

Afin de répondre à une problématique de génération de données d’entrée lors de tests d’intégration, il a récemment fallu que je mette au point une solution de génération de grosses quantités de “fausses” réponses à des questionnaires Google Form, et de les exporter au format CSV. La problématique étant assez inhabituelle, et ce projet personnel illustrant très simplement l’utilisation de la librairie Faker.js, j’ai décidé de le partager au travers de cet article.
Si vous souhaitez y jeter un œil, le projet est disponible sur ce repository.
Problématique et choix des technologies
L’objectif de ce projet était de développer un programme permettant à l’utilisateur de générer une quantité arbitraire de réponses à un questionnaire qu’il aura spécifié en entrée au préalable. L’idée est d’offrir la possibilité à l’utilisateur de spécifier une répartition statistique des réponses, afin d’obtenir des résultats qui reflètent les courbes de tendance demandées.

J’ai choisi de développer le script à l’aide de Node.js, car ayant déjà eu vent de la librairie Faker.js, il me tardait de jouer et d’expérimenter avec cette dernière.
Pour ce qui est des formats d’entrée / sortie, j’ai choisi le format JSON car le parsing de ce format est très facile à mettre en place. De plus, j’ai aussi voulu expérimenter avec la validation de données à l’aide de Schémas JSON, en utilisant la librairie AJV. Je n’aborderai cependant pas cette étape de validation de données d’entrée dans cet article. Enfin, le choix du format CSV en sortie était plus une contrainte qu’un choix car l’objectif était avant tout de répliquer les données exportées par Google de la manière la plus fidèle possible, en comprenant donc le format de fichier en sortie.
Génération aléatoire de réponses et respect des courbes de tendances
Une des contraintes de ce projet était de produire des réponses qui suivent des tendances spécifiées en entrée, il y a plusieurs manières de procéder pour résoudre ce problème.
Une solution possible aurait été de demander à l’utilisateur de spécifier exactement le nombre de réponses attendues pour chaque option possible, puis de simplement générer les réponses demandées, comme illustré dans le diagramme ci-dessous.
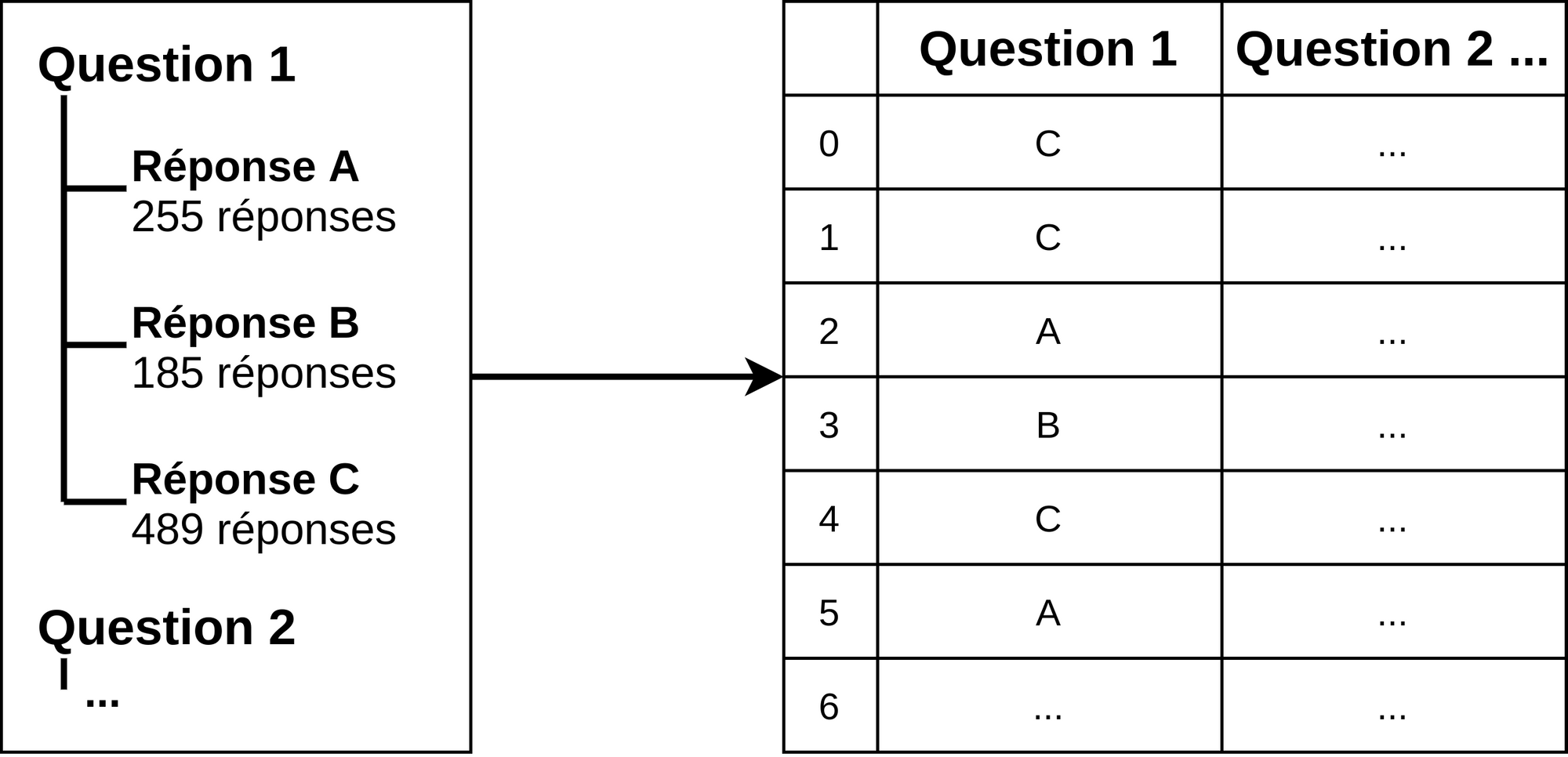
Le principal défaut de cette solution est qu’elle demande à l’utilisateur d’effectuer un travail préliminaire : déterminer le nombre de réponses total pour chaque option de réponse, en fonction de la courbe de tendance attendue, ce qui n’est pas nécessairement trivial lorsqu’on commence à prendre en compte les questions facultatives et les questions avec réponses multiples. L’objectif est donc de se contenter de tendances en entrées, comme illustré sur le diagramme ci-dessous.

Une autre solution possible serait donc d’effectuer le calcul du nombre de réponses nécessaires dans le programme, et de générer par la suite des réponses qui suivraient une distribution respectant parfaitement les tendances demandées. Cependant, il n’était pas nécessaire pour ce projet de respecter exactement ces tendances, mais simplement de les utiliser en tant qu’indications, et de produire des réponses aléatoires distribuées plus ou moins selon les pourcentages attendus. Par conséquent, plus le nombre de réponses générées sera élevé, et plus les tendances seront respectées.
Modélisation du questionnaire
Il est possible de modéliser un questionnaire reçu en entrée par l’interface suivante :
interface Form {
title: string; // Titre du questionnaire
locale: string; // Locale utilisée par Faker.js
dateMin: number; // Date minimum des timestamps de réponses
dateMax: number; // Date maximum des timestamps de réponses
answerCount: number; // Nombre de réponses à générer
questions: Question[]; // Questions du questionnaire
}
Comme Google attache une timestamp à chaque réponse, on demande à l’utilisateur de spécifier un encadrement pour ces timestamps, afin de ne pas générer des réponses datées de 1975 par exemple. Pour chaque réponse, le timestamp généré sera pris aléatoirement et de manière uniforme entre ces deux bornes. Le champ locale représente la langue utilisée dans la génération de réponses à l’aide de Faker.js, mais nous y reviendrons plus tard dans l’article. Passons maintenant à la modélisation des questions.
Il existe, à l’heure où j’écris cet article, 10 types de questions disponibles sur Google Form :
- Les réponses courtes et les réponses longues qui sont des champs de saisie libre (et qui autorisent en fait le même nombre de caractères).
- Les choix multiples pour lesquels l’utilisateur doit choisir une unique réponse parmi plusieurs options, dont l’une d’entre elles peut être un champ “Autre” composé d’un champ de saisie libre.
- Les cases à cocher, qui sont similaires aux choix multiples mais où l’utilisateur peut sélectionner plusieurs réponses par question.
- Les listes déroulantes, qui fonctionnent comme des questions à choix multiples mais présentées différemment.
- Les échelles linéaires, où l’utilisateur peut choisir une valeur sur une échelle (de 1 à 5 par exemple).
- Les grilles à choix multiples qui sont des grilles de questions où l’utilisateur coche une colonne (une réponse) par ligne.
- Les grilles de cases à cocher, qui sont similaires aux grilles à choix multiple mais où l’utilisateur peut cocher plusieurs colonnes par ligne.
- Les dates, où l’utilisateur doit spécifier une date (il est possible de demander à l’utilisateur d’indiquer l’année ou nom, et d’indiquer une heure ou non).
- Les heures, où l’utilisateur peut répondre par une heure de la journée ou une durée (comprise entre 0 secondes et 72h 59min et 59sec).
On peut remarquer que les listes déroulantes et les échelles linéaires sont en réalité des questions à choix multiples, présentées sous une autre forme. De plus, les grilles à choix multiples et les grilles de cases à cocher ne sont en réalité qu’une concaténation de plusieurs questions (une par ligne). On peut donc en conclure qu’il est possible de regrouper certains types de questions, afin de simplifier la modélisation du questionnaire, et même si dans le code original (disponible sur ce repository), j’ai différencié les questions “grilles” des questions à choix multiples, j’ai décidé dans cet article de les regrouper par soucis de simplicité.
L’interface Question, qui possède les informations communes à tous les types de questions est la suivante :
type QuestionType = 'FREE_TEXT' | 'DATE' | 'TIME' | 'MULTIPLE_CHOICE' | 'CHECKBOXES';
interface Question {
title: string; // Titre de la question
type: QuestionType; // Type de question
required: boolean; // Indique si la question est obligatoire ou non
noAnswerProbability?: number; // Probabilité de sauter la question si elle est facultative
}
Et les interface filles, modélisant spécifiquement chaque type de question sont les suivantes :
interface FreeTextQuestion extends Question {
type: 'FREE_TEXT';
answerModel: string; // Modèle de réponse pour Faker.js
}
export interface DateQuestion extends Question {
type: 'DATE';
min: number; // Date minimale
max: number; // Date maximale
withYear: boolean; // Indique si l'année doit être spécifiée dans la réponse
withTime: boolean; // Indique si l'heure doit être spécifiée dans la réponse
}
export interface TimeQuestion extends Question {
type: 'TIME';
min: number; // Heure ou durée minimale
max: number; // Heure ou durée maximale
}
export interface ChoiceQuestion extends Question {
type: 'MULTIPLE_CHOICE' | 'CHECKBOXES';
answerOptions: AnswerOption[]; // Options de réponses possibles
}
type AnswerOptionType = 'FIXED' | 'OTHER';
interface AnswerOption {
type: AnswerOptionType; // Type de réponse : Fixe ou autre (saisie libre)
probability: number; // Probabilité que cette réponse soit choisie
value?: string; // Valeur de la réponse pour une réponse fixe
answerModel: string; // Modèle de réponse Faker.js pour une réponse "Autre"
}
Génération de réponses pour des questions Date et Heure
Puisque pour ce projet, il n’était pas nécessaire de spécifier des courbes de tendances en entrée pour les questions de type date et heure, j’ai choisi de faire simple et de générer les réponses selon une distribution aléatoire uniforme. Il serait cependant tout à fait possible de demander à l’utilisateur de spécifier une loi de probabilité en entrée (exponentielle, normale, ou même personnalisée) et de générer des réponses aléatoires selon cette loi.
Pour les questions de type date, le format de données en sortie générées par Google diffère selon si la question demande à l’utilisateur de spécifier l’année et / ou l’heure dans sa réponse. De ce fait, il était nécessaire de demander à l’utilisateur de préciser dans le fichier JSON si ces paramètres étaient demandés dans la question.
Comme je travaillais avec des dates générées aléatoirement, il était pratique et pertinent de représenter ces dates par des timestamps, qui ne seraient convertis au format généré par Google que lors de l’export final du fichier CSV.
La génération des réponses aux questions de type heure (ou durée) suit la même logique, en remplaçant les timestamps par des durées en secondes, qui seraient converties par la suite au format attendu.
Génération de réponses pour des questions à choix multiples et cases à cocher
À chaque fois que le programme tente de générer une réponse à une question à choix multiple, il suit la logique suivante :
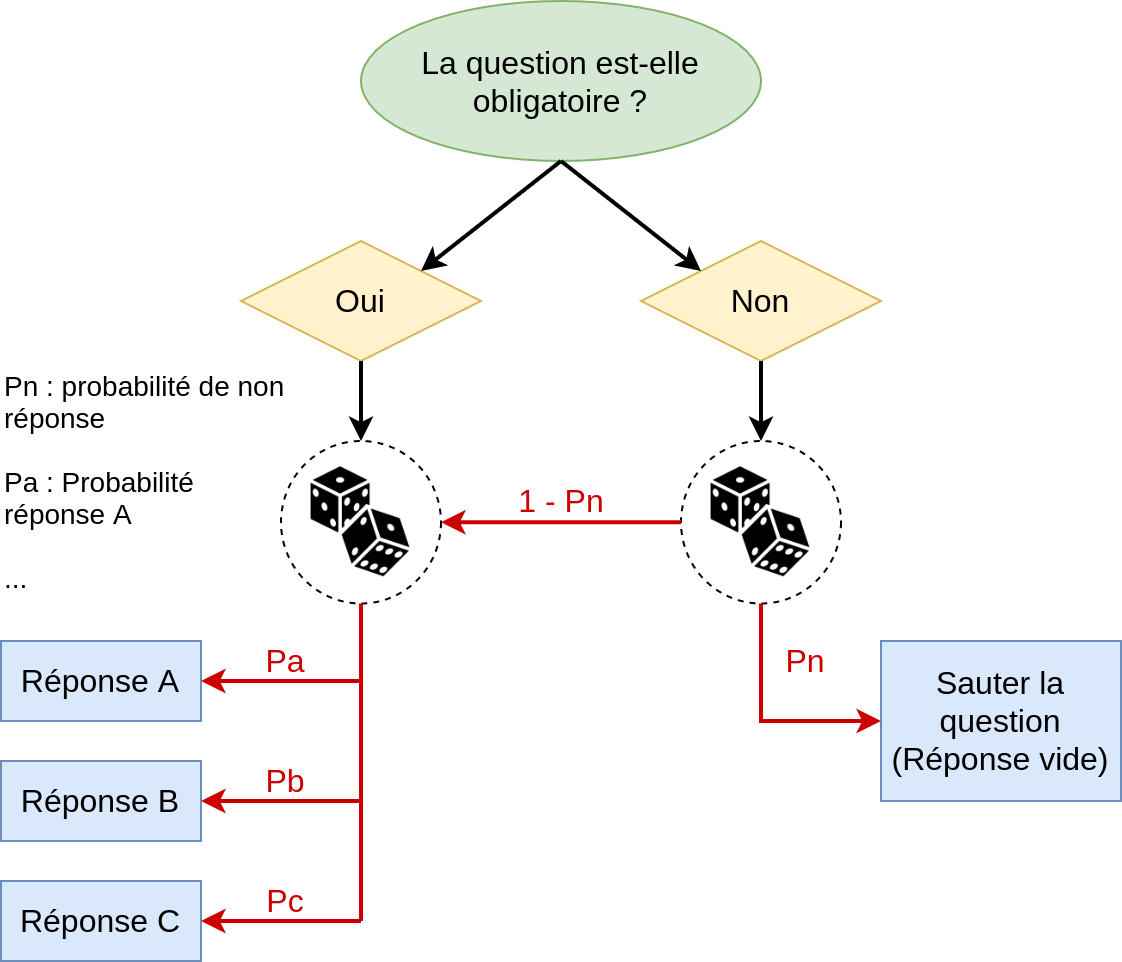
On décide d’abord si on saute la question ou non, puis on sélectionne une unique réponse parmi les options données, le tout en suivant les probabilités données en entrée. Un tel processus implique que, pour respecter les tendances, la somme des probabilités des questions (Pa, Pb, Pc…) doit être égale à 1. De plus, on remarque que dans le cas d’une question facultative, la probabilité réelle qu’une réponse (par exemple A) soit sélectionnée n’est plus égale à Pa mais égale à (1 - Pn) x Pa. Ce mode calcul des probabilité était une contraintes imposée par les spécifications du projet, mais il est tout à fait possible de s’en affranchir, en considérant une réponse vide comme une réponse normale et d’effectuer une seule épreuve aléatoire.
Pour les questions de type cases à cocher, le processus se complique un peu. En effet, dans ce type de questions, plusieurs réponses sont possibles. On va dans ce cas effectuer une épreuve aléatoire par réponse possible, afin de déterminer si cette dernière sera sélectionnée. Le diagramme du fonctionnement est le suivant :
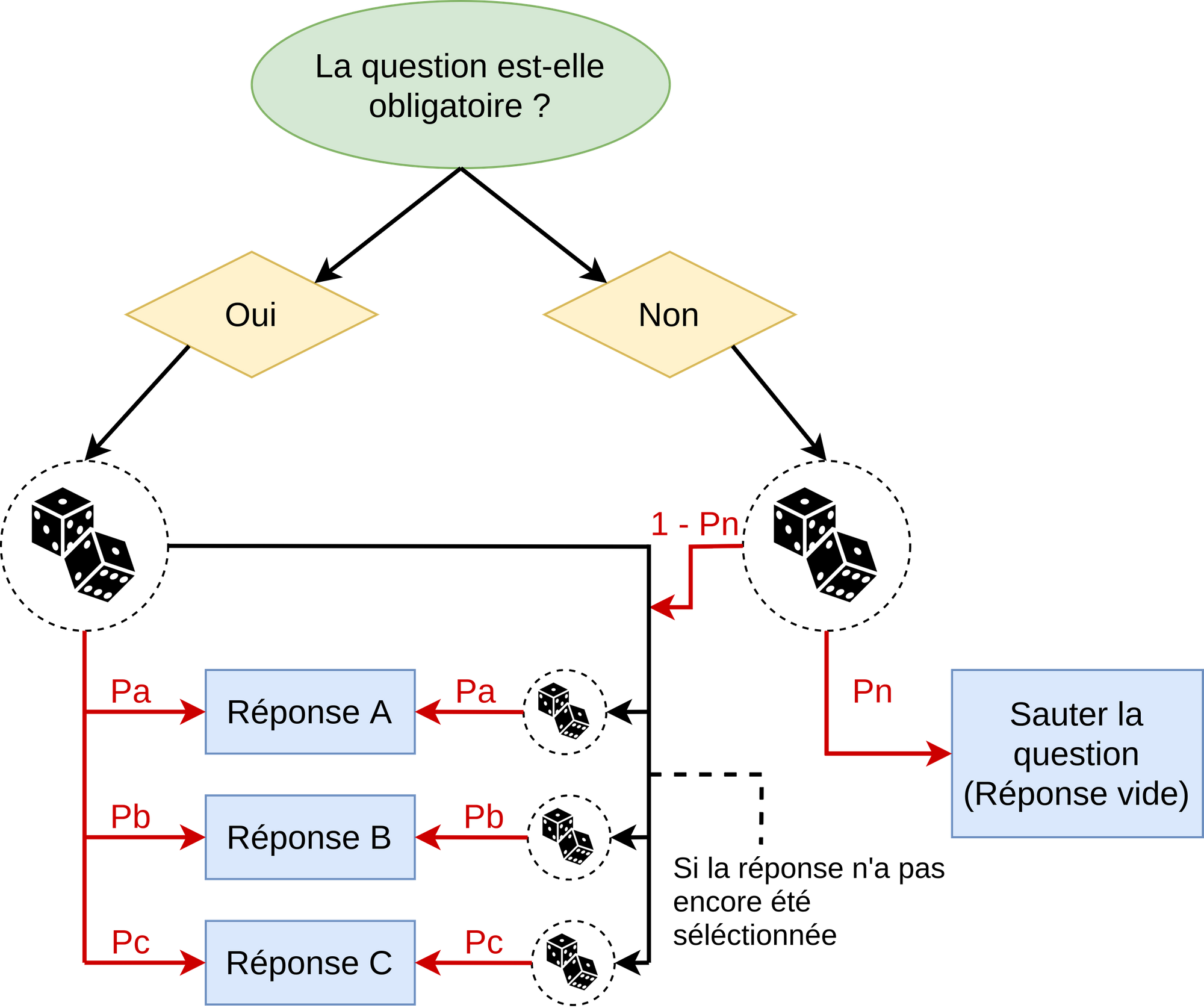
La partie droite du diagramme est identique au diagramme précédent, en remplaçant l’épreuve aléatoire unique de la question par plusieurs épreuves, une par question, pour savoir si celle-ci sera sélectionnée. Cependant, il faut aussi prendre en compte le cas où la question est obligatoire. En effet, dans ce cas, on effectue une épreuve aléatoire, similaire à celle du diagramme précédent, qui déterminera une question qui sera choisie “d’avance”. De ce fait, on pourra être garanti qu’on aura au moins une réponse sélectionnée. Il suffira ensuite d’effectuer des épreuves aléatoires pour toutes les autres questions qui n’ont pas encore été sélectionnées, afin de déterminer si ces dernières seront elles aussi cochées.
Nous n’avons pas encore évoqué le cas où la réponse sélectionnée est la réponse “Autre” (avec un champ de saisie libre). Que mettre comme valeur dans le champ de texte à saisir ? Une suite de caractères aléatoires ? Rien du tout ? C’est là que rentre en jeu Faker.js...
Génération de réponses pour les champs de saisie libres
Afin de générer automatiquement des réponses pour les champs de saisie libre, nous allons utiliser Faker.js, une librairie Node.js permettant de générer de grosses quantités de données appartenant à certaines catégories. En effet, Faker.js propose plusieurs catégories et sous-catégories de données à générer : adresses emails, genres musicaux, races d’animaux, noms d’entreprise, marques de voitures etc. Il est aussi possible de choisir la langue dans laquelle seront générées ces données. L’intégralité des catégories de données et des langues disponibles sont listées sur la page GitHub de Faker.js.
L’un des principaux avantages de cette librairie est sa simplicité d’usage. Pour installer la librairie, il suffit d’installer le package suivant :
npm install faker --save
À noter que si vous codez en TypeScript, il vous sera nécessaire d’installer les Types du projet à l’aide de la commande :
npm install @types/faker --save-dev
Une fois le package installé, il vous suffit de l’importer, de définir la locale si vous souhaitez obtenir des données dans une autre langue que l’anglais et d’appeler les méthodes statiques disponibles pour générer des données :
import faker from 'faker';
faker.locale = 'fr';
console.log(faker.internet.email()); // Adresse email
console.log(faker.internet.email()); // Une autre adresse email
console.log(faker.music.genre()); // Genre musical
console.log(faker.name.jobDescriptor()); // Description de job
Faker.js inclut une méthode extrêmement utile de génération de chaînes de caractères par interpolation : la méthode Faker.fake(). Avec cette méthode, vous pouvez spécifier, au sein de votre chaîne de caractères, des catégories de données, que faker va remplacer par des valeurs générées aléatoirement. L’exemple suivant illustre l’utilisation de cette méthode :
console.log(faker.fake('Je travaille en tant que {{name.jobType}} chez {{company.companyName}}'));
// Je travaille en tant que Designer chez Duval - Rolland
console.log(faker.fake('Je travaille en tant que {{name.jobType}} chez {{company.companyName}}'));
// Je travaille en tant que Producteur chez Rousseau SA
Cette méthode d’interpolation va nous être très utile dans la génération des réponses de notre questionnaire. En effet, pour chaque champ de saisie libre (que ce soit une réponse à une question de type FREE_TEXT ou une réponse “Autre” dans une question à choix multiples), on demande à l’utilisateur de spécifier dans le fichier JSON du questionnaire un champ answerModel, qui contient en réalité une chaîne de caractères avec des clés d’interpolation de Faker.js. De cette manière, après avoir défini la locale de Faker.js (en se basant sur la locale du questionnaire donnée à la racine du fichier JSON), on va par la suite pouvoir générer des réponses pour chaque question, y compris pour les champs de saisie libre, tout en gardant une certaine cohérence dans les données obtenues.
Pour aller plus loin, Faker.js propose des fonctions utilitaires telles que la méthode Faker.helpers.createCard() qui permet de générer une fiche contact, contenant des données cohérentes au sein de la fiche. En effet, le fait que les méthodes d’interpolation de Faker.js prennent des valeurs “aléatoires”, implique qu’il est possible de générer une série de réponses au questionnaire qui ressemblerait à cela :
- Prénom : Sébastien
- Nom de famille : Charpentier
- Sexe : Femme
- Adresse email : julien.dupont@gmail.com
Afin de garantir une meilleur cohérence dans les données générées, on pourrait par exemple générer une fiche contact à chaque fois qu’on génère une série de réponses au questionnaire, et privilégier les données présentes dans cette fiche lors de l’interpolation. Cette amélioration n’a pas été implémentée dans le projet disponible sur le repository, par manque de temps, et car le besoin n’était pas présent lors de la création du projet.
Conclusion
La problématique traitée dans cet article était la génération de réponses automatiques à un questionnaire Google Form en grande quantité, et le respect du format de données exporté par Google. J’ai préféré privilégier la lisibilité du code aux performances et de ce fait, il est clair que la solution proposée est loin d’être la plus optimisée. Cependant, les résultats obtenus sont ceux qui étaient attendus, et la solution permet d’effectuer des générations de grosses quantités de réponses en des temps tout à fait acceptables : validation du fichier JSON et génération d’environ 10000 réponses en moins de 4 secondes. Ce projet est au final une mise en pratique plutôt inhabituelle de Faker.js, une librairie très puissante et simple d’utilisation.
