

Attends… reste ! je vais te raconter quelque chose ! 😀
Dans cet article, je vais t’expliquer comment avec une équipe de trois développeurs nous avons fait évoluer le socle technique d’une grosse application monolithique, de manière transparente pour les utilisateurs.
Les besoins du client
Nombreux sont ceux qui aujourd'hui possèdent un bon vieux legacy, et qui n’aimeraient qu’une chose, utiliser des technologies plus modernes pour gagner en efficacité mais aussi en confort de développement.
La mission a commencé au moment où notre client a eu besoin de nouvelles fonctionnalités. Deux choix se sont alors présentés : continuer à développer sur le legacy ou repartir d’une base propre pour éviter d’ajouter toujours plus de dettes.
Le client chez qui j’ai évolué possède plusieurs applications, toutes sur le même socle technique (STRUTS2/Spring), et développées de la même manière. L’objectif de cette mission était donc de prendre une des applications pour en faire un projet pilote afin de répercuter ensuite toutes les améliorations sur l’ensemble des applications du SI.
Les besoins étaient :
- d’intégrer une nouvelle stack technique pour les nouveaux développements
- de mettre en place une industrialisation
- de former les développeurs à Angular
- de faire des retours d’expérience au reste des équipes
- de documenter, beaucoup, beaucoup
Mais comment intégrer une nouvelle brique technique ?
Après avoir considéré notre besoin, la seconde question à se poser est celle des contraintes. La principale contrainte était d’avoir une brique s’interconnectant bien avec l'écosystème présent afin de pouvoir facilement faire évoluer le reste du système d’information par la suite. Le SI étant basé sur du JAVA, il a été choisi de rester sur cette technologie, mais en quittant STRUTS.
Le choix de la nouvelle stack technique a été de passer sur du Spring Boot pour la partie Backend et sur de l'Angular pour les interfaces utilisateurs. L'objectif principal étant de pouvoir facilement dissocier les développements front et back.
Toute la nouvelle architecture a été Dockerisée en même temps que la CI/CD a été mise en place. Objectif : en finir avec le packaging en local pour la production et tendre vers une mise en production en 1 clic.
Nous avons néanmoins une contrainte forte : un utilisateur doit se connecter à partir du legacy et doit partager sa session avec la nouvelle brique technique. Pour cela nous avons été obligé de stocker des informations sur notre utilisateur tout au long de son cycle de vie dans l’application. Les deux applications étant basées sur du Spring, nous n’aurons pas de difficulté à utiliser Spring Session et de faire basculer le stockage de la session dans un système à part. La solution technique nous paraissait intéressante et rapide à mettre en place. Nous avons choisi d’utiliser Redis pour stocker les sessions. Redis étant une base de données NoSQL, nous avons de très bonnes performances en lecture/écriture.
Cependant, nous avons fait face à un nouveau problème : quand nous basculons d’une application à une autre, notre Cookie de session est en permanence renouvelé. Nous avons donc cherché un moyen de "duper" le navigateur pour avoir les deux applications sur le même cookie. Pour réaliser cela, nous avons eu l’idée d'intégrer un reverse proxy (Apache) pour que notre DNS soit tout le temps identique. Nous avons redirigé nos requêtes sur les URLs au lieu de faire des redirections DNS.
Voici un petit schéma représentant la nouvelle architecture pour la gestion des sessions :
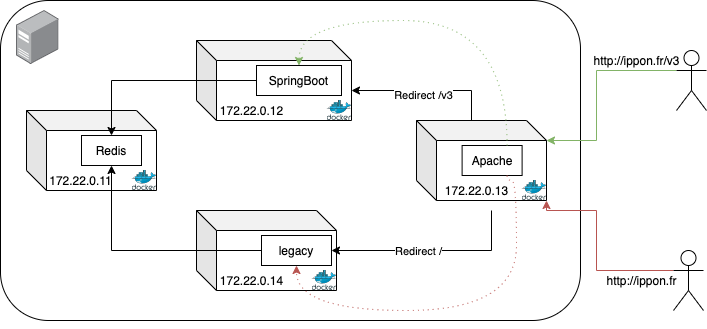 Architecture applicative pour la gestion des sessions
Architecture applicative pour la gestion des sessions
Les problèmes rencontrés….
Tout au long de l'implémentation de cette solution, nous avons réalisé de nombreux tests pour vérifier que nous n’avions pas de régression.
Les tests en environnement de développement
Nous avons commencé sur nos environnements de sandbox, qui sont à l’image de ce que nous aurons en production, sauf la volumétrie des jeux de données.
Durant les tests, nous nous sommes rendu compte que nous avions beaucoup d'erreurs de sérialisation pour mettre des objets en sessions dans le REDIS. Après analyse, Nous avons remarqué que toutes les classes d’objets mises en session n'implémentent pas la célèbre interface Serializable. Après une longue matinée d’ajout, cela a été fixé.
Une fois ce problème résolu, nous n’avions plus aucune erreur dans le legacy correspondant à des erreurs de sérialisation, tous les objets de session étaient bien persistés dans le redis. Les tests de premier niveau sont concluants, on peut alors passer à des tests à plus grande échelle.
Les tests en environnement de recette utilisateurs
Nous avions à notre disposition une base de données identique à la production mais anonymisée. Nous installons alors l'application dans son environnement de recette, et les utilisateurs pilotes peuvent commencer à faire une recette globale de l’application.
“L’application est lente…” , “Je ne peux rien faire…”, ont été des retours que nous avons eu.
Petite investigation et surprise !
En dix minutes et avec quatre utilisateurs, le container du legacy a écrit plus de 1,5TB de données en session 👏. Effectivement, par rapport à l’ancienne architecture, une nouvelle problématique est à prendre en compte. Le legacy étant dans un container et le redis aussi, nous passons par le réseau.
Le legacy a toujours écrit ce poids en objet de sessions, cependant personne ne s’en est jamais rendu compte car elle tournait dans un Tomcat directement sur la machine, donc pas d'échange réseau.
Pour corriger ces problèmes, il a été nécessaire d’apporter des modifications sur le legacy et sur le redis. Côté legacy, nous avons corrigé en limitant les objets mis en session, en repensant certaines parties de l’application. En parallèle, nous avons configuré le redis pour qu’il n'écrive pas ces données en temps réel sur le disque. En faisant ça nous avons réduit le temps d’attente entre chaque écriture, donc amélioré les performances.
Limiter les objets et faire en sorte que ce qui arrive sur le redis s'écrive beaucoup plus vite a doublé la vitesse historique de l’application et ramené les traces réseaux à un niveau normal.
Suite à cette correction, les utilisateurs ont poursuivi leur recette et ont donné le GO pour partir en production. A partir de ce jour, nous avons démarré une nouvelle phase du projet : faire migrer les différentes fonctionnalités phares du legacy sur la nouvelle application, pour apporter plus de confort pour les utilisateurs au quotidien.
Bilan sur cette intégration
Nous avons choisi cette cohabitation car l’objectif final de cette application est de migrer entièrement sur la nouvelle version. Beaucoup de fonctionnalités ne sont plus utilisées par les utilisateurs, car les écrans ne correspondent plus au besoin, ou alors ils ont été développés pour un besoin précis, utilisés une seule fois.
Si je devais retenir une seule chose sur cette migration, c’est qu’il faut faire attention entre une solution théorique et une implémentation réelle.
Nous avons révélé le côté obscur de ce legacy, ce qui a permis de faire ressortir des mauvaises pratiques de développement sur la gestion des objets en session et de cibler des améliorations rapides à mettre en place avec un fort intérêt. Beaucoup de nos découvertes ont tout de suite été corrigées sur les autres applications du SI.
