

La lecture de cet article se fera sous trois axes qui permettront de répondre aux questions suivantes. Quelle architecture mettre en place sur AWS pour faire du calcul distribué en full serverless ? Quelles sont les limitations que l’on peut rencontrer et leur contournement ? Et enfin, comment rendre son architecture résiliente et tolérante aux fautes ?
Qu’est-ce que le calcul distribué et les scénarios possibles ?
Définition
En informatique, le calcul distribué est une méthode de programmation consistant à découper un calcul en plusieurs blocs exécutables en parallèle en général sur plusieurs machines.
Son antonyme est le calcul séquentiel qui est une méthode de programmation consistant cette fois à exécuter les blocs d'un calcul les uns après les autres sur la même machine.
Au niveau de la théorie, le temps global du calcul peut être découpé en deux :
- le temps de calcul (temps de traitement d’un bloc)
- le temps de communication (partage des résultats de chaque bloc)
Plus un calcul est distribué plus son temps de calcul tend vers 0 mais son temps de communication tend vers l’infini. Dans ce cas, il faut générer beaucoup de messages entre des machines qui peuvent être parfois très éloignées physiquement. On retrouve donc l’inverse pour le calcul séquentiel qui s’exécute généralement dans le même processus sur la même machine, par conséquent le temps de communication est proche de zéro mais le temps de calcul tend vers l’infini.
Après avoir exposé la théorie, nous allons mieux comprendre les avantages du calcul distribué via différents scénarios d’exemples.
Les scénarios possibles
En tant qu’ingénieur data, nous ne sommes pas uniquement confrontés à de gros calculs mathématiques, le calcul distribué est également intéressant pour de nombreux autres cas d’usage. Un scénario que l’on retrouve régulièrement est le traitement de fichier.
Par exemple, on souhaite découper et traiter 100 000 fichiers CSV avant de venir insérer leurs données dans une base de données. Le traitement d’un fichier nécessite en moyenne trois secondes avec un écart type faible. En séquentiel, c'est-à-dire en bouclant sur l’ensemble des fichiers, il faudrait donc 100 000 x 3 secondes soit 83h pour traiter l’ensemble. Cette solution, coûteuse en temps, peut donc ne pas convenir. D’ailleurs, elle est loin d'être optimale face à la programmation concurrente couplée aux possibilités d'infrastructure facilement scalable et serverless qu'offre le cloud.
En distribuant le traitement de chaque fichier, dans un système parfait, nous pourrions passer d’un temps global de traitement de 83 h à trois secondes (ou plus exactement le temps de traitement du plus long fichier à traiter).
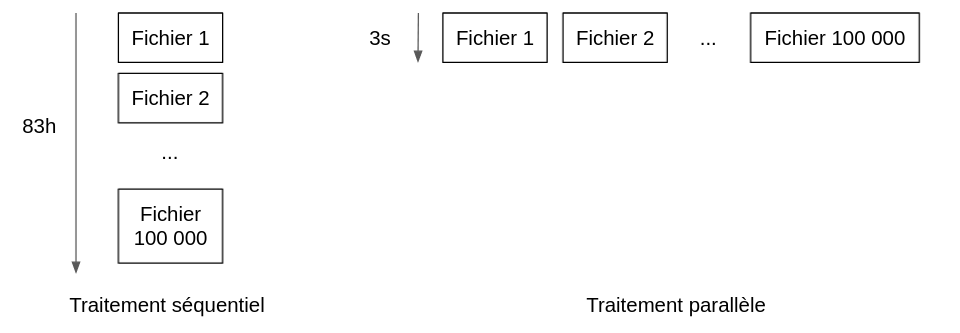
En référence à la section précédente, on comprend pourquoi en calcul distribué le temps de calcul tend vers zéro mais on a oublié ici le temps de communication. On ne pourra jamais atteindre seulement trois secondes dans la réalité, il faut prendre en compte le temps de lancement de traitement de chaque fichier, le temps de récupération des réponses et éventuellement l’agrégation des résultats. De plus, ce ne sont généralement pas les seules limitations à prendre en compte : il faut également penser aux limites de quotas des outils utilisés comme le nombre maximum d'exécutions concurrentes ou des limitations d’appels d’APIs par exemple.
Le cloud et les services AWS à utiliser
Au travers de cet article, nous allons proposer une solution d’architecture ayant pour but de répondre au scénario précédent, c'est-à-dire permettant le traitement en parallèle de 100 000 fichiers.
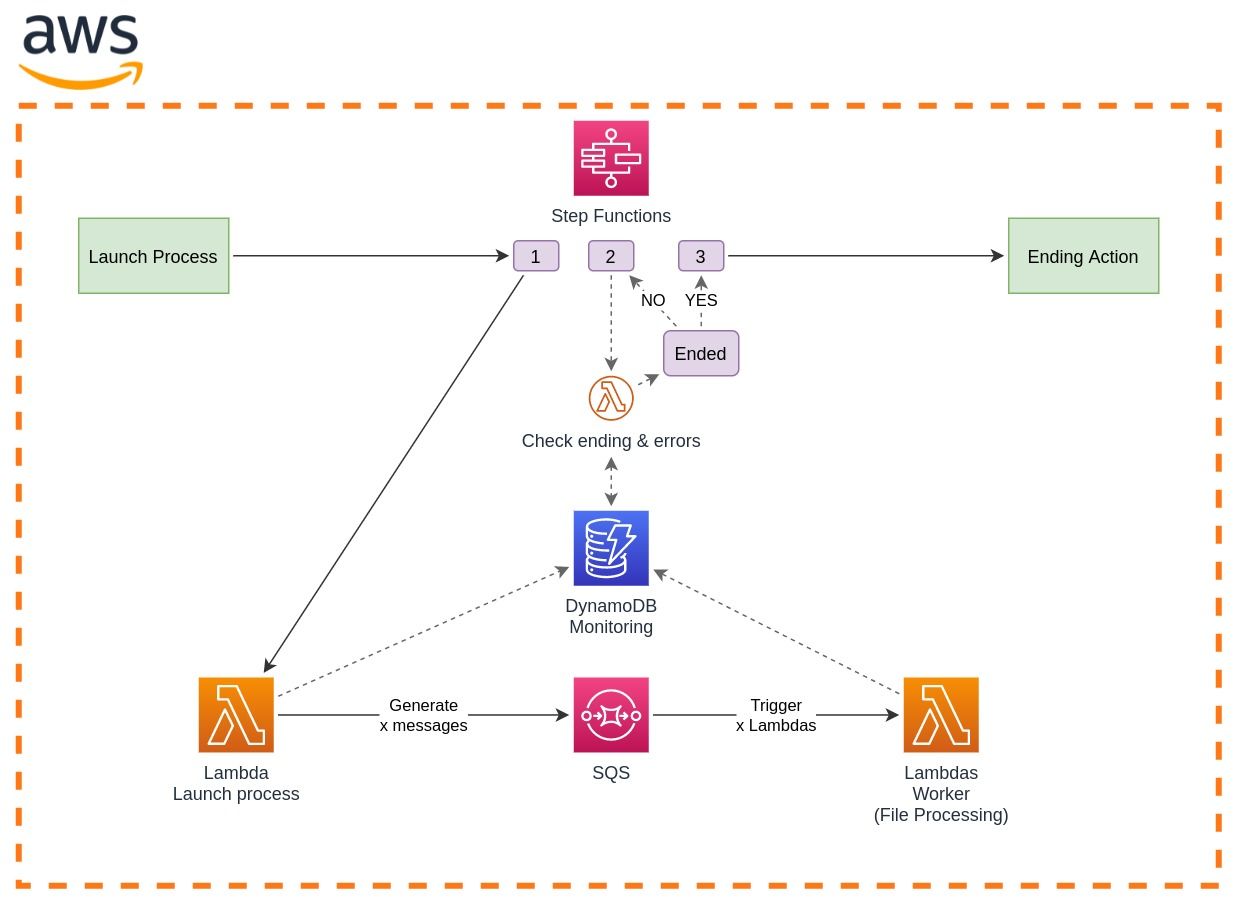
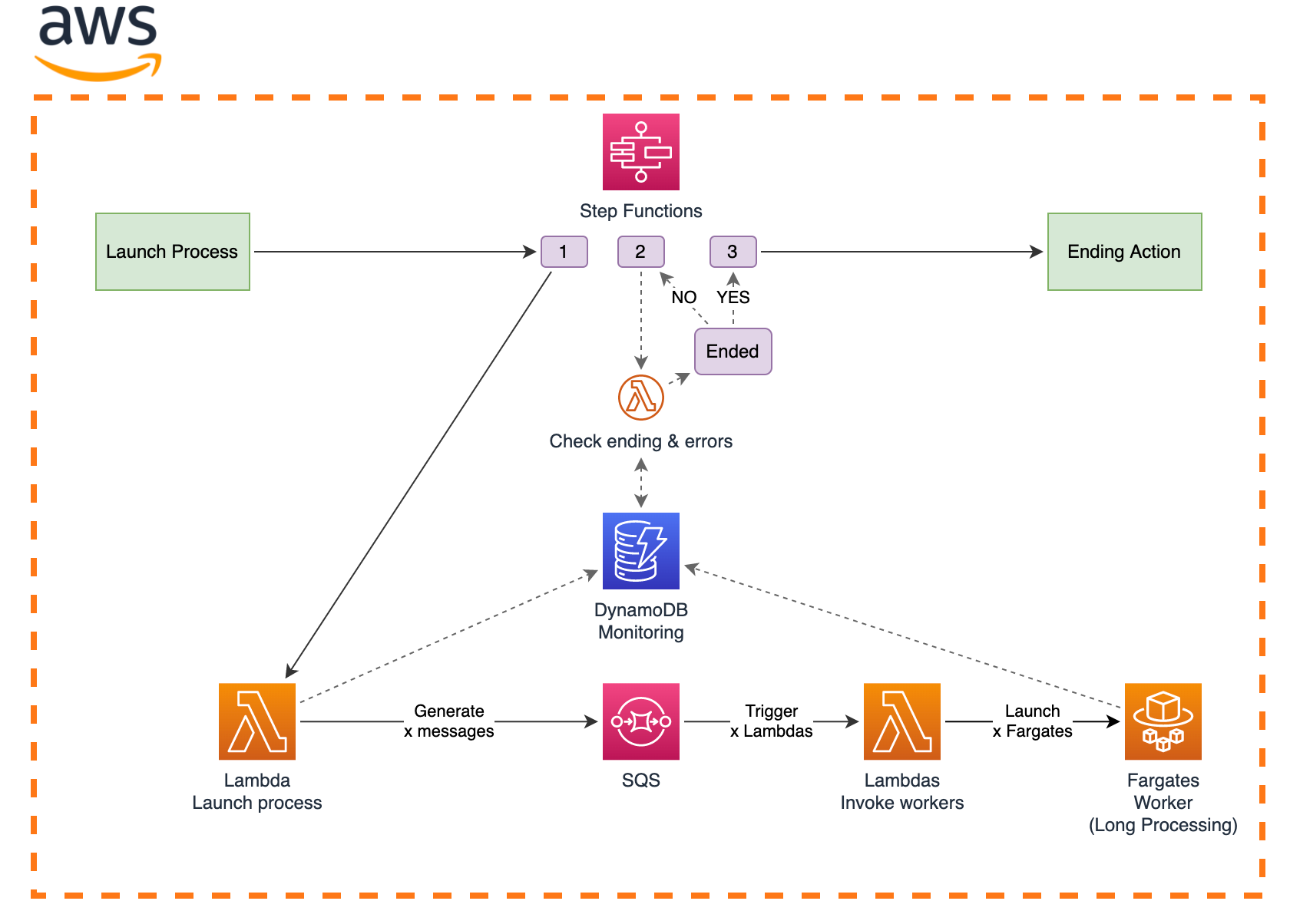
Schéma de l’architecture
Composants utilisés
AWS Lambda est un service d’exécution de code en mode serverless. C’est-à-dire que AWS se charge de gérer les ressources de calcul et du programme qui va exécuter le code en fonction du langage de programmation choisi. La limite d’exécution d’une fonction est fixée à 15 minutes. Les Lambdas sont plutôt prévues pour réaliser des petites actions.
Amazon SQS est un service de file d’attente de messages entièrement géré par AWS. SQS propose deux types de files d'attente de messages : les files d'attente standard (débit maximum et minimum 1 apparition des messages) et les files d'attente FIFO (apparition des messages garantis dans l’ordre).
Une file d’attente peut également être configurée comme une file d'attente de lettres mortes (Dead Letter Queue) pour recevoir les messages qui n’ont pas pu être traités.
AWS Step Functions est un orchestrateur serverless. AWS gère le passage d’un état à un autre et seules ces transitions sont facturées. Chaque état permet de réaliser une action telle qu’appeler un autre service AWS par exemple.
Amazon DynamoDB est un service serverless de base de données NoSQL de type documents et clé-valeur.
Amazon S3 n’est pas représenté dans le schéma mais il va servir au stockage des fichiers à traiter. En effet, il s’agit d’un service de stockage d'objets offrant performance, disponibilité et sécurité des données.
Si vous souhaitez avoir plus de renseignements sur ces services, n’hésitez pas à consulter leur documentation officielle.
Explication de l’architecture
L’ensemble du process est orchestré par AWS Step Functions.
L’état 1 consiste à invoquer une fonction Lambda qui se charge de faire l’inventaire des fichiers à traiter. Pour ce faire, la fonction va écrire pour chaque fichier un item dans une table DynamoDB. La clé de partition sera un id de run, cela permet de faire de l’historisation tout en gardant de bonnes performances en lecture et des coûts réduits. La clé de tri sera l’URI S3 du fichier à traiter c’est-à-dire son emplacement dans un bucket S3 et enfin un autre sous-attribut sera le statut (“NotProcessed” à l’initialisation).
L’image ci-après est un exemple de la table au moment de l’initialisation.
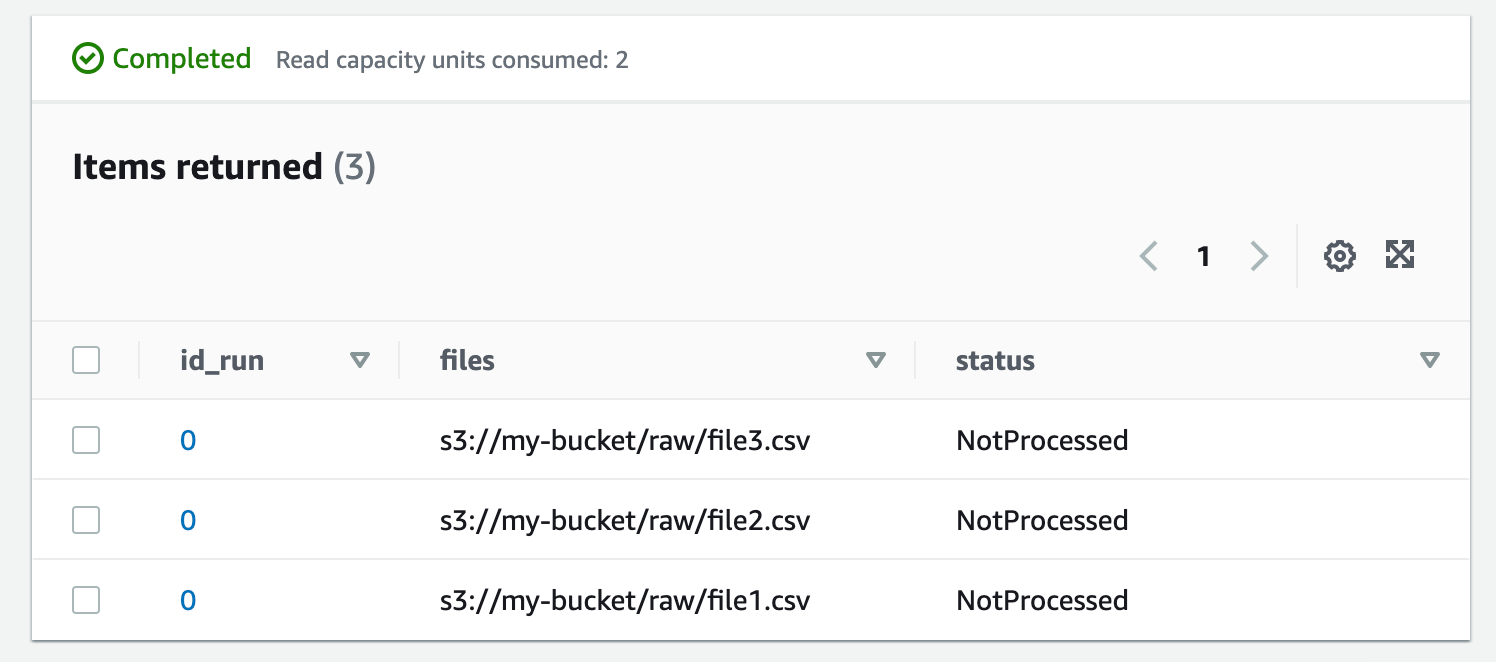
On le verra par la suite, cette table va avoir plusieurs fonctions essentielles. La Lambda va ensuite créer un message par fichier dans une file d’attente SQS et chaque message va contenir son URI de ressource S3. Cette étape va donc servir à générer 100 000 messages SQS.
Ensuite, la file d’attente SQS est configurée de manière à être automatiquement consultée par une autre fonction Lambda que l’on appellera “worker”. Un processus interne à Lambda va venir « pull » les messages disponibles et invoquer une fonction par message. Chaque exécution de la fonction “worker” va ensuite traiter son fichier (celui spécifié dans le message). Avant la fin de l'exécution, la fonction Lambda met à jour la table DynamoDB avec le statut du fichier traité.
L’état 2 consiste à contrôler la fin du processus. La Step Function invoque une fonction Lambda qui va se baser sur la table DynamoDB pour déterminer si chaque fichier a pu être traité en réalisant une query sur l’id de run et un filtre sur les statuts. Si pour chaque fichier, nous avons un statut de succès ou d’erreur, c’est que le processus est terminé. Selon la réponse de la Lambda, la Step Function devra : soit attendre avant de rappeler à nouveau la Lambda (c’est que le process n'est pas terminé), soit passer à l'état suivant après avoir reçu une réponse de terminaison.
L’état 3 s’occupera de lancer certaines actions supplémentaires en fonction du cas d’usage telles que le lancement de jobs de vérification, l'envoi de notifications ou encore le lancement d'un autre processus avant la fin d'exécution de la Step Function.
Supervision du traitement
Dans cette partie nous allons faire un zoom au niveau de l’état 2 de la Step Function et revenir sur la détection de terminaison du processus. En effet, qui dit processus asynchrone dit difficulté à en connaître la fin. Pour rappel, un processus asynchrone est un processus qui lance l’exécution de plusieurs tâches en parallèle sans attendre une réponse de ces dernières. Nous pourrions regarder s’il reste des messages dans la queue SQS. Pour ce faire nous devrions utiliser le SDK AWS et récupérer les attributs suivant : ApproximateNumberOfMessages, ApproximateNumberOfMessagesDelayed, ApproximateNumberOfMessagesNotVisible. Juste par le nom des attributs qui nous sont disponibles, on se doute de la faible fiabilité de cette idée. On pourrait également essayer de voir si des fonctions Lambda sont toujours en cours d’exécution mais ce n’est pas possible ou alors avec un retard d’au moins une minute en utilisant l’API Cloudwatch.
De plus, aucune de ces deux solutions n'apporterait une réponse pour remonter les erreurs jusqu’à la Step Functions. C’est important que la Step Function ait connaissance de ces erreurs afin qu’elle puisse s'arrêter si le succès de cette étape est nécessaire pour la suite et surtout informer les équipes techniques.
L’ajout de la base de données DynamoDB dans l’architecture est donc essentiel pour deux raisons : la détection de fin du traitement et la détection des erreurs.
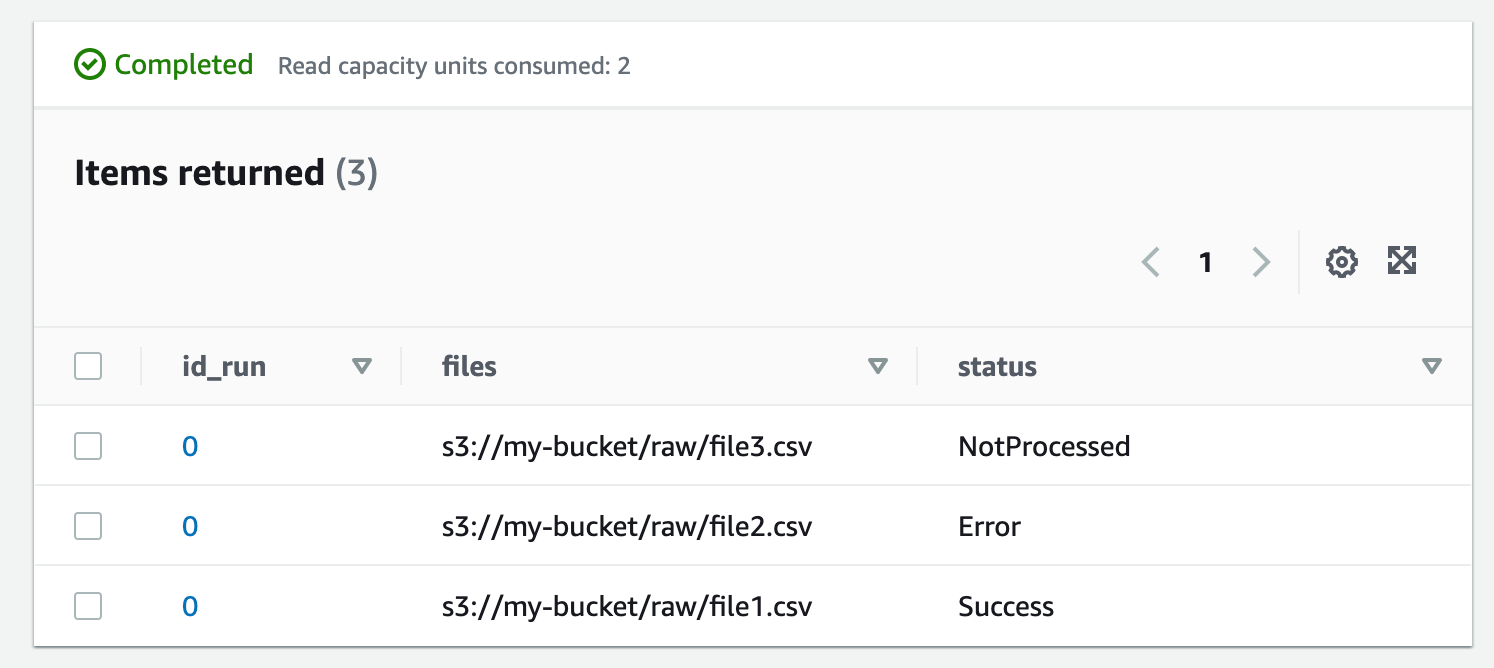
Une table DynamoDB remplie de cette façon nous apprendrait qu’il y a eu une erreur lors du traitement du fichier 2 et que le fichier 3 est toujours en cours de traitement.
Résilience de l’architecture
La résilience de l’architecture se fait grâce au paramétrage d’une file d’attente de lettre morte (Dead Letter Queue). Les messages sont consommés par Lambda et deviennent invisibles pendant leur traitement. Si les fonctions se terminent sans erreur alors les messages sont automatiquement supprimés de la file d’attente. Dans le cas contraire, une fois que le temps paramétré dans le champ “Visibility timeout” est écoulé, les messages reviennent dans la file d’attente et ils se trouvent alors à nouveau disponible pour réaliser une autre tentative de traitement par de nouvelles exécutions Lambda.
Ce mécanisme peut se produire plusieurs fois en fonction du nombre paramétré dans le champ “Maximum Receives”. Supposons que ce nombre est de 3, alors la troisième fois que les messages réapparaissent ils ne seront pas visibles dans la file d’attente principale mais dans une seconde file d’attente appelée file d’attente de lettre morte. Des solutions peuvent ensuite être mises en place pour faire remonter les erreurs. Sur un projet, nous avons fait le choix d’avoir une autre Lambda qui traite les messages de cette file d’attente de lettre de morte afin de mettre à jour la table dynamoDB avec le statut d’erreur pour les fichiers qui n’ont pas pu être traités.
Mise en place de l’architecture et des bons paramètres Lambda
L’objectif de cette partie est de voir comment distribuer le plus possible le traitement tout en ayant une tolérance maximale des erreurs et des limites de quotas.
Remarque, on peut penser que la limite de 1000 exécutions concurrentes est la plus impactante dans l’architecture mais ce n’est pas nécessairement le cas. Tout dépend également du traitement qu’effectue chaque exécution Lambda. Si chaque Lambda effectue de multiples lectures ou écritures vers un bucket S3, on pourrait potentiellement atteindre les limites de l’API de S3 avant. C’est d’autant plus vrai avec des APIs externes qui ont des quotas généralement bien plus faibles.
Détection des limitations par l’expérience
Après lecture de la documentation d’AWS nous avons repéré les deux limitations principales suivantes : un maximum de 1000 invocations concurrentes de Lambda sur un même compte et un temps d’exécution maximal d’une Lambda de 15 min.
Nous avons également mis de côté certains paramètres principaux que l’on peut adapter : limiter le nombre de fichiers par run, le nombre de fichiers que peut traiter 1 lambda (Batch size), le nombre de fois que les messages SQS réapparaissent, et le temps de génération des messages.
Afin de proposer les meilleures réponses et optimisations possibles, nous allons réaliser l’expérience suivante : simuler le traitement de 15 000 fichiers avec un temps de traitement de 2 mins pour chaque fichier.
Les paramètres de la SQS :
- nombre de messages envoyés : 15 000 en 68s
- Visibility timeout : 10 mins
- Delivery Delay : 0s
- Maximum receives : 1 (Cela signifie que si le message réapparaît, alors il ira directement dans la dead letter queue)
Les paramètres de la Lambda “worker” :
- code : sleep de 2 mins
- Batch size : 1 (1 message = 1 lambda)
- Batch window : 0
Voici les tableaux de bord de supervision obtenus :
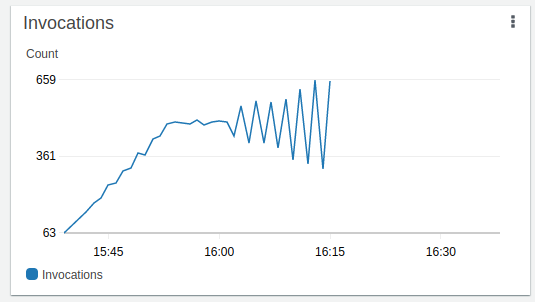
Cette vue est très intéressante, elle nous permet d'observer le fonctionnement de polling de messages fait par Lambda sur la queue SQS. La documentation nous dit que Lambda fait du “long polling” sur la file d’attente jusqu’à ce que des messages apparaissent. Lorsque c’est le cas, Lambda lit jusqu’à 5 lots de messages et invoque une fonction par lot. Si des messages sont toujours disponibles, Lambda augmente la capacité de lecture de lots de messages de 60 par minute (jusqu’à une certaine limite).
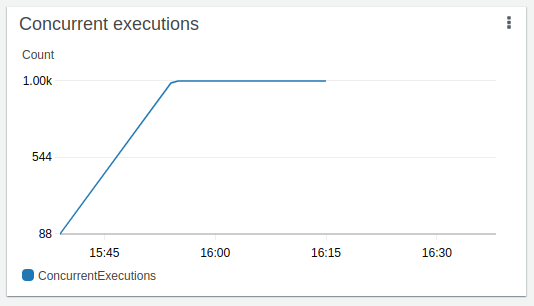
En mettant en corrélation ce graphe avec le précédent, évidemment, plus le moteur de polling de messages de lambda lit des messages, plus le nombre d'exécutions concurrentes augmente. Il est toutefois intéressant de constater qu’il faille une dizaine de minutes pour atteindre le maximum de 1 000.
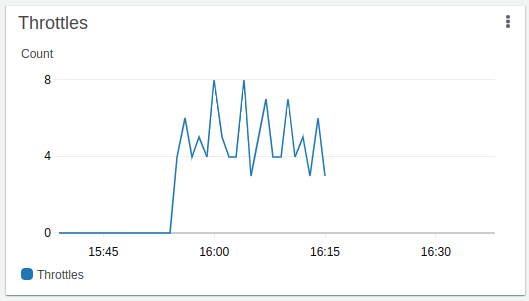
Lorsque l’on atteint le maximum de 1 000 exécutions de lambda concurrentes, nous commençons à constater quelques “throttles”, c’est-à-dire des messages qui ont été consommés mais qui n’ont pas pu être traités car il n’était plus possible d’invoquer de nouvelles lambdas.
Nous avons atteint le maximum de lambdas concurrentes vers 15h55 et la fin de l'exécution a eu lieu à 16h15. On remarque que le nombre de lambda “throttle” ne semble pas si important.
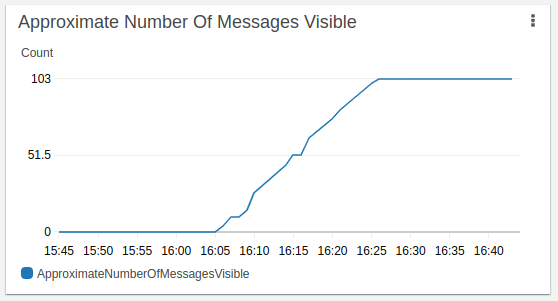
Apparition des messages dans la Dead Letter Queue
Lorsque les lambdas sont “throttles”, les messages partent ensuite dans la file d’attente de lettre morte. Pour rappel, on a paramétré la file d’attente avec le paramètre “Maximum Receives” a 1.
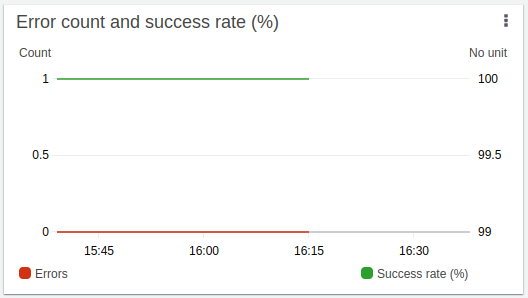
Cette dernière vue peut sembler surprenante, en effet, elle nous indique qu’il y a eu 100 % de succès de Lambda et 0 échec alors qu’il y a eu 103 messages qui n’ont pas pu être traités. On suppose donc que lorsqu’une Lambda est “throttle”, elle n’influe pas sur la statistique de succès et d’échec, cette information est donc primordiale à garder en tête lorsque l’on supervise son infrastructure !
En se basant sur ces résultats, lorsque l’on fait des traitements distribués avec une architecture AWS Lambda et SQS, il est possible d’atteindre la limite d'exécution concurrente de Lambda en fonction du nombre de messages et du temps de traitement.
Cette limite d’exécution concurrente peut être abaissée en fonction de vos besoins en remplissant le champ “Reserve concurrency” mais le risque de “Throttles” sera plus important. Les idées présentées dans la suite de l’article vous seront donc d’autant plus utiles.
Comment éviter le “throttle” de fonctions Lambda ?
1. Le temps de traitement d’un fichier
Bien que très rapide, le pulling de message et l'invocation de Lambda prend un certain temps, donc globalement quelque soit le nombre de fichiers à traiter si individuellement le temps de traitement d’un fichier est inférieur à quelques secondes alors il y aura toujours des Lambdas disponibles.
Dit autrement, plus le traitement d’un fichier est rapide, plus il y aura de ressources disponibles et plus l’ensemble sera rapide.
Il est donc important d’optimiser le code et les algorithmes utilisés. Si vous faites de la transformation de données, pensez à la vectorisation.
Une autre solution pour augmenter la rapidité de vos fonctions Lambdas est d’augmenter la mémoire. Bien souvent oublié, ce mécanisme permet aussi d’augmenter le CPU.
Enfin, un temps de traitement faible permet de s’assurer qu’aucune Lambda ne dépassera les 15 minutes possibles, avant d’être arrêtée par un timeout.
2. Le nombre de fichiers (ou le nombre de noeuds à calculer)
C’est le point le plus direct, si vous avez seulement quelques milliers de fichiers à traiter avec un temps de traitement court, il n’y aura pas de problème particulier dû au temps que met le polling de message à scaler. L’objectif est dans ce cas de mettre des paramètres optimums qui permettent de traiter l’ensemble le plus rapidement possible.
3. Le nombre de fichiers que peut traiter 1 Lambda
On peut aussi adapter son code pour qu’une fonction lambda invoquée traite plusieurs messages. Avec notre scénario, cette solution dépend toutefois de l'hypothèse de départ suivante : le temps de traitement d’un fichier est faible, connu et stable. Il faut, en effet, éviter de tomber dans le timeout de lambda de 15 minutes.
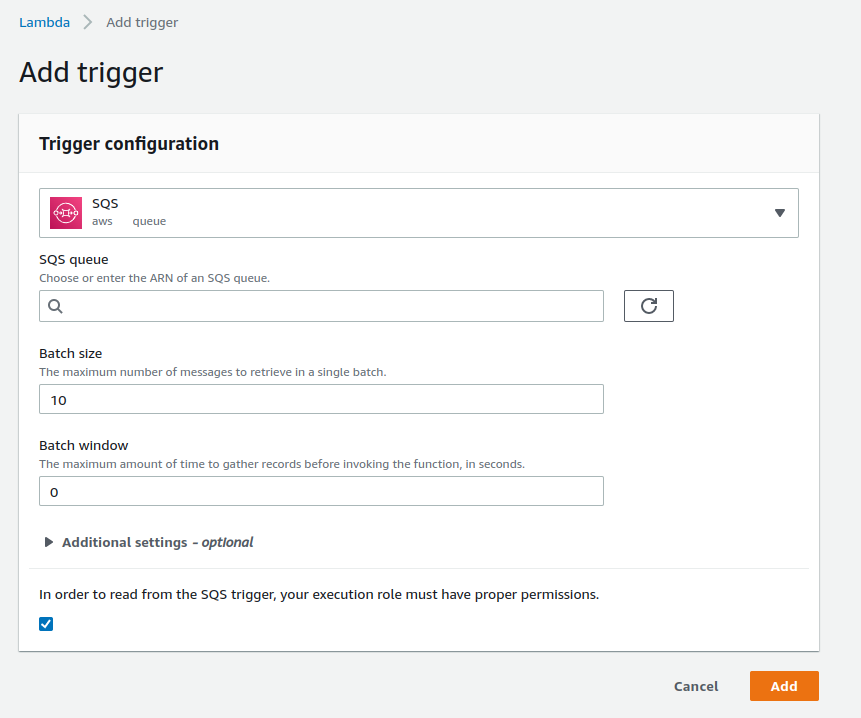
Dans ce cas, lorsque vous ajoutez votre SQS dans les réglages de votre Lambda, deux paramètres s’offrent à vous :
- Batch size : entre 1 et 10 000 (messages) (Standard) ; entre 1 et 10 en FIFO
- Batch windows : entre 0 et 300 (secondes) ; pas compatible en FIFO
Par exemple avec un batch size de 1000 il vous faudra seulement 1000 fonctions Lambdas pour traiter 1 million de messages.
Il est toutefois important de faire attention que dans un lot, par défaut, les messages sont en succès ensemble ou en erreur ensemble. Si le traitement de neuf messages se passe sans problème mais qu’une erreur survient au dixième alors la Lambda échoue et l’ensemble des messages sera à nouveau disponible alors qu’une partie a déjà été traitée.
Depuis la mise à jour de décembre 2021, il est possible de spécifier les messages en échec, cette section de la documentation vous indique la démarche à suivre.
4. Le délai de génération des messages
Supposons que l’on ait besoin de générer un million de messages. Une solution très simple consisterait à utiliser une tâche Fargate pour la génération des messages et de mettre un “sleep” correspondant au temps moyen de traitement tous les 1000 fichiers.
Une autre idée que vous pourriez avoir consisterait à modifier le temps d’invisibilité des messages lors de leur envoi dans la file d’attente afin qu’ils n’apparaissent pas tous en même temps. Ce paramètre, appelé “delay-seconds” si on utilise le client AWS, prend des valeurs entre 0 et 15 mins. La valeur maximale n’est pas très loin des 10 minutes nécessaires pour arriver à saturation des pulls, de ce fait nous ne recommandons pas cette solution.
Toutefois si dans le futur ce paramètre était amené à évoluer avec des valeurs plus grandes acceptées alors cela pourrait être une bonne solution.
5. Dead Letter queue & nombre maximum de réception
Avoir des lambdas qui “Throttles” n’est pas la fin du monde, il faut juste faire en sorte que les messages non traités réapparaissent dans la file d’attente, ce qui est d’ailleurs le comportement par défaut lorsque l’on ne paramètre pas de file d’attente de lettre morte (Dead Letter Queue). Ce n’est toutefois pas recommandé car en cas d’erreurs répétées l’architecture tournerait en rond sans jamais se terminer.
Il faut donc paramétrer une Dead Letter Queue qui recevra les messages n’ayant pas pu être traité après un certain nombre de tentatives. Celui-ci est paramétrable avec l’item “Maximum receives” qui prend une valeur entre 1 et 1 000.
Lorsqu’un message est lu, celui-ci devient invisible pendant un certain temps avant de réapparaître. Les recommandations d’AWS sur le sujet sont assez larges, elles stipulent que le temps d’invisibilité d’un message doit être supérieur à 3x le timeout d’une Lambda pour éviter qu’un message soit consommé par une lambda plusieurs fois.
Adaptation de l’architecture pour des calculs plus long
Dans le cas où le besoin nécessite de longs traitements supérieurs à 10 mins alors l’architecture peut être adaptée en ajoutant des conteneurs Fargate. L’appel des lambdas n’est qu’un passe-plat qui invoque des conteneurs Fargate. Cela permet de garder l’architecture très résiliente avec la possibilité que les messages aient plusieurs tentatives en cas d’erreurs avec SQS et de superviser l’architecture avec DynamoDB.
Une autre architecture possible avec des Fargate est celle-ci : Design Pattern for Highly Parallel Compute: Recursive Scaling with Amazon SQS | AWS Architecture Blog (proposée sur le blog d’AWS). Elle est particulièrement intéressante en cas d’apparition de messages en continu dans la SQS.
Limitation et alternative
Pour des cas d’usage avec un nombre faible de fichiers à traiter, cette proposition d’architecture n’est pas être pas la plus recommandée, elle nécessite un certain nombre de ressources AWS. Elle peut être réalisée plus simplement en utilisant la fonctionnalité Map state de AWS Step Fonction. Cette fonctionnalité permet de paralléliser une action mais est limitée au nombre maximum de 25 milles événements que peut faire AWS Step Function.
Dans le cas où les données nécessitent de grosses transformations et que Spark semble adapté, il peut être intéressant d’utiliser le service AWS Glue.
Coût très faible de l’architecture
La step function est gratuite ou presque gratuite, AWS offre 4 000 états tous les mois. Relativement similaire pour la file d’attente SQS : par mois, le premier million de messages est gratuit puis il faut compter 0,40 $ par million de messages.
Pour la DynamoDB, il faut compter un peu moins de 1 $ par exécution complète.
Le service Lambda propose une offre gratuite qui inclut 1 million d’invocation de fonction par mois et 400 000 Go-secondes de temps de calcul par mois.
Dans notre scénario de 100 000 fichiers (avec un temps de traitement moyen de trois secondes par fichier), en allouant 640 MB de mémoire par Lambda, on consomme un peu moins de 200 000 Go-secondes. Par conséquent, nous pouvons lancer 2 fois le traitement complet des fichiers gratuitement grâce à l’offre gratuite de AWS tous les mois.
Il ne reste plus qu’à compter les coûts de stockage s3. Comme nous sommes amenés à écrire plusieurs fois les données, 100 Go sur un mois coûte 2,3$ et l’écriture de deux fois 100 000 fichiers coûte 1$. Le coût de lecture est négligeable, environ 0,10$.
Enfin, si l’on souhaite chiffrer ses données, il faut rajouter 1,2$ pour 2 lectures et écritures avec KMS.
En dehors de l’offre gratuite, chaque lancement coûterait environ 5 à 6$ USD.
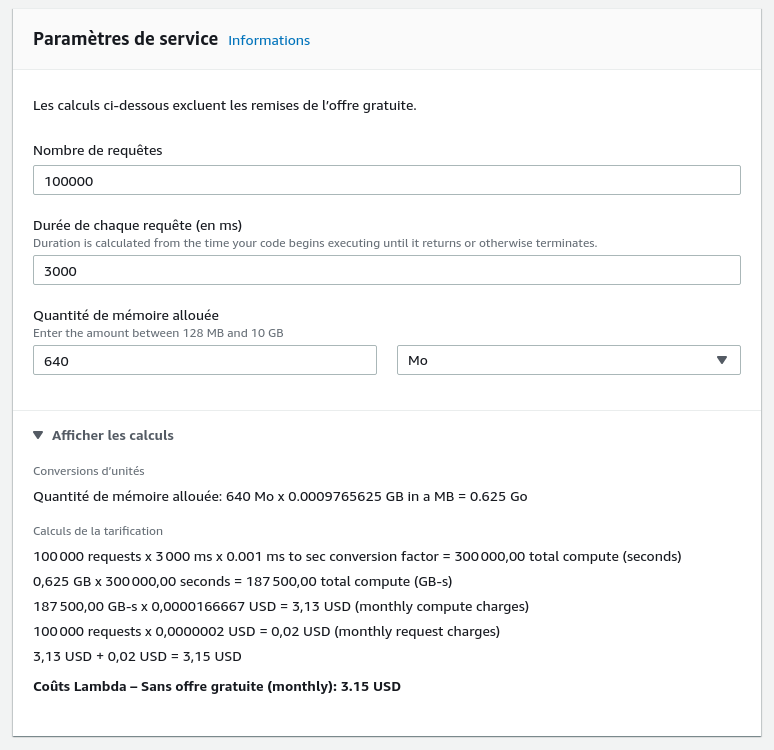
Ainsi, cette architecture ne coûte que quelques dollars à chaque exécution complète.
Conclusion
Au terme de cet article, vous savez comment créer une architecture de traitement distribué très simple, hautement résiliente et à moindre coût sur AWS.
Pour l’avoir utilisée dans plusieurs projets, nous trouvons qu’elle fonctionne bien pour des cas simples et évite le recours à des frameworks parfois complexes ou des outils plus coûteux.
