

Un petit fichier mais de grands pouvoirs
On ne vous présente plus Docker, comme le décrit parfaitement l’article d’Alexandre Fillatre (Docker pour les nu... pour les débutants), ce formidable outil permettant de construire et distribuer rapidement un ensemble d’applications. Puis de les partager à n’importe qui, sans avoir à se soucier du système d’exploitation ni de l’environnement d’exécution, via un petit fichier tout simple : le Dockerfile. Si vous n’êtes pas à l’aise avec les concepts majeurs de Docker tels que les images, les builds et la construction d’un Dockerfile, je vous invite à consulter l’article cité précédemment et à revenir ici juste après (je vous attends sagement).
De grands pouvoirs impliquent de grandes responsabilités
Lorsqu’on comprend la puissance et l’importance de Docker dans tous les projets de développement, on comprend aussi que c’est sur le Dockerfile que tout repose. Un Dockerfile mal écrit peut mettre en péril tout votre code, mais il suffit d’une mauvaise optimisation pour constater les conséquences sur votre projet.
Écrire un Dockerfile est assez simple, par exemple, si vous souhaitez exécuter votre code Python dans un conteneur Docker, vous pourrez le mettre en place assez facilement en quelques minutes et avec seulement quelques lignes de code. Par contre, écrire un Dockerfile optimisé et créer des images qui le sont également, ça demande quelques efforts supplémentaires.
Docker et le Cloud, amis pour la vie
Lorsque vous lancez le “Build” d’un Dockerfile, vous créez une image Docker qui a une certaine taille, et qui occupe donc un certain espace de stockage. Je ne vous présente pas les plateformes Cloud, mais il va de soi que la majorité du temps ces images sont stockées dans un registre privé, hébergé chez un Cloud Provider. Des services tels que Container Registry chez GCP ou AWS ECR (Elastic Container Registry) vous permettent de stocker vos images Docker moyennant un coût. Les tarifications varient d’un Cloud Provider à un autre, mais en ce qui concerne le stockage, on se situe autour des 0,026$ (par GO par mois) du côté de GCP et 0,10$ du côté d’AWS. Le transfert de données entrantes est gratuit mais en sortie les coûts sont très variables selon les use cases, voici ci-joint les grilles tarifaires d’AWS et GCP pour plus de détails :
Vous l’avez donc compris, stocker une image Docker n’est pas gratuit, certes les tarifs sont peu onéreux mais la facture peut assez vite grimper si on n’optimise pas la taille de nos images. De plus, on peut gagner en performance en réduisant les temps de build de vos images, ainsi que votre productivité. Par exemple, si demain quelqu’un doit charger l’image Docker que vous avez poussée mais que celle-ci fait 3GB et que sa connexion n’est pas performante, cela peut s’avérer être très long. La réduire à 300MB divisera par 10 le chargement de l’image en question, plutôt pratique vous en conviendrez.
Un autre exemple de l'impact de la taille d'une image : dans le cloud, lorsqu'on veut gérer de l'élasticité, si on souhaite être réactif à une montée en charge, le temps de téléchargement de l'image est à prendre en compte. Dès lors, une taille d'image optimisée est nécessaire si l'on souhaite bénéficier d'une telle fonctionnalité.
Un peu de contexte
Avant de rentrer dans le vif du sujet, j’aimerais apporter quelques éléments de contexte. Lors d’une mission sur une plateforme Data à laquelle j’ai pris part, nous n’appliquions pas les bonnes pratiques que je vais vous présenter sur Docker. Une quantité colossale d’images s’accumulait dans notre Container Registry et celles-ci pouvaient peser plusieurs Giga octets alors qu’elles ne servaient qu’à exécuter un code Python très basique.
Ce manque d’optimisation entraînait également une surcharge de travail au niveau de notre CI/CD. Les capacités de notre Jenkins étant limitées, lorsqu’il fallait build des images très lourdes, cela pouvait créer une file d’attente des builds et donc ralentir tout notre processus de livraison.
Lorsque je faisais mes tests en local sur ma machine, je me suis rendu compte de ce manque d’optimisation. J’ai constaté que les images qu’on créait étaient aussi lourdes, je me suis donc demandé comment optimiser mes images à tous les niveaux afin d’améliorer nos processus, économiser du temps et de l’argent. Cette démarche s’inscrit bien évidemment dans le Green IT car oui, en économisant de l’espace de stockage, on limite indirectement notre empreinte carbone et nos émissions de gaz à effet de serre.
Je vous propose donc une liste non exhaustive mais suffisamment détaillée qui vous permettra d’optimiser vos images Docker (et sans en affecter le fonctionnement).
Nous prendrons l’exemple d’images Python (car c’était mon cas d’usage) mais sachez que la majorité de ces conseils s’appliquent aux autres langages de programmation.
Partez d’une base légère !
Théoriquement, lorsque vous souhaitez créer une image exécutant du code Python, la première étape de votre Dockerfile est d’importer une image Python comme base. Et c’est exactement cette étape qui peut alourdir fortement votre image. Démonstration !
Attention, petit disclaimer concernant les versions “alpine” qui vont être utilisées. Je ne recommande pas de les utiliser dans un environnement de production de manière générale, à moins de bien en comprendre le fonctionnement.
Je vais importer 3 images Python : la python:3.9.11, la python:3.9.11-slim et la python:3.9.11-alpine. Je prends le soin de rajouter le mot clé “time” en début de commande pour afficher le temps d’exécution de la commande que je lance.
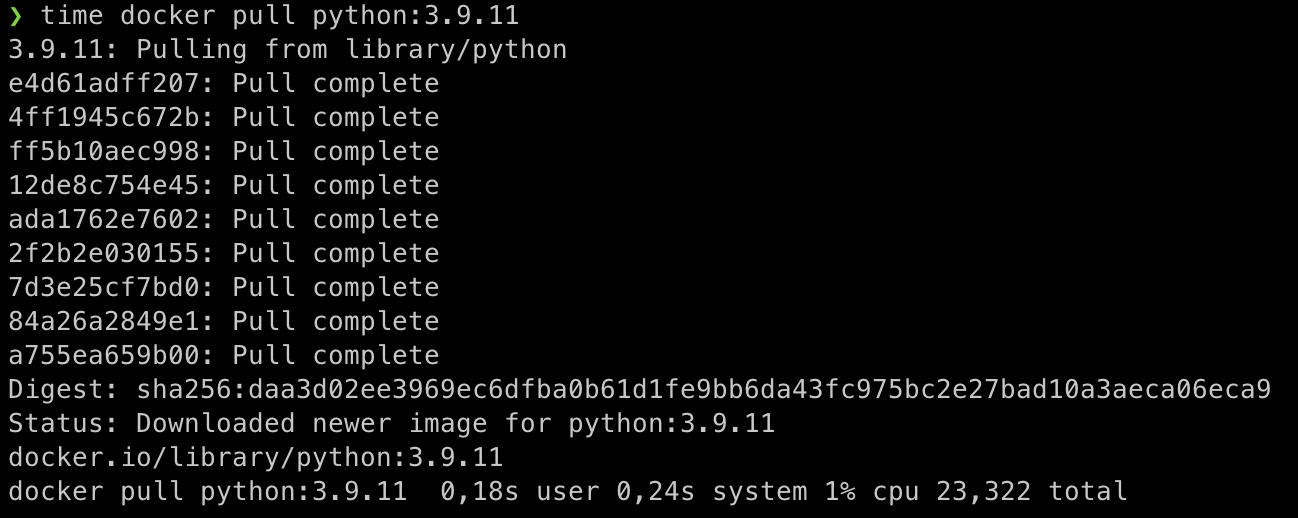
Première image téléchargée (la python:3.9.11) et le temps de chargement de l’image est de 23,32 secondes. Retenez bien la durée !

6,49 secondes pour sa petite sœur (la python:3.9.11-slim), performance honorable !
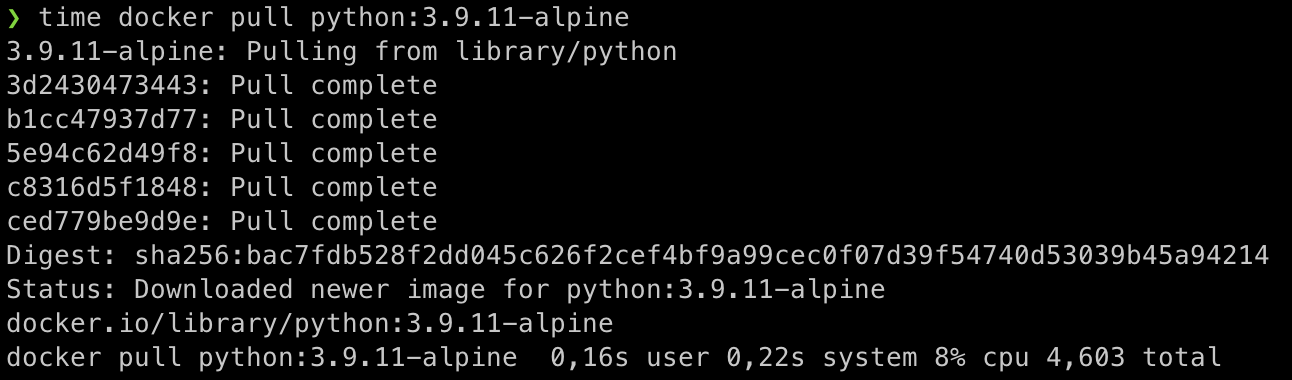
Et enfin, 4,6 secondes pour notre dernière version : la python:3.9.11-alpine.
Nous pouvons donc en conclure que l’image complète Python est 3,5 fois plus longue à télécharger que la version slim et 5 fois plus que la version alpine.
Mais ce n’est pas tout, voyons ce que tout cela donne en termes d’espace de stockage occupé par ces images.

Inutile de débattre, le constat est sans appel. L’image complète de Python est 7 fois plus lourde que la version slim et 19 fois plus que la version alpine. Cela était prévisible, la taille des images impacte directement le temps de chargement, donc pas de surprise à ce niveau.
Vous avez donc compris qu’il est préférable d’utiliser les versions slim ou alpine des images que vous allez télécharger. Mais cela n’est pas exempt de tout compromis.
La version slim ne contient que les packages minimaux nécessaires pour exécuter du code Python. Attention, selon la nature de votre code et des packages nécessaires à son exécution, il est possible que vous rencontriez des erreurs (parfois inexplicables) lors de vos builds. Dans cette situation, n’hésitez pas à tester avec l’image Python complète, si cela fait disparaître vos erreurs alors cela provient sûrement de la version slim de l’image Python.
En ce qui concerne la version alpine, elle a été spécifiquement construite pour être utilisée dans des conteneurs. Nous l’avons vu, sa taille très réduite est idéale et présente bien des intérêts. Mais attention, comme pour la version slim, beaucoup de packages ne seront pas installés nativement sur l’image. Ce sera donc à vous de les installer manuellement si vous en avez besoin. Reste à vous de juger si partir d’une base très réduite, quitte à installer des packages supplémentaires, est bénéfique pour votre projet.
À noter que pour installer des packages, vous ne devrez plus utiliser la commande “apt-get” mais “apk” lorsque vous utilisez une version alpine.
Éviter les millefeuilles
Bien que le millefeuille soit l’une de mes pâtisseries préférées, avec Docker il faut les éviter.
Je ne reviendrai pas sur le concept des Layers (“couches” en français mais c’est beaucoup moins sexy) sur Docker, mais il est important de comprendre que chaque layer vient rallonger le temps d’exécution de votre image ainsi qu’augmenter l’espace de stockage occupé.
Dans un Dockerfile, il existe 3 instructions qui créent de nouveaux layers : FROM, RUN et COPY. Pour éviter de créer des layers inutiles, il faut minimiser le nombre d’appels de ces instructions. Cela passe par l’utilisation de l’option “&&” afin de combiner différentes commandes en une seule instruction.
Voici un exemple très simple d’utilisation de l’option && pour réduire notre nombre de layers, vous remarquerez que j’utilise le backslash / en bout de ligne afin que le code reste lisible. N’oubliez pas de supprimer le cache apt après l’installation de package avec une commande apt-get via la commande suivante : sudo apt-get clean.
Extrait du Dockerfile initial, ici 2 layers sont créés :

Extrait du Dockerfile “amélioré”, seulement 1 layer sera créé :

N’hésitez pas à utiliser cette option avec toutes vos commandes RUN et COPY afin de réduire le nombre de layers créés. Et nous allons justement voir que ces layers jouent un rôle bien plus important qu’on ne le croit !
Jouons à cache-cache !
Après quelques heures d’utilisation de Docker, vous devriez vous rendre compte d’une chose : on rebuild très souvent les mêmes images avec très peu de modifications d’un build à l’autre. C’est à ce moment précis qu’intervient le cache : il permet d’enregistrer localement les layers existants afin de les réutiliser s’ils ne sont pas modifiés lors des prochains builds. Attention, si un layer est modifié, le cache ne sera pas utilisé pour le layer en question mais également pour tous les layers suivants. Par exemple, si vous lancez le build d’un Dockerfile avec 4 layers, puis que vous modifiez uniquement le layer 2 et que vous relancez à nouveau le build : les layers 2, 3 et 4 seront reconstruites à nouveau sans utilisation du cache, bien que les layers 3 et 4 n’aient pas changé. Dans cet exemple, seul le layer 1 profite de la puissance du cache et gagne en temps de chargement.
L’ordre des layers est donc très important lors de l’utilisation du cache, vous devez donc veiller à ce que l’ordre de vos layers soit bien réfléchi à l’avance. Placez en premier les instructions susceptibles de ne pas changer et en dernier, les instructions qui risquent de varier d’un build à l’autre. Par exemple, pensez à placer l'installation des dépendances et des packages communs à toutes vos images avant de copier votre code source. Le code source étant amené à être modifié d’un build à l’autre, le layer responsable de sa copie doit être placé après les installations récurrentes afin de conserver celles-ci en cache.
L’ignorance a parfois du bon !
Si vous êtes familiers du développement en général, vous devez connaître le fameux fichier .gitignore permettant d’ignorer les fichiers locaux indésirables lors d’un push vers un dépôt Git distant.
Et bien figurez-vous qu’il existe exactement le même fichier avec Docker : le .dockerignore. Le fonctionnement est exactement le même, vous n’avez qu’à inscrire les noms de dossier(s) ou fichier(s) que vous ne voulez pas copier vers votre image Docker et ceux-ci seront ignorés lors de la copie. Très pratique lorsqu’on fait un “COPY . .” sans vouloir lister explicitement chaque fichier à charger !
Garder seulement l’essentiel
Toujours dans notre optique d’optimiser nos images Docker, vous devez toujours garder en tête la chose suivante : tout ce qui n’est pas essentiel au fonctionnement de mon programme n’a pas sa place dans mon image.
Cela commence par une première bonne pratique : ne stockez pas de données dans votre image. Si votre application est bien structurée, vous ne devriez pas vous retrouver avec des fichiers de données dans votre image. Stockez votre donnée ailleurs, dans les volumes par exemple, qui sont faits pour stocker la donnée en dehors de votre image.
Ensuite, pensez à ajouter quelques options supplémentaires lors de vos installations de packages afin de vous affranchir des dépendances inutiles. Voici une liste (non exhaustive) de flags à ajouter à vos commandes récurrentes :
RUN apt-get install –no-install-recommends package_à_installerRUN apk add --no-cache package_à_installer(si vous utilisez une version alpine)RUN pip3 install --no-cache-dir -r requirements.txt
Bonus
Pour finir, voici un outil facultatif mais qui peut s’avérer très utile. Il vous permettra d’être sûr de ne pas passer à côté d’une optimisation ou une bonne pratique sur votre Dockerfile, je vous recommande le site : fromlatest.io.
Le fonctionnement est tout simple, vous n’avez qu’à copier-coller le contenu de votre Dockerfile dans l’interface et le site vous fait une liste de recommandations à suivre pour améliorer votre fichier. Cela se présente sous cette forme :

À gauche, vous avez votre Dockerfile, et à droite la liste des recommandations triées par ordre d’importance (bugs possibles, optimisations, clarté du code, etc.).
Conclusion
Si vous êtes familiers avec Docker, alors vous serez sans doute étonnés que je n’aborde pas les Multistage Builds (“build à plusieurs étages” en français). Ici, l’objectif était de vous donner des clés rapides et simples à mettre en place pour optimiser vos images Docker. J’ai donc volontairement omis de vous expliquer son fonctionnement, mais cela fera sûrement l’objet d’un article dédié. Normalement, avec ces différentes optimisations vous êtes capables de réduire considérablement la taille de vos images et d’optimiser les temps de chargement de celles-ci. Votre utilisation de Docker s’en trouvera donc moins coûteuse et vous serez bien plus productif !
Je peux vous l’affirmer par expérience, ces optimisations m’ont permis de désengorger ma CI / CD via la réduction des temps de construction des images Docker utilisées lors de ma mission. Les modifications qui ont été apportées étaient certes très simples et peu coûteuses à mettre en place, et pourtant elles ont parfois divisé par 10 la taille de certaines images, sans en altérer le fonctionnement.