

DMS (Database Migration Service) est un service AWS permettant de migrer les données d’une base de données source vers une autre base cible.
Il est possible de répliquer ces données en temps réel grâce à l’option CDC (Change Data Capture) qui permet de récupérer les modifications ayant lieu sur la base source en continu pour les appliquer à la cible. De plus, on pourra effectuer des transformations sur les données en cours de transit pour les recevoir au format désiré.
Nous allons voir dans quel contexte utiliser ce processus (CDC) au travers d’un exemple d’utilisation et comment le paramétrer en fonction du besoin. Nous verrons également comment inclure le service de notification SNS pendant le transit des données, couplé à une queue SQS, pour garder une trace du déroulement de la migration.
Contexte d’utilisation
Considérons une base de données source PostgreSQL détenue par un tiers contenant un schéma vente avec une table voiture qui stocke des véhicules avec leurs informations respectives (prix, nombre de ventes, type de carburant, marque). En voici le contenu :
| id | price | pieces_sold | fuel_type | brand |
|---|---|---|---|---|
| 0 | 3000 | 430 | Diesel | Renault Twingo |
| 1 | 4200 | 267 | Essence | Citroën C3 |
| 2 | 10000 | 145 | Diesel | Peugeot 208 |
Cette base doit être migrée sur AWS vers une instance RDS qui sera la base cible. Le cas de figure est donc modélisé comme suit :
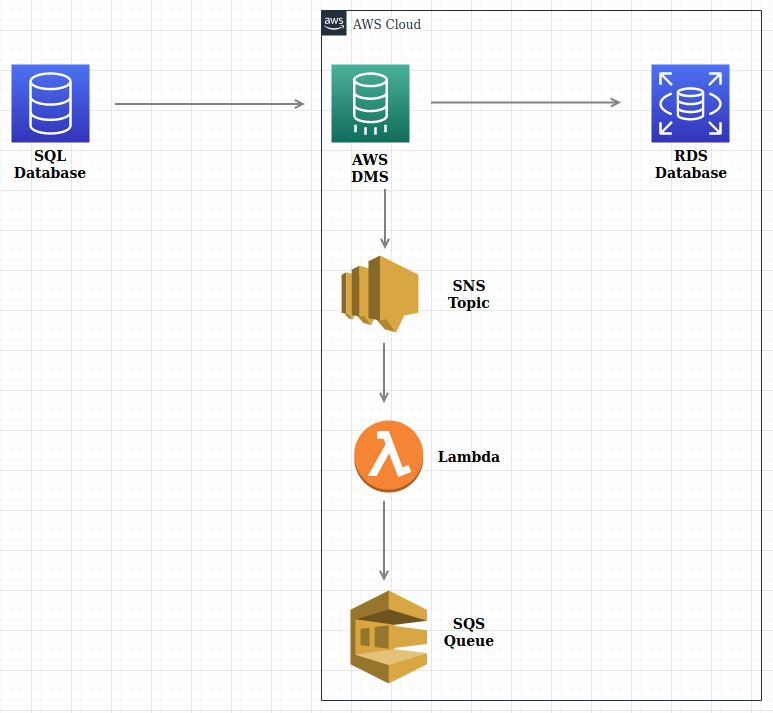
La lambda placée à la sortie de l’instance de migration DMS via la topique SNS va permettre de récupérer les lignes insérées à la volée dans une queue SQS (étape facultative).
La lambda est déclenchée par un événement qui est l’arrivée d’une nouvelle donnée dans DMS. Une fois déclenchée, elle exécute son code pour renvoyer directement toutes les informations de l’événement vers une messagerie (SQS) où nous pourrons consommer le message.
Le code de la lambda est le suivant :
Dans notre exemple, on considère que le schéma de la base source a déjà été transmis à la base cible mais que des données vont continuer d’être acheminées pendant un certain temps vers la base source, c’est pourquoi on aura besoin de tout répliquer en temps réel.
Nous considérons dans cet exemple que les données déjà présentes dans la base source ont été répliquées dans la base RDS cible en y important le schéma de données. Voici les étapes de cette procédure :
- Exportation du schéma de la base source :
pg_dump -U <myUser> -d <myDBName> -s “vente” -t “voiture” > schemaFileName.sql
(“-t” pour importer uniquement la table voulue) - Upload du fichier
schemaFileName.sqldans un bucket S3 du compte AWS où se trouve la base RDS - Utilisation d’un script permettant de récupérer le fichier contenant le schéma depuis le bucket S3 pour faire un
psql myRDSTargetDB < schemaFileName.sql. Ce script est à lancer sur la machine qui initie la connexion avec la base RDS.
A la fin de cette procédure, la base cible disposera de toutes les informations de la base source sur la table voiture.
Mise en place sur AWS
Nous allons maintenant mettre en place la solution sur notre compte AWS pour procéder à la réplication des données en temps réel.
Il va tout d’abord falloir préparer la migration comme suit (se rendre sur le service DMS) :
- Créer une instance de réplication
- Créer les endpoints source et cible avec comme source la base de données PostgreSQL et en cible la base RDS. Puis lier ces endpoints à l’instance de réplication précédemment créée
- Créer une instance de migration qui va utiliser les endpoints précédents et l’instance de réplication
Pour le dernier point (création de l’instance de migration), voici les différentes options possibles pour le type de migration :
- Juste les données existantes dans la base source
- Données existantes + changements en cours
- Juste les changements en cours
Pour notre exemple, on sélectionnera l’option “Replicate data changes only” étant donné que les données de notre base source ont déjà été répliquées à la cible pour notre table voiture.
Plus loin dans la création de l’instance de migration, on doit saisir les options pour CDC :
- Start mode : choisir “Disable custom CDC start mode” pour ne pas avoir à spécifier à partir de quel endroit récupérer nos données
- Stop mode : de même sélectionner “Disable custom CDC stop mode”
- LOB mode : “Limited LOB mode” et laisser le maximum à 32KB, cette option permet d’évincer les objets trop volumineux qui pourraient ralentir le transfert et les tronquera à la taille spécifiée (32KB)
En réalité, soit on arrête notre application le temps de la migration, soit on se sert des “startDate” et “endDate” pour commencer la migration à partir de la dernière donnée migrée (avec le dump).
La section “Table mapping” permet de choisir quels schéma/tables à répliquer. Cliquer sur “Add new selection rule” puis :
- Schema : “Enter a schema”
- Schema name :
vente - Table name :
voiture - Action : “Include”
On peut aussi appliquer des transformations sur les données récupérées pendant la réplication. Il faudra cliquer sur le bouton “Add new transformation”, puis :
- Target : “Column”
- Schema : “Enter a schema”
- Schema name :
vente - Table name :
voiture - Column name :
fuel_type - Action : “Remove column”
Cette transformation va nous permettre de ne pas recopier la column fuel_type dont nous n’avons pas besoin dans notre base cible.
Test de la réplication en continu
Nous lançons ensuite cette commande d’insertion de deux nouvelles lignes dans la table voiture de la base de données source :
INSERT INTO voiture VALUES (23000, 96, “Diesel”, “Audi A3”),(31000, 72, “Diesel”, “Mercedes A 180”);
Dans la base source les données sont mises à jour :
| id | price | pieces_sold | fuel_type | brand |
|---|---|---|---|---|
| 0 | 6000 | 430 | Diesel | Renault Twingo |
| 1 | 8200 | 267 | Essence | Citroën C3 |
| 2 | 15000 | 145 | Diesel | Peugeot 208 |
| 3 | 23000 | 96 | Diesel | Audi A3 |
| 4 | 31000 | 72 | Diesel | Mercedes A 180 |
De même pour la base cible en omettant la recopie de la colonne fuel_type :
| id | price | pieces_sold | brand |
|---|---|---|---|
| 0 | 6000 | 430 | Renault Twingo |
| 1 | 8200 | 267 | Citroën C3 |
| 2 | 15000 | 145 | Peugeot 208 |
| 3 | 23000 | 96 | Audi A3 |
| 4 | 31000 | 72 | Mercedes A 180 |
Conclusion
Notre exemple est un cas assez courant de ce que l’on peut vouloir faire lors de la migration d ‘une base de données présente chez un client vers le Cloud AWS.
La mise en place de la solution est rapide et la customisation très diverse. Nous avons vu également que l’on pouvait choisir quels schémas/tables répliquer et quelles étaient les différentes transformations possibles.
Cet exemple couvre le cas d’une réplication temps réel pour des bases SQL mais le principe est le même par exemple avec du NoSQL (MongoDB). On utilisera à ce moment l’API DataPump pour importer le schéma existant de la base source vers la cible.