
Besoin métier
Une application externe envoie des notifications de type WebHook à travers notre API qui est responsable de distribuer ces messages aux différentes applications internes de notre SI, en les répartissant dans des topics distincts. Pour répondre à ce besoin, nous allons implémenter le Fan-out Pattern avec Spring Cloud Stream en faisant transiter ces messages à travers des topics Kafka. Notre API a l’avantage de répondre rapidement au WebHook, étant donné que l’on ne fait que produire un message qui sera consommé de manière asynchrone.
Fan-out pattern
Le Fan-out pattern est un pattern de messaging bien connu dans les architectures event-driven. Le producer publie ses messages dans un topic d’échange. Ce topic est chargé de distribuer ces messages en fonction de critères préétablis dans d’autres topics. Les consommateurs des applications cibles sont en écoute sur ces topics, afin de récupérer leurs messages respectifs.
Spring Cloud Stream
Spring Cloud Stream est un framework qui permet de connecter des microservices entre eux à travers un système de messaging. Plusieurs Binders sont implémentés (RabbitMQ, Kafka, Kafka Streams, Google PubSub, Azure Event Hubs, …).
Spring Cloud Function
Spring Cloud Function permet d’exposer simplement des fonctions sous forme de @Beans. Il est de plus en plus utilisé dans le cadre des architectures Serverless et Function-as-a-Service (FaaS).
Depuis la version 2.1, Spring Cloud Stream intègre le support de Spring Cloud Function, avec une approche alternative dans la manière de définir les streams, en se basant sur la programmation fonctionnelle, en déclarant des beans de type java.util.function.[Supplier/Function /Consumer].
Approche réactive
Les Functions peuvent utiliser l’approche impérative ou réactive. Dans la première, les functions sont déclenchées à chaque événement. Dans la seconde, on gère un flux d'événement à l’aide de Flux et Mono du Projet Reactor. C’est ce que l’on utilise dans notre exemple.
Kafka Streams
Kafka Streams est une librairie de Kafka qui permet de traiter les données à la volée et en temps réel, avec une faible latence tout en étant scalable. Elle permet de manipuler des KStreams et des KTables.
Implémentation
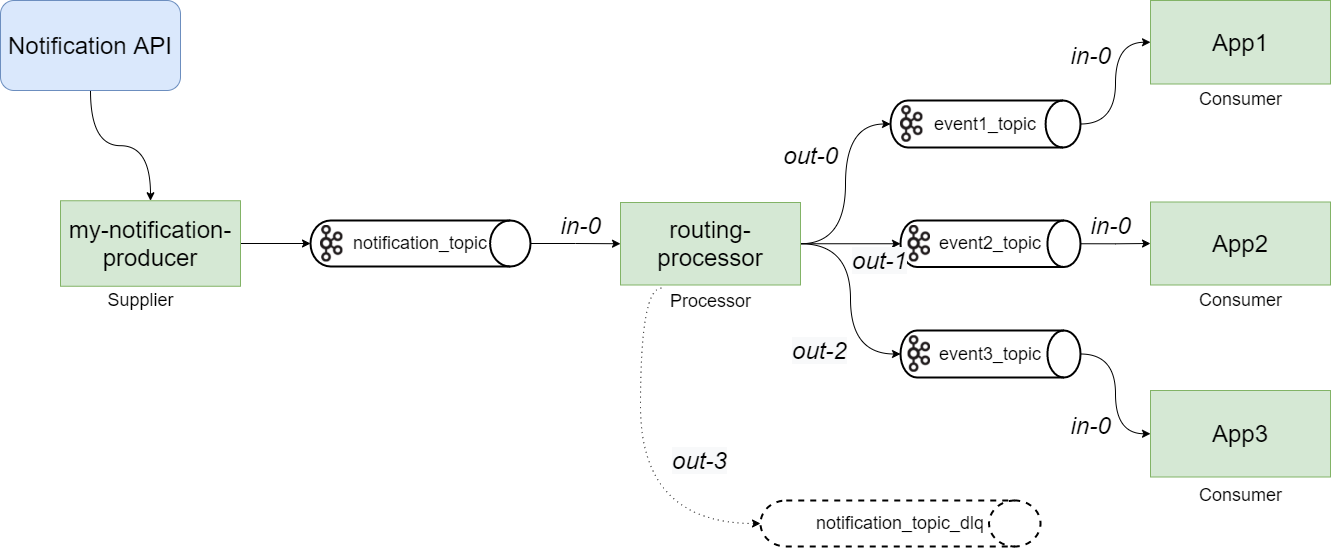
Voici le schéma que nous allons mettre en place :
Supplier
Déclaration du bean Supplier, qui va produire le message dans le topic notification_topic
@Bean("notification-producer")
NotificationProducer notificationProducer() {
return new MyNotificationProducer();
}Implémentation du Supplier avec flux réactif à l’aide de la librairie Reactor
@Slf4j
public class MyNotificationProducer implements Supplier<Flux<Message<NotificationEvent>>>, NotificationProducer {
private Sinks.Many<Message<NotificationEvent>> sink = Sinks.many().unicast().onBackpressureBuffer();
@Override
public void produce(NotificationEvent event) {
log.info("Emit event: {}", event);
Message<NotificationEvent> message = MessageBuilder
.withPayload(event)
.setHeader(KafkaHeaders.MESSAGE_KEY, toKey(event))
.build();
sink.emitNext(message, Sinks.EmitFailureHandler.FAIL_FAST);
}
@Override
public Flux<Message<NotificationEvent>> get() {
return sink.asFlux();
}
private String toKey(NotificationEvent event) {
return "key_" + event.getId();
}
}Function routing-processor
- Le processor traite le message en entrée pour le distribuer ensuite. Il utilise Kafka Stream pour router les messages à l’aide de
.branch()et de prédicats.
La règle est la suivante :
si le message en entrée contient"event1", on route sur le topicevent1_topic
si le message en entrée contient"event2", on route sur le topicevent2_topic
si le message en entrée contient"event3", on route sur le topicevent3_topic
sinon on route sur le topicnotification_topic_dlq - La méthode
branch()route vers les sorties multiples out-0, out-1, out-2 et out-3.
D’autres méthodes de KStream permettent aussi de faire du filter(), map(), flatMap(), groupBy().
La méthodeto()redirige vers un unique topic.
@Bean("routing-processor")
public Function<KStream<String, NotificationEvent>, KStream<String, NotificationEvent>[]> routingProcessor() {
Predicate<String, NotificationEvent> isEvent1 = (k, v) -> EVENT_1.equals(v.getType());
Predicate<String, NotificationEvent> isEvent2 = (k, v) -> EVENT_2.equals(v.getType());
Predicate<String, NotificationEvent> isEvent3 = (k, v) -> EVENT_3.equals(v.getType());
Predicate<String, NotificationEvent> isEventUnknown = (k, v) -> !Arrays.asList(EVENT_1, EVENT_2, EVENT_3).contains(v.getType());
return input -> input.branch(isEvent1, isEvent2, isEvent3, isEventUnknown);
}
Consumer
Dans notre exemple simple, la fonction du consumer App1 est de consommer et de logger le message dans le topic event1. De même pour les event2 et event3. En jouant avec les consumer group ids, une application peut être consommatrice des événements qui l'intéresse de plusieurs topics.
Ces 3 consommateurs sont déclarés dans le même projet, mais pourraient être dans des projets Spring Boot séparés.
@Bean
public Consumer<NotificationEvent> event1() {
return data -> log.info("Data received from event-1... " + data.getAction());
}
Configuration : application.yml
Ce fichier de configuration contient la déclaration du broker, les définitions des cloud functions et les différents bindings.
La déclaration des bindings respecte la convention de nommage suivante :
<functionName> + -in- + <index>
spring:
cloud:
stream:
kafka:
binder:
brokers: localhost:29092
producer-properties:
key.serializer: "org.apache.kafka.common.serialization.StringSerializer"
bindings:
routing-processor-in-0.consumer.configuration.value.deserializer: org.springframework.kafka.support.serializer.JsonDeserializer
routing-processor-out-0.producer.configuration.value.serializer: org.springframework.kafka.support.serializer.JsonSerializer
bindings:
notification-producer-out-0.destination: notification_topic
routing-processor-in-0.destination: notification_topic
routing-processor-out-0.destination: event1_topic
routing-processor-out-1.destination: event2_topic
routing-processor-out-2.destination: event3_topic
routing-processor-out-3.destination: notification_topic_dlq
event1-in-0.destination: event1_topic
event2-in-0.destination: event2_topic
event3-in-0.destination: event3_topic
function:
definition: notification-producer;routing-processor;event1;event2;event3
Tests d’intégration
Pour nos tests d’intégration, on démarre un Kafka local embarqué. On publie un événement de notification de type ‘event1’ dans le topic d’entrée principale notification_topic, puis l’on consomme ce message depuis le topic event1_topic et on vérifie que ce message est identique.
@RunWith(SpringRunner.class)
@SpringBootTest
public class EmbeddedKafkaApplicationTests {
...
@ClassRule
public static EmbeddedKafkaRule embeddedKafka = new EmbeddedKafkaRule(1, true,
OUTPUT_EVENT1_TOPIC, OUTPUT_EVENT2_TOPIC, OUTPUT_EVENT3_TOPIC);
@BeforeClass
public static void setup() {
System.setProperty("spring.cloud.stream.kafka.binder.brokers", embeddedKafka.getEmbeddedKafka().getBrokersAsString());
}
@Test
public void testSendReceiveEvent1() {
NotificationEvent event = NotificationEvent.builder()
.id(1L)
.type("event1")
.action("object.created")
.build();
sendMessage(event, INPUT_TOPIC);
ConsumerRecords<String, NotificationEvent> records = consumeMessage(OUTPUT_EVENT1_TOPIC, GROUP1_NAME);
assertThat(records.count()).isEqualTo(1);
assertThat(records.iterator().next().value()).isEqualTo(event);
}
...
}
Voici les méthodes utilitaires pour publier/consommer les messages :
private void sendMessage(NotificationEvent event, String inputTopic) {
Map<String, Object> senderProps = KafkaTestUtils.producerProps(embeddedKafka.getEmbeddedKafka());
senderProps.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
senderProps.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, JsonSerializer.class);
DefaultKafkaProducerFactory<byte[], byte[]> pf = new DefaultKafkaProducerFactory<>(senderProps);
KafkaTemplate<byte[], byte[]> template = new KafkaTemplate<>(pf, true);
template.setDefaultTopic(inputTopic);
Message<NotificationEvent> message = org.springframework.integration.support.MessageBuilder
.withPayload(event)
.setHeader(KafkaHeaders.MESSAGE_KEY, "myKey")
.build();
template.send(message);
}
private ConsumerRecords<String, NotificationEvent> consumeMessage(String outputTopic, String groupName) {
Map<String, Object> consumerProps = KafkaTestUtils.consumerProps(groupName, "false", embeddedKafka.getEmbeddedKafka());
consumerProps.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
consumerProps.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
consumerProps.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, JsonDeserializer.class);
consumerProps.put(JsonDeserializer.TRUSTED_PACKAGES, "fr.ippon.cloud.fanoutrouting.domain");
DefaultKafkaConsumerFactory<String, NotificationEvent> cf = new DefaultKafkaConsumerFactory<>(consumerProps);
Consumer<String, NotificationEvent> consumer = cf.createConsumer();
consumer.subscribe(Collections.singleton(outputTopic));
ConsumerRecords<String, NotificationEvent> records = consumer.poll(Duration.ofSeconds(10));
consumer.commitSync();
return records;
}
Démo du projet fanout-routing
Pour lancer et tester le projet en local, il suffit de suivre la procédure dans le Readme du projet.
L’intégralité des sources sont sur Github
Conclusion
- Il y a certainement beaucoup de manières différentes de répondre au besoin initial. L’avantage de l’implémentation présentée ci-dessus est qu’elle nécessite au final très peu de code et de configuration.
- Spring Cloud Stream permet de supprimer la dépendance avec le middleware de message et les bindings sont facilement adaptables.
- Spring Cloud Function permet une meilleure lisibilité du code, en permettant de se
passer des annotations que l’on avait avec Spring Cloud Streams en legacy. Par exemple :@Input("") MessageChannel publisher(); @Output("") MessageChannel publisher();et en ne manipulant que des fonctions (Supplier/Function/Consumer).