
Comme vous le savez certainement, la sécurité des données est un enjeu majeur dans une plateforme de données. Si cette plateforme a besoin de stocker des données personnelles et/ou sensibles, comme par exemple, des données de ressources humaines, de paie, de santé ou plus simplement des adresses postales, des noms et des prénoms, il va falloir protéger ces données au niveau du stockage (par le chiffrement) mais aussi lors de l’utilisation de ces données.
Snowflake est devenu un nouvel acteur important sur le marché des plateformes de données. Aujourd’hui nous allons parler de cette plateforme et plus précisément d’une fonctionnalité importante pour la sécurité : le masquage dynamique des données.
Ce masquage des données est proposé depuis peu nativement dans certains data warehouses (comme Azure SQL Data Warehouse) et permet d’éviter des solutions de contournement onéreuses en temps et en coût. Sans ce masquage, il aurait fallu soit avoir un jeu de données anonymisé (faisable, mais couvrir tous les cas possibles peut être compliqué), soit concevoir une API qui masque ces données (ce qui coûte du temps et de l’argent). Car oui, le masquage dynamique des données est intégré dans Snowflake sans surcoût.
Snowflake dispose d’un masquage dynamique des données (dynamic data masking dans la langue de Kendrick Lamar) qui offre la possibilité via des politiques de masquage (masking policy) de transformer ou non les données dans les colonnes de nos tables, en fonction de conditions définies au préalable par le responsable de sécurité. Ce masquage est qualifié de “dynamique” car les données sont masquées au moment de la consultation par la masking policy associée.
Ce masquage permet de rajouter une couche de sécurité, d’utiliser et de manipuler ces données sans pour autant en révéler le contenu. C’est ce que nous allons découvrir ensemble aujourd’hui !
Qu’est-ce donc qu’une masking policy ?
Une masking policy est une fonction qui applique ou non une transformation sur les données d’une colonne lors d’une requête sur la table. Cela permet de ne pas modifier les données dans la table mais seulement lors de la lecture de la table, de manière transparente pour l’utilisateur.
Une masking policy est un objet défini par trois éléments :
- un type de données : une masking policy ne peut fonctionner que sur un seul type de données et il doit être le même en entrée et en sortie ;
- une ou des conditions de masquage : ces conditions déterminent quand la fonction de masquage s’applique, pour quel utilisateur, rôle ou compte. Il est possible d’utiliser les fonctions contextuelles de Snowflake. Par exemple, il est possible de récupérer le rôle effectuant une requête sur la table ;
- une ou des fonctions de masquage : les fonctions vont transformer les données lorsque les conditions de masquage ne sont pas remplies. Il est possible d'utiliser des UDF et toutes les fonctions de Snowflake possible (comme REGEXP_REPLACE par exemple).
Prenons un exemple :
La requête suivante crée une masking policy nommée mask_salaire qui ne peut être utilisée que sur des NUMBER.
create masking policy mask_salaire as (val number) returns number ->
case
when current_role() in ('RH') then val
else 1000
end;Une masking policy peut être appliquée sur une ou plusieurs colonnes et cela, sur une ou plusieurs tables et/ou vues. Ainsi, le mask_salaire présenté plus haut peut être appliqué sur toutes les tables et vues qui contiennent une colonne SALAIRE ou assimilé, de type NUMBER.
Nous appliquons le mask_salaire sur notre table EMPLOYE comme ceci :
alter table if exists EMPLOYE modify column SALAIRE set masking policy mask_salaire;Si le rôle utilisé pour l’exécution des requêtes (le résultat de la fonction contextuelle current_role()) n’est pas RH, les valeurs de la colonne SALAIRE seront remplacées par 1000, sinon elles ne seront pas modifiées.
Exemple de résultat avec :
- à gauche, le résultat d'une lecture avec le rôle RH
- à droite, le résultat d'une lecture sans le rôle RH
| NOM | PRENOM | SALAIRE | NOM | PRENOM | SALAIRE |
|---|---|---|---|---|---|
| Balkany | Patrick | 1000000 | Balkany | Patrick | 1000 |
| Poutou | Philippe | 2000 | Poutou | Philippe | 1000 |
Que se passe-t-il lors d’une requête ?
Les masking policies sont prioritaires sur les autres opérations, pour garantir la sécurité des données. Ce qui veut dire que, dans notre exemple, une requête qui fait une somme sur la colonne SALAIRE, donnera une valeur différente en fonction du rôle appelant.
Résultat de la requête "select sum(SALAIRE) as SALAIRE from EMPLOYE;" avec le rôle RH (à gauche) et sans le rôle RH (à droite) :
| SALAIRE | SALAIRE |
|---|---|
| 1002000 | 2000 |
Il est aussi possible d’avoir des masking policies imbriquées. Par exemple, si nous avons une masking policy sur une table et une masking policy sur une vue de cette même table, une requête sur la vue déclenche la masking policy sur la table puis celle sur la vue. Le diagramme suivant illustre cette hiérarchie des masking policies :
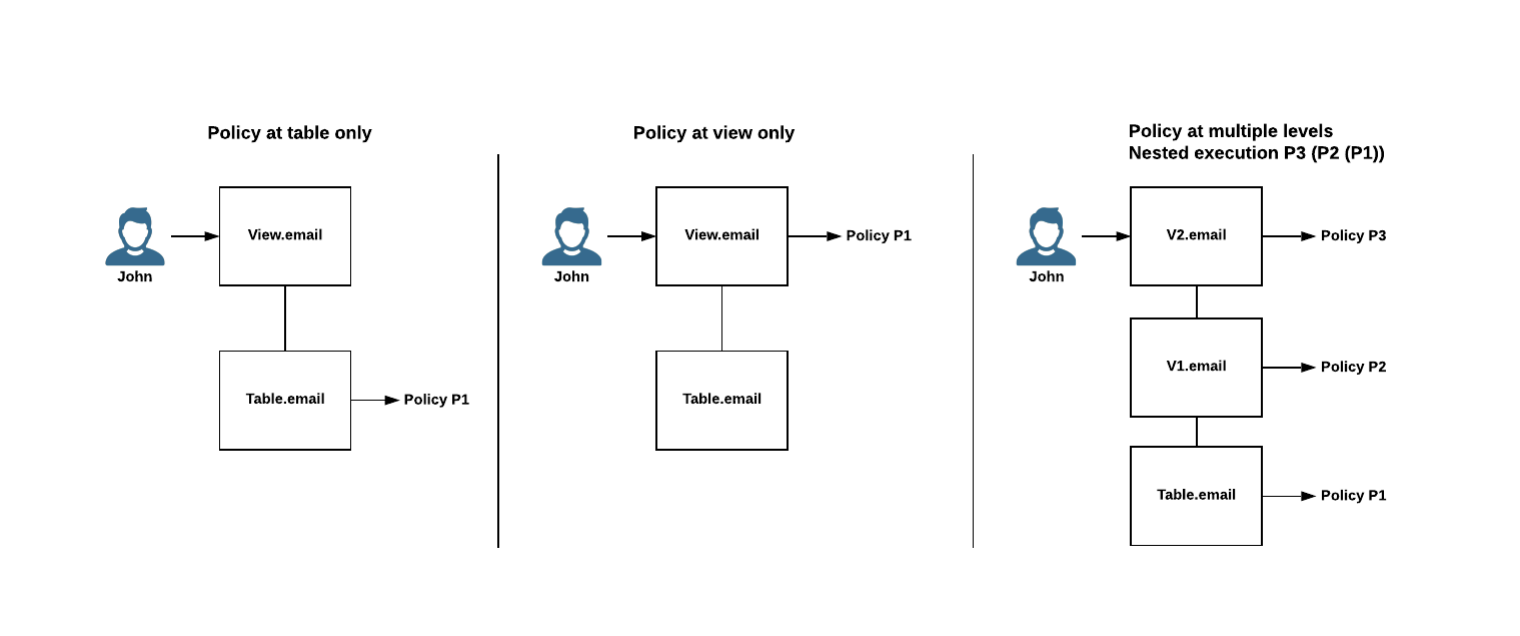
Très bien, maintenant que nous avons la théorie, regardons comment cela se passe en pratique !
Mise en place des masking policies
Prenons un exemple : nous avons sur notre plateforme de données, deux tables :
- EMPLOYE : cette table contient trois colonnes : NOM, PRENOM et SALAIRE
- PRIME : cette table contient trois colonnes : ID_EMPLOYE, SALAIRE, PRIME
Nous avons deux types d’utilisateurs : les développeurs et les ressources humaines. Les ressources humaines doivent accéder aux données en clair et les données doivent être masquées pour les développeurs.
Ici, nous avons deux groupes d’utilisateurs que nous pouvons regrouper sous deux rôles différents : DEVELOPPEUR et RH. Nous allons nous servir de ces rôles pour nos masking policies.
Les masking policies doivent :
- Pour la colonne SALAIRE : remplacer la valeur numérique par 1000 si le rôle n’est pas RH
- Pour la colonne NOM : montrer la première lettre suivie de 4 X si le rôle n’est pas RH
Tout d’abord, la bonne pratique Snowflake est de créer un rôle qui gère les masking policies (dans notre cas, masking_admin). Ce rôle a deux droits : un droit de création de masking policies et un droit d’application des masking policies sur les tables. Il a aussi les droits en lecture sur les tables qui ont des données à masquer.
En SQL, cela donne :
-- Role Snowflake par défaut qui gère les rôles et les users
use role SECURITYADMIN;
-- Création du rôle
create role masking_admin;
-- Deux droits sont donnés au rôle
grant create masking policy on schema <schema qui contiendra les masking policies> to role masking_admin;
grant APPLY masking policy on account to role masking_admin;
-- Droits de lecture sur la base, les schémas et les tables
grant usage on database <ma base> to role masking_admin;
grant usage on all schemas in database <ma base> to role masking_admin;
grant select on all tables in database <ma base> to role masking_admin;Nous voyons que le droit de création de masking policy (CREATE MASKING POLICY) s'applique sur un schéma en particulier. C’est normal car dans Snowflake, les masking policies sont des objets qui sont stockés dans des schémas. A la différence du droit d’application des masking policies qui est un droit au niveau du compte Snowflake.
Maintenant, nous allons pouvoir créer nos masking policies !
create or replace masking policy mask_salaire as (val number) returns number ->
case
when current_role() in ('RH') then val
else 1000
end;
create or replace masking policy mask_nom as (val string) returns string ->
case
when current_role() in ('RH') then val
else regexp_replace(val, '^([\\w]).+', '\\1XXXX')
end;Les conditions de masquage sont les mêmes : si le rôle courant (le rôle qui lance les requêtes) n’est pas RH, nous masquons les données.
Dans la première masking policy, nous remplaçons la valeur originale par 1000 et dans la deuxième, nous utilisons la méthode REGEXP_REPLACE. Cette méthode prend en entrée : la valeur à modifier (VAL), une regex et une chaîne de caractères de remplacement. Ici, la regex capture la première lettre de VAL et ignore le reste. La chaîne de remplacement récupère la première lettre capturée par la regex et ajoute 4 ‘X’ derrière.
La dernière étape est d’attacher les masking policies sur les colonnes à masquer.
use role masking_admin;
alter table if exists "EMPLOYE" modify column NOM set masking policy mask_nom;
alter table if exists "EMPLOYE" modify column SALAIRE set masking policy mask_salaire;
alter table if exists "PRIME" modify column SALAIRE set masking policy mask_salaire;Attacher une masking policy à une colonne est une requête ALTER TABLE sur la colonne à masquer. Ici nous attachons les masking policies aux colonnes que nous voulons masquer : les colonnes NOM et SALAIRE de la table EMPLOYE et la colonne SALAIRE de la table PRIME.
Désormais, lorsqu’un utilisateur avec le rôle RH requêtera la table il verra les données en clair. Les autres utilisateurs, par contre, verront des données transformées, comme suit.




Tadaa ! Nous avons sécurisé nos données sensibles avec des masking policies, tout en gardant l’avantage de pouvoir travailler sur les tables. Nous avons autorisé uniquement le rôle RH à accéder aux données réelles. C’est une sécurité forte qui convient parfaitement aux données sensibles et/ou des données à protéger dans le cadre de la RGPD.
Gestion avancée des droits
Dans les masking policies, il est possible de faire ce que l’on veut dans les conditions de masquage. Il est tout à fait possible de reléguer la gestion des accès aux données dans une table et d’utiliser une condition d’existence dans la masking policy pour autoriser ou non l’accès aux données. Je m’explique.
Si nous déplaçons la gestion des accès dans une table, comme celle-ci :
create table "ENTITLEMENT" ( "MASK" VARCHAR, "GRANTED_ON" VARCHAR, "EXPIRATION_DATE" DATE);
insert into "ENTITLEMENT" ("MASK", "GRANTED_ON", "EXPIRATION_DATE") values ('mask_nom', 'RH', NULL);
insert into "ENTITLEMENT" ("MASK", "GRANTED_ON", "EXPIRATION_DATE") values ('mask_salaire', 'RH', NULL);
Il suffit de changer la condition de masquage de nos masking policies, comme ceci :
create or replace masking policy mask_nom AS (val string) returns string ->
case
when exists
(select granted_on
from "ENTITLEMENT"
where mask = 'mask_nom'
and granted_on = current_role()
and (expiration_date is null or expiration_date > current_date()))
then val
else regexp_replace(val, '^([\\w]).+', '\\1XXXX')
end;
create or replace masking policy mask_salaire AS (val string) returns string ->
case
when exists
(select granted_on
from "ENTITLEMENT"
where mask = 'mask_salaire'
and granted_on = current_role()
and (expiration_date is null or expiration_date > current_date()))
then val
else 1000
end;pour pouvoir gérer finement les accès aux données !
Pour plus de sécurité, nous n’allons autoriser la gestion de cette table qu’au rôle masking_admin.
grant ownership on table "ENTITLEMENT" to role masking_admin;Ainsi, le rôle masking_admin a tous les droits sur cette table, et uniquement lui, a accès à cette table.
Pour résumer :
Nous avons créé une table “d’autorisations”, avec une colonne MASK qui contient le nom de la masking policy, une colonne GRANTED_ON qui contient le rôle à autoriser et une colonne EXPIRATION_DATE qui donne la date d’expiration de ce droit. Si la date est NULL alors le droit n’a pas d’expiration. De plus, nous avons modifié les conditions de masquage par une requête qui vérifie l’existence d’un résultat lorsque nous cherchons, dans la table "d'autorisations" (ENTITLEMENT), le nom du rôle. Et enfin nous avons donné au rôle masking_admin et à lui seul, tous les droits sur la table "d'autorisations".
Grâce à cela, nous pouvons autoriser plus finement les accès aux données, autoriser plusieurs rôles pour une seule ou des masking policies et gérer la durée de validité de ces accès.
Jusqu’où la sécurité est-elle garantie ?
Ici nous avons créé des masking policies qui dépendent du rôle appelant. Il est possible de le faire par rapport à des utilisateurs et/ou des comptes Snowflake.
Dans tous les cas, lors des requêtes sur des tables possédant des masking policies, les données seront masquées ou non en fonction des conditions des masking policies. Ce qui veut dire que :
- Si je crée une table en clonant une table avec des masking policies, je clone les masking policies avec. La table clonée fait référence aux masking policies de la table originale.
- Si je crée une table en utilisant le CTAS (create table … as select …), comme la table est créée depuis une requête, les données dans cette table seront transformées selon les conditions de la masking policy, puis mises dans la table. Ce qui veut dire que la table ne fera pas référence aux masking policies mais contiendra des données transformées. Il faut donc faire très attention lors de l’usage du CTAS, car si nous créons une table avec un rôle qui a accès aux données, les données ne seront pas masquées !
Finalement, qu’importe la méthode, les données seront toujours en sécurité (avec le clone, elles sont masquées, avec le CTAS elles sont transformées). Mais nous remarquons qu’il est plus intéressant de cloner les tables afin de :
- garantir le masquage des données via les masking policy
- garantir l’accès aux données originales aux personnes autorisées
- empêcher la création de table avec des données non masquées (cas du CTAS cf ci-dessus)
Par ailleurs, cloner les tables est une bonne pratique Snowflake. Nous pouvons utiliser ce clone pour établir un workflow de travail :
- Je clone les données de production vers une base de développement
- Je travaille sur cette base
- Une fois mon travail terminé, je clone les données de production vers une base de test
- Je teste mon développement
- Si les tests sont réussis, je peux pousser mon développement en production
Et ainsi de suite ! Grâce à cela, nous avons toujours des données à jour et une sécurité garantie. Il faut cependant faire attention à bien ajouter les masking policies en production, lors de l’ajout de nouvelles tables et/ou de colonnes à masquer.
De même, ce workflow n'entraîne pas de surcoût de stockage grâce au zero copy cloning de Snowflake. Cette méthode de clone ne copie pas les objets mais fait référence à l’objet original. Si des modifications ont lieu dans l’objet cloné, ce seront uniquement ces modifications qui seront stockées, ce qui réduit les coûts de stockage. Malin !
Et voilà, c’est tout ce que j’avais à vous dire sur les masking policies. Pour approfondir, je vous conseille la documentation (qui est en anglais et en français) Snowflake : https://docs.snowflake.com/en/user-guide/security-column-intro.html. De plus, il existe aussi les secure views, qui permettent aussi de masquer des données. Ces vues sécurisées permettent elles aussi de filtrer l’accès à certaines données sensibles mais elles ont aussi un inconvénient : avec une masking policy, il est possible de l’appliquer sur plusieurs tables pour avoir la même protection, alors qu’il faudra créer une vue sécurisée par table avec la même condition de masquage. Ce qui donne lieu à un grand nombre de vues dans Snowflake et à des potentiels soucis de gestion des ces vues.
