
dbt (Data Build Tool) est un outil qui permet de transformer les données directement dans un data warehouse de manière efficace. Il ne permet pas d'extraire ou de charger des données, mais il est utile pour transformer les données déjà chargées dans votre entrepôt de données, il est donc le T dans l’approche ELT (Extract - Load - Transform).
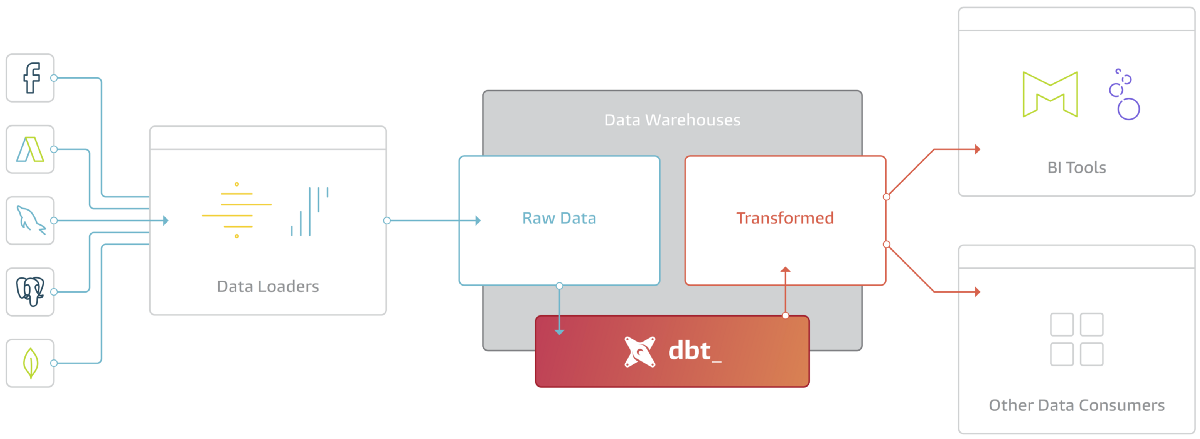
Son fonctionnement est simple, dbt prend du code (pouvant être construit à partir d’un moteur de templates : Jinja et de SQL), le compile en SQL, et l'exécute sur votre base de données.
De plus, dbt permet de mettre en place de bonnes pratiques qui rapproche le code SQL du développement logiciel :
- le versionning de code SQL
- Le changement d’environnements (dev, pre-prod, prod)
- L’utilisation de macros pour simplifier la lecture et la maintenance du code
- L’utilisation de variables lors du lancement des requêtes
- Génération automatique de documentation
- Programmation automatique de l’exécution des requêtes (version payante)
- Tester son code
L’objectif de cet article est de présenter en détails le dernier aspect de ces bonnes pratiques, à savoir, les tests unitaires et les tests d’intégrations.
Si vous souhaitez découvrir en quoi consiste un projet dbt ou pourquoi l’adopter, vous pouvez consulter l’article d’Arnaud Col sur notre Blog : Découvrez DBT.
Pré-requis
Certains concepts importants sont à connaître afin de comprendre comment effectuer les tests dans dbt.
Structure
La structure d’un projet dbt doit être assez précise. On peut initialiser cette structure en utilisant la commande dbt init ce qui va créer automatiquement les éléments suivants :
- analysis
- data
- macros
- models
- snapshots
- tests
- un fichier dbt_projet.yml pré-configuré
Si l’on désire changer le nom d’un dossier, il faudra aussi le changer dans ce fichier afin que dbt puisse le reconnaître. Pour plus de détails sur cette mise en place ou sur l’utilisation de ces dossiers, vous pouvez vous référer à l’article d’Arnaud Col sur notre Blog : Découvrez DBT.
Modèles
Premièrement, un objet (table, vue, …) créé à l’aide d’un script dbt s'appellera un modèle et il aura le nom mon_modele si le fichier le créant s’appelle mon_modele.sql.
Sources
Dans dbt, les sources sont les tables déjà présentes dans le data warehouse, issues d’un outil d’extraction et de chargement.
En les spécifiant dans un fichier .yml (voir exemple dans Script 1), dans le répertoire models cela permettra de :
- Nommer, décrire et tester les données externes
- D’utiliser la macro jinja {{ source() }} qui aidera à définir le lineage (Directed Acyclic Graph représentant comment les modèles sont créés) pour la documentation.
version: 2
sources:
- name: schemaA
tables:
- name: tableA1
description: Description table
- name: tableA2
columns:
- name: col1
description: Description col1
tests:
- not_null
- unique
- name: schemaB
tables:
- name: tableB1Pour plus de détails, vous pouvez vous référer à la doc.
Références
La macro {{ ref() }} est certainement la fonctionnalité la plus importante de dbt. Elle permet de découper une requête compliquée en plusieurs modèles plus simples en isolant les différents domaines fonctionnels. Ceci permet de grandement faciliter la maintenance de ces requêtes.
En pratique, cette macro permet de faire référence à un modèle depuis un autre tout en permettant à dbt de créer automatiquement le graph de dépendances. Ceci permettra à dbt de déployer les modèles dans le bon ordre lors d’un appel à dbt run et de compléter le lineage de la documentation.
Exemple :
model_a.sql
SELECT *
FROM {{ source('schemaA', 'tableA1') }}model_b.sql
SELECT *
FROM {{ ref('model_a') }}Pour plus de détails, vous pouvez vous référer à la doc.
Seeds
Dans dbt, les seeds sont des fichiers .csv dans votre projet (généralement dans le dossier data) qui peuvent être directement chargés dans le data warehouse en utilisant la commande dbt seed --select filename.csv .
Ces fichiers sont utilisés pour des données statiques qui ne changent pas souvent, et peuvent être utilisés dans des modèles en utilisant la macro {{ ref() }}.
Maîtrisez vos modèles avec les tests
En dbt, les tests sont des affirmations que l’on fait sur nos modèles et nos sources. Cela permet d’être plus sûr de ce que l’on fait et aussi de vérifier que nos nouveaux modèles n’impactent pas ceux qui existent déjà, ce qui est souvent compliqué et fastidieux en analytique.
Une bonne pratique est de faire tourner ces tests à chaque fois que l’on veut faire une Pull Request dans un pipeline CI (Continuous Integration).
Pour ce faire, il suffit de faire un job (enchaînement de commandes dbt) faisant les étapes suivantes :
- On met à jour les seed servant aux tests : dbt seed --full-refresh --select tests.*
- On met à jour les modèles : dbt run --full-refresh
- On fait passer tous les tests : dbt test
Pour ceux utilisant dbt Cloud, cet article détaille les étapes à réaliser pour intégrer un job de CI facilement.
Tests unitaires : tests génériques
Lors de la création d’un nouveau modèle, c’est une bonne pratique de renseigner un fichier .yml dans le dossier models (similaire au fichier .yml de la partie Sources). Script 4 présente un exemple model_name.yml. dbt s’appuie sur ce fichier pour alimenter la documentation quand on la génère avec la commande dbt docs generate . De plus, la partie tests va permettre de tester des colonnes spécifiques pour un modèle donné. Une fois ces tests renseignés, il suffit d’utiliser la commande : dbt test -m model_name.
version: 2
models:
- name: model_name
description: Description model
columns:
- name: col1
description: Description col1
tests:
- unique
- not_null
- name: col2
tests:
- accepted_values:
values: ['val1', 'val2']dbt vous propose des tests génériques déjà implémentés (notamment not_null, unique, accepted_values et relationships) mais vous pouvez très bien implémenter les vôtres. Pour ce faire, il faut en fait écrire une macro dans le dossier prévu à cet effet, et préfixer le nom du fichier par test_ suivi du nom du test. On peut ajouter des arguments, mais il faut au moins :
- model : obligatoire, c’est la ressource sur laquelle on va appliquer le test
- column_name : La colonne sur laquelle le test est défini (si le test s’applique au niveau de la colonne)
Le Script 5 présente un test de positivité : test_is_positive.sql
{% test is_positive(model, column_name) %}
WITH validation AS (
SELECT
{{ column_name }} AS positive_field
FROM {{ model }}
),
validation_errors AS (
SELECT
positive_field
FROM validation
WHERE positive_field <= 0
)
SELECT count(*)
FROM validation_errors
{% endtest %}Pour passer un test, il faut que la sortie de ce dernier soit 0 ou qu’il ne renvoie aucune ligne. Le Script 5 compte le nombre de lignes ayant column_name inférieur ou égale à 0. Si cela retourne autre chose que 0, le test échouera.
Une fois écrit, il suffit d’utiliser ce test directement dans le .yml du modèle comme vu précédemment dans le Script 4.
Petit plus : on peut vouloir ne pas faire échouer le test, mais simplement lever un avertissement. Pour cela, il suffit de modifier la configuration du test en ajoutant la ligne suivante dans la définition de la macro vu dans Script 5 :
{{ config(severity = 'warn') }}Tests unitaires : tests sur mesure
Pour des cas plus spécifiques, les tests génériques ne suffisent pas. En fait, la manière la plus simple de définir un test est d’écrire la requête SQL qui renverra les lignes défaillantes. Il suffira d’ajouter autant de fichiers .sql que l’on veut de tests dans le dossier tests et d’y écrire le SELECT approprié.
Le Script 6 présente un exemple de test sur mesure. Celui-ci consiste à vérifier le pourcentage de l’ensemble des ingrédients pour chaque recette.
SELECT
RECETTE,
SUM(INGREDIENTS) AS TOTAL
FROM {{ ref('ingredients_recettes') }}
GROUP BY RECETTE
HAVING TOTAL != 100Ces tests permettent par exemple d’insérer de la logique métier directement dans les tests afin de faire une première étape de validation de la qualité des données issues de nos modèles.
Tests d’intégrations
Ces tests permettent de maîtriser le comportement d’un modèle de manière isolée mais aussi faisant partie d’un tout. Ils sont proches des tests end-to-end, l’idée étant de contrôler les entrées de notre modèle en connaissant sa sortie et donc de vérifier que la transformation fait exactement ce que l’on veut.
Prenons l’exemple suivant :

La Table1 se base sur la SourceA et la Table2 sur la Table1. Lors de la CI, nous aimerions avoir le comportement suivant :
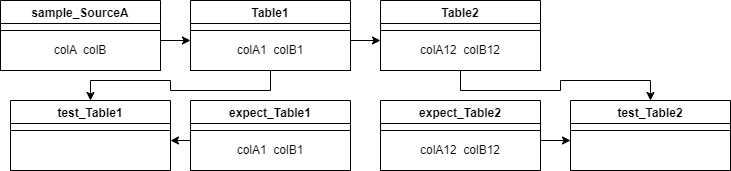
Les tests_Table sont en fait des tests sur mesure comme vu précédemment. Ils vont comparer les sorties des modèles avec ce que l’on attendait et retourner une erreur s'ils ne contiennent pas la même chose. Plus précisément, nous allons faire un HASH de chaque ligne de la table créée et vérifier qu’ils se trouvent dans les HASH de la table attendue. Il faut absolument forcer le type de chaque colonne afin de comparer des objets du même type :
{% set columns_to_compare = 'COLA1::STRING, COLB1::INTEGER' %}
SELECT
*,
HASH(columns_to_compare) AS H
FROM {{ ref('Table1') }}
WHERE
H NOT IN (SELECT HASH(columns_to_compare)
FROM {{ ref('expect_Table1') }} )Comme dit précédemment, nous voulons ce comportement uniquement lors de la CI. C’est là que la magie de jinja intervient. À chaque job on peut attribuer différents paramètres tels que le nom de la cible (target.name) et s’en servir afin de compiler différemment le code SQL suivant ces paramètres. Il suffit d’écrire une macro mockable_source qui permet de faire ceci et de l’utiliser à la place de source :
{% macro mockable_source(schema_name, table_name, mocked_source) %}
{% if target.name == 'CI' %}
{{ ref(mocked_source} }}
{% else %}
{{ source(schema_name, table_name) }}
{% endif %}
{% endtest %}suivant l’environnement d'exécution
La mise en place des tests d’intégrations se déroule donc en plusieurs étapes :
- Imitation (mocking) de la/les source(s). Il s’agit de prendre un sous-ensemble de celle-ci (un sample) avec lequel nous allons pouvoir tester notre modèle, une recette parmi d'autres par exemple. Ensuite, il suffit de sélectionner à l’aide d’une requête la ou les lignes correspondant à cette recette dans la ou les tables sources. Par soucis de lisibilité et de compréhension, on place tous ces fichiers dans un dossier data/samples et on les préfixe tel que : sample_source_name.csv. Enfin, on lance la commande dbt seed –select sample_source_name afin de pouvoir les utiliser.
- Une fois toutes les sources mockés, il faut faire tourner le modèle en s’assurant qu’il se base sur ces sources mockés (en rajoutant or target.name == 'dev' dans la macro mockable_source par exemple) et utiliser la commande dbt –full-refresh -m model_name. Nous contrôlons une première fois à la main le résultat obtenu et si celui-ci est cohérent nous prenons la sortie de ce modèle afin de le placer dans un fichier expect_model_name.csv, placé dans un dossier data/expects. Il faudra lancer la même commande qu’en 1. afin de l’utiliser.
- Quand tout cela est fait, il ne reste plus qu’à écrire le test sur mesure vu dans le Script 7 et vérifier que ce dernier ne retourne rien.
NB : Lors de la création des samples et des expects, il faut faire attention à certains types de données. Ces fichiers sont des .csv et il est très compliqué de comprendre les listes et les JSON. Nous conseillons de les convertir en STRING afin de simplifier leur utilisation. Certaines fois, cela nécessitera l’ajout de la fonction PARSE_JSON afin de pouvoir lire ces champs.
Conclusion
L’utilisation de dbt permet de grandement faciliter le versioning et l’implémentation de requêtes SQL tout en amenant des bonnes pratiques de développement logiciel. De plus, la mise en place des différents tests vu dans cet article permet de réduire le temps de vérification et de qualité des données issues d’analyses parfois complexes.
En effet d’un côté, les tests unitaires, qu’ils soient génériques ou sur mesure permettent de vérifier la qualité des données et peuvent ajouter des règles métiers précises. D’un autre côté, la mise en place de tests d’intégration permet de s’assurer que le développement d’un nouveau modèle n'impacte pas ce qui existe déjà.