.__type = 'UPDATE' AND table.__start_time < event.__time AND table.__is_current = true")
.update(Map(
"__is_current" -> lit(false),
"__end_time" -> $"event.__time"
))
.execute
DeltaTable
.forPath(tablePath)
.as("table")
.merge(transformedEvents.where($"__type" =!= "DELETE").as("event"), "table.id = event.id AND table.__start_time = event.__time")
.whenNotMatched
.insert(Map(
"id" -> $"event.id",
"value" -> $"event.value",
"__start_time" -> $"event.__time",
"__end_time" -> $"event.__end_time",
"__is_current" -> $"event.__is_current",
"__is_deleted" -> $"event.__is_deleted"
))
.execute
}
Et voilà à nouveau le résultat attendu :
Il existe un dernier cas particulier à noter : si dans une même transaction de la BDD source il y a plusieurs modifications de la même donnée, les events auront la même date de commit __time, ou __ts_ms si on utilise Debezium. Il est donc impossible de les ordonner et de connaître l’état final de notre BDD. On peut à la place (ou en complément) baser notre logique sur la position de l’événement dans les logs de transaction de la base de données. Par exemple, le connecteur PostgreSQL de Debezium permet de récupérer la position de l’événement dans le WAL (Write-Ahead Log) via la colonne __lsn (Log Sequence Number). On ordonne ainsi de manière plus fiable les événements entre eux.
Conclusion
Historiser les données avec la fonction merge de Delta Lake n’est pas simple si on tient compte de toutes les subtilités d’un cas réel. Les exemples que l’on trouve en ligne sont souvent (toujours ?) vraiment triviaux ce qui peut mener à des résultats inattendus en production. Cela démontre encore une fois la nécessité absolue de couvrir l’ensemble des cas possibles via des tests unitaires. Il existe pour cela des astuces simples permettant aux tests de gagner en lisibilité et en efficacité… à découvrir prochainement sur ce blog !
